
TensorFlow डेटा वैलिडेशन (TFDV) प्रशिक्षण और डेटा सेवा का विश्लेषण कर सकता है:
वर्णनात्मक आँकड़ों की गणना करें,
एक स्कीमा का अनुमान लगाएं,
डेटा विसंगतियों का पता लगाएं।
कोर एपीआई कार्यक्षमता के प्रत्येक टुकड़े का समर्थन करता है, सुविधाजनक तरीकों के साथ जो शीर्ष पर निर्मित होते हैं और इन्हें नोटबुक के संदर्भ में कहा जा सकता है।
वर्णनात्मक डेटा आँकड़ों की गणना करना
टीएफडीवी वर्णनात्मक आंकड़ों की गणना कर सकता है जो मौजूद सुविधाओं और उनके मूल्य वितरण के आकार के संदर्भ में डेटा का त्वरित अवलोकन प्रदान करता है। फ़ेसेट्स ओवरव्यू जैसे उपकरण आसान ब्राउज़िंग के लिए इन आँकड़ों का एक संक्षिप्त दृश्य प्रदान कर सकते हैं।
उदाहरण के लिए, मान लीजिए कि वह path TFRecord प्रारूप में एक फ़ाइल की ओर इंगित करता है (जिसमें tensorflow.Example प्रकार के रिकॉर्ड होते हैं)। निम्नलिखित स्निपेट टीएफडीवी का उपयोग करके आंकड़ों की गणना को दर्शाता है:
stats = tfdv.generate_statistics_from_tfrecord(data_location=path)
लौटाया गया मान एक DatasetFeatureStatisticsList प्रोटोकॉल बफ़र है। उदाहरण नोटबुक में पहलुओं के अवलोकन का उपयोग करते हुए आँकड़ों का एक दृश्य शामिल है:
tfdv.visualize_statistics(stats)
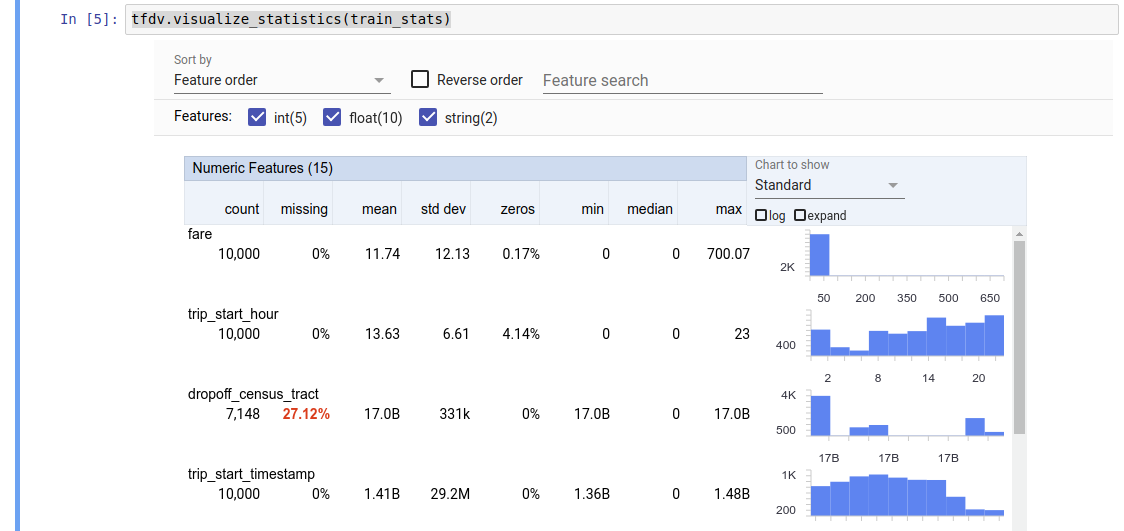
पिछला उदाहरण मानता है कि डेटा TFRecord फ़ाइल में संग्रहीत है। टीएफडीवी अन्य सामान्य प्रारूपों के लिए विस्तारशीलता के साथ सीएसवी इनपुट प्रारूप का भी समर्थन करता है। आप यहां उपलब्ध डेटा डिकोडर पा सकते हैं। इसके अलावा, TFDV पांडा डेटाफ़्रेम के रूप में दर्शाए गए इन-मेमोरी डेटा वाले उपयोगकर्ताओं के लिए tfdv.generate_statistics_from_dataframe उपयोगिता फ़ंक्शन प्रदान करता है।
डेटा आँकड़ों के एक डिफ़ॉल्ट सेट की गणना करने के अलावा, TFDV सिमेंटिक डोमेन (जैसे, चित्र, पाठ) के लिए आँकड़ों की गणना भी कर सकता है। सिमेंटिक डोमेन आंकड़ों की गणना को सक्षम करने के लिए, एक tfdv.StatsOptions ऑब्जेक्ट को enable_semantic_domain_stats के साथ True पर सेट करके tfdv.generate_statistics_from_tfrecord पास करें।
Google क्लाउड पर चल रहा है
आंतरिक रूप से, टीएफडीवी बड़े डेटासेट पर आंकड़ों की गणना को मापने के लिए अपाचे बीम के डेटा-समानांतर प्रसंस्करण ढांचे का उपयोग करता है। उन अनुप्रयोगों के लिए जो टीएफडीवी के साथ गहराई से एकीकृत करना चाहते हैं (उदाहरण के लिए डेटा-जनरेशन पाइपलाइन के अंत में सांख्यिकी पीढ़ी संलग्न करना, कस्टम प्रारूप में डेटा के लिए आंकड़े उत्पन्न करना ), एपीआई सांख्यिकी पीढ़ी के लिए एक बीम पीट्रांसफॉर्म को भी उजागर करता है।
