
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي كيفية إنشاء نص باستخدام RNN القائم على الأحرف. ستعمل مع مجموعة بيانات من كتابات شكسبير من كتاب أندريه كارباثي " الفعالية غير المعقولة للشبكات العصبية المتكررة" . بالنظر إلى تسلسل الأحرف من هذه البيانات ("شكسبير") ، درب نموذجًا لتوقع الحرف التالي في التسلسل ("هـ"). يمكن إنشاء تسلسلات أطول من النص عن طريق استدعاء النموذج بشكل متكرر.
يتضمن هذا البرنامج التعليمي تعليمات برمجية قابلة للتشغيل تم تنفيذها باستخدام tf.keras والتنفيذ الحثيث. ما يلي هو نموذج الإخراج عندما تم تدريب النموذج في هذا البرنامج التعليمي لمدة 30 حقبة ، وبدأ بالموجه "Q":
QUEENE: I had thought thou hadst a Roman; for the oracle, Thus by All bids the man against the word, Which are so weak of care, by old care done; Your children were in your holy love, And the precipitation through the bleeding throne. BISHOP OF ELY: Marry, and will, my lord, to weep in such a one were prettiest; Yet now I was adopted heir Of the world's lamentable day, To watch the next way with his father with his face? ESCALUS: The cause why then we are all resolved more sons. VOLUMNIA: O, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, it is no sin it should be dead, And love and pale as any will to that word. QUEEN ELIZABETH: But how long have I heard the soul for this world, And show his hands of life be proved to stand. PETRUCHIO: I say he look'd on, if I must be content To stay him from the fatal of our country's bliss. His lordship pluck'd from this sentence then for prey, And then let us twain, being the moon, were she such a case as fills m
في حين أن بعض الجمل نحوية ، إلا أن معظمها ليس له معنى. لم يتعلم النموذج معنى الكلمات ، لكن ضع في اعتبارك:
النموذج قائم على الشخصية. عندما بدأ التدريب ، لم يكن النموذج يعرف كيف يتهجى كلمة إنجليزية ، أو أن تلك الكلمات كانت حتى وحدة نصية.
تشبه بنية الإخراج مسرحية - تبدأ كتل النص عمومًا باسم مكبر الصوت ، بأحرف كبيرة تشبه مجموعة البيانات.
كما هو موضح أدناه ، يتم تدريب النموذج على مجموعات صغيرة من النص (100 حرف لكل منها) ، ولا يزال بإمكانه إنشاء تسلسل أطول من النص بهيكل متماسك.
يثبت
استيراد TensorFlow ومكتبات أخرى
import tensorflow as tf
import numpy as np
import os
import time
قم بتنزيل مجموعة بيانات شكسبير
قم بتغيير السطر التالي لتشغيل هذا الرمز على بياناتك الخاصة.
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt 1122304/1115394 [==============================] - 0s 0us/step 1130496/1115394 [==============================] - 0s 0us/step
اقرأ البيانات
أولاً ، انظر في النص:
# Read, then decode for py2 compat.
text = open(path_to_file, 'rb').read().decode(encoding='utf-8')
# length of text is the number of characters in it
print(f'Length of text: {len(text)} characters')
Length of text: 1115394 characters
# Take a look at the first 250 characters in text
print(text[:250])
First Citizen: Before we proceed any further, hear me speak. All: Speak, speak. First Citizen: You are all resolved rather to die than to famish? All: Resolved. resolved. First Citizen: First, you know Caius Marcius is chief enemy to the people.
# The unique characters in the file
vocab = sorted(set(text))
print(f'{len(vocab)} unique characters')
65 unique characters
معالجة النص
تحويل النص
قبل التدريب ، تحتاج إلى تحويل السلاسل إلى تمثيل رقمي.
يمكن لطبقة tf.keras.layers.StringLookup تحويل كل حرف إلى معرف رقمي. يحتاج فقط إلى تقسيم النص إلى رموز أولاً.
example_texts = ['abcdefg', 'xyz']
chars = tf.strings.unicode_split(example_texts, input_encoding='UTF-8')
chars
<tf.RaggedTensor [[b'a', b'b', b'c', b'd', b'e', b'f', b'g'], [b'x', b'y', b'z']]>
الآن قم بإنشاء طبقة tf.keras.layers.StringLookup :
ids_from_chars = tf.keras.layers.StringLookup(
vocabulary=list(vocab), mask_token=None)
يتم التحويل من الرموز المميزة إلى معرفات الأحرف:
ids = ids_from_chars(chars)
ids
<tf.RaggedTensor [[40, 41, 42, 43, 44, 45, 46], [63, 64, 65]]>
نظرًا لأن الهدف من هذا البرنامج التعليمي هو إنشاء نص ، فسيكون من المهم أيضًا عكس هذا التمثيل واستعادة السلاسل التي يمكن للبشر قراءتها منه. لهذا يمكنك استخدام tf.keras.layers.StringLookup(..., invert=True) .
