
Komponen Pipeline TFX ContohGen menyerap data ke dalam pipeline TFX. Ia menggunakan file/layanan eksternal untuk menghasilkan Contoh yang akan dibaca oleh komponen TFX lainnya. Ini juga menyediakan partisi yang konsisten dan dapat dikonfigurasi, serta mengacak kumpulan data untuk praktik terbaik ML.
- Menggunakan: Data dari sumber data eksternal seperti CSV,
TFRecord, Avro, Parket, dan BigQuery. - Memancarkan: catatan
tf.Example, catatantf.SequenceExample, atau format proto, bergantung pada format payload.
ContohGen dan Komponen Lainnya
ContohGen menyediakan data ke komponen yang menggunakan pustaka Validasi Data TensorFlow , seperti SchemaGen , StatisticsGen , dan Contoh Validator . Ini juga menyediakan data ke Transform , yang memanfaatkan pustaka TensorFlow Transform , dan pada akhirnya ke target penerapan selama inferensi.
Sumber dan Format Data
Saat ini instalasi standar TFX mencakup komponen ContohGen lengkap untuk sumber dan format data berikut:
Pelaksana khusus juga tersedia yang memungkinkan pengembangan komponen ContohGen untuk sumber dan format data berikut:
Lihat contoh penggunaan dalam kode sumber dan diskusi ini untuk informasi lebih lanjut tentang cara menggunakan dan mengembangkan pelaksana kustom.
Selain itu, sumber dan format data berikut tersedia sebagai contoh komponen khusus :
Menyerap format data yang didukung oleh Apache Beam
Apache Beam mendukung penyerapan data dari berbagai sumber dan format data , ( lihat di bawah ). Kemampuan ini dapat digunakan untuk membuat komponen ContohGen khusus untuk TFX, yang ditunjukkan oleh beberapa komponen ContohGen yang ada ( lihat di bawah ).
Cara menggunakan Komponen ContohGen
Untuk sumber data yang didukung (saat ini, file CSV, file TFRecord dengan tf.Example , tf.SequenceExample dan format proto, serta hasil kueri BigQuery) komponen pipeline SampleGen dapat digunakan langsung dalam penerapan dan memerlukan sedikit penyesuaian. Misalnya:
example_gen = CsvExampleGen(input_base='data_root')
atau seperti di bawah ini untuk mengimpor TFRecord eksternal dengan tf.Example secara langsung:
example_gen = ImportExampleGen(input_base=path_to_tfrecord_dir)
Rentang, Versi, dan Pemisahan
Span adalah pengelompokan contoh pelatihan. Jika data Anda disimpan di sistem file, setiap Span dapat disimpan di direktori terpisah. Semantik suatu Span tidak dikodekan secara keras ke dalam TFX; suatu Rentang mungkin berkaitan dengan data satu hari, data satu jam, atau pengelompokan lainnya yang berarti bagi tugas Anda.
Setiap Rentang dapat menampung beberapa Versi data. Sebagai contoh, jika Anda menghapus beberapa contoh dari suatu Span untuk membersihkan data berkualitas buruk, hal ini dapat menghasilkan Versi baru dari Span tersebut. Secara default, komponen TFX beroperasi pada Versi terbaru dalam suatu Rentang.
Setiap Versi dalam suatu Rentang selanjutnya dapat dibagi lagi menjadi beberapa Pemisahan. Kasus penggunaan paling umum untuk memisahkan Span adalah membaginya menjadi data pelatihan dan data evaluasi.
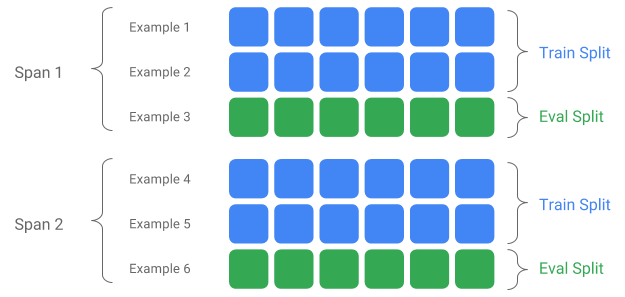
Pembagian input/output khusus
Untuk menyesuaikan rasio pemisahan train/eval yang akan dihasilkan ContohGen, atur output_config untuk komponen ContohGen. Misalnya:
# Input has a single split 'input_dir/*'.
# Output 2 splits: train:eval=3:1.
output = proto.Output(
split_config=example_gen_pb2.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
]))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Perhatikan bagaimana hash_buckets disetel dalam contoh ini.
