
Xác thực dữ liệu TensorFlow (TFDV) có thể phân tích dữ liệu đào tạo và phục vụ cho:
tính toán thống kê mô tả,
suy ra một lược đồ ,
phát hiện sự bất thường của dữ liệu .
API cốt lõi hỗ trợ từng phần chức năng, với các phương thức tiện lợi được xây dựng trên cùng và có thể được gọi trong ngữ cảnh của sổ ghi chép.
Tính toán thống kê dữ liệu mô tả
TFDV có thể tính toán số liệu thống kê mô tả nhằm cung cấp cái nhìn tổng quan nhanh chóng về dữ liệu về các tính năng hiện có và hình dạng phân bổ giá trị của chúng. Các công cụ như Tổng quan về khía cạnh có thể cung cấp hình ảnh trực quan ngắn gọn về các số liệu thống kê này để dễ dàng duyệt qua.
Ví dụ: giả sử path đó trỏ đến một tệp ở định dạng TFRecord (chứa các bản ghi thuộc loại tensorflow.Example ). Đoạn mã sau minh họa việc tính toán số liệu thống kê bằng TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
Giá trị trả về là bộ đệm giao thức DatasetFeatureStatisticsList . Sổ tay ví dụ chứa hình ảnh trực quan về số liệu thống kê bằng cách sử dụng Tổng quan về các khía cạnh :
tfdv.visualize_statistics(stats)
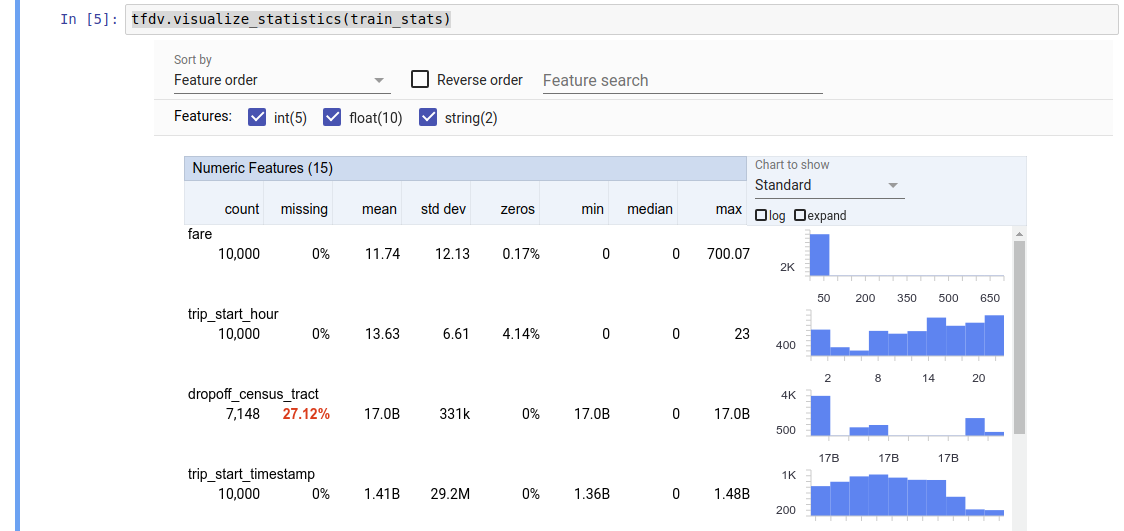
Ví dụ trước giả định rằng dữ liệu được lưu trữ trong tệp TFRecord . TFDV cũng hỗ trợ định dạng đầu vào CSV, có khả năng mở rộng cho các định dạng phổ biến khác. Bạn có thể tìm thấy các bộ giải mã dữ liệu có sẵn ở đây . Ngoài ra, TFDV còn cung cấp chức năng tiện ích tfdv.generate_statistics_from_dataframe cho người dùng có dữ liệu trong bộ nhớ được biểu thị dưới dạng DataFrame của gấu trúc.
Ngoài việc tính toán một tập hợp thống kê dữ liệu mặc định, TFDV còn có thể tính toán số liệu thống kê cho các miền ngữ nghĩa (ví dụ: hình ảnh, văn bản). Để kích hoạt tính toán thống kê miền ngữ nghĩa, hãy chuyển một đối tượng tfdv.StatsOptions với enable_semantic_domain_stats được đặt thành True thành tfdv.generate_statistics_from_tfrecord .
