
يمكن لبرنامج TensorFlow Data Validation (TFDV) تحليل بيانات التدريب وتقديمها من أجل:
حساب الإحصاء الوصفي,
استنتاج مخطط ،
الكشف عن الشذوذ في البيانات .
تدعم واجهة برمجة التطبيقات الأساسية كل جزء من الوظائف، مع أساليب ملائمة يتم بناؤها في الأعلى ويمكن استدعاؤها في سياق أجهزة الكمبيوتر المحمولة.
حساب إحصائيات البيانات الوصفية
يمكن لـ TFDV حساب الإحصائيات الوصفية التي توفر نظرة عامة سريعة على البيانات من حيث الميزات الموجودة وأشكال توزيعات قيمتها. يمكن لأدوات مثل Facets Overview أن توفر تصورًا موجزًا لهذه الإحصائيات لتسهيل التصفح.
على سبيل المثال، لنفترض أن هذا path يشير إلى ملف بتنسيق TFRecord (الذي يحتفظ بسجلات من النوع tensorflow.Example ). يوضح المقتطف التالي حساب الإحصائيات باستخدام TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
القيمة التي تم إرجاعها هي مخزن مؤقت لبروتوكول DatasetFeatureStatisticsList . يحتوي مثال دفتر الملاحظات على تصور للإحصائيات باستخدام نظرة عامة على الأوجه :
tfdv.visualize_statistics(stats)
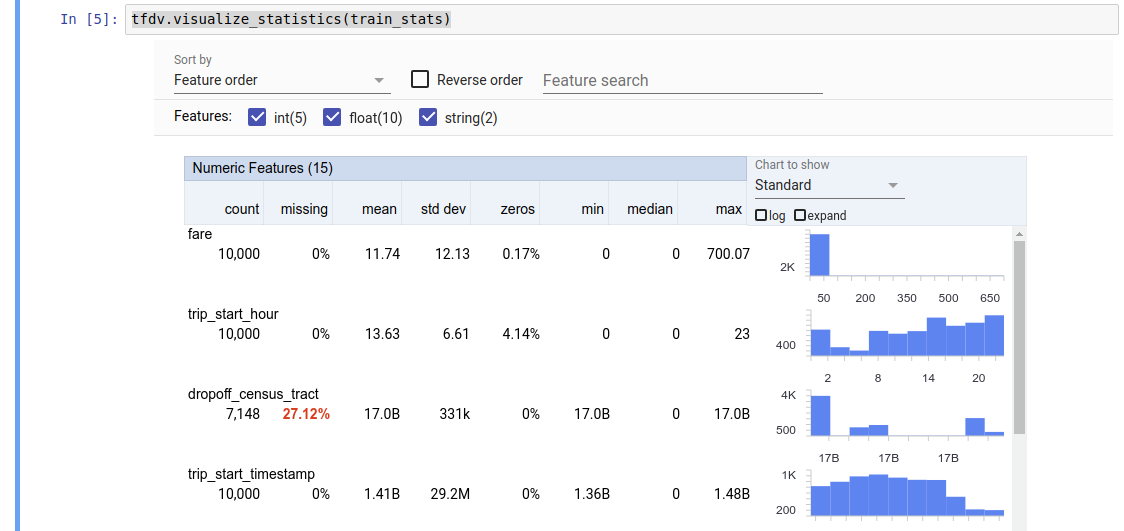
يفترض المثال السابق أن البيانات مخزنة في ملف TFRecord . يدعم TFDV أيضًا تنسيق إدخال CSV، مع إمكانية التوسعة للتنسيقات الشائعة الأخرى. يمكنك العثور على أجهزة فك ترميز البيانات المتوفرة هنا . بالإضافة إلى ذلك، يوفر TFDV وظيفة الأداة المساعدة tfdv.generate_statistics_from_dataframe للمستخدمين الذين لديهم بيانات في الذاكرة ممثلة في صورة pandas DataFrame.
بالإضافة إلى حساب مجموعة افتراضية من إحصائيات البيانات، يمكن لـ TFDV أيضًا حساب إحصائيات المجالات الدلالية (مثل الصور والنص). لتمكين حساب إحصائيات المجال الدلالي، قم بتمرير كائن tfdv.StatsOptions مع تعيين enable_semantic_domain_stats على True إلى tfdv.generate_statistics_from_tfrecord .