Untuk sumber masukan yang telah dipisah, atur input_config untuk komponen ContohGen:
# Input train split is 'input_dir/train/*', eval split is 'input_dir/eval/*'.
# Output splits are generated one-to-one mapping from input splits.
input = proto.Input(splits=[
example_gen_pb2.Input.Split(name='train', pattern='train/*'),
example_gen_pb2.Input.Split(name='eval', pattern='eval/*')
])
example_gen = CsvExampleGen(input_base=input_dir, input_config=input)
Untuk contoh gen berbasis file (misalnya CsvExampleGen dan ImportExampleGen), pattern adalah pola file relatif glob yang dipetakan ke file input dengan direktori root yang diberikan oleh jalur basis input. Untuk contoh gen berbasis kueri (misalnya BigQueryExampleGen, PrestoExampleGen), pattern adalah kueri SQL.
Secara default, seluruh direktori basis input diperlakukan sebagai pemisahan input tunggal, dan pemisahan output train dan eval dihasilkan dengan rasio 2:1.
Silakan merujuk ke proto/example_gen.proto untuk konfigurasi pemisahan input dan output SampleGen. Dan lihat panduan komponen hilir untuk memanfaatkan pemisahan khusus di hilir.
Metode Pemisahan
Saat menggunakan metode pemisahan hash_buckets , alih-alih seluruh catatan, seseorang dapat menggunakan fitur untuk mempartisi contoh. Jika suatu fitur ada, ContohGen akan menggunakan sidik jari fitur tersebut sebagai kunci partisi.
Fitur ini dapat digunakan untuk mempertahankan pemisahan yang stabil dengan properti tertentu contoh: misalnya, pengguna akan selalu dimasukkan ke dalam pemisahan yang sama jika "user_id" dipilih sebagai nama fitur partisi.
Penafsiran tentang arti "fitur" dan cara mencocokkan "fitur" dengan nama yang ditentukan bergantung pada implementasi exampleGen dan jenis contohnya.
Untuk implementasi ContohGen yang sudah jadi:
- Jika menghasilkan tf.Example, maka "fitur" berarti entri di tf.Example.features.feature.
- Jika menghasilkan tf.SequenceExample, maka "fitur" berarti entri di tf.SequenceExample.context.feature.
- Hanya fitur int64 dan bytes yang didukung.
Dalam kasus berikut, ContohGen menimbulkan kesalahan runtime:
- Nama fitur yang ditentukan tidak ada dalam contoh.
- Fitur kosong:
tf.train.Feature(). - Jenis fitur yang tidak didukung, misalnya fitur float.
Untuk mengeluarkan pemisahan train/eval berdasarkan fitur dalam contoh, atur output_config untuk komponen ContohGen. Misalnya:
# Input has a single split 'input_dir/*'.
# Output 2 splits based on 'user_id' features: train:eval=3:1.
output = proto.Output(
split_config=proto.SplitConfig(splits=[
proto.SplitConfig.Split(name='train', hash_buckets=3),
proto.SplitConfig.Split(name='eval', hash_buckets=1)
],
partition_feature_name='user_id'))
example_gen = CsvExampleGen(input_base=input_dir, output_config=output)
Perhatikan bagaimana partition_feature_name disetel dalam contoh ini.
Menjangkau
Span dapat diambil dengan menggunakan spesifikasi '{SPAN}' dalam pola input glob :
- Spesifikasi ini mencocokkan angka dan memetakan data ke dalam nomor SPAN yang relevan. Misalnya, 'data_{SPAN}-*.tfrecord' akan mengumpulkan file seperti 'data_12-a.tfrecord', 'data_12-b.tfrecord'.