Google क्लाउड पर TFDV चलाने के लिए, TFDV व्हील फ़ाइल को डाउनलोड किया जाना चाहिए और डेटाफ़्लो श्रमिकों को प्रदान किया जाना चाहिए। व्हील फ़ाइल को वर्तमान निर्देशिका में इस प्रकार डाउनलोड करें:
pip download tensorflow_data_validation \
--no-deps \
--platform manylinux2010_x86_64 \
--only-binary=:all:
निम्नलिखित स्निपेट Google क्लाउड पर TFDV के उपयोग का एक उदाहरण दिखाता है:
import tensorflow_data_validation as tfdv
from apache_beam.options.pipeline_options import PipelineOptions, GoogleCloudOptions, StandardOptions, SetupOptions
PROJECT_ID = ''
JOB_NAME = ''
GCS_STAGING_LOCATION = ''
GCS_TMP_LOCATION = ''
GCS_DATA_LOCATION = ''
# GCS_STATS_OUTPUT_PATH is the file path to which to output the data statistics
# result.
GCS_STATS_OUTPUT_PATH = ''
PATH_TO_WHL_FILE = ''
# Create and set your PipelineOptions.
options = PipelineOptions()
# For Cloud execution, set the Cloud Platform project, job_name,
# staging location, temp_location and specify DataflowRunner.
google_cloud_options = options.view_as(GoogleCloudOptions)
google_cloud_options.project = PROJECT_ID
google_cloud_options.job_name = JOB_NAME
google_cloud_options.staging_location = GCS_STAGING_LOCATION
google_cloud_options.temp_location = GCS_TMP_LOCATION
options.view_as(StandardOptions).runner = 'DataflowRunner'
setup_options = options.view_as(SetupOptions)
# PATH_TO_WHL_FILE should point to the downloaded tfdv wheel file.
setup_options.extra_packages = [PATH_TO_WHL_FILE]
tfdv.generate_statistics_from_tfrecord(GCS_DATA_LOCATION,
output_path=GCS_STATS_OUTPUT_PATH,
pipeline_options=options)
इस मामले में, उत्पन्न सांख्यिकी प्रोटो को GCS_STATS_OUTPUT_PATH पर लिखी गई TFRecord फ़ाइल में संग्रहीत किया जाता है।
ध्यान दें Google क्लाउड पर किसी भी tfdv.generate_statistics_... फ़ंक्शन (उदाहरण के लिए, tfdv.generate_statistics_from_tfrecord ) को कॉल करते समय, आपको एक output_path प्रदान करना होगा। कोई नहीं निर्दिष्ट करने से त्रुटि हो सकती है।
डेटा पर एक स्कीमा का अनुमान लगाना
स्कीमा डेटा के अपेक्षित गुणों का वर्णन करता है। इनमें से कुछ संपत्तियाँ हैं:
- कौन सी सुविधाएँ मौजूद होने की उम्मीद है
- उनके प्रकार
- प्रत्येक उदाहरण में किसी सुविधा के लिए मानों की संख्या
- सभी उदाहरणों में प्रत्येक सुविधा की उपस्थिति
- सुविधाओं के अपेक्षित डोमेन.
