
TensorFlow Data Validation (TFDV) peut analyser les données de formation et de diffusion pour :
calculer des statistiques descriptives,
déduire un schéma ,
détecter les anomalies de données .
L'API principale prend en charge chaque élément de fonctionnalité, avec des méthodes pratiques qui s'appuient sur celles-ci et peuvent être appelées dans le contexte de blocs-notes.
Calcul de statistiques de données descriptives
TFDV peut calculer des statistiques descriptives qui fournissent un aperçu rapide des données en termes de caractéristiques présentes et de formes de leurs distributions de valeurs. Des outils tels que Facets Overview peuvent fournir une visualisation succincte de ces statistiques pour une navigation facile.
Par exemple, supposons que ce path pointe vers un fichier au format TFRecord (qui contient des enregistrements de type tensorflow.Example ). L'extrait suivant illustre le calcul des statistiques à l'aide de TFDV :
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
La valeur renvoyée est un tampon de protocole DatasetFeatureStatisticsList . L' exemple de notebook contient une visualisation des statistiques à l'aide de Facets Overview :
tfdv.visualize_statistics(stats)
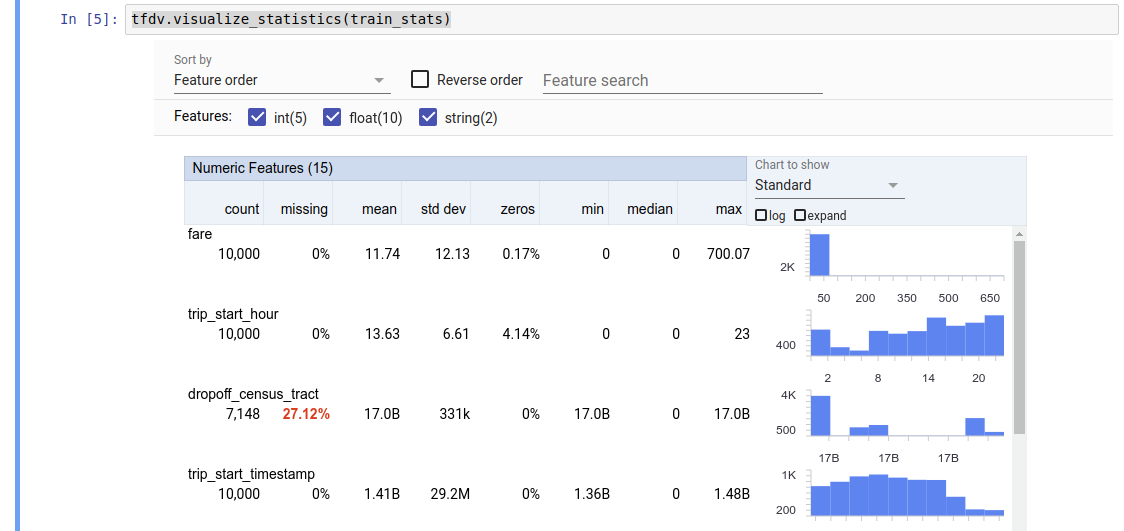
L'exemple précédent suppose que les données sont stockées dans un fichier TFRecord . TFDV prend également en charge le format d'entrée CSV, avec extensibilité pour d'autres formats courants. Vous pouvez trouver les décodeurs de données disponibles ici . De plus, TFDV fournit la fonction utilitaire tfdv.generate_statistics_from_dataframe pour les utilisateurs dont les données en mémoire sont représentées sous la forme d'un DataFrame pandas.
En plus de calculer un ensemble de statistiques de données par défaut, TFDV peut également calculer des statistiques pour des domaines sémantiques (par exemple, images, texte). Pour activer le calcul des statistiques du domaine sémantique, transmettez un objet tfdv.StatsOptions avec enable_semantic_domain_stats défini sur True à tfdv.generate_statistics_from_tfrecord .
Exécution sur Google Cloud
En interne, TFDV utilise le cadre de traitement parallèle des données d' Apache Beam pour faire évoluer le calcul des statistiques sur de grands ensembles de données. Pour les applications qui souhaitent s'intégrer plus profondément à TFDV (par exemple, attacher la génération de statistiques à la fin d'un pipeline de génération de données, générer des statistiques pour les données dans un format personnalisé ), l'API expose également un Beam PTransform pour la génération de statistiques.