- Secara opsional, spesifikasi ini dapat ditentukan dengan lebar bilangan bulat saat dipetakan. Misalnya, 'data_{SPAN:2}.file' dipetakan ke file seperti 'data_02.file' dan 'data_27.file' (masing-masing sebagai masukan untuk Span-2 dan Span-27), tetapi tidak dipetakan ke 'data_1. file' atau 'data_123.file'.
- Jika spesifikasi SPAN tidak ada, maka diasumsikan selalu Span '0'.
- Jika SPAN ditentukan, alur akan memproses rentang terbaru, dan menyimpan nomor rentang dalam metadata.
Misalnya, asumsikan ada data masukan:
- '/tmp/span-1/kereta/data'
- '/tmp/span-1/eval/data'
- '/tmp/span-2/kereta/data'
- '/tmp/span-2/eval/data'
dan konfigurasi input ditampilkan seperti di bawah ini:
splits {
name: 'train'
pattern: 'span-{SPAN}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/eval/*'
}
saat memicu pipeline, ia akan memproses:
- '/tmp/span-2/train/data' sebagai pemisahan kereta
- '/tmp/span-2/eval/data' sebagai pemisahan eval
dengan nomor rentang sebagai '2'. Jika nanti '/tmp/span-3/...' sudah siap, cukup picu pipeline lagi dan ia akan mengambil span '3' untuk diproses. Di bawah ini menunjukkan contoh kode untuk menggunakan spesifikasi span:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Mengambil rentang tertentu dapat dilakukan dengan RangeConfig, yang dirinci di bawah.
Tanggal
Jika sumber data Anda disusun berdasarkan sistem file berdasarkan tanggal, TFX mendukung pemetaan tanggal secara langsung ke nomor rentang. Ada tiga spesifikasi untuk mewakili pemetaan dari tanggal ke rentang: {YYYY}, {MM} dan {DD}:
- Ketiga spesifikasi tersebut harus ada dalam pola glob masukan jika ada yang ditentukan:
- Spesifikasi {SPAN} atau kumpulan spesifikasi tanggal ini dapat ditentukan secara eksklusif.
- Tanggal kalender dengan tahun dari YYYY, bulan dari MM, dan hari dalam bulan dari DD dihitung, kemudian nomor rentang dihitung sebagai jumlah hari sejak zaman unix (yaitu 01-01-1970). Misalnya, 'log-{YYYY}{MM}{DD}.data' cocok dengan file 'log-19700101.data' dan menggunakannya sebagai masukan untuk Span-0, dan 'log-20170101.data' sebagai masukan untuk Rentang-17167.
- Jika kumpulan spesifikasi tanggal ini ditentukan, pipeline akan memproses tanggal terbaru, dan menyimpan nomor rentang yang sesuai dalam metadata.
Misalnya, asumsikan ada data masukan yang disusun berdasarkan tanggal kalender:
- '/tmp/1970-01-02/kereta/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/kereta/data'
- '/tmp/1970-01-03/eval/data'
dan konfigurasi input ditampilkan seperti di bawah ini:
splits {
name: 'train'
pattern: '{YYYY}-{MM}-{DD}/train/*'
}
splits {
name: 'eval'
pattern: '{YYYY}-{MM}-{DD}/eval/*'
}
saat memicu pipeline, ia akan memproses:
- '/tmp/1970-01-03/train/data' sebagai pemisahan kereta
- '/tmp/1970-01-03/eval/data' sebagai pemisahan eval
dengan nomor rentang sebagai '2'. Jika nanti '/tmp/1970-01-04/...' sudah siap, cukup picu pipeline lagi dan ia akan mengambil span '3' untuk diproses. Di bawah ini menunjukkan contoh kode untuk menggunakan spesifikasi tanggal:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Versi
Versi dapat diambil dengan menggunakan spesifikasi '{VERSION}' dalam pola input glob :
- Spesifikasi ini mencocokkan angka dan memetakan data ke nomor VERSI yang relevan di bawah SPAN. Perhatikan bahwa spesifikasi Versi dapat digunakan kombinasi dengan spesifikasi Span atau Tanggal.
