Herramientas de procesamiento de texto para TensorFlow
TensorFlow proporciona dos bibliotecas para el procesamiento de texto y lenguaje natural: KerasNLP y TensorFlow Text. KerasNLP es una biblioteca de procesamiento de lenguaje natural (NLP) de alto nivel que incluye modelos modernos basados en transformadores, así como utilidades de tokenización de nivel inferior. Es la solución recomendada para la mayoría de los casos de uso de NLP. Basado en TensorFlow Text, KerasNLP abstrae las operaciones de procesamiento de texto de bajo nivel en una API diseñada para facilitar su uso. Pero si prefiere no trabajar con la API de Keras o si necesita acceso a las operaciones de procesamiento de texto de nivel inferior, puede usar TensorFlow Text directamente.
Keras PNL
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
La forma más fácil de comenzar a procesar texto en TensorFlow es usar KerasNLP. KerasNLP es una biblioteca de procesamiento de lenguaje natural que admite flujos de trabajo creados a partir de componentes modulares que tienen pesos y arquitecturas preestablecidos de última generación. Puede usar los componentes de KerasNLP con su configuración lista para usar. Si necesita más control, puede personalizar fácilmente los componentes. KerasNLP enfatiza el cálculo en gráfico para todos los flujos de trabajo, por lo que puede esperar una fácil producción utilizando el ecosistema TensorFlow.
KerasNLP es una extensión de la API central de Keras y todos los módulos KerasNLP de alto nivel son capas o modelos. Si está familiarizado con Keras, ya comprende la mayor parte de KerasNLP.
Para obtener más información, consulte KerasNLP .
Texto de TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
KerasNLP proporciona módulos de procesamiento de texto de alto nivel que están disponibles como capas o modelos. Si necesita acceder a herramientas de nivel inferior, puede usar TensorFlow Text. TensorFlow Text le brinda una rica colección de operaciones y bibliotecas para ayudarlo a trabajar con entradas en forma de texto, como cadenas de texto sin procesar o documentos. Estas bibliotecas pueden realizar el preprocesamiento que requieren regularmente los modelos basados en texto e incluyen otras características útiles para el modelado de secuencias.
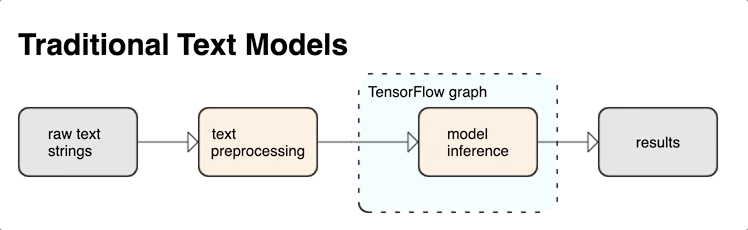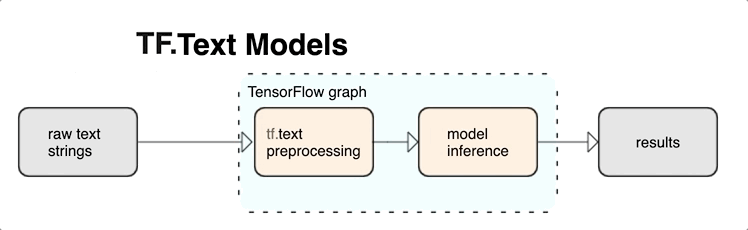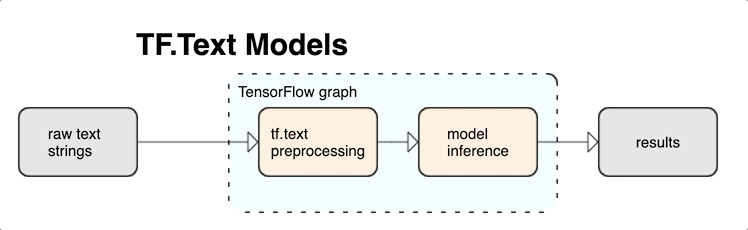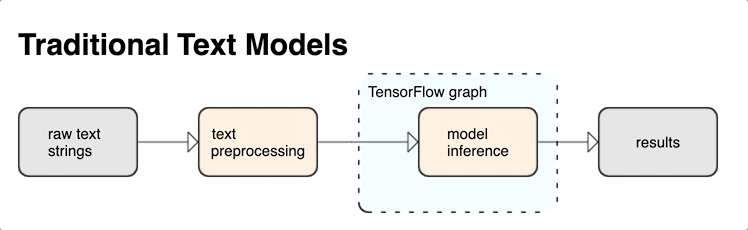
Puede extraer poderosas características de texto sintáctico y semántico desde el interior del gráfico de TensorFlow como entrada a su red neuronal.
La integración del preprocesamiento con el gráfico de TensorFlow brinda los siguientes beneficios:
- Facilita un gran conjunto de herramientas para trabajar con texto.
- Permite la integración con un gran conjunto de herramientas de TensorFlow para respaldar proyectos desde la definición del problema hasta la capacitación, la evaluación y el lanzamiento.
- Reduce la complejidad a la hora de servir y evita el sesgo entre la formación y el servicio
Además de lo anterior, no necesita preocuparse de que la tokenización en el entrenamiento sea diferente de la tokenización en la inferencia o la administración de scripts de preprocesamiento.