संक्षेप में, स्कीमा "सही" डेटा की अपेक्षाओं का वर्णन करती है और इस प्रकार डेटा में त्रुटियों का पता लगाने के लिए इसका उपयोग किया जा सकता है (नीचे वर्णित है)। इसके अलावा, उसी स्कीमा का उपयोग डेटा परिवर्तनों के लिए TensorFlow Transform को सेट करने के लिए किया जा सकता है। ध्यान दें कि स्कीमा काफी स्थिर होने की उम्मीद है, उदाहरण के लिए, कई डेटासेट एक ही स्कीमा के अनुरूप हो सकते हैं, जबकि आंकड़े (ऊपर वर्णित) प्रति डेटासेट भिन्न हो सकते हैं।
चूँकि स्कीमा लिखना एक कठिन कार्य हो सकता है, विशेष रूप से बहुत सारी विशेषताओं वाले डेटासेट के लिए, TFDV वर्णनात्मक आँकड़ों के आधार पर स्कीमा का प्रारंभिक संस्करण तैयार करने की एक विधि प्रदान करता है:
schema = tfdv.infer_schema(stats)
सामान्य तौर पर, टीएफडीवी विशिष्ट डेटासेट में स्कीमा को ओवरफिट करने से बचने के लिए आंकड़ों से स्थिर डेटा गुणों का अनुमान लगाने के लिए रूढ़िवादी अनुमान का उपयोग करता है। यह दृढ़ता से सलाह दी जाती है कि अनुमानित स्कीमा की समीक्षा करें और आवश्यकतानुसार इसे परिष्कृत करें , ताकि टीएफडीवी के अनुमानों से छूटे डेटा के बारे में किसी भी डोमेन ज्ञान को हासिल किया जा सके।
डिफ़ॉल्ट रूप से, tfdv.infer_schema प्रत्येक आवश्यक सुविधा के आकार का अनुमान लगाता है, यदि सुविधा के लिए value_count.min value_count.max बराबर है। आकार अनुमान को अक्षम करने के लिए infer_feature_shape तर्क को गलत पर सेट करें।
स्कीमा को स्वयं स्कीमा प्रोटोकॉल बफ़र के रूप में संग्रहीत किया जाता है और इस प्रकार इसे मानक प्रोटोकॉल-बफ़र एपीआई का उपयोग करके अद्यतन/संपादित किया जा सकता है। TFDV इन अद्यतनों को आसान बनाने के लिए कुछ उपयोगिता विधियाँ भी प्रदान करता है। उदाहरण के लिए, मान लें कि स्कीमा में एक आवश्यक स्ट्रिंग सुविधा payment_type का वर्णन करने के लिए निम्नलिखित श्लोक शामिल है जो एकल मान लेता है:
feature {
