
TensorFlow Data Validation (TFDV) può analizzare i dati di training e di fornitura per:
calcolare statistiche descrittive,
dedurre uno schema ,
rilevare anomalie nei dati .
L'API principale supporta ogni funzionalità, con metodi pratici che si basano su di essi e possono essere richiamati nel contesto dei notebook.
Calcolo statistico dei dati descrittivi
TFDV può calcolare statistiche descrittive che forniscono una rapida panoramica dei dati in termini di caratteristiche presenti e forme delle loro distribuzioni di valore. Strumenti come Panoramica delle faccette possono fornire una visualizzazione sintetica di queste statistiche per una facile navigazione.
Ad esempio, supponiamo che path punti a un file nel formato TFRecord (che contiene record di tipo tensorflow.Example ). Il seguente frammento illustra il calcolo delle statistiche utilizzando TFDV:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
Il valore restituito è un buffer del protocollo DatasetFeatureStatisticsList . Il notebook di esempio contiene una visualizzazione delle statistiche utilizzando la Panoramica dei facet :
tfdv.visualize_statistics(stats)
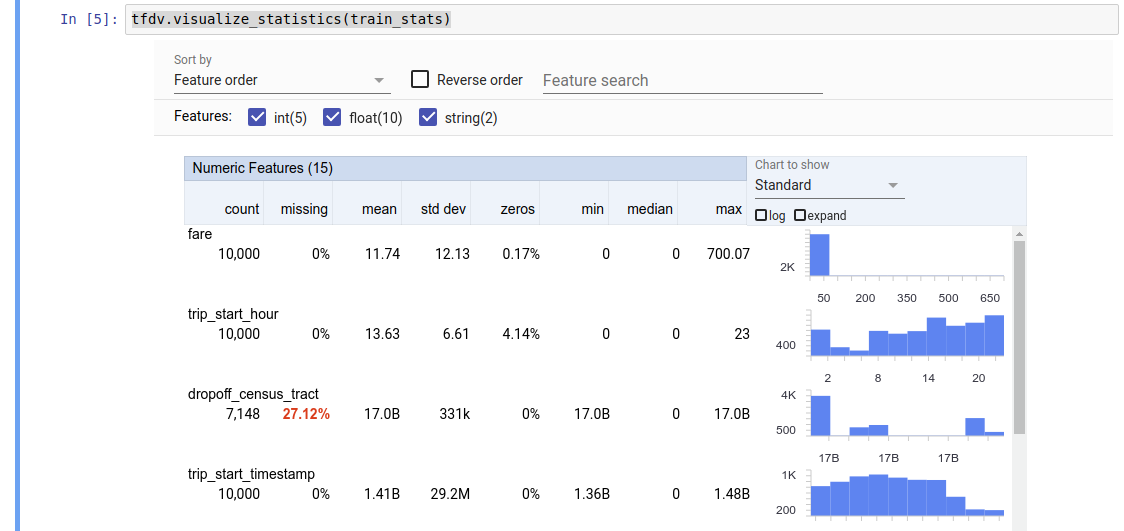
L'esempio precedente presuppone che i dati siano archiviati in un file TFRecord . TFDV supporta anche il formato di input CSV, con estensibilità per altri formati comuni. Puoi trovare i decoder dati disponibili qui . Inoltre, TFDV fornisce la funzione di utilità tfdv.generate_statistics_from_dataframe per gli utenti con dati in memoria rappresentati come DataFrame panda.
Oltre a calcolare un insieme predefinito di statistiche sui dati, TFDV può anche calcolare statistiche per domini semantici (ad esempio, immagini, testo). Per abilitare il calcolo delle statistiche del dominio semantico, passare un oggetto tfdv.StatsOptions con enable_semantic_domain_stats impostato su True a tfdv.generate_statistics_from_tfrecord .
In esecuzione su Google Cloud
Internamente, TFDV utilizza il framework di elaborazione parallela dei dati di Apache Beam per scalare il calcolo delle statistiche su set di dati di grandi dimensioni. Per le applicazioni che desiderano integrarsi più profondamente con TFDV (ad esempio allegare la generazione di statistiche alla fine di una pipeline di generazione di dati, generare statistiche per dati in formato personalizzato ), l'API espone anche un Beam PTransform per la generazione di statistiche.
