
Une fois vos données dans un pipeline TFX, vous pouvez utiliser les composants TFX pour les analyser et les transformer. Vous pouvez utiliser ces outils avant même de former un modèle.
Il existe de nombreuses raisons d’analyser et de transformer vos données :
- Pour trouver des problèmes dans vos données. Les problèmes courants incluent :
- Données manquantes, telles que des entités avec des valeurs vides.
- Étiquettes traitées comme des fonctionnalités, afin que votre modèle puisse jeter un coup d'œil à la bonne réponse pendant l'entraînement.
- Fonctionnalités avec des valeurs en dehors de la plage attendue.
- Anomalies de données.
- Le modèle appris par transfert comporte un prétraitement qui ne correspond pas aux données d'entraînement.
- Concevoir des ensembles de fonctionnalités plus efficaces. Par exemple, vous pouvez identifier :
- Fonctionnalités particulièrement informatives.
- Fonctionnalités redondantes.
- Des fonctionnalités dont l’échelle varie tellement qu’elles peuvent ralentir l’apprentissage.
- Fonctionnalités avec peu ou pas d’informations prédictives uniques.
Les outils TFX peuvent à la fois aider à détecter les bogues de données et à l'ingénierie des fonctionnalités.
Validation des données TensorFlow
- Aperçu
- Validation d'un exemple basé sur un schéma
- Détection du décalage entre la formation et la diffusion
- Détection de dérive
Aperçu
TensorFlow Data Validation identifie les anomalies dans la formation et la diffusion des données, et peut créer automatiquement un schéma en examinant les données. Le composant peut être configuré pour détecter différentes classes d'anomalies dans les données. Ça peut
- Effectuez des contrôles de validité en comparant les statistiques des données à un schéma qui codifie les attentes de l'utilisateur.
- Détectez les écarts entre la formation et la diffusion en comparant des exemples de données d'entraînement et de diffusion.
- Détectez la dérive des données en examinant une série de données.
Nous documentons chacune de ces fonctionnalités indépendamment :
- Validation d'un exemple basé sur un schéma
- Détection du décalage entre la formation et la diffusion
- Détection de dérive
Validation d'un exemple basé sur un schéma
TensorFlow Data Validation identifie toute anomalie dans les données d'entrée en comparant les statistiques de données à un schéma. Le schéma codifie les propriétés que les données d'entrée sont censées satisfaire, telles que les types de données ou les valeurs catégorielles, et peut être modifié ou remplacé par l'utilisateur.
La validation des données Tensorflow est généralement invoquée plusieurs fois dans le contexte du pipeline TFX : (i) pour chaque division obtenue à partir d'ExampleGen, (ii) pour toutes les données pré-transformées utilisées par Transform et (iii) pour toutes les données post-transformation générées par Transformer. Lorsqu'elles sont invoquées dans le contexte de Transform (ii-iii), les options statistiques et les contraintes basées sur le schéma peuvent être définies en définissant stats_options_updater_fn . Ceci est particulièrement utile lors de la validation de données non structurées (par exemple, des fonctionnalités de texte). Voir le code utilisateur pour un exemple.
Fonctionnalités avancées du schéma
Cette section couvre une configuration de schéma plus avancée qui peut aider avec des configurations spéciales.
Caractéristiques clairsemées
Le codage de fonctionnalités éparses dans les exemples introduit généralement plusieurs fonctionnalités qui devraient avoir la même valence pour tous les exemples. Par exemple la fonctionnalité clairsemée :
WeightedCategories = [('CategoryA', 0.3), ('CategoryX', 0.7)]
WeightedCategoriesIndex = ['CategoryA', 'CategoryX']
WeightedCategoriesValue = [0.3, 0.7]
sparse_feature {
name: 'WeightedCategories'
index_feature { name: 'WeightedCategoriesIndex' }
value_feature { name: 'WeightedCategoriesValue' }
}
La définition de fonctionnalité clairsemée nécessite une ou plusieurs fonctionnalités d'index et une fonctionnalité de valeur qui font référence aux fonctionnalités qui existent dans le schéma. La définition explicite de fonctionnalités clairsemées permet à TFDV de vérifier que les valences de toutes les fonctionnalités référencées correspondent.