name: "payment_type"
value_count {
min: 1
max: 1
}
type: BYTES
domain: "payment_type"
presence {
min_fraction: 1.0
min_count: 1
}
}
यह चिन्हित करने के लिए कि यह सुविधा कम से कम 50% उदाहरणों में भरी जानी चाहिए:
tfdv.get_feature(schema, 'payment_type').presence.min_fraction = 0.5
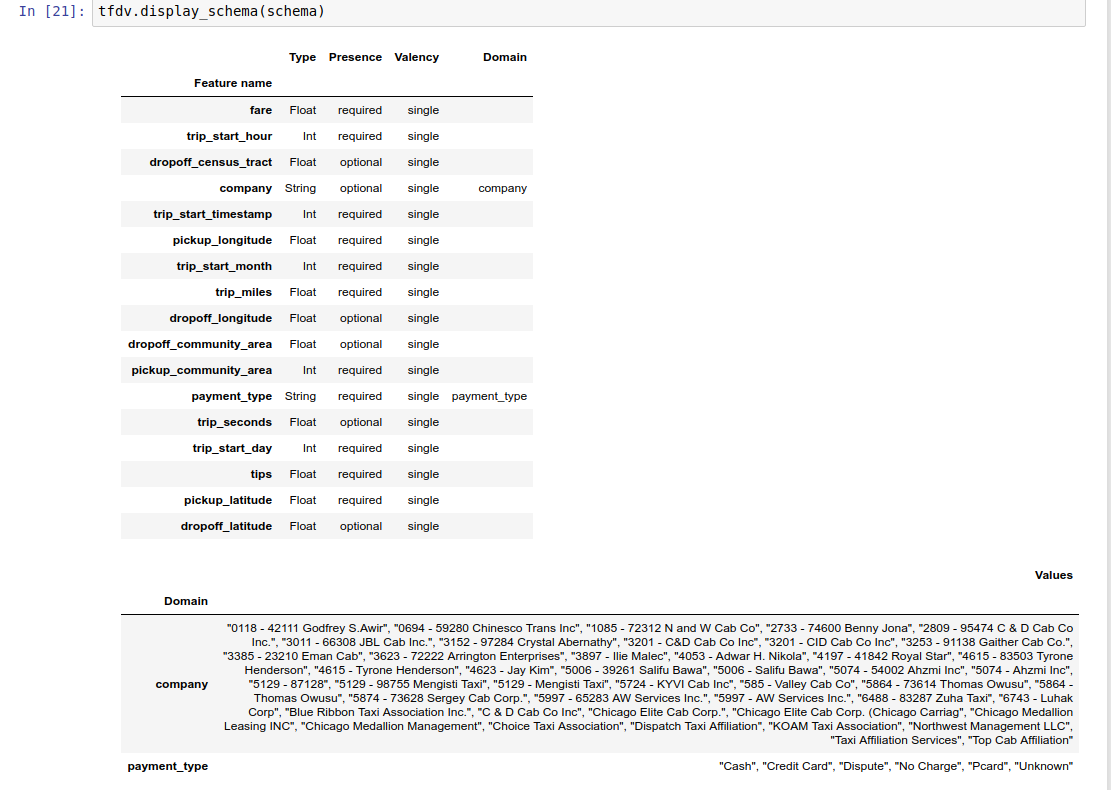
उदाहरण नोटबुक में एक तालिका के रूप में स्कीमा का एक सरल दृश्य शामिल है, जिसमें स्कीमा में एन्कोड किए गए प्रत्येक फीचर और उसकी मुख्य विशेषताओं को सूचीबद्ध किया गया है।
त्रुटियों के लिए डेटा की जाँच करना
किसी स्कीमा को देखते हुए, यह जांचना संभव है कि क्या कोई डेटासेट स्कीमा में निर्धारित अपेक्षाओं के अनुरूप है या क्या कोई डेटा विसंगतियां मौजूद हैं। आप स्कीमा के विरुद्ध डेटासेट के आँकड़ों का मिलान करके, या (बी) प्रति-उदाहरण के आधार पर त्रुटियों की जाँच करके संपूर्ण डेटासेट में त्रुटियों के लिए अपने डेटा की जाँच कर सकते हैं।
किसी स्कीमा के विरुद्ध डेटासेट के आँकड़ों का मिलान करना
समुच्चय में त्रुटियों की जांच करने के लिए, टीएफडीवी स्कीमा के विरुद्ध डेटासेट के आंकड़ों से मेल खाता है और किसी भी विसंगति को चिह्नित करता है। उदाहरण के लिए:
# Assume that other_path points to another TFRecord file
other_stats = tfdv.generate_statistics_from_tfrecord(data_location=other_path)
anomalies = tfdv.validate_statistics(statistics=other_stats, schema=schema)
परिणाम विसंगति प्रोटोकॉल बफ़र का एक उदाहरण है और किसी भी त्रुटि का वर्णन करता है जहां आँकड़े स्कीमा से सहमत नहीं हैं। उदाहरण के लिए, मान लें कि other_path के डेटा में स्कीमा में निर्दिष्ट डोमेन के बाहर फीचर payment_type के लिए मान वाले उदाहरण हैं।
इससे एक विसंगति उत्पन्न होती है
payment_type Unexpected string values Examples contain values missing from the schema: Prcard (<1%).