chars_from_ids = tf.keras.layers.StringLookup(
vocabulary=ids_from_chars.get_vocabulary(), invert=True, mask_token=None)
تستعيد هذه الطبقة الأحرف من متجهات المعرفات ، وتعيدها على هيئة tf.RaggedTensor للأحرف:
chars = chars_from_ids(ids)
chars
<tf.RaggedTensor [[b'a', b'b', b'c', b'd', b'e', b'f', b'g'], [b'x', b'y', b'z']]>
يمكنك tf.strings.reduce_join الأحرف مرة أخرى في سلاسل.
tf.strings.reduce_join(chars, axis=-1).numpy()
array([b'abcdefg', b'xyz'], dtype=object)
def text_from_ids(ids):
return tf.strings.reduce_join(chars_from_ids(ids), axis=-1)
مهمة التنبؤ
بالنظر إلى شخصية ، أو سلسلة من الأحرف ، ما هي الشخصية التالية الأكثر احتمالا؟ هذه هي المهمة التي تقوم بتدريب النموذج على القيام بها. سيكون الإدخال إلى النموذج عبارة عن سلسلة من الأحرف ، وتقوم بتدريب النموذج على التنبؤ بالإخراج — الحرف التالي في كل خطوة زمنية.
نظرًا لأن RNNs تحافظ على حالة داخلية تعتمد على العناصر التي سبق رؤيتها ، بالنظر إلى جميع الأحرف المحسوبة حتى هذه اللحظة ، ما هي الشخصية التالية؟
إنشاء أمثلة التدريب والأهداف
بعد ذلك قسّم النص إلى أمثلة متسلسلة. سيحتوي كل تسلسل إدخال على أحرف seq_length من النص.
لكل تسلسل إدخال ، تحتوي الأهداف المقابلة على نفس طول النص ، باستثناء إزاحة حرف واحد إلى اليمين.
لذا قسّم النص إلى أجزاء seq_length+1 . على سبيل المثال ، لنفترض أن seq_length يساوي 4 ونصنا هو "Hello". تسلسل الإدخال سيكون "Hell" ، والتسلسل الهدف "ello".
للقيام بذلك ، استخدم أولاً الدالة tf.data.Dataset.from_tensor_slices لتحويل متجه النص إلى سلسلة من فهارس الأحرف.
all_ids = ids_from_chars(tf.strings.unicode_split(text, 'UTF-8'))
all_ids
<tf.Tensor: shape=(1115394,), dtype=int64, numpy=array([19, 48, 57, ..., 46, 9, 1])>
ids_dataset = tf.data.Dataset.from_tensor_slices(all_ids)
for ids in ids_dataset.take(10):
print(chars_from_ids(ids).numpy().decode('utf-8'))
F i r s t C i t i
seq_length = 100
examples_per_epoch = len(text)//(seq_length+1)
تتيح لك طريقة batch تحويل هذه الأحرف الفردية بسهولة إلى تسلسلات بالحجم المطلوب.
sequences = ids_dataset.batch(seq_length+1, drop_remainder=True)
for seq in sequences.take(1):
print(chars_from_ids(seq))
tf.Tensor( [b'F' b'i' b'r' b's' b't' b' ' b'C' b'i' b't' b'i' b'z' b'e' b'n' b':' b'\n' b'B' b'e' b'f' b'o' b'r' b'e' b' ' b'w' b'e' b' ' b'p' b'r' b'o' b'c' b'e' b'e' b'd' b' ' b'a' b'n' b'y' b' ' b'f' b'u' b'r' b't' b'h' b'e' b'r' b',' b' ' b'h' b'e' b'a' b'r' b' ' b'm' b'e' b' ' b's' b'p' b'e' b'a' b'k' b'.' b'\n' b'\n' b'A' b'l' b'l' b':' b'\n' b'S' b'p' b'e' b'a' b'k' b',' b' ' b's' b'p' b'e' b'a' b'k' b'.' b'\n' b'\n' b'F' b'i' b'r' b's' b't' b' ' b'C' b'i' b't' b'i' b'z' b'e' b'n' b':' b'\n' b'Y' b'o' b'u' b' '], shape=(101,), dtype=string) 2022-01-26 01:13:19.940550: W tensorflow/core/data/root_dataset.cc:200] Optimization loop failed: CANCELLED: Operation was cancelled
من الأسهل رؤية ما يفعله هذا إذا قمت بضم الرموز المميزة مرة أخرى في سلاسل:
for seq in sequences.take(5):
print(text_from_ids(seq).numpy())
b'First Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou ' b'are all resolved rather to die than to famish?\n\nAll:\nResolved. resolved.\n\nFirst Citizen:\nFirst, you k' b"now Caius Marcius is chief enemy to the people.\n\nAll:\nWe know't, we know't.\n\nFirst Citizen:\nLet us ki" b"ll him, and we'll have corn at our own price.\nIs't a verdict?\n\nAll:\nNo more talking on't; let it be d" b'one: away, away!\n\nSecond Citizen:\nOne word, good citizens.\n\nFirst Citizen:\nWe are accounted poor citi'
للتدريب ، ستحتاج إلى مجموعة بيانات من أزواج (input, label) . حيث input label متواليات. في كل خطوة زمنية يكون الإدخال هو الحرف الحالي والتسمية هي الحرف التالي.