Certains cas d'utilisation introduisent des restrictions de valence similaires entre les fonctionnalités, mais ne codent pas nécessairement une fonctionnalité clairsemée. L’utilisation d’une fonctionnalité clairsemée devrait vous débloquer, mais n’est pas idéale.
Environnements de schéma
Par défaut, les validations supposent que tous les exemples d'un pipeline adhèrent à un seul schéma. Dans certains cas, l'introduction de légères variations de schéma est nécessaire, par exemple les fonctionnalités utilisées comme étiquettes sont requises lors de la formation (et doivent être validées), mais sont manquantes lors de la diffusion. Les environnements peuvent être utilisés pour exprimer de telles exigences, en particulier default_environment() , in_environment() , not_in_environment() .
Par exemple, supposons qu'une fonctionnalité nommée « LABEL » soit requise pour la formation, mais qu'elle ne soit pas disponible lors de la diffusion. Cela peut s’exprimer par :
- Définissez deux environnements distincts dans le schéma : ["SERVING", "TRAINING"] et associez 'LABEL' uniquement à l'environnement "TRAINING".
- Associez les données d'entraînement à l'environnement "TRAINING" et les données de diffusion à l'environnement "SERVING".
Génération de schéma
Le schéma de données d'entrée est spécifié en tant qu'instance du schéma TensorFlow .
Au lieu de créer manuellement un schéma à partir de zéro, un développeur peut s'appuyer sur la construction automatique de schéma de TensorFlow Data Validation. Plus précisément, TensorFlow Data Validation construit automatiquement un schéma initial basé sur des statistiques calculées sur les données d'entraînement disponibles dans le pipeline. Les utilisateurs peuvent simplement examiner ce schéma généré automatiquement, le modifier si nécessaire, l'archiver dans un système de contrôle de version et l'insérer explicitement dans le pipeline pour une validation ultérieure.
TFDV inclut infer_schema() pour générer automatiquement un schéma. Par exemple:
schema = tfdv.infer_schema(statistics=train_stats)
tfdv.display_schema(schema=schema)
Cela déclenche une génération automatique de schéma basée sur les règles suivantes :
Si un schéma a déjà été généré automatiquement, il est utilisé tel quel.
Sinon, TensorFlow Data Validation examine les statistiques de données disponibles et calcule un schéma approprié pour les données.
Remarque : Le schéma généré automatiquement est un effort optimal et tente uniquement de déduire les propriétés de base des données. Il est attendu que les utilisateurs l'examinent et le modifient si nécessaire.
Détection du décalage entre la formation et la diffusion
Aperçu
TensorFlow Data Validation peut détecter un écart de distribution entre les données d'entraînement et de diffusion. L'asymétrie de distribution se produit lorsque la distribution des valeurs de caractéristiques pour les données d'entraînement est très différente de celle des données de diffusion. L'une des principales causes de l'asymétrie de distribution est l'utilisation d'un corpus complètement différent pour la génération de données de formation afin de surmonter le manque de données initiales dans le corpus souhaité. Une autre raison est un mécanisme d'échantillonnage défectueux qui choisit uniquement un sous-échantillon des données de diffusion sur lequel s'entraîner.
Exemple de scénario
Consultez le Guide de démarrage de la validation des données TensorFlow pour plus d'informations sur la configuration de la détection des asymétries de diffusion et d'entraînement.
Détection de dérive
La détection de dérive est prise en charge entre des plages de données consécutives (c'est-à-dire entre la plage N et la plage N+1), par exemple entre différents jours de données d'entraînement. Nous exprimons la dérive en termes de distance L-infini pour les caractéristiques catégorielles et de divergence approximative de Jensen-Shannon pour les caractéristiques numériques. Vous pouvez définir la distance seuil afin de recevoir des avertissements lorsque la dérive est supérieure à ce qui est acceptable. Définir la distance correcte est généralement un processus itératif nécessitant des connaissances et des expérimentations dans le domaine.
