
אימות נתונים של TensorFlow (TFDV) יכול לנתח נתוני הדרכה והגשה כדי:
לחשב סטטיסטיקה תיאורית,
להסיק סכימה ,
לזהות חריגות בנתונים .
ה-API הליבה תומך בכל חלק של פונקציונליות, עם שיטות נוחות שמתבססות על גבי וניתן לקרוא אותן בהקשר של מחברות.
מחשוב נתונים סטטיסטיים תיאוריים
TFDV יכול לחשב נתונים סטטיסטיים תיאוריים המספקים סקירה מהירה של הנתונים במונחים של התכונות הקיימות והצורות של התפלגויות הערך שלהן. כלים כגון Facets Overview יכולים לספק הדמיה תמציתית של נתונים סטטיסטיים אלה לגלישה קלה.
לדוגמה, נניח path מצביע על קובץ בפורמט TFRecord (המחזיק רשומות מסוג tensorflow.Example ). הקטע הבא ממחיש את חישוב הסטטיסטיקה באמצעות TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
הערך המוחזר הוא מאגר פרוטוקול DatasetFeatureStatisticsList . המחברת לדוגמה מכילה הדמיה של הנתונים הסטטיסטיים באמצעות סקירת היבטים :
tfdv.visualize_statistics(stats)
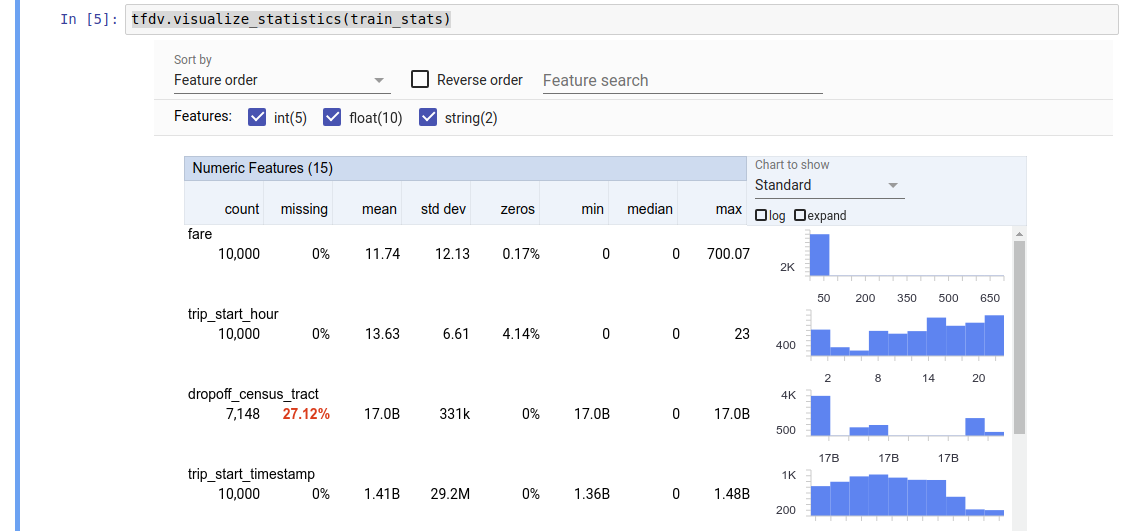
הדוגמה הקודמת מניחה שהנתונים מאוחסנים בקובץ TFRecord . TFDV תומך גם בפורמט קלט CSV, עם אפשרות הרחבה עבור פורמטים נפוצים אחרים. אתה יכול למצוא את מפענחי הנתונים הזמינים כאן . בנוסף, TFDV מספק את פונקציית השירות tfdv.generate_statistics_from_dataframe עבור משתמשים עם נתונים בזיכרון המיוצגים כ-Pandas DataFrame.