यह दर्शाता है कि फ़ीचर मानों के <1% में डोमेन से बाहर का मान आँकड़ों में पाया गया था।
यदि यह अपेक्षित था, तो स्कीमा को निम्नानुसार अद्यतन किया जा सकता है:
tfdv.get_domain(schema, 'payment_type').value.append('Prcard')
यदि विसंगति वास्तव में डेटा त्रुटि का संकेत देती है, तो प्रशिक्षण के लिए उपयोग करने से पहले अंतर्निहित डेटा को ठीक किया जाना चाहिए।
इस मॉड्यूल द्वारा पता लगाए जा सकने वाले विभिन्न विसंगति प्रकार यहां सूचीबद्ध हैं।
उदाहरण नोटबुक में एक तालिका के रूप में विसंगतियों का एक सरल दृश्य शामिल है, उन विशेषताओं को सूचीबद्ध किया गया है जहां त्रुटियों का पता चला है और प्रत्येक त्रुटि का संक्षिप्त विवरण है।

प्रति-उदाहरण के आधार पर त्रुटियों की जाँच करना
TFDV स्कीमा के विरुद्ध डेटासेट-व्यापी आँकड़ों की तुलना करने के बजाय, प्रति-उदाहरण के आधार पर डेटा को मान्य करने का विकल्प भी प्रदान करता है। टीएफडीवी प्रति-उदाहरण के आधार पर डेटा को मान्य करने और फिर पाए गए असामान्य उदाहरणों के लिए सारांश आंकड़े तैयार करने के लिए कार्य प्रदान करता है। उदाहरण के लिए:
options = tfdv.StatsOptions(schema=schema)
anomalous_example_stats = tfdv.validate_examples_in_tfrecord(
data_location=input, stats_options=options)
anomalous_example_stats जो validate_examples_in_tfrecord लौटाता है, एक DatasetFeatureStatisticsList प्रोटोकॉल बफ़र है जिसमें प्रत्येक डेटासेट में उदाहरणों का सेट होता है जो एक विशेष विसंगति प्रदर्शित करता है। आप इसका उपयोग अपने डेटासेट में उन उदाहरणों की संख्या निर्धारित करने के लिए कर सकते हैं जो किसी दिए गए विसंगति और उन उदाहरणों की विशेषताओं को प्रदर्शित करते हैं।
स्कीमा वातावरण
डिफ़ॉल्ट रूप से, सत्यापन यह मानता है कि पाइपलाइन में सभी डेटासेट एक ही स्कीमा का पालन करते हैं। कुछ मामलों में स्कीमा में मामूली बदलाव करना आवश्यक है, उदाहरण के लिए प्रशिक्षण के दौरान लेबल के रूप में उपयोग की जाने वाली सुविधाओं की आवश्यकता होती है (और उन्हें मान्य किया जाना चाहिए), लेकिन सेवा के दौरान गायब हैं।
ऐसी आवश्यकताओं को व्यक्त करने के लिए वातावरण का उपयोग किया जा सकता है। विशेष रूप से, स्कीमा में सुविधाओं को default_environment, in_environment और not_in_environment का उपयोग करके वातावरण के एक सेट से जोड़ा जा सकता है।
उदाहरण के लिए, यदि टिप्स सुविधा का उपयोग प्रशिक्षण में लेबल के रूप में किया जा रहा है, लेकिन सर्विंग डेटा में गायब है। पर्यावरण निर्दिष्ट किए बिना, यह एक विसंगति के रूप में दिखाई देगा।
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
serving_anomalies = tfdv.validate_statistics(serving_stats, schema)

इसे ठीक करने के लिए, हमें सभी सुविधाओं के लिए डिफ़ॉल्ट वातावरण को 'प्रशिक्षण' और 'सेवा' दोनों के रूप में सेट करना होगा, और सेवा वातावरण से 'टिप्स' सुविधा को बाहर करना होगा।
# All features are by default in both TRAINING and SERVING environments.
schema.default_environment.append('TRAINING')
schema.default_environment.append('SERVING')