يعمل على جوجل كلاود
داخليًا، يستخدم TFDV إطار المعالجة المتوازية للبيانات الخاص بـ Apache Beam لتوسيع نطاق حساب الإحصائيات عبر مجموعات البيانات الكبيرة. بالنسبة للتطبيقات التي ترغب في التكامل بشكل أعمق مع TFDV (على سبيل المثال، إرفاق إنشاء الإحصائيات في نهاية خط أنابيب إنشاء البيانات، وإنشاء إحصائيات للبيانات بتنسيق مخصص )، تعرض واجهة برمجة التطبيقات (API) أيضًا Beam PTransform لإنشاء الإحصائيات.
لتشغيل TFDV على Google Cloud، يجب تنزيل ملف عجلة TFDV وتقديمه إلى العاملين في Dataflow. قم بتنزيل ملف العجلة إلى الدليل الحالي كما يلي:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
يعرض المقتطف التالي مثالاً لاستخدام TFDV على Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
في هذه الحالة، يتم تخزين نموذج الإحصائيات الذي تم إنشاؤه في ملف TFRecord المكتوب إلى GCS_STATS_OUTPUT_PATH .
ملاحظة عند استدعاء أي من وظائف tfdv.generate_statistics_... (على سبيل المثال، tfdv.generate_statistics_from_tfrecord ) على Google Cloud، يجب عليك توفير output_path . قد يؤدي تحديد لا شيء إلى حدوث خطأ.
استنتاج مخطط على البيانات
يصف المخطط الخصائص المتوقعة للبيانات. بعض هذه الخصائص هي:
- ما هي الميزات التي من المتوقع أن تكون موجودة
- نوعهم
- عدد قيم الميزة في كل مثال
- وجود كل ميزة في جميع الأمثلة
- مجالات الميزات المتوقعة.
باختصار، يصف المخطط التوقعات الخاصة بالبيانات "الصحيحة" وبالتالي يمكن استخدامه لاكتشاف الأخطاء في البيانات (الموضحة أدناه). علاوة على ذلك، يمكن استخدام نفس المخطط لإعداد TensorFlow Transform لتحويلات البيانات. لاحظ أنه من المتوقع أن يكون المخطط ثابتًا إلى حد ما، على سبيل المثال، يمكن أن تتوافق عدة مجموعات بيانات مع نفس المخطط، في حين أن الإحصائيات (الموصوفة أعلاه) يمكن أن تختلف حسب مجموعة البيانات.
نظرًا لأن كتابة المخطط يمكن أن تكون مهمة شاقة، خاصة بالنسبة لمجموعات البيانات التي تحتوي على الكثير من الميزات، فإن TFDV يوفر طريقة لإنشاء نسخة أولية من المخطط استنادًا إلى الإحصائيات الوصفية:
schema = tfdv.infer_schema(stats)
بشكل عام، يستخدم TFDV الاستدلال المحافظ لاستنتاج خصائص البيانات المستقرة من الإحصائيات لتجنب الإفراط في ملاءمة المخطط لمجموعة البيانات المحددة. يُنصح بشدة بمراجعة المخطط المستنتج وتحسينه حسب الحاجة ، لالتقاط أي معرفة بالمجال حول البيانات التي قد تكون استدلالات TFDV قد فاتتها.
افتراضيًا، يستنتج tfdv.infer_schema شكل كل ميزة مطلوبة، إذا كانت value_count.min تساوي value_count.max للميزة. قم بتعيين الوسيطة infer_feature_shape إلى False لتعطيل استنتاج الشكل.