Per eseguire TFDV su Google Cloud, il file della ruota TFDV deve essere scaricato e fornito ai lavoratori Dataflow. Scarica il file della ruota nella directory corrente come segue:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
Il seguente snippet mostra un esempio di utilizzo di TFDV su Google Cloud:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
In questo caso, il protocollo statistico generato viene archiviato in un file TFRecord scritto in GCS_STATS_OUTPUT_PATH .
NOTA Quando si chiama una qualsiasi delle funzioni tfdv.generate_statistics_... (ad esempio, tfdv.generate_statistics_from_tfrecord ) su Google Cloud, è necessario fornire un output_path . Specificare Nessuno può causare un errore.
Dedurre uno schema sui dati
Lo schema descrive le proprietà previste dei dati. Alcune di queste proprietà sono:
- quali caratteristiche dovrebbero essere presenti
- il loro tipo
- il numero di valori per una caratteristica in ciascun esempio
- la presenza di ciascuna caratteristica in tutti gli esempi
- i domini di caratteristiche attesi.
In breve, lo schema descrive le aspettative per i dati "corretti" e può quindi essere utilizzato per rilevare errori nei dati (descritti di seguito). Inoltre, lo stesso schema può essere utilizzato per impostare TensorFlow Transform per le trasformazioni dei dati. Si noti che lo schema dovrebbe essere abbastanza statico, ad esempio, diversi set di dati possono conformarsi allo stesso schema, mentre le statistiche (descritte sopra) possono variare per set di dati.
Poiché scrivere uno schema può essere un compito noioso, soprattutto per set di dati con molte funzionalità, TFDV fornisce un metodo per generare una versione iniziale dello schema in base alle statistiche descrittive:
schema = tfdv.infer_schema(stats)
In generale, TFDV utilizza l'euristica conservativa per dedurre proprietà stabili dei dati dalle statistiche al fine di evitare di adattare eccessivamente lo schema al set di dati specifico. Si consiglia vivamente di rivedere lo schema dedotto e perfezionarlo secondo necessità , per acquisire qualsiasi conoscenza del dominio sui dati che l'euristica di TFDV potrebbe aver perso.
Per impostazione predefinita, tfdv.infer_schema deduce la forma di ciascuna funzionalità richiesta, se value_count.min è uguale value_count.max per la funzionalità. Imposta l'argomento infer_feature_shape su False per disabilitare l'inferenza della forma.
Lo schema stesso viene archiviato come buffer del protocollo dello schema e può quindi essere aggiornato/modificato utilizzando l'API del buffer di protocollo standard. TFDV fornisce anche alcuni metodi di utilità per facilitare questi aggiornamenti. Ad esempio, supponiamo che lo schema contenga la seguente stanza per descrivere una funzione di stringa richiesta payment_type che accetta un singolo valore:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
Per indicare che la funzionalità deve essere popolata in almeno il 50% degli esempi:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
Il notebook di esempio contiene una semplice visualizzazione dello schema come tabella, che elenca ciascuna funzionalità e le relative caratteristiche principali codificate nello schema.
