Herramientas de procesamiento de texto para TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
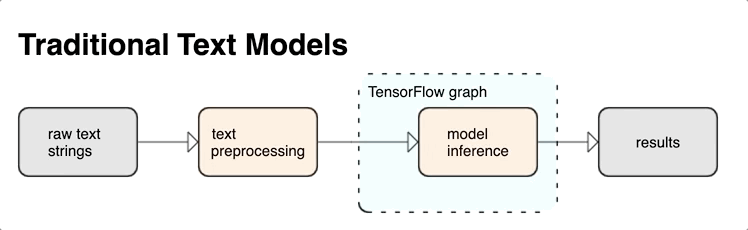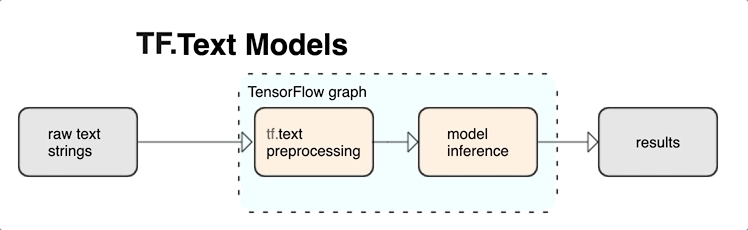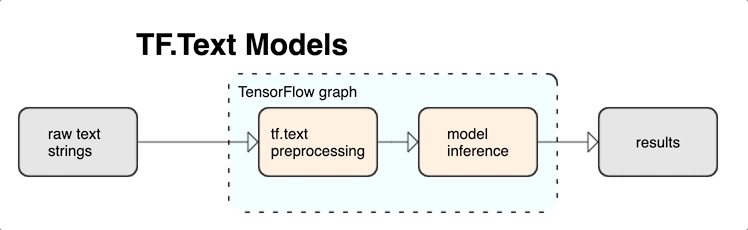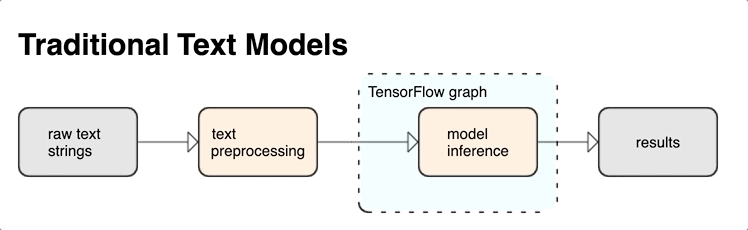
TensorFlow te ofrece una colección amplia de ops y bibliotecas para ayudarte a trabajar con entradas en forma de texto, como strings o documentos de texto sin procesar. Estas bibliotecas pueden realizar el procesamiento previo que requieren normalmente los modelos basados en texto; además, incluyen otras funciones útiles para el modelado de secuencias.
Puedes extraer potentes funciones de texto sintácticas y semánticas desde el grafo de TensorFlow como entrada para tu red neuronal.
Integrar el procesamiento previo con el grafo de TensorFlow ofrece los siguientes beneficios:
- Te brinda un gran kit de herramientas para trabajar con texto.
- Permite la integración con un gran paquete de herramientas de Tensorflow para las distintas etapas de los proyectos, desde la definición de los problemas hasta el entrenamiento, la evaluación y el lanzamiento.
- Reduce la complejidad durante la deriva y evita la desviación entre el entrenamiento y la deriva.
Además de los beneficios mencionados anteriormente, no necesitas preocuparte por que la asignación de token durante el entrenamiento sea diferente de la asignación de token durante la inferencia, ni por administrar secuencias de comandos de procesamiento previo.