Logiciels de traitement de texte pour TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
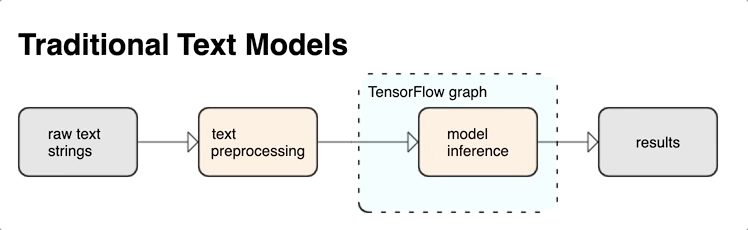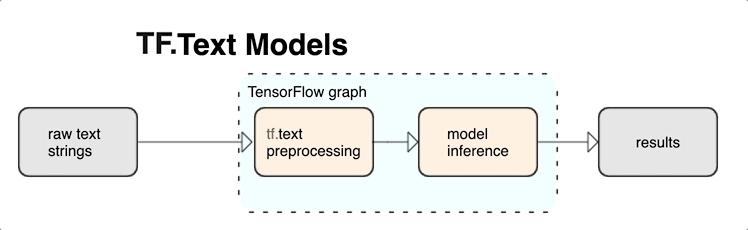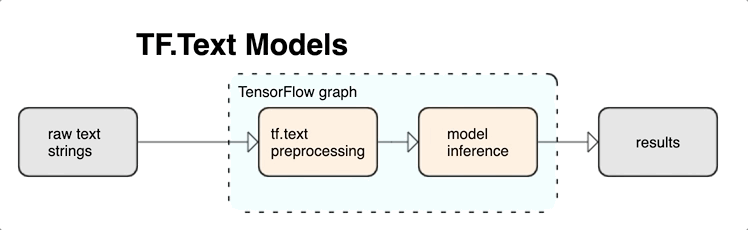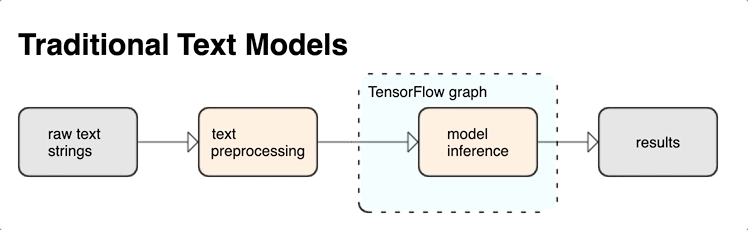
TensorFlow offre une riche collection d'opérations et de bibliothèques pour vous aider à utiliser des entrées au format texte, comme des documents ou des chaînes de texte brut. Ces bibliothèques peuvent exécuter le prétraitement fréquemment requis par les modèles basés sur le texte et incluent d'autres fonctionnalités utiles pour la modélisation des séquences.
Vous pouvez extraire des caractéristiques textuelles sémantiques et syntaxiques puissantes depuis le graphe TensorFlow sous forme d'entrée pour votre réseau de neurones.
L'intégration du prétraitement au graphe TensorFlow offre les avantages suivants :
- Boîte à outils complète pour travailler avec du texte
- Intégration à une suite étendue d'outils Tensorflow pour faciliter le déroulement des projets, de la définition du problème à l'entraînement, sans oublier l'évaluation et le lancement
- Réduction de la complexité au moment de l'inférence et évitement du décalage entraînement/inférence
Outre ces avantages, vous n'avez pas non plus à vous inquiéter d'une différence entre la tokenisation lors de l'entraînement et lors de l'inférence, ni à vous préoccuper des scripts de prétraitement.