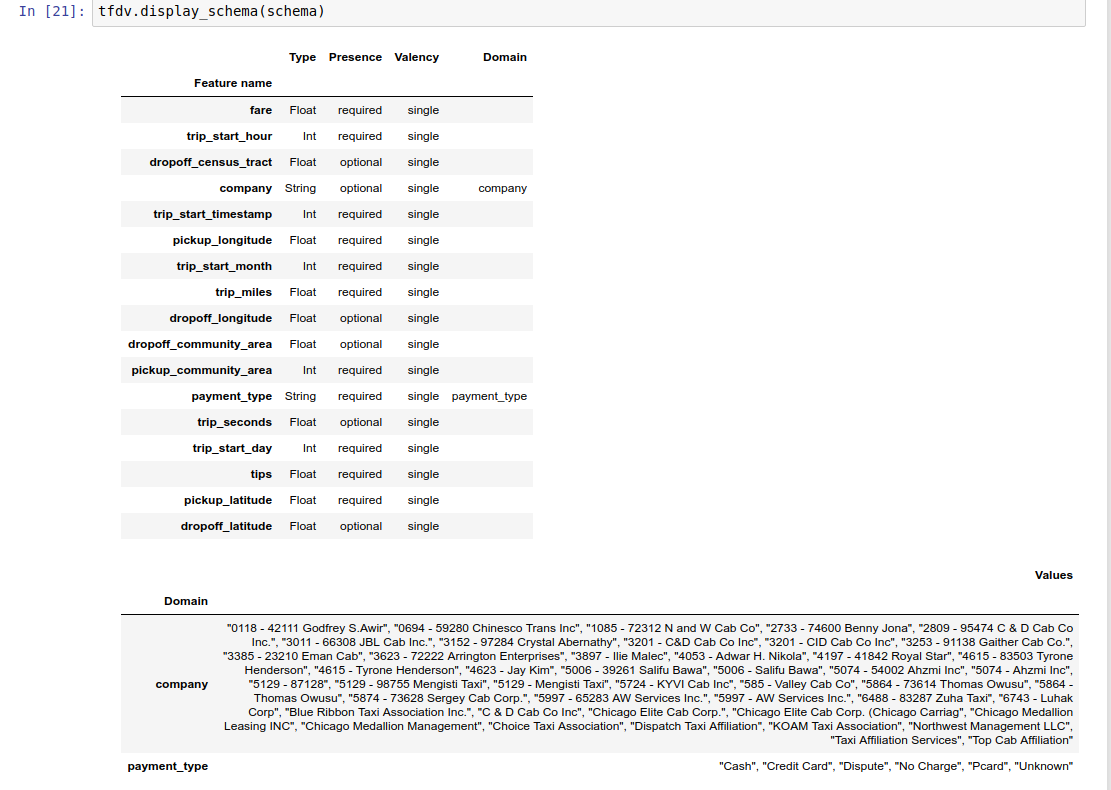
Controllo dei dati per eventuali errori
Dato uno schema è possibile verificare se un dataset è conforme alle aspettative fissate nello schema o se esistono anomalie nei dati . Puoi verificare la presenza di errori nei tuoi dati (a) in forma aggregata in un intero set di dati confrontando le statistiche del set di dati con lo schema o (b) controllando gli errori in base al singolo esempio.
Corrispondenza delle statistiche del set di dati con uno schema
Per verificare la presenza di errori nell'aggregato, TFDV confronta le statistiche del set di dati con lo schema e contrassegna eventuali discrepanze. Per esempio:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
Il risultato è un'istanza del buffer del protocollo Anomalies e descrive eventuali errori in cui le statistiche non concordano con lo schema. Si supponga, ad esempio, che i dati in other_path contengano esempi con valori per la funzionalità payment_type esterni al dominio specificato nello schema.
Ciò produce un'anomalia
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
indicando che nelle statistiche è stato trovato un valore fuori dominio in < 1% dei valori delle caratteristiche.
Se ciò era previsto, lo schema può essere aggiornato come segue:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
Se l'anomalia indica veramente un errore nei dati, è necessario correggere i dati sottostanti prima di utilizzarli per l'addestramento.
Di seguito sono elencate le varie tipologie di anomalie rilevabili da questo modulo.
Il notebook di esempio contiene una semplice visualizzazione delle anomalie sotto forma di tabella, che elenca le funzionalità in cui vengono rilevati errori e una breve descrizione di ciascun errore.

Controllo degli errori in base all'esempio
TFDV offre inoltre la possibilità di convalidare i dati in base all'esempio, invece di confrontare le statistiche a livello di set di dati con lo schema. TFDV fornisce funzioni per convalidare i dati in base all'esempio e quindi generare statistiche riassuntive per gli esempi anomali trovati. Per esempio:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
L' anomalous_example_stats restituito da validate_examples_in_tfrecord è un buffer del protocollo DatasetFeatureStatisticsList in cui ogni set di dati è costituito dal set di esempi che presentano una particolare anomalia. Puoi utilizzarlo per determinare il numero di esempi nel tuo set di dati che presentano una determinata anomalia e le caratteristiche di tali esempi.
Ambienti dello schema
Per impostazione predefinita, le convalide presuppongono che tutti i set di dati in una pipeline aderiscano a un unico schema. In alcuni casi è necessario introdurre leggere variazioni dello schema, ad esempio le funzionalità utilizzate come etichette sono richieste durante la formazione (e dovrebbero essere convalidate), ma mancano durante la pubblicazione.
Gli ambienti possono essere utilizzati per esprimere tali requisiti. In particolare, le funzionalità nello schema possono essere associate a un insieme di ambienti utilizzando default_environment, in_environment e not_in_environment.