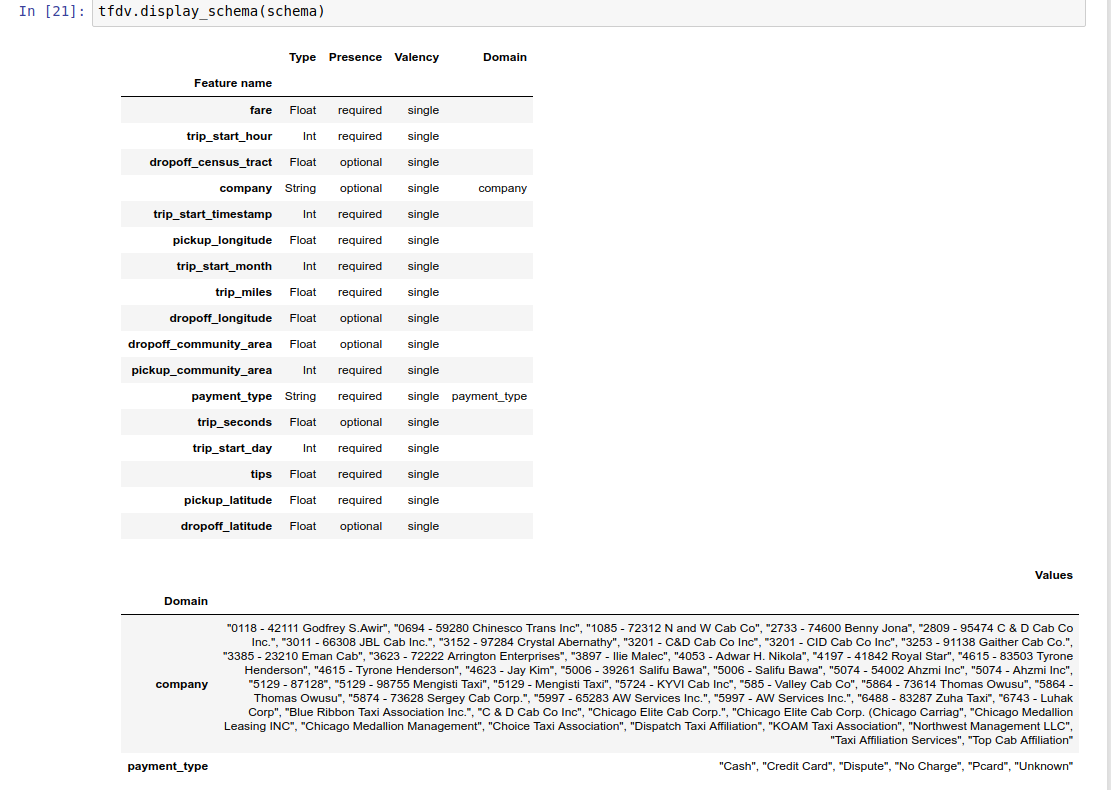
يتم تخزين المخطط نفسه كمخزن مؤقت لبروتوكول المخطط وبالتالي يمكن تحديثه/تحريره باستخدام واجهة برمجة تطبيقات المخزن المؤقت للبروتوكول القياسي. يوفر TFDV أيضًا بعض الطرق المساعدة لتسهيل هذه التحديثات. على سبيل المثال، لنفترض أن المخطط يحتوي على المقطع التالي لوصف ميزة سلسلة مطلوبة من payment_type الذي يأخذ قيمة واحدة:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
لوضع علامة على أنه يجب ملء الميزة في 50% على الأقل من الأمثلة:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
يحتوي مثال دفتر الملاحظات على تصور بسيط للمخطط على شكل جدول، يسرد كل ميزة وخصائصها الرئيسية كما تم ترميزها في المخطط.
التحقق من البيانات عن الأخطاء
في ضوء المخطط، من الممكن التحقق مما إذا كانت مجموعة البيانات تتوافق مع التوقعات المحددة في المخطط أو ما إذا كانت هناك أي حالات شاذة في البيانات . يمكنك التحقق من بياناتك بحثًا عن الأخطاء (أ) بشكل إجمالي عبر مجموعة بيانات بأكملها عن طريق مطابقة إحصائيات مجموعة البيانات مع المخطط، أو (ب) عن طريق التحقق من الأخطاء على أساس كل مثال.