- Spesifikasi ini juga dapat ditentukan secara opsional dengan lebar dengan cara yang sama seperti spesifikasi SPAN. misalnya 'span-{SPAN}/version-{VERSION:4}/data-*'.
- Jika spesifikasi VERSION tidak ada, versi disetel ke Tidak Ada.
- Jika SPAN dan VERSION keduanya ditentukan, pipeline akan memproses versi terbaru untuk rentang terbaru, dan menyimpan nomor versi dalam metadata.
- Jika VERSION ditentukan, tetapi tidak SPAN (atau spesifikasi tanggal), kesalahan akan terjadi.
Misalnya, asumsikan ada data masukan:
- '/tmp/span-1/ver-1/train/data'
- '/tmp/span-1/ver-1/eval/data'
- '/tmp/span-2/ver-1/train/data'
- '/tmp/span-2/ver-1/eval/data'
- '/tmp/span-2/ver-2/train/data'
- '/tmp/span-2/ver-2/eval/data'
dan konfigurasi input ditampilkan seperti di bawah ini:
splits {
name: 'train'
pattern: 'span-{SPAN}/ver-{VERSION}/train/*'
}
splits {
name: 'eval'
pattern: 'span-{SPAN}/ver-{VERSION}/eval/*'
}
saat memicu pipeline, ia akan memproses:
- '/tmp/span-2/ver-2/train/data' sebagai pemisahan kereta
- '/tmp/span-2/ver-2/eval/data' sebagai pemisahan eval
dengan nomor rentang sebagai '2' dan nomor versi sebagai '2'. Jika nanti '/tmp/span-2/ver-3/...' sudah siap, cukup picu pipeline lagi dan ia akan mengambil span '2' dan versi '3' untuk diproses. Di bawah ini menunjukkan contoh kode untuk menggunakan spesifikasi versi:
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN}/ver-{VERSION}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN}/ver-{VERSION}/eval/*')
])
example_gen = CsvExampleGen(input_base='/tmp', input_config=input)
Konfigurasi Rentang
TFX mendukung pengambilan dan pemrosesan rentang tertentu dalam exampleGen berbasis file menggunakan konfigurasi rentang, konfigurasi abstrak yang digunakan untuk mendeskripsikan rentang entitas TFX yang berbeda. Untuk mengambil rentang tertentu, atur range_config untuk komponen ContohGen berbasis file. Misalnya, asumsikan ada data masukan:
- '/tmp/span-01/kereta/data'
- '/tmp/span-01/eval/data'
- '/tmp/span-02/kereta/data'
- '/tmp/span-02/eval/data'
Untuk secara khusus mengambil dan memproses data dengan rentang '1', kami menentukan konfigurasi rentang selain konfigurasi input. Perhatikan bahwa ContohGen hanya mendukung rentang statis rentang tunggal (untuk menentukan pemrosesan rentang individual tertentu). Jadi, untuk StaticRange, angka_span_mulai harus sama dengan angka_span_akhir. Dengan menggunakan rentang yang disediakan, dan informasi lebar rentang (jika tersedia) untuk bantalan nol, ContohGen akan mengganti spesifikasi SPAN dalam pola pemisahan yang disediakan dengan nomor rentang yang diinginkan. Contoh penggunaannya ditunjukkan di bawah ini:
# In cases where files have zero-padding, the width modifier in SPAN spec is
# required so TFX can correctly substitute spec with zero-padded span number.
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='span-{SPAN:2}/train/*'),
proto.Input.Split(name='eval',
pattern='span-{SPAN:2}/eval/*')
])
# Specify the span number to be processed here using StaticRange.
range = proto.RangeConfig(
static_range=proto.StaticRange(
start_span_number=1, end_span_number=1)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/span-01/train/*' and 'input_dir/span-01/eval/*', respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Konfigurasi rentang juga dapat digunakan untuk memproses tanggal tertentu, jika spesifikasi tanggal digunakan, bukan spesifikasi SPAN. Misalnya, asumsikan ada data masukan yang disusun berdasarkan tanggal kalender:
- '/tmp/1970-01-02/kereta/data'
- '/tmp/1970-01-02/eval/data'
- '/tmp/1970-01-03/kereta/data'
- '/tmp/1970-01-03/eval/data'
Untuk mengambil dan mengolah data secara khusus pada tanggal 2 Januari 1970, kami melakukan hal berikut:
from tfx.components.example_gen import utils
input = proto.Input(splits=[
proto.Input.Split(name='train',
pattern='{YYYY}-{MM}-{DD}/train/*'),
proto.Input.Split(name='eval',
pattern='{YYYY}-{MM}-{DD}/eval/*')
])
# Specify date to be converted to span number to be processed using StaticRange.
span = utils.date_to_span_number(1970, 1, 2)
range = proto.RangeConfig(
static_range=range_config_pb2.StaticRange(
start_span_number=span, end_span_number=span)
)
# After substitution, the train and eval split patterns will be
# 'input_dir/1970-01-02/train/*' and 'input_dir/1970-01-02/eval/*',
# respectively.
example_gen = CsvExampleGen(input_base=input_dir, input_config=input,
range_config=range)
Contoh KhususGen
Jika komponen ContohGen yang tersedia saat ini tidak sesuai dengan kebutuhan Anda, Anda dapat membuat ContohGen kustom, yang memungkinkan Anda membaca dari sumber data berbeda atau dalam format data berbeda.
Kustomisasi ContohGen Berbasis File (Eksperimental)
Pertama, perluas BaseExampleGenExecutor dengan Beam PTransform khusus, yang menyediakan konversi dari pemisahan input pelatihan/eval Anda ke contoh TF. Misalnya, pelaksana CsvExampleGen menyediakan konversi dari pemisahan input CSV ke contoh TF.
Kemudian, buat komponen dengan eksekutor di atas, seperti yang dilakukan pada komponen CsvExampleGen . Alternatifnya, teruskan eksekutor khusus ke dalam komponen ContohGen standar seperti yang ditunjukkan di bawah ini.
from tfx.components.base import executor_spec
from tfx.components.example_gen.csv_example_gen import executor
example_gen = FileBasedExampleGen(
input_base=os.path.join(base_dir, 'data/simple'),
custom_executor_spec=executor_spec.ExecutorClassSpec(executor.Executor))
Sekarang, kami juga mendukung pembacaan file Avro dan Parket menggunakan metode ini.
Format Data Tambahan
Apache Beam mendukung pembacaan sejumlah format data tambahan . melalui Transformasi Beam I/O. Anda dapat membuat komponen ContohGen khusus dengan memanfaatkan Transformasi Beam I/O menggunakan pola yang mirip dengan contoh Avro
return (pipeline
| 'ReadFromAvro' >> beam.io.ReadFromAvro(avro_pattern)
| 'ToTFExample' >> beam.Map(utils.dict_to_example))
Saat tulisan ini dibuat, format dan sumber data yang saat ini didukung untuk Beam Python SDK meliputi:
- Amazon S3
- Apache Avro
- Apache Hadoop
- Apache Kafka
- Parket Apache
- Google Cloud BigQuery
- Tabel Besar Google Cloud
- Penyimpanan Data Google Cloud
- Pub/Sub Google Cloud
- Penyimpanan Google Cloud (GCS)
- MongoDB
Periksa dokumen Beam untuk daftar terbaru.
Kustomisasi Contoh Gen Berbasis Kueri (Eksperimental)
Pertama, perluas BaseExampleGenExecutor dengan Beam PTransform kustom, yang membaca dari sumber data eksternal. Kemudian, buat komponen sederhana dengan memperluas QueryBasedExampleGen.
Ini mungkin memerlukan konfigurasi koneksi tambahan atau tidak. Misalnya, pelaksana BigQuery membaca menggunakan konektor beam.io default, yang mengabstraksi detail konfigurasi koneksi. Pelaksana Presto , memerlukan Beam PTransform khusus dan protobuf konfigurasi koneksi khusus sebagai masukan.