فيما يلي وظيفة تأخذ تسلسلاً كمدخلات وتكرارها وتحويلها لمحاذاة الإدخال والتسمية لكل خطوة زمنية:
def split_input_target(sequence):
input_text = sequence[:-1]
target_text = sequence[1:]
return input_text, target_text
split_input_target(list("Tensorflow"))
(['T', 'e', 'n', 's', 'o', 'r', 'f', 'l', 'o'], ['e', 'n', 's', 'o', 'r', 'f', 'l', 'o', 'w'])
dataset = sequences.map(split_input_target)
for input_example, target_example in dataset.take(1):
print("Input :", text_from_ids(input_example).numpy())
print("Target:", text_from_ids(target_example).numpy())
Input : b'First Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou' Target: b'irst Citizen:\nBefore we proceed any further, hear me speak.\n\nAll:\nSpeak, speak.\n\nFirst Citizen:\nYou '
إنشاء دفعات تدريبية
لقد استخدمت tf.data لتقسيم النص إلى تسلسلات يمكن التحكم فيها. ولكن قبل إدخال هذه البيانات في النموذج ، تحتاج إلى خلط البيانات وتعبئتها في مجموعات.
# Batch size
BATCH_SIZE = 64
# Buffer size to shuffle the dataset
# (TF data is designed to work with possibly infinite sequences,
# so it doesn't attempt to shuffle the entire sequence in memory. Instead,
# it maintains a buffer in which it shuffles elements).
BUFFER_SIZE = 10000
dataset = (
dataset
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE, drop_remainder=True)
.prefetch(tf.data.experimental.AUTOTUNE))
dataset
<PrefetchDataset element_spec=(TensorSpec(shape=(64, 100), dtype=tf.int64, name=None), TensorSpec(shape=(64, 100), dtype=tf.int64, name=None))>
بناء النموذج
يعرّف هذا القسم النموذج على أنه فئة فرعية من طراز keras.Model (لمزيد من التفاصيل ، راجع إنشاء طبقات ونماذج جديدة عبر التصنيف الفرعي ).
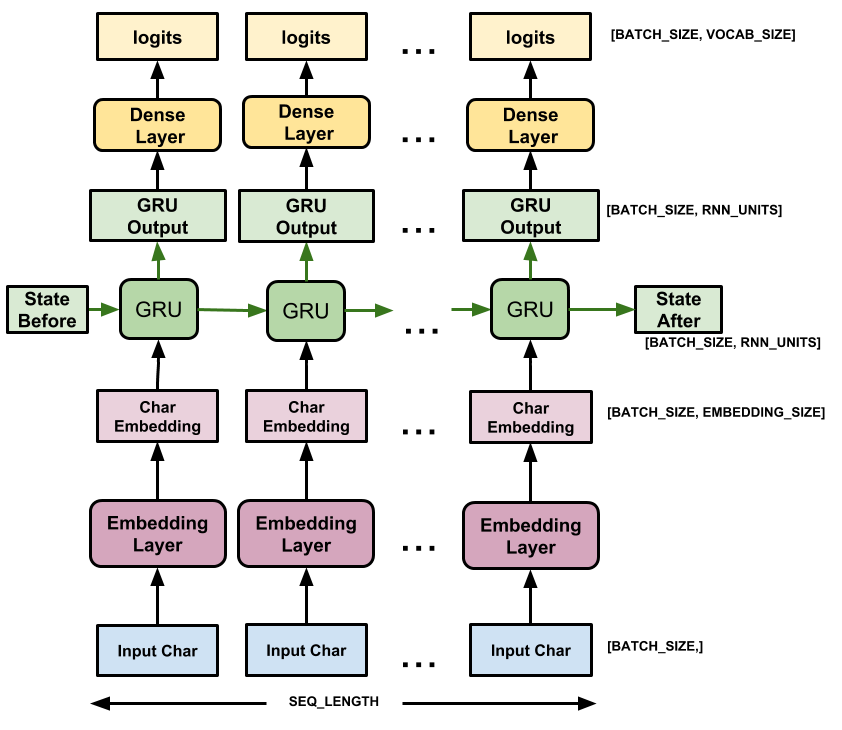
يتكون هذا النموذج من ثلاث طبقات:
-
tf.keras.layers.Embedding: طبقة الإدخال. جدول بحث قابل للتدريب يقوم بتعيين كل معرف حرف إلى متجه بأبعادembedding_dim؛ -
tf.keras.layers.GRU: نوع من RNNunits=rnn_units(يمكنك أيضًا استخدام طبقة LSTM هنا.) -
tf.keras.layers.Dense: الطبقة الناتجة ذات مخرجاتvocab_size. يقوم بإخراج سجل واحد لكل حرف في المفردات. هذه هي احتمالية تسجيل كل حرف وفقًا للنموذج.
