
ExampleGen TFX Pipeline 구성 요소는 데이터를 TFX 파이프라인으로 입력합니다. 이 구성 요소는 외부 파일/서비스를 사용하여 다른 TFX 구성 요소에서 읽을 예제를 생성합니다. 또한, 일관되고 구성 가능한 파티션을 제공하고 ML 모범 사례를 위해 데이터세트를 섞습니다.
- 입력: CSV,
TFRecord, Avro, Parquet 및 BigQuery와 같은 외부 데이터 소스의 데이터 - 출력: 페이로드 형식에 따라
tf.Example레코드,tf.SequenceExample레코드 또는 proto 형식
ExampleGen 및 기타 구성 요소
ExampleGen은 SchemaGen, StatisticsGen 및 Example Validator와 같은 TensorFlow 데이터 검증 라이브러리를 사용하는 구성 요소에 데이터를 제공합니다. 또한, TensorFlow Transform 라이브러리를 사용하는 Transform에 데이터를 제공하고 궁극적으로 추론 중에 배포 대상에 데이터를 제공합니다.
ExampleGen 구성 요소를 사용하는 방법
지원되는 데이터 소스(현재는 CSV 파일, tf.Example, tf.SequenceExample 및 proto 형식이 포함된 tf.Example 파일, 그리고 BigQuery 쿼리 결과)의 경우, ExampleGen 파이프라인 구성 요소를 배포에 직접 사용할 수 있으며 사용자 정의가 거의 필요하지 않습니다. 예를 들면, 다음과 같습니다.
from tfx.utils.dsl_utils import csv_input
from tfx.components.example_gen.csv_example_gen.component import CsvExampleGen
examples = csv_input(os.path.join(base_dir, 'data/simple'))
example_gen = CsvExampleGen(input=examples)
또는, tf.Example로 외부 TFRecord를 직접 가져오려는 경우에는 다음과 같습니다.
from tfx.utils.dsl_utils import tfrecord_input
from tfx.components.example_gen.import_example_gen.component import ImportExampleGen
examples = tfrecord_input(path_to_tfrecord_dir)
example_gen = ImportExampleGen(input=examples)
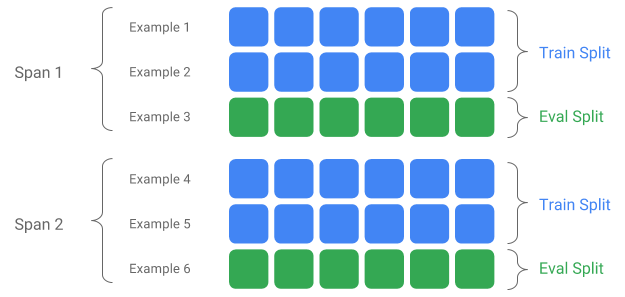
스팬, 버전 및 분할
스팬은 훈련 예제의 그룹입니다. 해당 데이터가 파일 시스템에 유지되는 경우, 각 스팬은 별도의 디렉토리에 저장될 수 있습니다. Span의 의미 체계는 TFX로 하드코딩되지 않습니다. 스팬은 하루 분량의 데이터, 한 시간 분량의 데이터 또는 해당 작업에 의미 있는 기타 데이터 그룹에 해당할 수 있습니다.
각 스팬은 여러 버전의 데이터를 보유할 수 있습니다. 예를 들어, 품질이 낮은 데이터를 정리하기 위해 스팬에서 일부 예를 제거하면 해당 스팬의 새 버전이 생성될 수 있습니다. 기본적으로, TFX 구성 요소는 스팬 내의 최신 버전에서 동작합니다.
스팬 내의 각 버전은 여러 분할로 더 세분화될 수 있습니다. 스팬을 분할하는 가장 일반적인 사용 사례는 훈련 데이터와 평가 데이터로 분할하는 것입니다.
사용자 정의 입력/출력 분할
참고: 이 기능은 TFX 0.14 이후부터만 사용할 수 있습니다.