مطابقة إحصائيات مجموعة البيانات مع المخطط
للتحقق من وجود أخطاء في المجمل، يقوم TFDV بمطابقة إحصائيات مجموعة البيانات مع المخطط ووضع علامة على أي اختلافات. على سبيل المثال:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
والنتيجة هي مثيل للمخزن المؤقت لبروتوكول Anomalies ويصف أي أخطاء حيث لا تتفق الإحصائيات مع المخطط. على سبيل المثال، لنفترض أن البيانات الموجودة في other_path تحتوي على أمثلة تحتوي على قيم لميزة payment_type خارج النطاق المحدد في المخطط.
وهذا ينتج حالة شاذة
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
يشير إلى أنه تم العثور على قيمة خارج النطاق في الإحصائيات في أقل من 1% من قيم الميزة.
إذا كان هذا متوقعًا، فيمكن تحديث المخطط على النحو التالي:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
إذا كان الشذوذ يشير حقًا إلى خطأ في البيانات، فيجب إصلاح البيانات الأساسية قبل استخدامها للتدريب.
يتم سرد أنواع الشذوذ المختلفة التي يمكن اكتشافها بواسطة هذه الوحدة هنا .
يحتوي نموذج دفتر الملاحظات على تصور بسيط للأوجه الشاذة في شكل جدول، يسرد الميزات التي تم اكتشاف الأخطاء فيها ووصفًا موجزًا لكل خطأ.

التحقق من الأخطاء على أساس كل مثال
يوفر TFDV أيضًا خيار التحقق من صحة البيانات على أساس كل مثال، بدلاً من مقارنة الإحصائيات على مستوى مجموعة البيانات مقابل المخطط. يوفر TFDV وظائف للتحقق من صحة البيانات على أساس كل مثال ثم إنشاء إحصائيات موجزة للأمثلة الشاذة التي تم العثور عليها. على سبيل المثال:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
إن anomalous_example_stats التي ترجعها validate_examples_in_tfrecord هي مخزن مؤقت لبروتوكول DatasetFeatureStatisticsList حيث تتكون كل مجموعة بيانات من مجموعة من الأمثلة التي تظهر حالة شاذة معينة. يمكنك استخدام هذا لتحديد عدد الأمثلة في مجموعة البيانات الخاصة بك والتي تظهر حالة شاذة معينة وخصائص تلك الأمثلة.
بيئات المخطط
افتراضيًا، تفترض عمليات التحقق من الصحة أن جميع مجموعات البيانات في المسار تلتزم بمخطط واحد. في بعض الحالات، يكون إدخال اختلافات طفيفة في المخطط أمرًا ضروريًا، على سبيل المثال، تكون الميزات المستخدمة كتسميات مطلوبة أثناء التدريب (وينبغي التحقق من صحتها)، ولكنها تكون مفقودة أثناء التقديم.
ويمكن استخدام البيئات للتعبير عن هذه المتطلبات. على وجه الخصوص، يمكن ربط الميزات الموجودة في المخطط بمجموعة من البيئات باستخدام default_environment وin_environment وnot_in_environment.
على سبيل المثال، إذا تم استخدام ميزة النصائح كتسمية في التدريب، ولكنها مفقودة في بيانات العرض. بدون تحديد البيئة، سوف يظهر كحالة شاذة.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

لإصلاح ذلك، نحتاج إلى تعيين البيئة الافتراضية لجميع الميزات لتكون "تدريب" و"خدمة"، واستبعاد ميزة "النصائح" من بيئة الخدمة.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
التحقق من انحراف البيانات والانجراف
بالإضافة إلى التحقق مما إذا كانت مجموعة البيانات تتوافق مع التوقعات المحددة في المخطط، يوفر TFDV أيضًا وظائف للكشف عن:
- الانحراف بين التدريب وخدمة البيانات
- الانجراف بين أيام مختلفة من بيانات التدريب
يقوم TFDV بإجراء هذا الفحص من خلال مقارنة إحصائيات مجموعات البيانات المختلفة بناءً على مقارنات الانحراف/الانحراف المحددة في المخطط. على سبيل المثال، للتحقق مما إذا كان هناك أي انحراف بين ميزة "نوع_الدفع" ضمن مجموعة بيانات التدريب والخدمة:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
ملحوظة: سوف يكتشف معيار L-infinity الانحراف فقط للميزات الفئوية. بدلاً من تحديد عتبة infinity_norm ، فإن تحديد عتبة jensen_shannon_divergence في skew_comparator من شأنه أن يكشف الانحراف لكل من الميزات الرقمية والفئوية.