Chạy trên Google Cloud
Trong nội bộ, TFDV sử dụng khung xử lý song song dữ liệu của Apache Beam để mở rộng quy mô tính toán số liệu thống kê trên các tập dữ liệu lớn. Đối với các ứng dụng muốn tích hợp sâu hơn với TFDV (ví dụ: đính kèm việc tạo số liệu thống kê ở cuối quy trình tạo dữ liệu, tạo số liệu thống kê cho dữ liệu ở định dạng tùy chỉnh ), API cũng hiển thị Beam PTransform để tạo số liệu thống kê.
Để chạy TFDV trên Google Cloud, tệp bánh xe TFDV phải được tải xuống và cung cấp cho nhân viên Dataflow. Tải file bánh xe về thư mục hiện tại như sau:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
Đoạn mã sau đây hiển thị ví dụ về cách sử dụng TFDV trên Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
Trong trường hợp này, nguyên mẫu thống kê được tạo sẽ được lưu trữ trong tệp TFRecord được ghi vào GCS_STATS_OUTPUT_PATH .
LƯU Ý Khi gọi bất kỳ hàm tfdv.generate_statistics_... nào (ví dụ: tfdv.generate_statistics_from_tfrecord ) trên Google Cloud, bạn phải cung cấp output_path . Việc chỉ định Không có thể gây ra lỗi.
Suy ra một lược đồ trên dữ liệu
Lược đồ mô tả các thuộc tính dự kiến của dữ liệu. Một số thuộc tính này là:
- những tính năng nào được mong đợi sẽ có mặt
- kiểu của họ
- số lượng giá trị cho một tính năng trong mỗi ví dụ
- sự hiện diện của từng tính năng trên tất cả các ví dụ
- các miền tính năng dự kiến.
Nói tóm lại, lược đồ mô tả những kỳ vọng về dữ liệu "chính xác" và do đó có thể được sử dụng để phát hiện lỗi trong dữ liệu (được mô tả bên dưới). Hơn nữa, lược đồ tương tự có thể được sử dụng để thiết lập Biến đổi TensorFlow cho các chuyển đổi dữ liệu. Lưu ý rằng lược đồ dự kiến sẽ khá tĩnh, ví dụ: một số tập dữ liệu có thể tuân theo cùng một lược đồ, trong khi số liệu thống kê (được mô tả ở trên) có thể khác nhau tùy theo tập dữ liệu.
Vì việc viết một lược đồ có thể là một công việc tẻ nhạt, đặc biệt đối với các tập dữ liệu có nhiều tính năng, TFDV cung cấp một phương pháp để tạo phiên bản ban đầu của lược đồ dựa trên số liệu thống kê mô tả:
schema = tfdv.infer_schema(stats)
Nói chung, TFDV sử dụng phương pháp phỏng đoán thận trọng để suy ra các thuộc tính dữ liệu ổn định từ số liệu thống kê nhằm tránh việc trang bị quá mức lược đồ cho tập dữ liệu cụ thể. Chúng tôi khuyên bạn nên xem lại lược đồ được suy luận và tinh chỉnh nó nếu cần , để nắm bắt mọi kiến thức về miền dữ liệu mà phương pháp phỏng đoán của TFDV có thể đã bỏ sót.
Theo mặc định, tfdv.infer_schema suy ra hình dạng của từng tính năng bắt buộc, nếu value_count.min bằng value_count.max cho tính năng đó. Đặt đối số infer_feature_shape thành Sai để tắt suy luận hình dạng.