ExampleGen이 출력할 훈편/평가 분할 비율을 사용자 정의하려면 ExampleGen 구성 요소에 대한 output_config를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx.proto import example_gen_pb2
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = example_gen_pb2.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
example_gen_pb2.SplitConfig.Split(name='train', hash_buckets=3),
example_gen_pb2.SplitConfig.Split(name='eval', hash_buckets=1)
]))
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, output_config=output)
이 예에서 hash_buckets가 어떻게 설정되었는지 확인하세요.
이미 분할된 입력 소스의 경우, ExampleGen 구성 요소에 대한 input_config를 설정합니다.
from tfx.proto import example_gen_pb2
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, input_config=input)
파일 기반 예제 gen(예: CsvExampleGen 및 ImportExampleGen)의 경우, pattern은 입력 기본 경로로 루트 디렉토리가 지정되어 입력 파일에 매핑되는 glob 상대 파일 패턴입니다. 쿼리 기반 예제 getn(예: BigQueryExampleGen, PrestoExampleGen)의 경우, pattern은 SQL 쿼리입니다.
기본적으로, 전체 입력의 기본 dir은 단일 입력 분할로 처리되고, train 및 eval의 출력 분할은 2:1 비율로 생성됩니다.
자세한 내용은 proto/example_gen.proto를 참조하세요.
분할 방법
hash_buckets 분할 방법을 사용하는 경우, 전체 레코드 대신 예제의 파티션을 만드는 기능을 사용할 수 있습니다. 기능이 있는 경우, ExampleGen은 해당 기능의 지문을 파티션 키로 사용합니다.
이 기능은 예제의 특정한 속성과 관련해 안정적인 분할을 유지하는 데 사용할 수 있습니다. 예를 들어, 파티션 기능 이름으로 "user_id"를 선택한 경우, 사용자는 항상 동일한 분할에 배치됩니다.
"기능"의 의미와 "기능"을 지정된 이름과 일치시키는 방법에 대한 해석은 ExampleGen 구현 및 예제 유형에 따라 다릅니다.
기존 ExampleGen 구현의 경우:
- tf.Example을 생성하는 경우, "기능"은 tf.Example.features.feature의 항목을 의미합니다.
- tf.SequenceExample을 생성하는 경우, "기능"은 tf.SequenceExample.context.feature의 항목을 의미합니다.
- int64 및 바이트 기능만 지원됩니다.
다음과 같은 경우, ExampleGen은 런타임 오류를 발생시킵니다.
- 지정된 기능 이름이 예제에 없습니다.
- 비어 있는 기능입니다(
tf.train.Feature()). - 지원되지 않는 기능 유형입니다(예: 부동 기능).
예제의 기능을 기반으로 train/eval 분할을 출력하려면 ExampleGen 구성 요소에 대한 output_config를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx.proto import example_gen_pb2
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = example_gen_pb2.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
example_gen_pb2.SplitConfig.Split(name='train', hash_buckets=3),
example_gen_pb2.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, output_config=output)
이 예제에서 partition_feature_name이 어떻게 설정되었는지 확인하세요.
Span
참고: 이 기능은 TFX 0.15 이후부터만 사용할 수 있습니다.
입력 glob 패턴에서 '{SPAN}' 사양을 사용하여 스팬을 검색할 수 있습니다.
- 이 사양은 숫자와 일치하고 데이터를 관련 SPAN 번호에 매핑합니다. 예를 들어, 'data_ {SPAN}-*. tfrecord'는 'data_12-a.tfrecord', 'date_12-b.tfrecord'와 같은 파일을 수집합니다.
- 선택적으로, 이 사양은 매핑될 때 정수의 너비로 지정할 수 있습니다. 예를 들어, 'data_{SPAN:2}.file'은 'data_02.file' 및 'data_27.file'(각각 Span-2 및 Span-27에 대한 입력)과 같은 파일에 매핑되지만 'data_1.file' 및 'data_123.file'에는 매핑되지 않습니다.
- SPAN 사양이 누락된 경우, 항상 스팬 '0'으로 간주됩니다.
- SPAN이 지정되면 파이프라인은 최신 스팬을 처리하고 스팬 번호를 메타데이터에 저장합니다.