نفس الشيء مع التحقق مما إذا كانت مجموعة البيانات تتوافق مع التوقعات المحددة في المخطط، والنتيجة هي أيضًا مثيل للمخزن المؤقت لبروتوكول Anomalies وتصف أي انحراف بين مجموعات بيانات التدريب والخدمة. على سبيل المثال، لنفترض أن بيانات العرض تحتوي على أمثلة أكثر بكثير مع ميزة payement_type لها قيمة Cash ، فإن هذا ينتج عنه انحراف غير طبيعي
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
إذا كان الشذوذ يشير حقًا إلى انحراف بين بيانات التدريب وتقديم البيانات، فمن الضروري إجراء مزيد من التحقيق لأن ذلك قد يكون له تأثير مباشر على أداء النموذج.
يحتوي دفتر الأمثلة على مثال بسيط للتحقق من الحالات الشاذة القائمة على الانحراف.
يمكن اكتشاف الانجراف بين أيام مختلفة من بيانات التدريب بطريقة مماثلة
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
ملحوظة: سوف يكتشف معيار L-infinity الانحراف فقط للميزات الفئوية. بدلاً من تحديد عتبة infinity_norm ، فإن تحديد عتبة jensen_shannon_divergence في skew_comparator من شأنه أن يكشف الانحراف لكل من الميزات الرقمية والفئوية.
كتابة موصل البيانات المخصصة
لحساب إحصائيات البيانات، يوفر TFDV عدة طرق ملائمة للتعامل مع بيانات الإدخال بتنسيقات مختلفة (على سبيل المثال، TFRecord of tf.train.Example ، وCSV، وما إلى ذلك). إذا لم يكن تنسيق البيانات الخاص بك موجودًا في هذه القائمة، فستحتاج إلى كتابة موصل بيانات مخصص لقراءة بيانات الإدخال، وتوصيله بواجهة برمجة التطبيقات TFDV الأساسية لحساب إحصائيات البيانات.
واجهة برمجة التطبيقات الأساسية TFDV لحساب إحصائيات البيانات عبارة عن Beam PTransform الذي يأخذ PCollection من دفعات من أمثلة الإدخال (يتم تمثيل مجموعة من أمثلة الإدخال كـ Arrow RecordBatch)، ويخرج PCollection الذي يحتوي على مخزن مؤقت واحد لبروتوكول DatasetFeatureStatisticsList .
بمجرد الانتهاء من تنفيذ موصل البيانات المخصص الذي يقوم بتجميع أمثلة الإدخال الخاصة بك في Arrow RecordBatch، فإنك تحتاج إلى توصيله بـ tfdv.GenerateStatistics API لحساب إحصائيات البيانات. خذ TFRecord لـ tf.train.Example على سبيل المثال. يوفر tfx_bsl موصل بيانات TFExampleRecord ، وفيما يلي مثال لكيفية توصيله بواجهة برمجة تطبيقات tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
حساب الإحصائيات على شرائح البيانات
يمكن تكوين TFDV لحساب الإحصائيات عبر شرائح البيانات. يمكن تمكين التقطيع من خلال توفير وظائف التقطيع التي تأخذ Arrow RecordBatch وتخرج سلسلة من مجموعات النموذج (slice key, record batch) . يوفر TFDV طريقة سهلة لإنشاء وظائف التقطيع القائمة على قيمة الميزة والتي يمكن توفيرها كجزء من tfdv.StatsOptions عند حساب الإحصائيات.
عند تمكين التقطيع، يحتوي النموذج الأولي DatasetFeatureStatisticsList الناتج على عدة نماذج أولية من DatasetFeatureStatistics ، واحد لكل شريحة. يتم تعريف كل شريحة باسم فريد يتم تعيينه كاسم لمجموعة البيانات في نموذج DatasetFeatureStatistics . افتراضيًا، يقوم TFDV بحساب إحصائيات مجموعة البيانات الإجمالية بالإضافة إلى الشرائح التي تم تكوينها.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])