Ad esempio, se la funzionalità dei suggerimenti viene utilizzata come etichetta nella formazione, ma manca nei dati di pubblicazione. Senza l'ambiente specificato, verrà visualizzato come un'anomalia.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

Per risolvere questo problema, dobbiamo impostare l'ambiente predefinito per tutte le funzionalità su "FORMAZIONE" e "SERVIMENTO" ed escludere la funzionalità "suggerimenti" dall'ambiente di SERVIZIO.
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
Controllo dell'inclinazione e della deriva dei dati
Oltre a verificare se un set di dati è conforme alle aspettative fissate nello schema, TFDV fornisce anche funzionalità per rilevare:
- disallineamento tra i dati di addestramento e quelli di elaborazione
- deriva tra diversi giorni di dati di addestramento
TFDV esegue questo controllo confrontando le statistiche di diversi set di dati in base ai comparatori di deriva/inclinazione specificati nello schema. Ad esempio, per verificare se esiste una discrepanza tra la funzione "payment_type" all'interno del set di dati di addestramento e di servizio:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
NOTA La norma L-infinito rileverà solo la distorsione per le caratteristiche categoriali. Invece di specificare una soglia infinity_norm , specificando una soglia jensen_shannon_divergence in skew_comparator rileverebbe l'inclinazione sia per le caratteristiche numeriche che per quelle categoriali.
Lo stesso vale per verificare se un set di dati è conforme alle aspettative impostate nello schema, il risultato è anche un'istanza del buffer del protocollo Anomalies e descrive qualsiasi disallineamento tra i set di dati di addestramento e quelli di servizio. Ad esempio, supponiamo che i dati di servizio contengano un numero significativamente maggiore di esempi con la funzione payement_type con valore Cash , ciò produce un'anomalia di distorsione
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
Se l'anomalia indica veramente una discrepanza tra i dati di addestramento e quelli di elaborazione, sono necessarie ulteriori indagini poiché ciò potrebbe avere un impatto diretto sulle prestazioni del modello.
Il notebook di esempio contiene un semplice esempio di controllo delle anomalie basate sulla distorsione.
Il rilevamento della deriva tra giorni diversi dei dati di allenamento può essere effettuato in modo simile
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
NOTA La norma L-infinito rileverà solo la distorsione per le caratteristiche categoriali. Invece di specificare una soglia infinity_norm , specificando una soglia jensen_shannon_divergence in skew_comparator rileverebbe l'inclinazione sia per le caratteristiche numeriche che per quelle categoriali.
Scrittura del connettore dati personalizzato
Per calcolare le statistiche dei dati, TFDV fornisce diversi metodi convenienti per gestire i dati di input in vari formati (ad esempio TFRecord di tf.train.Example , CSV, ecc.). Se il formato dei tuoi dati non è presente in questo elenco, devi scrivere un connettore dati personalizzato per leggere i dati di input e collegarlo all'API core TFDV per elaborare le statistiche dei dati.
L' API principale di TFDV per il calcolo delle statistiche dei dati è un Beam PTransform che accetta una PCollection di batch di esempi di input (un batch di esempi di input è rappresentato come Arrow RecordBatch) e restituisce una PCollection contenente un singolo buffer di protocollo DatasetFeatureStatisticsList .
Dopo aver implementato il connettore dati personalizzato che raggruppa gli esempi di input in un Arrow RecordBatch, è necessario collegarlo all'API tfdv.GenerateStatistics per calcolare le statistiche dei dati. Prendi TFRecord di tf.train.Example 's per esempio. tfx_bsl fornisce il connettore dati TFExampleRecord e di seguito è riportato un esempio di come collegarlo all'API tfdv.GenerateStatistics .
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
Calcolo delle statistiche su porzioni di dati
TFDV può essere configurato per calcolare statistiche su porzioni di dati. Lo slicing può essere abilitato fornendo funzioni di slicing che accettano un Arrow RecordBatch e producono una sequenza di tuple di forma (slice key, record batch) . TFDV fornisce un modo semplice per generare funzioni di slicing basate sul valore delle funzionalità che possono essere fornite come parte di tfdv.StatsOptions durante il calcolo delle statistiche.
Quando l'affettamento è abilitato, il protocollo di output DatasetFeatureStatisticsList contiene più protocolli DatasetFeatureStatistics , uno per ogni fetta. Ogni sezione è identificata da un nome univoco impostato come nome del set di dati nel protocollo DatasetFeatureStatistics . Per impostazione predefinita TFDV calcola le statistiche per il set di dati complessivo oltre alle sezioni configurate.
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])