예를 들어, 다음의 입력 데이터가 있다고 가정해 보겠습니다.
- '/tmp/span-1/train/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/train/data'
- '/tmp/span-2/eval/data'
입력 구성은 다음과 같습니다.
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
파이프라인을 트리거할 때 다음과 같이 처리됩니다.
- '/tmp/span-2/train/data'를 train 분할로 처리
- '/tmp/span-2/eval/data'를 eval 분할로 처리
이 때 스팬 번호는 '2'입니다. 나중에 '/tmp/span-3/...'이 준비될 때 파이프라인을 다시 트리거하기만 하면 처리를 위해 스팬 '3'이 선택됩니다. 다음은 스팬 사양을 사용하기 위한 코드 예제입니다.
from tfx.proto import example_gen_pb2
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
example_gen_pb2.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
examples = csv_input('/tmp')
example_gen = CsvExampleGen(input=examples, input_config=input)
특정 스팬 검색은 RangeConfig를 사용하여 수행할 수 있습니다. 아래에 이 내용을 자세히 설명합니다.
Date
참고: 이 기능은 TFX 0.24.0 이후부터만 사용할 수 있습니다.
데이터 소스가 날짜별로 파일 시스템에 구성되어 있는 경우, TFX는 날짜를 스팬 번호에 직접 매핑할 수 있도록 지원합니다. 날짜에서 스팬으로의 매핑을 나타내는 {YYYY}, {MM} 및 {DD}의 세 가지 사양이 있습니다.
- 사양이 지정된 경우, 세 가지 사양이 입력 glob 패턴에 모두 있어야 합니다.
SPAN
사양 또는 이 날짜 사양 세트를 배타적으로 지정할 수 있습니다.- YYYY의 연도, MM의 월 및 DD의 날짜가 포함된 달력 날짜가 계산된 다음, 스팬 번호가 Unix epoch(예: 1970-01-01) 이후의 일 수로 계산됩니다. 예를 들어, 'log-{YYYY}{MM}{DD}.data'는 'log-19700101.data' 파일과 일치하여 이 파일을 Span-0의 입력으로 사용하고 'log-20170101.data'는 Span-17167의 입력으로 사용합니다.
- 이 날짜 사양 세트가 지정되면 파이프라인은 최신 날짜를 처리하고 메타데이터에 해당 스팬 번호를 저장합니다.
예를 들어, 달력 날짜별로 구성된 입력 데이터가 있다고 가정해 보겠습니다.
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
입력 구성은 다음과 같습니다.
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
파이프라인을 트리거할 때 다음과 같이 처리됩니다.
- '/tmp/1970-01-03/train/data'를 train 분할로 처리
- '/tmp/1970-01-03/eval/data'를 eval 분할로 처리
이 때 스팬 번호는 '2'입니다. 나중에 '/tmp/1970-01-04/...'가 준비될 때 파이프라인을 다시 트리거하기만 하면 처리를 위해 스팬 '3'이 선택됩니다. 다음은 날짜 사양을 사용하기 위한 코드 예제입니다.
from tfx.proto import example_gen_pb2
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
example_gen_pb2.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
examples = csv_input('/tmp')
example_gen = CsvExampleGen(input=examples, input_config=input)
Version
참고: 이 기능은 TFX 0.24.0 이후부터만 사용할 수 있습니다.
입력 glob 패턴에서 '{VERSION}' 사양을 사용하여 버전을 검색할 수 있습니다.
- 이 사양은 숫자와 일치하고 데이터를 SPAN 아래의 관련 VERSION 번호에 매핑합니다. 버전 사양은 스팬 또는 날짜 사양과 함께 사용할 수 있습니다.
- 이 사양은 SPAN 사양과 같은 방식으로 너비를 선택적으로 지정할 수도 있습니다(예: 'span-{SPAN}/version-{VERSION:4}/data-*').
- VERSION 사양이 누락된 경우, 버전은 None으로 설정됩니다.
- SPAN과 VERSION이 모두 지정되면 파이프라인은 최신 스팬의 최신 버전을 처리하고 메타데이터에 버전 번호를 저장합니다.