Consultez le Guide de démarrage de la validation des données TensorFlow pour plus d'informations sur la configuration de la détection de dérive.
Utiliser des visualisations pour vérifier vos données
TensorFlow Data Validation fournit des outils permettant de visualiser la distribution des valeurs des caractéristiques. En examinant ces distributions dans un notebook Jupyter à l'aide de Facets, vous pouvez détecter les problèmes courants liés aux données.
Identifier les distributions suspectes
Vous pouvez identifier les bogues courants dans vos données en utilisant un affichage Aperçu des facettes pour rechercher des distributions suspectes de valeurs de caractéristiques.
Données déséquilibrées
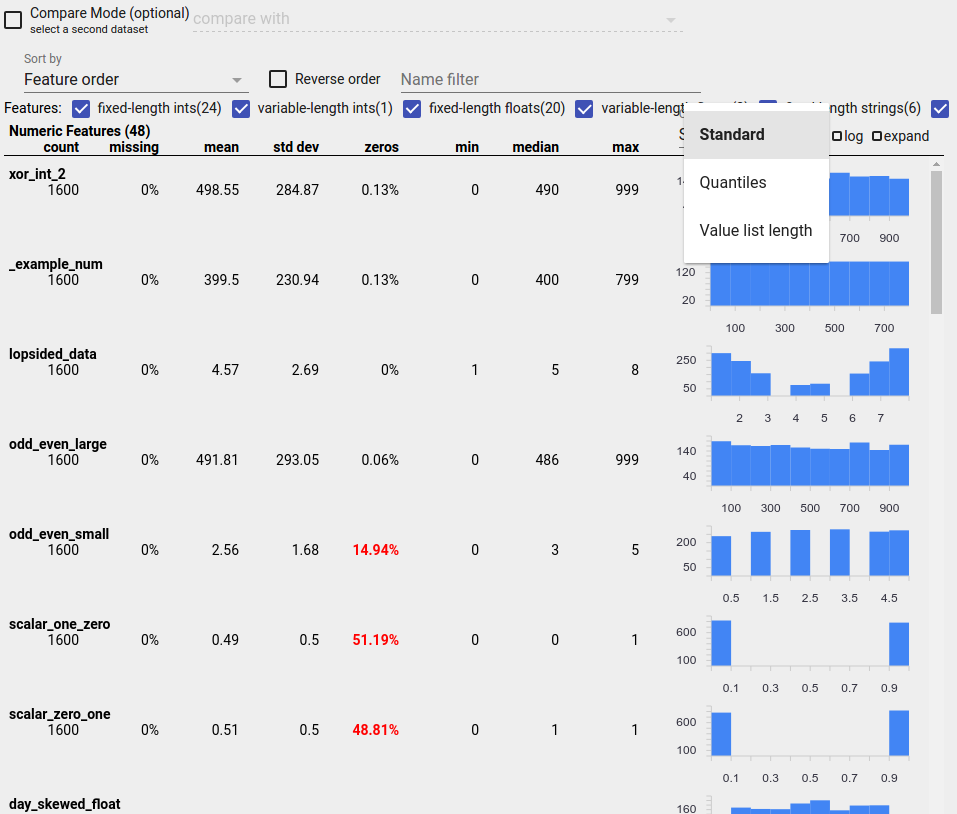
Une fonctionnalité déséquilibrée est une fonctionnalité pour laquelle une valeur prédomine. Des fonctionnalités déséquilibrées peuvent se produire naturellement, mais si une fonctionnalité a toujours la même valeur, vous pouvez avoir un bug de données. Pour détecter des fonctionnalités déséquilibrées dans un aperçu des facettes, choisissez « Non-uniformité » dans la liste déroulante « Trier par ».