Pour exécuter TFDV sur Google Cloud, le fichier de roue TFDV doit être téléchargé et fourni aux nœuds de calcul Dataflow. Téléchargez le fichier wheel dans le répertoire actuel comme suit :
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
L'extrait suivant montre un exemple d'utilisation de TFDV sur Google Cloud :
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
Dans ce cas, le prototype de statistiques généré est stocké dans un fichier TFRecord écrit dans GCS_STATS_OUTPUT_PATH .
REMARQUE Lorsque vous appelez l'une des fonctions tfdv.generate_statistics_... (par exemple, tfdv.generate_statistics_from_tfrecord ) sur Google Cloud, vous devez fournir un output_path . Spécifier Aucun peut provoquer une erreur.
Déduire un schéma sur les données
Le schéma décrit les propriétés attendues des données. Certaines de ces propriétés sont :
- quelles fonctionnalités devraient être présentes
- leur type
- le nombre de valeurs pour une fonctionnalité dans chaque exemple
- la présence de chaque fonctionnalité dans tous les exemples
- les domaines de fonctionnalités attendus.
En bref, le schéma décrit les attentes concernant les données « correctes » et peut ainsi être utilisé pour détecter les erreurs dans les données (décrites ci-dessous). De plus, le même schéma peut être utilisé pour configurer TensorFlow Transform pour les transformations de données. Notez que le schéma est censé être assez statique, par exemple, plusieurs ensembles de données peuvent se conformer au même schéma, alors que les statistiques (décrites ci-dessus) peuvent varier selon l'ensemble de données.
Étant donné que l'écriture d'un schéma peut être une tâche fastidieuse, en particulier pour les ensembles de données comportant de nombreuses fonctionnalités, TFDV fournit une méthode pour générer une version initiale du schéma basée sur les statistiques descriptives :
schema = tfdv.infer_schema(stats)
En général, TFDV utilise des heuristiques conservatrices pour déduire des propriétés de données stables à partir des statistiques afin d'éviter un surajustement du schéma à l'ensemble de données spécifique. Il est fortement conseillé de revoir le schéma déduit et de l'affiner si nécessaire , pour capturer toute connaissance du domaine sur les données que l'heuristique de TFDV aurait pu manquer.
Par défaut, tfdv.infer_schema déduit la forme de chaque fonctionnalité requise, si value_count.min est égal à value_count.max pour la fonctionnalité. Définissez l’argument infer_feature_shape sur False pour désactiver l’inférence de forme.
Le schéma lui-même est stocké en tant que tampon de protocole de schéma et peut ainsi être mis à jour/modifié à l'aide de l'API standard de tampon de protocole. TFDV fournit également quelques méthodes utilitaires pour faciliter ces mises à jour. Par exemple, supposons que le schéma contienne la strophe suivante pour décrire une fonctionnalité de chaîne requise payment_type qui prend une seule valeur :
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Pour indiquer que la fonctionnalité doit être renseignée dans au moins 50 % des exemples :
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
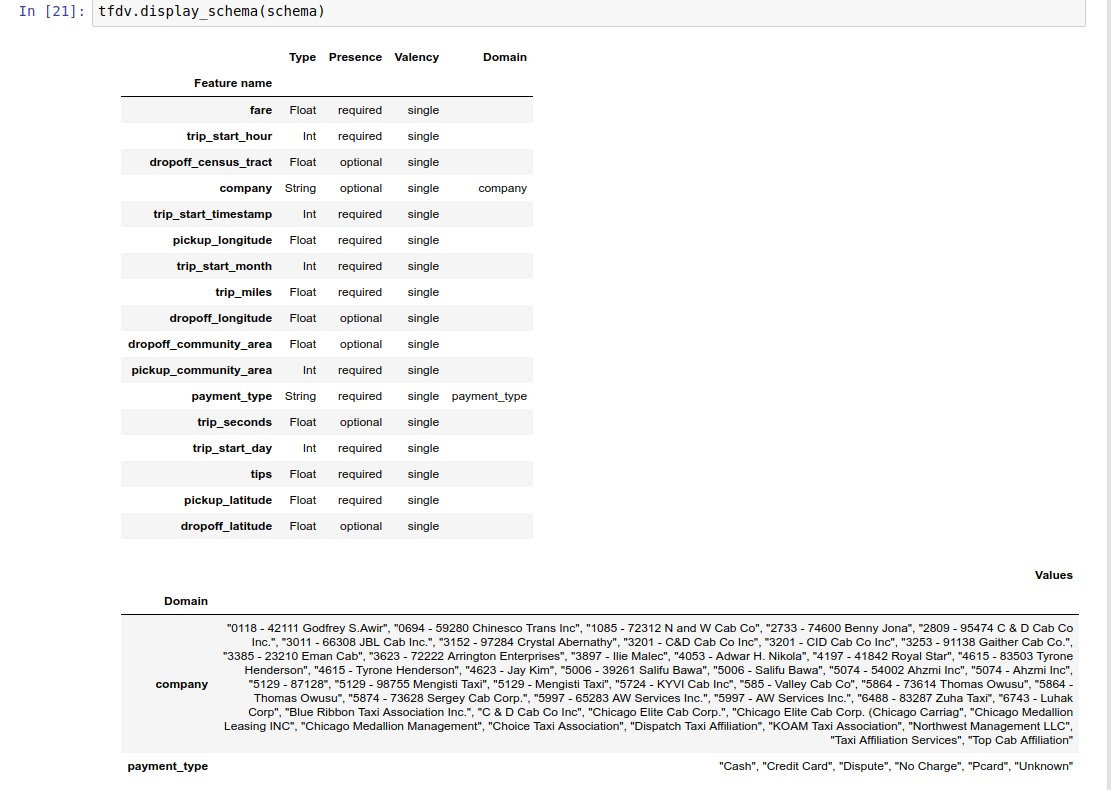
L' exemple de bloc-notes contient une visualisation simple du schéma sous forme de tableau, répertoriant chaque fonctionnalité et ses principales caractéristiques telles qu'encodées dans le schéma.