Jika konfigurasi koneksi diperlukan untuk komponen SampleGen kustom, buat protobuf baru dan teruskan melalui custom_config, yang sekarang menjadi parameter eksekusi opsional. Di bawah ini adalah contoh cara menggunakan komponen yang dikonfigurasi.
from tfx.examples.custom_components.presto_example_gen.proto import presto_config_pb2
from tfx.examples.custom_components.presto_example_gen.presto_component.component import PrestoExampleGen
presto_config = presto_config_pb2.PrestoConnConfig(host='localhost', port=8080)
example_gen = PrestoExampleGen(presto_config, query='SELECT * FROM chicago_taxi_trips')
Komponen Hilir ContohGen
Konfigurasi pemisahan khusus didukung untuk komponen hilir.
StatistikGen
Perilaku defaultnya adalah melakukan pembuatan statistik untuk semua pemisahan.
Untuk mengecualikan pemisahan apa pun, setel exclude_splits untuk komponen StatisticsGen. Misalnya:
# Exclude the 'eval' split.
statistics_gen = StatisticsGen(
examples=example_gen.outputs['examples'],
exclude_splits=['eval'])
SkemaGen
Perilaku defaultnya adalah menghasilkan skema berdasarkan semua pemisahan.
Untuk mengecualikan pemisahan apa pun, setel exclude_splits untuk komponen SchemaGen. Misalnya:
# Exclude the 'eval' split.
schema_gen = SchemaGen(
statistics=statistics_gen.outputs['statistics'],
exclude_splits=['eval'])
ContohValidator
Perilaku defaultnya adalah memvalidasi statistik semua pemisahan pada contoh masukan terhadap suatu skema.
Untuk mengecualikan pemisahan apa pun, setel exclude_splits untuk komponen ContohValidator. Misalnya:
# Exclude the 'eval' split.
example_validator = ExampleValidator(
statistics=statistics_gen.outputs['statistics'],
schema=schema_gen.outputs['schema'],
exclude_splits=['eval'])
Mengubah
Perilaku default adalah menganalisis dan menghasilkan metadata dari pemisahan 'kereta' dan mengubah semua pemisahan.
Untuk menentukan pemisahan analisis dan pemisahan transformasi, atur splits_config untuk komponen Transform. Misalnya:
# Analyze the 'train' split and transform all splits.
transform = Transform(
examples=example_gen.outputs['examples'],
schema=schema_gen.outputs['schema'],
module_file=_taxi_module_file,
splits_config=proto.SplitsConfig(analyze=['train'],
transform=['train', 'eval']))
Pelatih dan Tuner
Perilaku defaultnya adalah melatih pada pemisahan 'kereta' dan mengevaluasi pada pemisahan 'eval'.
Untuk menentukan pemisahan kereta dan mengevaluasi pemisahan, atur train_args dan eval_args untuk komponen Trainer. Misalnya:
# Train on the 'train' split and evaluate on the 'eval' split.
Trainer = Trainer(
module_file=_taxi_module_file,
examples=transform.outputs['transformed_examples'],
schema=schema_gen.outputs['schema'],
transform_graph=transform.outputs['transform_graph'],
train_args=proto.TrainArgs(splits=['train'], num_steps=10000),
eval_args=proto.EvalArgs(splits=['eval'], num_steps=5000))
Penilai
Perilaku default adalah menyediakan metrik yang dihitung pada pemisahan 'eval'.
Untuk menghitung statistik evaluasi pada pemisahan khusus, atur example_splits untuk komponen Evaluator. Misalnya:
# Compute metrics on the 'eval1' split and the 'eval2' split.
evaluator = Evaluator(
examples=example_gen.outputs['examples'],
model=trainer.outputs['model'],
example_splits=['eval1', 'eval2'])
Detail selengkapnya tersedia di referensi API CsvExampleGen , implementasi API FileBasedExampleGen , dan referensi API ImportExampleGen .