- VERSION이 지정되었지만 SPAN(또는 날짜 사양)이 지정되지 않은 경우, 오류가 발생합니다.
예를 들어, 다음과 같은 입력 데이터가 있다고 가정해 보겠습니다.
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
입력 구성은 다음과 같습니다.
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
파이프라인을 트리거할 때 다음과 같이 처리됩니다.
- '/tmp/span-2/ver-2/train/data'를 train 분할로 처리
- '/tmp/span-2/ver-2/eval/data'를 eval 분할로 처리
이 때 스팬 번호는 '2'이고 버전 번호도 '2'입니다. 나중에 '/tmp/span-2/ver-3/...'이 준비될 때 파이프라인을 다시 트리거하기만 하면 처리를 위해 스팬 '2'와 버전 '3'이 선택됩니다. 다음은 버전 사양을 사용하기 위한 코드 예제입니다.
from tfx.proto import example_gen_pb2
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
example_gen_pb2.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
examples = csv_input('/tmp')
example_gen = CsvExampleGen(input=examples, input_config=input)
Range Config
참고: 이 기능은 TFX 0.24.0 이후부터만 사용할 수 있습니다.
TFX는 여러 TFX 엔터티의 범위를 설명하는 데 사용되는 추상 구성인 범위 구성을 사용하여 파일 기반 ExampleGen에서 특정 스팬의 검색과 처리를 지원합니다. 특정 스팬을 검색하려면 파일 기반 ExampleGen 구성 요소에 대해 range_config를 설정합니다. 예를 들어, 다음의 입력 데이터가 있다고 가정해 보겠습니다.
- '/tmp/span-01/train/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/train/data'
- '/tmp/span-02/eval/data'
스팬이 '1'인 데이터를 특정하게 검색하고 처리하기 위해, 입력 구성 외에 범위 구성을 지정합니다. ExampleGen은 단일 스팬 정적 범위만 지원합니다(특정한 개별 스팬의 처리를 지정하기 위해). 따라서 StaticRange의 경우, start_span_number는 end_span_number와 같아야 합니다. 제공된 스팬과 0(영) 채우기를 위한 스팬 너비 정보(제공된 경우)를 사용하여 ExampleGen은 제공된 분할 패턴의 SPAN 사양을 원하는 스팬 번호로 대체합니다. 사용 예는 다음과 같습니다.
from tfx.proto import example_gen_pb2
from tfx.proto import range_config_pb2
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
example_gen_pb2.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = range_config_pb2.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, input_config=input,
range_config=range)
SPAN 사양 대신 날짜 사양을 사용하는 경우, 범위 구성을 사용하여 특정 날짜를 처리할 수도 있습니다. 예를 들어, 달력 날짜별로 구성된 입력 데이터가 있다고 가정해 보겠습니다.
- '/tmp/1970-01-02/train/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/train/data'
- '/tmp/1970-01-03/eval/data'
1970년 1월 2일 데이터를 특정하게 검색하고 처리하기 위해 다음을 수행합니다.
from tfx.components.example_gen import utils
from tfx.proto import example_gen_pb2
from tfx.proto import range_config_pb2
input = example_gen_pb2.Input(splits=[
example_gen_pb2.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
example_gen_pb2.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = range_config_pb2.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
examples = csv_input(input_dir)
example_gen = CsvExampleGen(input=examples, input_config=input,
range_config=range)
사용자 정의 ExampleGen
참고: 이 기능은 TFX 0.14 이후부터만 사용할 수 있습니다.
현재 사용 가능한 ExampleGen 구성 요소가 필요에 맞지 않는 경우, BaseExampleGenExecutor에서 확장된 새 실행기를 포함하는 사용자 정의 ExampleGen을 만듭니다.
파일 기반 ExampleGen
먼저, train/eval 입력 분할에서 TF 예로의 변환을 제공하는 사용자 정의 Beam PTransform을 이용해 BaseExampleGenExecutor를 확장합니다. 예를 들어, CsvExampleGen 실행기는 입력 CSV 분할에서 TF 예로의 변환을 제공합니다.