Vérification des données pour les erreurs
Étant donné un schéma, il est possible de vérifier si un ensemble de données est conforme aux attentes définies dans le schéma ou s'il existe des anomalies dans les données . Vous pouvez vérifier vos données pour détecter les erreurs (a) dans l'ensemble d'un ensemble de données entier en faisant correspondre les statistiques de l'ensemble de données avec le schéma, ou (b) en vérifiant les erreurs par exemple.
Faire correspondre les statistiques de l'ensemble de données avec un schéma
Pour vérifier les erreurs dans l'agrégat, TFDV compare les statistiques de l'ensemble de données au schéma et marque toute divergence. Par exemple:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
Le résultat est une instance du tampon de protocole Anomalies et décrit toutes les erreurs pour lesquelles les statistiques ne correspondent pas au schéma. Par exemple, supposons que les données sur other_path contiennent des exemples avec des valeurs pour la fonctionnalité payment_type en dehors du domaine spécifié dans le schéma.
Cela produit une anomalie
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
indiquant qu'une valeur hors domaine a été trouvée dans les statistiques dans < 1 % des valeurs des fonctionnalités.
Si cela était attendu, le schéma peut être mis à jour comme suit :
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Si l'anomalie indique réellement une erreur de données, les données sous-jacentes doivent être corrigées avant de les utiliser pour la formation.
Les différents types d'anomalies pouvant être détectées par ce module sont répertoriés ici .
L' exemple de cahier contient une visualisation simple des anomalies sous forme de tableau, répertoriant les fonctionnalités où des erreurs sont détectées et une brève description de chaque erreur.

Vérification des erreurs par exemple
TFDV offre également la possibilité de valider les données par exemple, au lieu de comparer les statistiques à l'échelle de l'ensemble de données avec le schéma. TFDV fournit des fonctions permettant de valider les données par exemple, puis de générer des statistiques récapitulatives pour les exemples anormaux trouvés. Par exemple:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
Le anomalous_example_stats renvoyé par validate_examples_in_tfrecord est un tampon de protocole DatasetFeatureStatisticsList dans lequel chaque ensemble de données est constitué de l'ensemble d'exemples qui présentent une anomalie particulière. Vous pouvez l'utiliser pour déterminer le nombre d'exemples de votre ensemble de données qui présentent une anomalie donnée et les caractéristiques de ces exemples.
Environnements de schéma
Par défaut, les validations supposent que tous les ensembles de données d'un pipeline adhèrent à un seul schéma. Dans certains cas, l'introduction de légères variations de schéma est nécessaire, par exemple les fonctionnalités utilisées comme étiquettes sont requises lors de la formation (et doivent être validées), mais sont manquantes lors de la diffusion.
Les environnements peuvent être utilisés pour exprimer de telles exigences. En particulier, les fonctionnalités du schéma peuvent être associées à un ensemble d'environnements en utilisant default_environment, in_environment et not_in_environment.