Bản thân lược đồ được lưu trữ dưới dạng bộ đệm giao thức Lược đồ và do đó có thể được cập nhật/chỉnh sửa bằng API bộ đệm giao thức tiêu chuẩn. TFDV cũng cung cấp một số phương pháp tiện ích để giúp việc cập nhật này dễ dàng hơn. Ví dụ: giả sử lược đồ chứa khổ thơ sau để mô tả tính năng chuỗi bắt buộc payment_type nhận một giá trị duy nhất:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Để đánh dấu rằng đối tượng địa lý phải được đưa vào ít nhất 50% số ví dụ:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
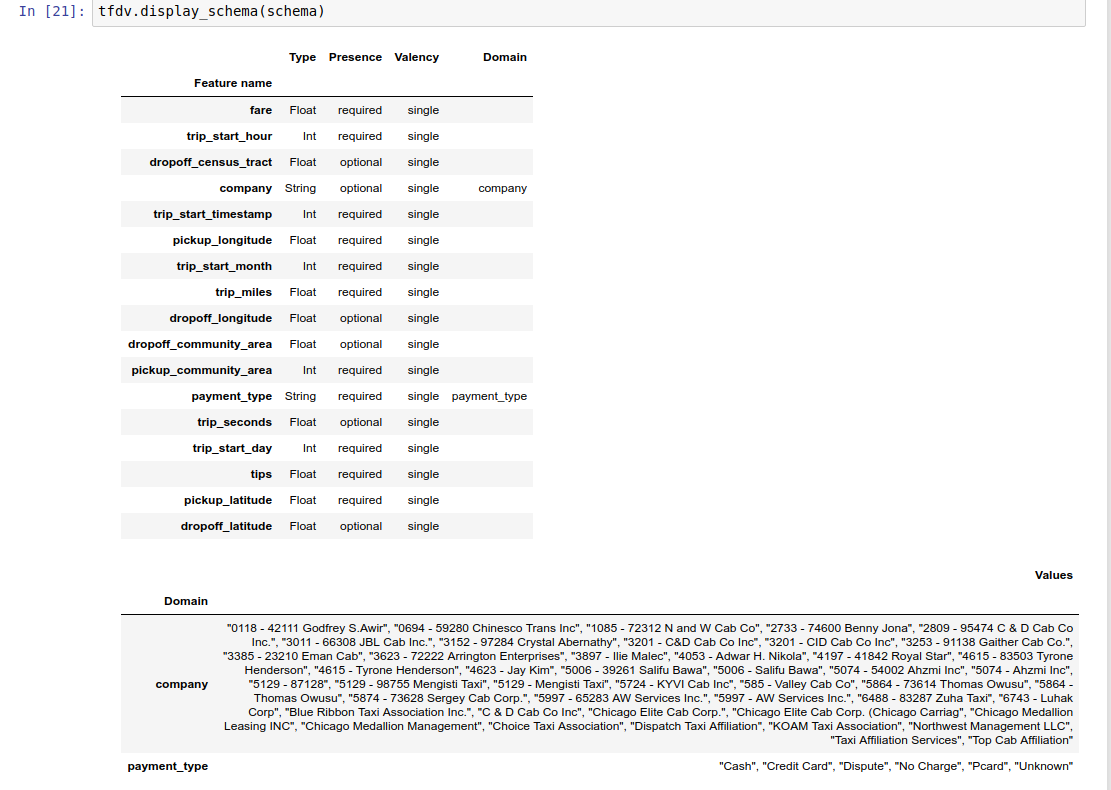
Sổ tay ví dụ chứa hình ảnh trực quan đơn giản về lược đồ dưới dạng bảng, liệt kê từng tính năng và các đặc điểm chính của nó như được mã hóa trong lược đồ.
Kiểm tra dữ liệu để tìm lỗi
Đưa ra một lược đồ, có thể kiểm tra xem tập dữ liệu có tuân thủ các kỳ vọng đặt ra trong lược đồ hay không hoặc liệu có tồn tại bất kỳ sự bất thường nào về dữ liệu hay không. Bạn có thể kiểm tra lỗi dữ liệu của mình (a) trong tổng hợp trên toàn bộ tập dữ liệu bằng cách đối chiếu số liệu thống kê của tập dữ liệu với lược đồ hoặc (b) bằng cách kiểm tra lỗi trên cơ sở từng ví dụ.