# Specify that 'tips' feature is not in SERVING environment.
tfdv.get_feature(schema, 'tips').not_in_environment.append('SERVING')
serving_anomalies_with_env = tfdv.validate_statistics(
serving_stats, schema, environment='SERVING')
डेटा के तिरछापन और बहाव की जाँच करना
यह जाँचने के अलावा कि कोई डेटासेट स्कीमा में निर्धारित अपेक्षाओं के अनुरूप है या नहीं, TFDV यह पता लगाने के लिए कार्यक्षमताएँ भी प्रदान करता है:
- प्रशिक्षण और डेटा परोसने के बीच अंतर
- प्रशिक्षण के विभिन्न दिनों के डेटा के बीच अंतर
टीएफडीवी स्कीमा में निर्दिष्ट ड्रिफ्ट/स्क्यू तुलनित्रों के आधार पर विभिन्न डेटासेट के आंकड़ों की तुलना करके यह जांच करता है। उदाहरण के लिए, यह जांचने के लिए कि प्रशिक्षण और सेवारत डेटासेट के भीतर 'भुगतान_प्रकार' सुविधा के बीच कोई विसंगति है या नहीं:
# Assume we have already generated the statistics of training dataset, and
# inferred a schema from it.
serving_stats = tfdv.generate_statistics_from_tfrecord(data_location=serving_data_path)
# Add a skew comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering skew anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').skew_comparator.infinity_norm.threshold = 0.01
skew_anomalies = tfdv.validate_statistics(
statistics=train_stats, schema=schema, serving_statistics=serving_stats)
ध्यान दें एल-इनफ़िनिटी मानदंड केवल श्रेणीबद्ध विशेषताओं के लिए तिरछा का पता लगाएगा। infinity_norm थ्रेशोल्ड को निर्दिष्ट करने के बजाय, skew_comparator में jensen_shannon_divergence थ्रेशोल्ड को निर्दिष्ट करने से संख्यात्मक और श्रेणीबद्ध दोनों विशेषताओं के लिए तिरछा पता चलेगा।
यह जांचने के साथ ही कि क्या कोई डेटासेट स्कीमा में निर्धारित अपेक्षाओं के अनुरूप है, परिणाम भी विसंगति प्रोटोकॉल बफर का एक उदाहरण है और प्रशिक्षण और सेवारत डेटासेट के बीच किसी भी विषमता का वर्णन करता है। उदाहरण के लिए, मान लीजिए कि सर्विंग डेटा में फीचर payement_type के साथ Cash वैल्यू वाले काफी अधिक उदाहरण हैं, तो यह एक विषम विसंगति पैदा करता है
payment_type High L-infinity distance between serving and training The L-infinity distance between serving and training is 0.0435984 (up to six significant digits), above the threshold 0.01. The feature value with maximum difference is: Cash
यदि विसंगति वास्तव में प्रशिक्षण और डेटा प्रस्तुत करने के बीच एक विसंगति का संकेत देती है, तो आगे की जांच आवश्यक है क्योंकि इसका मॉडल प्रदर्शन पर सीधा प्रभाव पड़ सकता है।
उदाहरण नोटबुक में तिरछा-आधारित विसंगतियों की जाँच का एक सरल उदाहरण है।
प्रशिक्षण के विभिन्न दिनों के डेटा के बीच अंतर का पता लगाना इसी तरह से किया जा सकता है
# Assume we have already generated the statistics of training dataset for
# day 2, and inferred a schema from it.
train_day1_stats = tfdv.generate_statistics_from_tfrecord(data_location=train_day1_data_path)