Par exemple, si la fonctionnalité de conseils est utilisée comme étiquette dans la formation, mais est manquante dans les données de diffusion. Sans environnement spécifié, cela apparaîtra comme une anomalie.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Pour résoudre ce problème, nous devons définir l'environnement par défaut pour toutes les fonctionnalités sur « FORMATION » et « SERVING », et exclure la fonctionnalité « conseils » de l'environnement SERVING.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Vérification de l'asymétrie et de la dérive des données
En plus de vérifier si un ensemble de données est conforme aux attentes définies dans le schéma, TFDV fournit également des fonctionnalités pour détecter :
- décalage entre la formation et la diffusion des données
- dérive entre différents jours de données d'entraînement
TFDV effectue cette vérification en comparant les statistiques de différents ensembles de données en fonction des comparateurs de dérive/inclinaison spécifiés dans le schéma. Par exemple, pour vérifier s'il existe un écart entre la fonctionnalité « payment_type » dans l'ensemble de données de formation et de diffusion :
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
REMARQUE La norme L-infini détectera uniquement les biais pour les caractéristiques catégorielles. Au lieu de spécifier un seuil infinity_norm , la spécification d'un seuil jensen_shannon_divergence dans skew_comparator détecterait l'asymétrie pour les caractéristiques numériques et catégorielles.
De même pour vérifier si un ensemble de données est conforme aux attentes définies dans le schéma, le résultat est également une instance du tampon de protocole Anomalies et décrit tout écart entre les ensembles de données de formation et de service. Par exemple, supposons que les données de diffusion contiennent beaucoup plus d'exemples avec la fonctionnalité payement_type ayant la valeur Cash , cela produit une anomalie asymétrique.
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Si l'anomalie indique réellement un écart entre les données de formation et de diffusion, une enquête plus approfondie est nécessaire car cela pourrait avoir un impact direct sur les performances du modèle.
L' exemple de bloc-notes contient un exemple simple de vérification des anomalies basées sur les biais.
La détection de la dérive entre les différents jours de données d'entraînement peut être effectuée de la même manière
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
REMARQUE La norme L-infini détectera uniquement les biais pour les caractéristiques catégorielles. Au lieu de spécifier un seuil infinity_norm , la spécification d'un seuil jensen_shannon_divergence dans skew_comparator détecterait l'asymétrie pour les caractéristiques numériques et catégorielles.
Écriture d'un connecteur de données personnalisé
Pour calculer les statistiques des données, TFDV fournit plusieurs méthodes pratiques pour gérer les données d'entrée dans différents formats (par exemple TFRecord de tf.train.Example , CSV, etc.). Si votre format de données ne figure pas dans cette liste, vous devez écrire un connecteur de données personnalisé pour lire les données d'entrée et le connecter à l'API principale de TFDV pour calculer les statistiques de données.
L' API principale de TFDV pour le calcul des statistiques de données est un Beam PTransform qui prend une PCollection de lots d'exemples d'entrée (un lot d'exemples d'entrée est représenté sous la forme d'un Arrow RecordBatch) et génère une PCollection contenant un seul tampon de protocole DatasetFeatureStatisticsList .
Une fois que vous avez implémenté le connecteur de données personnalisé qui regroupe vos exemples d'entrée dans un Arrow RecordBatch, vous devez le connecter à l'API tfdv.GenerateStatistics pour calculer les statistiques de données. Prenez TFRecord de tf.train.Example par exemple. tfx_bsl fournit le connecteur de données TFExampleRecord et vous trouverez ci-dessous un exemple de la façon de le connecter à l'API tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Calcul de statistiques sur des tranches de données
TFDV peut être configuré pour calculer des statistiques sur des tranches de données. Le découpage peut être activé en fournissant des fonctions de découpage qui intègrent un Arrow RecordBatch et génèrent une séquence de tuples de forme (slice key, record batch) . TFDV fournit un moyen simple de générer des fonctions de découpage basées sur la valeur des caractéristiques qui peuvent être fournies dans le cadre de tfdv.StatsOptions lors du calcul des statistiques.
Lorsque le découpage est activé, le proto DatasetFeatureStatisticsList de sortie contient plusieurs protos DatasetFeatureStatistics , un pour chaque tranche. Chaque tranche est identifiée par un nom unique qui est défini comme nom de l'ensemble de données dans le proto DatasetFeatureStatistics . Par défaut, TFDV calcule des statistiques pour l'ensemble de données global en plus des tranches configurées.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])