Les fonctionnalités les plus déséquilibrées seront répertoriées en haut de chaque liste de types de fonctionnalités. Par exemple, la capture d'écran suivante montre une fonctionnalité composée uniquement de zéros et une seconde très déséquilibrée, en haut de la liste « Fonctionnalités numériques » :

Données uniformément distribuées
Une caractéristique uniformément distribuée est une caractéristique pour laquelle toutes les valeurs possibles apparaissent à peu près à la même fréquence. Comme pour les données déséquilibrées, cette répartition peut se produire naturellement, mais peut également être produite par des bogues de données.
Pour détecter les caractéristiques uniformément distribuées dans un aperçu des facettes, choisissez « Non-uniformité » dans la liste déroulante « Trier par » et cochez la case « Ordre inverse » :

Les données de chaîne sont représentées à l'aide de graphiques à barres s'il existe 20 valeurs uniques ou moins, et sous forme de graphique de distribution cumulative s'il existe plus de 20 valeurs uniques. Ainsi, pour les données de chaîne, les distributions uniformes peuvent apparaître soit sous forme de graphiques à barres plates comme celui ci-dessus, soit sous forme de lignes droites comme celui ci-dessous :

Bogues pouvant produire des données uniformément distribuées
Voici quelques bogues courants qui peuvent produire des données uniformément distribuées :
Utiliser des chaînes pour représenter des types de données autres que des chaînes, tels que des dates. Par exemple, vous aurez de nombreuses valeurs uniques pour une fonctionnalité datetime avec des représentations telles que "2017-03-01-11-45-03". Les valeurs uniques seront distribuées uniformément.
Y compris des indices tels que « numéro de ligne » en tant que fonctionnalités. Là encore, vous avez de nombreuses valeurs uniques.
Données manquantes
Pour vérifier si une caractéristique manque entièrement de valeurs :
- Choisissez « Montant manquant/zéro » dans la liste déroulante « Trier par ».
- Cochez la case "Ordre inverse".
- Regardez la colonne "manquant" pour voir le pourcentage d'instances avec des valeurs manquantes pour une fonctionnalité.
Un bug de données peut également entraîner des valeurs de fonctionnalités incomplètes. Par exemple, vous pouvez vous attendre à ce que la liste de valeurs d'une fonctionnalité comporte toujours trois éléments et découvrir que parfois elle n'en contient qu'un. Pour rechercher des valeurs incomplètes ou d'autres cas dans lesquels les listes de valeurs de caractéristiques ne contiennent pas le nombre d'éléments attendu :
Choisissez « Longueur de la liste de valeurs » dans le menu déroulant « Graphique à afficher » sur la droite.
Regardez le graphique à droite de chaque ligne de fonctionnalités. Le graphique montre la plage de longueurs de liste de valeurs pour la fonctionnalité. Par exemple, la ligne en surbrillance dans la capture d'écran ci-dessous montre une fonctionnalité qui comporte des listes de valeurs de longueur nulle :

Grandes différences d’échelle entre les fonctionnalités
Si l'échelle de vos fonctionnalités varie considérablement, le modèle peut avoir des difficultés à apprendre. Par exemple, si certaines fonctionnalités varient de 0 à 1 et d’autres de 0 à 1 000 000 000, vous avez une grande différence d’échelle. Comparez les colonnes « max » et « min » entre les fonctionnalités pour trouver des échelles très variables.
Envisagez de normaliser les valeurs des caractéristiques pour réduire ces grandes variations.
Étiquettes avec des étiquettes non valides
Les estimateurs de TensorFlow ont des restrictions sur le type de données qu'ils acceptent comme étiquettes. Par exemple, les classificateurs binaires ne fonctionnent généralement qu'avec les étiquettes {0, 1}.
Examinez les valeurs des étiquettes dans la vue d'ensemble des facettes et assurez-vous qu'elles sont conformes aux exigences des estimateurs .