그런 다음, CsvExampleGen component에서 수행한 것처럼 위의 실행기로 구성 요소를 만듭니다. 또는, 아래와 같이 표준 ExampleGen 구성 요소에 사용자 정의 실행기를 전달합니다.
from tfx.components.base import executor_spec
from tfx.components.example_gen.component import FileBasedExampleGen
from tfx.components.example_gen.csv_example_gen import executor
from tfx.utils.dsl_utils import external_input
examples = external_input(os.path.join(base_dir, 'data/simple'))
example_gen = FileBasedExampleGen(
input=examples,
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
이제, 이 방법을 사용하여 Avro 및 Parquet 파일 읽기도 지원합니다.
쿼리 기반 ExampleGen
먼저, 외부 데이터 소스에서 데이터를 읽는 사용자 정의 Beam PTransform으로 BaseExampleGenExecutor를 확장합니다. 그런 다음, QueryBasedExampleGen을 확장하여 간단한 구성 요소를 만듭니다.
추가 연결 구성이 필요할 수도 있고 필요하지 않을 수도 있습니다. 예를 들어, BigQuery 실행기는 연결 구성 정보를 추상화하는 기본 beam.io 커넥터를 사용하여 읽습니다. Presto 실행기에는 사용자 정의 Beam PTransform 및 사용자 정의 연결 구성 protobuf가 입력으로 필요합니다.
사용자 정의 ExampleGen 구성 요소에 연결 구성이 필요한 경우, 새 protobuf를 생성하고 이제는 선택적 실행 매개변수인 custom_config를 통해 이를 전달합니다. 다음은 구성된 구성 요소를 사용하는 방법을 보여주는 예입니다.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
ExampleGen 다운스트림 구성 요소
다운스트림 구성 요소에 대해 사용자 정의 분할 구성이 지원됩니다.
StatisticsGen
모든 분할에 대해 통계 생성을 수행하는 것이 기본 동작입니다.
분할을 제외하려면 StatisticsGen 구성 요소에 대해 exclude_splits를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx import components
...
# Exclude the 'eval' split.
statistics_gen = components.StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SchemaGen
모든 분할을 기반으로 스키마를 생성하는 것이 기본 동작입니다.
분할을 제외하려면 SchemaGen 구성 요소에 대해 exclude_splits를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx import components
...
# Exclude the 'eval' split.
schema_gen = components.SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ExampleValidator
스키마에 대한 입력 예에서 모든 분할의 통계를 검증하는 것이 기본 동작입니다.
분할을 제외하려면 ExampleValidator 구성 요소에 대해 exclude_splits를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx import components
...
# Exclude the 'eval' split.
example_validator = components.ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Transform
'훈련' 분할에서 메타데이터를 분석 및 생성하고 모든 분할을 변환하는 것이 기본 동작입니다.
분석 분할 및 변환 분할을 지정하려면 Transform 구성 요소에 대해 splits_config를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx import components
from tfx.proto import transform_pb2
...
# Analyze the 'train' split and transform all splits.
transform = components.Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=transform_pb2.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Trainer 및 Tuner
'train' 분할에서 훈련하고, 'eval' 분할에서 평가하는 것이 기본 동작입니다.
훈련 분할과 평가 분할을 지정하려면 Trainer 구성 요소에 대해 train_args 및 eval_args를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx import components
from tfx.proto import trainer_pb2
...
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = components.Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=trainer_pb2.TrainArgs(splits=['train'], num_steps=10000),
eval_args=trainer_pb2.EvalArgs(splits=['eval'], num_steps=5000))
Evaluator
'eval' 분할에서 계산된 메트릭을 제공하는 것이 기본 동작입니다.
사용자 정의 분할에 대한 평가 통계를 계산하려면 Evaluator 구성 요소에 대한 example_splits를 설정합니다. 예를 들면, 다음과 같습니다.
from tfx import components
from tfx.proto import evaluator_pb2
...
# Compute metrics on the 'eval1' split and the 'eval2' split.
Trainer = components.Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])