# Length of the vocabulary in chars
vocab_size = len(vocab)
# The embedding dimension
embedding_dim = 256
# Number of RNN units
rnn_units = 1024
class MyModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, rnn_units):
super().__init__(self)
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.gru = tf.keras.layers.GRU(rnn_units,
return_sequences=True,
return_state=True)
self.dense = tf.keras.layers.Dense(vocab_size)
def call(self, inputs, states=None, return_state=False, training=False):
x = inputs
x = self.embedding(x, training=training)
if states is None:
states = self.gru.get_initial_state(x)
x, states = self.gru(x, initial_state=states, training=training)
x = self.dense(x, training=training)
if return_state:
return x, states
else:
return x
model = MyModel(
# Be sure the vocabulary size matches the `StringLookup` layers.
vocab_size=len(ids_from_chars.get_vocabulary()),
embedding_dim=embedding_dim,
rnn_units=rnn_units)
لكل حرف ، يبحث النموذج عن التضمين ، ويشغل GRU مرة واحدة مع التضمين كمدخل ، ويطبق الطبقة الكثيفة لإنشاء سجلات تتنبأ باحتمالية تسجيل الحرف التالي:
جرب النموذج
قم الآن بتشغيل النموذج لترى أنه يعمل بالشكل المتوقع.
تحقق أولاً من شكل الإخراج:
for input_example_batch, target_example_batch in dataset.take(1):
example_batch_predictions = model(input_example_batch)
print(example_batch_predictions.shape, "# (batch_size, sequence_length, vocab_size)")
(64, 100, 66) # (batch_size, sequence_length, vocab_size)
في المثال أعلاه ، طول تسلسل الإدخال هو 100 ولكن يمكن تشغيل النموذج على مدخلات بأي طول:
model.summary()
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) multiple 16896
gru (GRU) multiple 3938304
dense (Dense) multiple 67650
=================================================================
Total params: 4,022,850
Trainable params: 4,022,850
Non-trainable params: 0
_________________________________________________________________
للحصول على تنبؤات فعلية من النموذج ، تحتاج إلى أخذ عينات من توزيع الإخراج ، للحصول على فهارس الأحرف الفعلية. يتم تحديد هذا التوزيع من خلال اللوغاريتمات عبر مفردات الأحرف.
جربه كمثال أول في الدفعة:
sampled_indices = tf.random.categorical(example_batch_predictions[0], num_samples=1)
sampled_indices = tf.squeeze(sampled_indices, axis=-1).numpy()
هذا يعطينا ، في كل خطوة ، تنبؤًا بفهرس الحرف التالي:
sampled_indices
array([29, 23, 11, 14, 42, 27, 56, 29, 14, 6, 9, 65, 22, 15, 34, 64, 44,
41, 11, 51, 10, 44, 42, 56, 13, 50, 1, 33, 45, 23, 28, 43, 12, 62,
45, 60, 43, 62, 38, 19, 50, 35, 19, 14, 60, 56, 10, 64, 39, 56, 2,
51, 63, 42, 39, 64, 43, 20, 20, 17, 40, 15, 52, 46, 7, 25, 34, 43,
11, 11, 31, 34, 38, 44, 22, 49, 23, 4, 27, 0, 31, 39, 5, 9, 43,
58, 33, 30, 49, 6, 63, 5, 50, 4, 6, 14, 62, 3, 7, 35])
قم بفك تشفيرها لرؤية النص الذي تنبأ به هذا النموذج غير المدرب:
print("Input:\n", text_from_ids(input_example_batch[0]).numpy())
print()
print("Next Char Predictions:\n", text_from_ids(sampled_indices).numpy())
Input: b":\nWherein the king stands generally condemn'd.\n\nBAGOT:\nIf judgement lie in them, then so do we,\nBeca" Next Char Predictions: b"PJ:AcNqPA'.zIBUyeb:l3ecq?k\nTfJOd;wfudwYFkVFAuq3yZq lxcZydGGDaBmg,LUd::RUYeIjJ\\(N[UNK]RZ&.dsTQj'x&k\\)'Aw!,V"
تدريب النموذج
في هذه المرحلة يمكن التعامل مع المشكلة على أنها مشكلة تصنيف معيارية. بالنظر إلى حالة RNN السابقة ، والإدخال في هذه الخطوة الزمنية ، توقع فئة الحرف التالي.