בנוסף לחישוב מערך ברירת מחדל של נתונים סטטיסטיים, TFDV יכול גם לחשב סטטיסטיקות עבור תחומים סמנטיים (למשל, תמונות, טקסט). כדי לאפשר חישוב של סטטיסטיקות תחום סמנטי, העבר אובייקט tfdv.StatsOptions כאשר enable_semantic_domain_stats מוגדר כ-True to tfdv.generate_statistics_from_tfrecord .
פועל על Google Cloud
באופן פנימי, TFDV משתמש במסגרת עיבוד הנתונים המקבילה של Apache Beam כדי להתאים את חישוב הנתונים הסטטיסטיים על פני מערכי נתונים גדולים. עבור יישומים המעוניינים להשתלב עמוק יותר עם TFDV (לדוגמה, צרף יצירת סטטיסטיקה בסוף צינור יצירת נתונים, הפקת נתונים סטטיסטיים בפורמט מותאם אישית ), ה-API חושף גם Beam PTransform ליצירת סטטיסטיקות.
כדי להפעיל את TFDV ב-Google Cloud, יש להוריד את קובץ הגלגל TFDV ולספק אותו לעובדי Dataflow. הורד את קובץ הגלגל לספרייה הנוכחית באופן הבא:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
הקטע הבא מציג דוגמה לשימוש ב-TFDV ב-Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
במקרה זה, פרוטו הסטטיסטיקה שנוצר מאוחסן בקובץ TFRecord שנכתב אל GCS_STATS_OUTPUT_PATH .
הערה בעת קריאה לכל אחת מהפונקציות tfdv.generate_statistics_... (למשל, tfdv.generate_statistics_from_tfrecord ) ב-Google Cloud, עליך לספק output_path . ציון None עלול לגרום לשגיאה.
הסקת סכימה על הנתונים
הסכימה מתארת את המאפיינים הצפויים של הנתונים. חלק מהנכסים הללו הם:
- אילו תכונות צפויות להיות נוכחות
- הסוג שלהם
- מספר הערכים עבור תכונה בכל דוגמה
- הנוכחות של כל תכונה בכל הדוגמאות
- התחומים הצפויים של תכונות.
בקיצור, הסכימה מתארת את הציפיות לנתונים "נכונים" ובכך ניתן להשתמש בה כדי לזהות שגיאות בנתונים (מתוארים להלן). יתר על כן, ניתן להשתמש באותה סכמה להגדרת TensorFlow Transform עבור טרנספורמציות נתונים. שים לב שהסכימה צפויה להיות סטטית למדי, למשל, מספר מערכי נתונים יכולים להתאים לאותה סכימה, בעוד שהסטטיסטיקה (מתוארת לעיל) יכולה להשתנות לכל מערך נתונים.