So khớp số liệu thống kê của tập dữ liệu với lược đồ
Để kiểm tra lỗi trong tổng hợp, TFDV khớp số liệu thống kê của tập dữ liệu với lược đồ và đánh dấu mọi khác biệt. Ví dụ:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
Kết quả là một phiên bản của bộ đệm giao thức bất thường và mô tả bất kỳ lỗi nào mà số liệu thống kê không phù hợp với lược đồ. Ví dụ: giả sử rằng dữ liệu tại other_path chứa các ví dụ có giá trị cho tính năng payment_type nằm ngoài miền được chỉ định trong lược đồ.
Điều này tạo ra sự bất thường
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
chỉ ra rằng giá trị ngoài miền đã được tìm thấy trong số liệu thống kê ở < 1% giá trị đối tượng địa lý.
Nếu điều này được mong đợi thì lược đồ có thể được cập nhật như sau:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Nếu sự bất thường thực sự chỉ ra lỗi dữ liệu thì dữ liệu cơ bản phải được sửa trước khi sử dụng cho mục đích đào tạo.
Các loại bất thường khác nhau có thể được phát hiện bởi mô-đun này được liệt kê ở đây .
Sổ tay ví dụ chứa hình ảnh trực quan đơn giản về các điểm bất thường dưới dạng bảng, liệt kê các tính năng phát hiện lỗi và mô tả ngắn gọn về từng lỗi.

Kiểm tra lỗi trên cơ sở từng ví dụ
TFDV cũng cung cấp tùy chọn xác thực dữ liệu trên cơ sở từng ví dụ, thay vì so sánh số liệu thống kê trên toàn tập dữ liệu với lược đồ. TFDV cung cấp các chức năng xác thực dữ liệu trên cơ sở từng mẫu và sau đó tạo số liệu thống kê tóm tắt cho các mẫu bất thường được tìm thấy. Ví dụ:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats mà validate_examples_in_tfrecord trả về là bộ đệm giao thức DatasetFeatureStatisticsList trong đó mỗi tập dữ liệu bao gồm tập hợp các ví dụ thể hiện một điểm bất thường cụ thể. Bạn có thể sử dụng điều này để xác định số lượng mẫu trong tập dữ liệu của mình có biểu hiện bất thường nhất định và đặc điểm của các mẫu đó.
Môi trường lược đồ
Theo mặc định, quá trình xác thực giả định rằng tất cả các tập dữ liệu trong một quy trình đều tuân theo một lược đồ duy nhất. Trong một số trường hợp, việc giới thiệu các biến thể lược đồ nhỏ là cần thiết, chẳng hạn như các tính năng được sử dụng làm nhãn là bắt buộc trong quá trình đào tạo (và phải được xác thực) nhưng lại bị thiếu trong quá trình cung cấp.
Môi trường có thể được sử dụng để thể hiện các yêu cầu như vậy. Cụ thể, các tính năng trong lược đồ có thể được liên kết với một tập hợp môi trường bằng cách sử dụng default_environment, in_environment và not_in_environment.
Ví dụ: nếu tính năng mẹo đang được sử dụng làm nhãn trong đào tạo nhưng bị thiếu trong dữ liệu cung cấp. Nếu không chỉ định môi trường, nó sẽ hiển thị dưới dạng bất thường.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Để khắc phục điều này, chúng ta cần đặt môi trường mặc định cho tất cả các tính năng là 'ĐÀO TẠO' và 'PHỤC VỤ', đồng thời loại trừ tính năng 'mẹo' khỏi môi trường PHỤC VỤ.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Kiểm tra độ lệch và trôi dữ liệu
Ngoài việc kiểm tra xem tập dữ liệu có tuân thủ các kỳ vọng đặt ra trong lược đồ hay không, TFDV còn cung cấp các chức năng để phát hiện:
- sai lệch giữa đào tạo và phục vụ dữ liệu
- trôi dạt giữa các ngày khác nhau của dữ liệu đào tạo
TFDV thực hiện kiểm tra này bằng cách so sánh số liệu thống kê của các bộ dữ liệu khác nhau dựa trên bộ so sánh độ lệch/độ lệch được chỉ định trong lược đồ. Ví dụ: để kiểm tra xem có bất kỳ sai lệch nào giữa tính năng 'Payment_type' trong tập dữ liệu đào tạo và phân phát hay không:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
LƯU Ý Định mức L-vô cực sẽ chỉ phát hiện độ lệch đối với các đặc điểm phân loại. Thay vì chỉ định ngưỡng infinity_norm , việc chỉ định ngưỡng jensen_shannon_divergence trong skew_comparator sẽ phát hiện độ lệch cho cả đặc điểm số và phân loại.