إرفاق مُحسِّن ووظيفة خسارة
تعمل دالة خسارة tf.keras.losses.sparse_categorical_crossentropy القياسية في هذه الحالة لأنها تُطبق عبر البعد الأخير للتنبؤات.
نظرًا لأن نموذجك يقوم بإرجاع سجلات ، فأنت بحاجة إلى تعيين علامة from_logits .
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True)
example_batch_mean_loss = loss(target_example_batch, example_batch_predictions)
print("Prediction shape: ", example_batch_predictions.shape, " # (batch_size, sequence_length, vocab_size)")
print("Mean loss: ", example_batch_mean_loss)
Prediction shape: (64, 100, 66) # (batch_size, sequence_length, vocab_size) Mean loss: tf.Tensor(4.1895466, shape=(), dtype=float32)
لا ينبغي أن يكون النموذج الذي تمت تهيئته حديثًا متأكدًا جدًا من نفسه ، يجب أن يكون لجميع سجلات الإخراج نفس المقادير. لتأكيد هذا يمكنك التحقق من أن أسي متوسط الخسارة يساوي تقريبًا حجم المفردات. تعني الخسارة الأعلى بكثير أن النموذج متأكد من إجاباته الخاطئة ، وأنه تمت تهيئته بشكل سيئ:
tf.exp(example_batch_mean_loss).numpy()
65.99286
قم بتكوين إجراء التدريب باستخدام طريقة tf.keras.Model.compile . استخدم tf.keras.optimizers.Adam مع الوسيطات الافتراضية ووظيفة الخسارة.
model.compile(optimizer='adam', loss=loss)
تكوين نقاط التفتيش
استخدم tf.keras.callbacks.ModelCheckpoint لضمان حفظ نقاط التفتيش أثناء التدريب:
# Directory where the checkpoints will be saved
checkpoint_dir = './training_checkpoints'
# Name of the checkpoint files
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt_{epoch}")
checkpoint_callback = tf.keras.callbacks.ModelCheckpoint(
filepath=checkpoint_prefix,
save_weights_only=True)
نفذ التدريب
للحفاظ على وقت التدريب معقولاً ، استخدم 10 فترات لتدريب النموذج. في Colab ، اضبط وقت التشغيل على GPU لتدريب أسرع.
EPOCHS = 20
history = model.fit(dataset, epochs=EPOCHS, callbacks=[checkpoint_callback])
Epoch 1/20 172/172 [==============================] - 7s 25ms/step - loss: 2.7409 Epoch 2/20 172/172 [==============================] - 5s 24ms/step - loss: 2.0092 Epoch 3/20 172/172 [==============================] - 5s 24ms/step - loss: 1.7211 Epoch 4/20 172/172 [==============================] - 5s 24ms/step - loss: 1.5550 Epoch 5/20 172/172 [==============================] - 5s 24ms/step - loss: 1.4547 Epoch 6/20 172/172 [==============================] - 5s 24ms/step - loss: 1.3865 Epoch 7/20 172/172 [==============================] - 5s 24ms/step - loss: 1.3325 Epoch 8/20 172/172 [==============================] - 5s 24ms/step - loss: 1.2875 Epoch 9/20 172/172 [==============================] - 5s 24ms/step - loss: 1.2474 Epoch 10/20 172/172 [==============================] - 5s 24ms/step - loss: 1.2066 Epoch 11/20 172/172 [==============================] - 5s 24ms/step - loss: 1.1678 Epoch 12/20 172/172 [==============================] - 5s 24ms/step - loss: 1.1270 Epoch 13/20 172/172 [==============================] - 5s 24ms/step - loss: 1.0842 Epoch 14/20 172/172 [==============================] - 5s 24ms/step - loss: 1.0388 Epoch 15/20 172/172 [==============================] - 5s 24ms/step - loss: 0.9909 Epoch 16/20 172/172 [==============================] - 5s 24ms/step - loss: 0.9409 Epoch 17/20 172/172 [==============================] - 5s 24ms/step - loss: 0.8887 Epoch 18/20 172/172 [==============================] - 5s 24ms/step - loss: 0.8373 Epoch 19/20 172/172 [==============================] - 5s 24ms/step - loss: 0.7849 Epoch 20/20 172/172 [==============================] - 5s 24ms/step - loss: 0.7371
توليد نص
إن أبسط طريقة لإنشاء نص باستخدام هذا النموذج هي تشغيله في حلقة ، وتتبع الحالة الداخلية للنموذج أثناء تنفيذه.