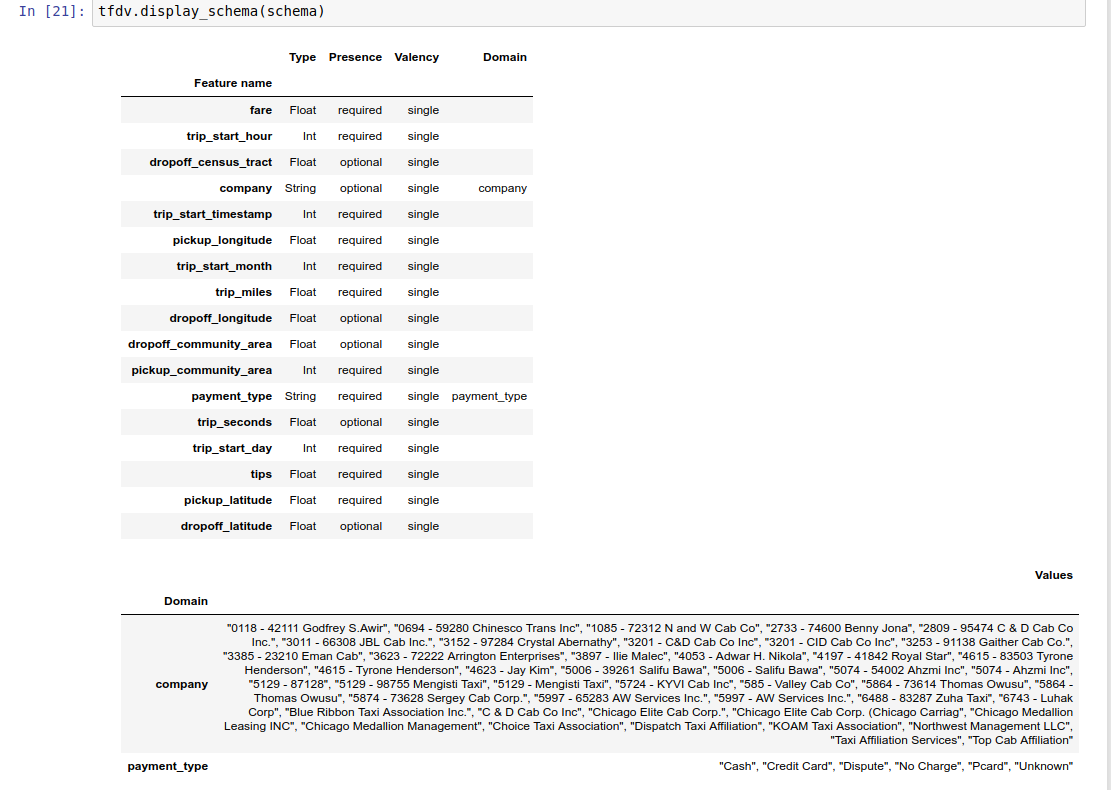
מכיוון שכתיבת סכימה יכולה להיות משימה מייגעת, במיוחד עבור מערכי נתונים עם הרבה תכונות, TFDV מספק שיטה ליצור גרסה ראשונית של הסכימה על סמך הנתונים הסטטיסטיים התיאוריים:
schema = tfdv.infer_schema(stats)
באופן כללי, TFDV משתמש בהיוריסטיקה שמרנית כדי להסיק מהסטטיסטיקה מאפייני נתונים יציבים על מנת למנוע התאמה יתר של הסכימה למערך הנתונים הספציפי. מומלץ מאוד לסקור את הסכימה המשוערת ולחדד אותה לפי הצורך , כדי ללכוד כל ידע בתחום לגבי הנתונים שהיוריסטיקה של TFDV עשויה להחמיץ.
כברירת מחדל, tfdv.infer_schema מסיק את הצורה של כל תכונה נדרשת, אם value_count.min שווה ל- value_count.max עבור התכונה. הגדר את הארגומנט infer_feature_shape ל-false כדי להשבית את הסקת הצורה.
הסכימה עצמה מאוחסנת כמאגר פרוטוקול Schema ולכן ניתן לעדכן/לערוך אותה באמצעות ה-API הסטנדרטי של פרוטוקול-buffer. TFDV מספק גם כמה שיטות שירות כדי להקל על העדכונים הללו. לדוגמה, נניח שהסכימה מכילה את הבית הבא לתיאור תכונת מחרוזת נדרשת payment_type שלוקחת ערך בודד:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
כדי לציין שהפיצ'ר צריך להיות מאוכלס ב-50% לפחות מהדוגמאות:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
המחברת לדוגמה מכילה הדמיה פשוטה של הסכימה כטבלה, המפרטת כל תכונה והמאפיינים העיקריים שלה כפי שמקודדים בסכימה.
בדיקת הנתונים לאיתור שגיאות
בהינתן סכימה, ניתן לבדוק אם מערך נתונים תואם את הציפיות שנקבעו בסכימה או אם קיימות חריגות נתונים . אתה יכול לבדוק את הנתונים שלך עבור שגיאות (א) במצטבר על פני מערך נתונים שלם על ידי התאמת הנתונים הסטטיסטיים של מערך הנתונים לסכימה, או (ב) על ידי בדיקת שגיאות על בסיס דוגמה.