Tương tự như việc kiểm tra xem tập dữ liệu có tuân thủ các kỳ vọng đặt ra trong lược đồ hay không, kết quả cũng là một phiên bản của bộ đệm giao thức Bất thường và mô tả mọi sai lệch giữa tập dữ liệu huấn luyện và tập dữ liệu phục vụ. Ví dụ: giả sử dữ liệu phân phối chứa nhiều ví dụ hơn đáng kể với tính năng payement_type có giá trị Cash , điều này tạo ra sự bất thường về độ lệch
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Nếu sự bất thường thực sự chỉ ra sự sai lệch giữa dữ liệu đào tạo và cung cấp dữ liệu thì cần phải điều tra thêm vì điều này có thể có tác động trực tiếp đến hiệu suất của mô hình.
Sổ tay mẫu chứa một ví dụ đơn giản về việc kiểm tra các điểm bất thường dựa trên độ lệch.
Việc phát hiện sự trôi dạt giữa các ngày khác nhau của dữ liệu huấn luyện có thể được thực hiện theo cách tương tự
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
LƯU Ý Định mức L-vô cực sẽ chỉ phát hiện độ lệch cho các đặc điểm phân loại. Thay vì chỉ định ngưỡng infinity_norm , việc chỉ định ngưỡng jensen_shannon_divergence trong skew_comparator sẽ phát hiện độ lệch cho cả đặc điểm số và phân loại.
Viết trình kết nối dữ liệu tùy chỉnh
Để tính toán thống kê dữ liệu, TFDV cung cấp một số phương pháp thuận tiện để xử lý dữ liệu đầu vào ở nhiều định dạng khác nhau (ví dụ: TFRecord của tf.train.Example , CSV, v.v.). Nếu định dạng dữ liệu của bạn không có trong danh sách này, bạn cần viết trình kết nối dữ liệu tùy chỉnh để đọc dữ liệu đầu vào và kết nối nó với API lõi TFDV để tính toán thống kê dữ liệu.
API lõi TFDV để tính toán thống kê dữ liệu là một Beam PTransform lấy PCollection gồm các lô mẫu đầu vào (một loạt mẫu đầu vào được biểu diễn dưới dạng Arrow RecordBatch) và xuất ra một PCollection chứa một bộ đệm giao thức DatasetFeatureStatisticsList .
Sau khi triển khai trình kết nối dữ liệu tùy chỉnh để sắp xếp các mẫu đầu vào của bạn trong Arrow RecordBatch, bạn cần kết nối nó với API tfdv.GenerateStatistics để tính toán số liệu thống kê dữ liệu. Lấy TFRecord của tf.train.Example làm ví dụ. tfx_bsl cung cấp trình kết nối dữ liệu TFExampleRecord và bên dưới là ví dụ về cách kết nối nó với API tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Tính toán thống kê trên các lát dữ liệu
TFDV có thể được cấu hình để tính toán số liệu thống kê trên các lát dữ liệu. Có thể kích hoạt tính năng cắt bằng cách cung cấp các chức năng cắt có chứa Arrow RecordBatch và xuất ra một chuỗi các bộ dữ liệu có dạng (slice key, record batch) . TFDV cung cấp một cách dễ dàng để tạo các hàm cắt dựa trên giá trị tính năng có thể được cung cấp như một phần của tfdv.StatsOptions khi tính toán số liệu thống kê.
Khi tính năng cắt được bật, proto DatasetFeatureStatisticsList đầu ra chứa nhiều proto DatasetFeatureStatistics , một proto cho mỗi lát. Mỗi lát được xác định bằng một tên duy nhất được đặt làm tên tập dữ liệu trong nguyên mẫu DatasetFeatureStatistics . Theo mặc định, TFDV tính toán số liệu thống kê cho tập dữ liệu tổng thể bên cạnh các lát được định cấu hình.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])