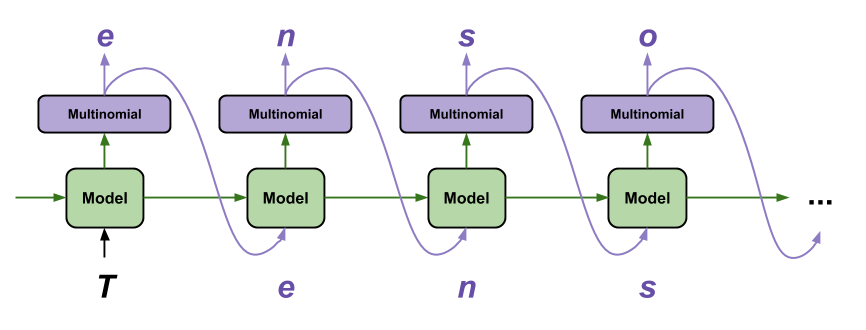
في كل مرة تقوم باستدعاء النموذج تقوم بتمرير بعض النصوص والحالة الداخلية. يُرجع النموذج تنبؤًا للحرف التالي وحالته الجديدة. مرر التوقع وحالة مرة أخرى لمواصلة إنشاء النص.
ما يلي يجعل التنبؤ بخطوة واحدة:
class OneStep(tf.keras.Model):
def __init__(self, model, chars_from_ids, ids_from_chars, temperature=1.0):
super().__init__()
self.temperature = temperature
self.model = model
self.chars_from_ids = chars_from_ids
self.ids_from_chars = ids_from_chars
# Create a mask to prevent "[UNK]" from being generated.
skip_ids = self.ids_from_chars(['[UNK]'])[:, None]
sparse_mask = tf.SparseTensor(
# Put a -inf at each bad index.
values=[-float('inf')]*len(skip_ids),
indices=skip_ids,
# Match the shape to the vocabulary
dense_shape=[len(ids_from_chars.get_vocabulary())])
self.prediction_mask = tf.sparse.to_dense(sparse_mask)
@tf.function
def generate_one_step(self, inputs, states=None):
# Convert strings to token IDs.
input_chars = tf.strings.unicode_split(inputs, 'UTF-8')
input_ids = self.ids_from_chars(input_chars).to_tensor()
# Run the model.
# predicted_logits.shape is [batch, char, next_char_logits]
predicted_logits, states = self.model(inputs=input_ids, states=states,
return_state=True)
# Only use the last prediction.
predicted_logits = predicted_logits[:, -1, :]
predicted_logits = predicted_logits/self.temperature
# Apply the prediction mask: prevent "[UNK]" from being generated.
predicted_logits = predicted_logits + self.prediction_mask
# Sample the output logits to generate token IDs.
predicted_ids = tf.random.categorical(predicted_logits, num_samples=1)
predicted_ids = tf.squeeze(predicted_ids, axis=-1)
# Convert from token ids to characters
predicted_chars = self.chars_from_ids(predicted_ids)
# Return the characters and model state.
return predicted_chars, states
one_step_model = OneStep(model, chars_from_ids, ids_from_chars)
قم بتشغيله في حلقة لتوليد بعض النص. بالنظر إلى النص الذي تم إنشاؤه ، سترى أن النموذج يعرف متى يتم استخدام الأحرف الكبيرة وإنشاء فقرات وتقليد مفردات كتابة تشبه شكسبير. مع قلة فترات التدريب ، لم يتعلم بعد تكوين جمل متماسكة.