התאמת הנתונים הסטטיסטיים של מערך הנתונים לסכימה
כדי לבדוק אם יש שגיאות במצטבר, TFDV מתאים את הנתונים הסטטיסטיים של מערך הנתונים מול הסכימה ומסמן אי-התאמות כלשהן. לְדוּגמָה:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
התוצאה היא מופע של מאגר הפרוטוקול Anomalies ומתאר שגיאות שבהן הסטטיסטיקה אינה תואמת את הסכימה. לדוגמה, נניח שהנתונים ב- other_path מכילים דוגמאות עם ערכים עבור התכונה payment_type מחוץ לדומיין שצוין בסכימה.
זה מייצר אנומליה
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
מה שמצביע על כך שנמצא ערך מחוץ לתחום בסטטיסטיקה בפחות מ-1% מערכי התכונה.
אם זה היה צפוי, ניתן לעדכן את הסכימה באופן הבא:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
אם האנומליה באמת מצביעה על שגיאת נתונים, יש לתקן את הנתונים הבסיסיים לפני השימוש בהם לאימון.
סוגי האנומליות השונים שניתן לזהות על ידי מודול זה מפורטים כאן .
המחברת לדוגמה מכילה הדמיה פשוטה של החריגות כטבלה, המפרטת את התכונות שבהן מתגלות שגיאות ותיאור קצר של כל שגיאה.

בדיקת שגיאות על בסיס דוגמה
TFDV מספקת גם את האפשרות לאמת נתונים על בסיס דוגמה, במקום להשוות נתונים סטטיסטיים בכל מערך הנתונים מול הסכימה. TFDV מספק פונקציות לאימות נתונים על בסיס דוגמה ולאחר מכן יצירת סטטיסטיקות סיכום עבור הדוגמאות החריגות שנמצאו. לְדוּגמָה:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
ה- anomalous_example_stats שמחזיר validate_examples_in_tfrecord הוא מאגר פרוטוקול DatasetFeatureStatisticsList שבו כל מערך נתונים מורכב מקבוצת הדוגמאות המציגות אנומליה מסוימת. אתה יכול להשתמש בזה כדי לקבוע את מספר הדוגמאות במערך הנתונים שלך שמציגות אנומליה נתונה ואת המאפיינים של דוגמאות אלו.
סביבות סכימה
כברירת מחדל, אימותים מניחים שכל מערכי הנתונים בצנרת דבקים בסכימה אחת. במקרים מסוימים יש צורך להציג שינויים קלים בסכימה, למשל תכונות המשמשות כתוויות נדרשות במהלך ההדרכה (וצריך לאמתן), אך הן חסרות במהלך ההגשה.
ניתן להשתמש בסביבות כדי לבטא דרישות כאלה. בפרט, ניתן לשייך תכונות בסכימה לקבוצה של סביבות המשתמשות ב-default_environment, in_environment ו-not_in_environment.
לדוגמה, אם תכונת הטיפים משמשת כתווית בהדרכה, אך חסרה בנתוני ההגשה. ללא ציון סביבה, זה יופיע כאנומליה.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

כדי לתקן זאת, עלינו להגדיר את סביבת ברירת המחדל עבור כל התכונות להיות גם 'TRAINING' וגם 'SERVING', ולא לכלול את תכונת ה'טיפים' מסביבת SERVING.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
בדיקת הטיית נתונים וסחיפה
בנוסף לבדיקה האם מערך נתונים תואם את הציפיות שנקבעו בסכימה, TFDV מספק גם פונקציונליות לזיהוי:
- הטיה בין נתוני אימון להגשה
- להיסחף בין ימי אימון שונים
TFDV מבצע בדיקה זו על ידי השוואת הנתונים הסטטיסטיים של מערכי נתונים שונים בהתבסס על השוואות הסחף/הטייה שצוינו בסכימה. לדוגמה, כדי לבדוק אם יש הטיה בין התכונה 'סוג_תשלום' בתוך מערך ההדרכה וההגשה:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
הערה נורמה L-אינסוף תזהה רק הטיה עבור המאפיינים הקטגוריים. במקום לציין סף infinity_norm , ציון סף jensen_shannon_divergence ב- skew_comparator יזהה הטיה הן עבור תכונות מספריות והן עבור תכונות קטגוריות.