# Add a drift comparator to schema for 'payment_type' and set the threshold
# of L-infinity norm for triggering drift anomaly to be 0.01.
tfdv.get_feature(schema, 'payment_type').drift_comparator.infinity_norm.threshold = 0.01
drift_anomalies = tfdv.validate_statistics(
statistics=train_day2_stats, schema=schema, previous_statistics=train_day1_stats)
ध्यान दें एल-इनफ़िनिटी मानदंड केवल श्रेणीबद्ध विशेषताओं के लिए तिरछा का पता लगाएगा। infinity_norm थ्रेशोल्ड को निर्दिष्ट करने के बजाय, skew_comparator में jensen_shannon_divergence थ्रेशोल्ड को निर्दिष्ट करने से संख्यात्मक और श्रेणीबद्ध दोनों विशेषताओं के लिए तिरछा पता चलेगा।
कस्टम डेटा कनेक्टर लिखना
डेटा आँकड़ों की गणना करने के लिए, TFDV विभिन्न प्रारूपों में इनपुट डेटा को संभालने के लिए कई सुविधाजनक तरीके प्रदान करता है (उदाहरण के लिए tf.train.Example , CSV, आदि का TFRecord )। यदि आपका डेटा प्रारूप इस सूची में नहीं है, तो आपको इनपुट डेटा पढ़ने के लिए एक कस्टम डेटा कनेक्टर लिखना होगा, और डेटा आंकड़ों की गणना के लिए इसे टीएफडीवी कोर एपीआई से कनेक्ट करना होगा।
डेटा आँकड़ों की गणना के लिए TFDV कोर एपीआई एक बीम PTransform है जो इनपुट उदाहरणों के बैचों का एक PCollection लेता है (इनपुट उदाहरणों का एक बैच एक Arrow रिकॉर्डबैच के रूप में दर्शाया जाता है), और एक एकल DatasetFeatureStatisticsList प्रोटोकॉल बफर वाले PCollection को आउटपुट करता है।
एक बार जब आप कस्टम डेटा कनेक्टर लागू कर लेते हैं जो आपके इनपुट उदाहरणों को एरो रिकॉर्डबैच में बैच करता है, तो आपको डेटा आंकड़ों की गणना के लिए इसे tfdv.GenerateStatistics API से कनेक्ट करना होगा। उदाहरण के लिए tf.train.Example का TFRecord लें। tfx_bsl TFExampleRecord डेटा कनेक्टर प्रदान करता है, और इसे tfdv.GenerateStatistics API से कैसे कनेक्ट करें इसका एक उदाहरण नीचे दिया गया है।
import tensorflow_data_validation as tfdv
from tfx_bsl.public import tfxio
import apache_beam as beam
from tensorflow_metadata.proto.v0 import statistics_pb2
DATA_LOCATION = ''
OUTPUT_LOCATION = ''
with beam.Pipeline() as p:
_ = (
p
# 1. Read and decode the data with tfx_bsl.
| 'TFXIORead' >> (
tfxio.TFExampleRecord(
file_pattern=[DATA_LOCATION],
telemetry_descriptors=['my', 'tfdv']).BeamSource())
# 2. Invoke TFDV `GenerateStatistics` API to compute the data statistics.
| 'GenerateStatistics' >> tfdv.GenerateStatistics()
# 3. Materialize the generated data statistics.
| 'WriteStatsOutput' >> WriteStatisticsToTFRecord(OUTPUT_LOCATION))
डेटा के टुकड़ों पर आँकड़ों की गणना करना
टीएफडीवी को डेटा के स्लाइस पर आंकड़ों की गणना करने के लिए कॉन्फ़िगर किया जा सकता है। स्लाइसिंग को स्लाइसिंग फ़ंक्शन प्रदान करके सक्षम किया जा सकता है जो एक एरो RecordBatch लेता है और फॉर्म के टुपल्स (slice key, record batch) के अनुक्रम को आउटपुट करता है। टीएफडीवी फीचर वैल्यू आधारित स्लाइसिंग फ़ंक्शन उत्पन्न करने का एक आसान तरीका प्रदान करता है जिसे आंकड़ों की गणना करते समय tfdv.StatsOptions के हिस्से के रूप में प्रदान किया जा सकता है।
जब स्लाइसिंग सक्षम होती है, तो आउटपुट DatasetFeatureStatisticsList प्रोटो में कई DatasetFeatureStatistics प्रोटोज़ होते हैं, प्रत्येक स्लाइस के लिए एक। प्रत्येक स्लाइस को एक अद्वितीय नाम से पहचाना जाता है जिसे DatasetFeatureStatistics proto में डेटासेट नाम के रूप में सेट किया जाता है। डिफ़ॉल्ट रूप से टीएफडीवी कॉन्फ़िगर किए गए स्लाइस के अलावा समग्र डेटासेट के लिए आंकड़ों की गणना करता है।
import tensorflow_data_validation as tfdv
from tensorflow_data_validation.utils import slicing_util
# Slice on country feature (i.e., every unique value of the feature).
slice_fn1 = slicing_util.get_feature_value_slicer(features={'country': None})
# Slice on the cross of country and state feature (i.e., every unique pair of
# values of the cross).
slice_fn2 = slicing_util.get_feature_value_slicer(
features={'country': None, 'state': None})
# Slice on specific values of a feature.
slice_fn3 = slicing_util.get_feature_value_slicer(
features={'age': [10, 50, 70]})
stats_options = tfdv.StatsOptions(
slice_functions=[slice_fn1, slice_fn2, slice_fn3])