start = time.time()
states = None
next_char = tf.constant(['ROMEO:'])
result = [next_char]
for n in range(1000):
next_char, states = one_step_model.generate_one_step(next_char, states=states)
result.append(next_char)
result = tf.strings.join(result)
end = time.time()
print(result[0].numpy().decode('utf-8'), '\n\n' + '_'*80)
print('\nRun time:', end - start)
ROMEO: This is not your comfort, when you see-- Huntsmit, we have already, let us she so hard, Matters there well. Thou camallo, this night, you should her. Gar of all the world to save my life, I'll do well for one boy, and fetch she pass The shadow with others' sole. First Huntsman: O rude blue, come,' to woe, and beat my beauty is ears. An, thither, be ruled betimes, be cruel wonder That hath but adainst my head. Nurse: Peter, your ancest-ticked faint. MIRANDA: More of Hereford, speak you: father, for our gentleman Who do I not? look, soars! CORIOLANUS: Why, sir, what was done to brine? I pray, how many mouth A brave defence speak to us: he has not out To hold my soldiers; like one another smiled Than a mad father's boots, you know, my lord, Where is he was better than you see, of the town, our kindred heart, that would sudden to the worse, An if I met, yet fetch him own. LUCENTIO: I may be relight. MENENIUS: Ay, with sixteen years, finders both, and as the most proportion's mooners ________________________________________________________________________________ Run time: 2.67258358001709
أسهل شيء يمكنك القيام به لتحسين النتائج هو تدريبها لفترة أطول (جرب EPOCHS = 30 ).
يمكنك أيضًا تجربة سلسلة بدء مختلفة ، أو محاولة إضافة طبقة RNN أخرى لتحسين دقة النموذج ، أو ضبط معلمة درجة الحرارة لإنشاء تنبؤات عشوائية أكثر أو أقل.
إذا كنت تريد أن يقوم النموذج بإنشاء نص بشكل أسرع ، فإن أسهل شيء يمكنك القيام به هو تجميع إنشاء النص. في المثال أدناه ، يولد النموذج 5 مخرجات في نفس الوقت تقريبًا الذي استغرقه لتوليد 1 أعلاه.
start = time.time()
states = None
next_char = tf.constant(['ROMEO:', 'ROMEO:', 'ROMEO:', 'ROMEO:', 'ROMEO:'])
result = [next_char]
for n in range(1000):
next_char, states = one_step_model.generate_one_step(next_char, states=states)
result.append(next_char)
result = tf.strings.join(result)
end = time.time()
print(result, '\n\n' + '_'*80)
print('\nRun time:', end - start)
tf.Tensor( [b"ROMEO:\nThe execution forbear that I was a kiss\nA mother in their ownsation with out the rest;\nNor seal'd-me to tell thee joyful? what said Yor Marcius! woe\nThat banish'd unrever-elent I confess\nA husband.\n\nLADY ANNE:\nTo men of summon encest wond\nlike him, Anding your freth hate for vain\nMay hardly slakes meer's name, o' no voice,\nBegail that passing child that valour'd gown?\n\nWARWICK:\nOxford, how much that made the rock Tarpeian?\n\nLUCENTIO:\nImirougester: I am too your freeds.\n\nCAPULET:\nThen I will wash\nBecause the effect of the citizens,\nOur skifts are born. Know the most patards time and will\nwomen! compare of the coronation, I did\nif you find it won to him and I.\n\nROMEO:\nGood evil; get you gone, let me have married me but yet.\n\nWARWICK:\nWhy, thou hast said his hastings? King Henry's head,\nAnd doth our scene stubility in merit ot perils\nHere to revenge, I say, proud queen,\nUnless you hence, my sons of weary perfects;\nReshon'd the prisoner in blood of jocund\nIn every scoutness' gentle Rucuov" b"ROMEO: go. Take it on yon placking for me, if thou didst love so blunt,\nLest old Lucio, whom I defy years, fellow-hands,\nThis very approbation lives.\n\nLADY ANNE:\nThat's your yel; if it come.\n\nKATHARINA:\nI'll pray you, sit,\nPut not your boot of such as they were, at length\nWas grieved for grept Hanting, on my service, kill, kill, kissis;\nAnd yet I was an Edward in every but a\ngreat maker your flesh and gold, another fear,\nAnd this, before your brother's son,\nWith its strange: but he will set upon you.\n\nCORIOLANUS:\nAy, my lord.\n\nFRIAR LAURENCE:\nRomeo! O, ho! first let remembers to piece away.\nThis is the Tower.\n\nThird Citizen:\nBehold, the matter?\n\nDUKE VINCENTIO:\nYou are too blind so many; yet so I did will take Mercutio,\nI may be jogging whiles; he sees it.\n\nCLARENCE:\nMethought that evil weeps so Romeo?\nWho be so heavy? I think they speak,\nBefore she will be flight.\n\nAll:\nOl, is become of such hath call'd hims, study and dance.