בדומה לבדיקה אם מערך נתונים תואם את הציפיות שנקבעו בסכימה, התוצאה היא גם מופע של מאגר הפרוטוקול Anomalies ומתארת כל הטיה בין מערכי ההדרכה וההגשה. לדוגמה, נניח שנתוני ההגשה מכילים הרבה יותר דוגמאות עם תכונה payement_type בעלת ערך Cash , הדבר מייצר חריגה מוטה
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
אם האנומליה באמת מצביעה על הטיה בין נתוני ההדרכה וההגשה, יש צורך בחקירה נוספת שכן לכך עשויה להיות השפעה ישירה על ביצועי המודל.
המחברת לדוגמה מכילה דוגמה פשוטה לבדיקת חריגות המבוססות על הטיה.
זיהוי סחיפה בין ימי אימון שונים יכול להתבצע בצורה דומה
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
הערה נורמה L-אינסוף תזהה רק הטיה עבור המאפיינים הקטגוריים. במקום לציין סף infinity_norm , ציון סף jensen_shannon_divergence ב- skew_comparator יזהה הטיה הן עבור תכונות מספריות והן עבור תכונות קטגוריות.
כתיבת מחבר נתונים מותאם אישית
כדי לחשב נתונים סטטיסטיים, TFDV מספק מספר שיטות נוחות לטיפול בנתוני קלט בפורמטים שונים (למשל TFRecord של tf.train.Example , CSV וכו'). אם פורמט הנתונים שלך אינו ברשימה זו, עליך לכתוב מחבר נתונים מותאם אישית לקריאת נתוני קלט, ולחבר אותו ל-API הליבה של TFDV למחשוב נתונים סטטיסטיים.
ממשק API הליבה של TFDV למחשוב נתונים סטטיסטיים הוא Beam PTransform שלוקח PCollection של אצווה של דוגמאות קלט (אצווה של דוגמאות קלט מיוצגת כ- Arrow RecordBatch), ומוציא PCollection המכיל מאגר פרוטוקול DatasetFeatureStatisticsList יחיד.
לאחר שיישמת את מחבר הנתונים המותאם אישית שמקבץ את דוגמאות הקלט שלך ב-Arrow RecordBatch, עליך לחבר אותו עם ה-API של tfdv.GenerateStatistics לחישוב הנתונים הסטטיסטיים. קח לדוגמא TFRecord של tf.train.Example . tfx_bsl מספק את מחבר הנתונים TFExampleRecord , ולהלן דוגמה כיצד לחבר אותו עם ה-API של tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
סטטיסטיקות מחשוב על פני פרוסות נתונים
ניתן להגדיר את TFDV כדי לחשב נתונים סטטיסטיים על פני פרוסות נתונים. ניתן להפעיל חיתוך על-ידי מתן פונקציות חיתוך המקבלות Arrow RecordBatch ומוציאות רצף של טופלים של טופס (slice key, record batch) . TFDV מספק דרך קלה ליצור פונקציות חיתוך מבוססות ערכי תכונה שניתן לספק כחלק מ- tfdv.StatsOptions בעת מחשוב סטטיסטיקה.
כאשר חיתוך מופעל, פרוטו הפלט DatasetFeatureStatisticsList מכיל פרוטו מרובים של DatasetFeatureStatistics , אחד לכל פרוסה. כל פרוסה מזוהה על ידי שם ייחודי המוגדר כשם מערך הנתונים בפרוטו DatasetFeatureStatistics . כברירת מחדל, TFDV מחשב נתונים סטטיסטיים עבור מערך הנתונים הכולל בנוסף לפרוסות המוגדרות.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])