\nIf that my powerful sings\nshould be a beacheries. Edward as 'lon " b"ROMEO:\nThe son, peace! thy sacred lizer throne,\nRather my tongue upon't. I can, bethick your help!\nJust of a king, woe's stand and love.\n\nBRUTUS:\nI can better divish'd and not all under affect:\nO, be quickly, villain, to report this school,\nI had none seen the dust of Hortensio.\n\nBIANCA:\nGod's good, my lord, to help your rece,ter famina,\nAnd Juliet like my hold, Liest your best:\nTo-morrow that I keep in some villaging\nAnd make her beauty continued in pees.\nMethoughts to London with our bodies in bounting love,\nCompliment by ups my green as I do favours\nWith a precious wind with child by adly way in love\nUnder the world; and so it is the malmsey-butt in\nThe very new offing to your follies.\n\nJULIET:\nCome on, lay here in hazarring her to bring me. I less there\nEscaped for flight, we may do infringe him.\n\nKeeper:\nMy lord, I have no other bent.\nWhere be the ped-she king's great aid;\nIf you'll more entertainment from you betred,\nThe secrets me to keep him soft; to curse the war,\nThe care colour. W" b"ROMEO:\nGood vows. Thou dead to lurp!\nO God! I cannot make, you have desert\nThan my passes to women all hopes with him?\n\nSecond Musician:\nNo, my liege, in gistocking a cockle or a month o' the peoper.\n\nDUKE VINCENTIO:\nNow, hark! the day; and therefore stand at safe\nWill come, to accuse my dusy hath done, upon you\nBut your will make me out in high forget. If you're past me leave,\nIf not, Saint George I bid thee here,\nMy father, eyes; and I fear any think\nTo the purpose magiin: I find thou refuse\nAnd bethink me to the earth the dire part and day strike.\n\nKING EDWARD IV:\nWhat were you lose. Father, I fear\nIs true the liquid dress: but 'tis a wildly\nkindly, proud I am severe;\nThe time shall point your state as voices and chartels\nclow the king's, being rather tell me out.\n\nPOLIXENES:\nA ponder, cord, not title and heart-honour in host;\nAnd call ummised the injury\nAs many as your tert of honour, this steep\nTo your infinity, if thou owest to\nforsworn you word unbrain; for, brings an edg,\nPloceed pas" b"ROMEO:\nNumbering, and may not unking, methinks, Lord Hastings, let him left your\nresolution as I live in solemn-more,\nAs if this still and scars of ceremony,\nShowing, as in a month being rather child,\nLook on my banish'd hands;\nWho after many moticing Romans,\nThat quickly shook like soft and stone with me.\n\nQUEEN MARGARET:\nAnd limp her tender than thy embassist, fines,\nWith enns most kinding eee:\nOr else you do to help him there:\nIf thou behold, by his rapher,\nAnd 'genty men's sake. Awar!\n\nISABELLA:\nO, pardon me, indeed, didst not a friend for aid\nMyself to-night: thou hast proved corooling\nWhom his oath rides of steeded knaves. I am\ngentlemen, you have come to both groan and my love.\n\nLUCIO:\nBador,ly, madam, but ne'er cause the crown,\nAnd, if I live, my lord.\n\nKING LEWIS XI:\nWarwick, Plaunis; and seeing thou hast slain\nThe bastardy of England am alike.'\nThe royal rabot, to appoint their power,\nFor such a day for this for me; so it is\nmoney, and again with lightning breasts: taste\nThese dece"], shape=(5,), dtype=string) ________________________________________________________________________________ Run time: 2.5006580352783203
تصدير المولد
يمكن بسهولة حفظ هذا النموذج المكون من خطوة واحدة واستعادته ، مما يتيح لك استخدامه في أي مكان يُقبل فيه نموذج tf.saved_model .
tf.saved_model.save(one_step_model, 'one_step')
one_step_reloaded = tf.saved_model.load('one_step')
WARNING:tensorflow:Skipping full serialization of Keras layer <__main__.OneStep object at 0x7fbb7c739510>, because it is not built. 2022-01-26 01:15:24.355813: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as gru_cell_layer_call_fn, gru_cell_layer_call_and_return_conditional_losses while saving (showing 2 of 2). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: one_step/assets INFO:tensorflow:Assets written to: one_step/assets
states = None
next_char = tf.constant(['ROMEO:'])
result = [next_char]
for n in range(100):
next_char, states = one_step_reloaded.generate_one_step(next_char, states=states)
result.append(next_char)
print(tf.strings.join(result)[0].numpy().decode("utf-8"))
ROMEO: Take man's, wife, mark me, and be advised. Fool, in the crown, unhappy is the easy throne, Enforced
متقدم: تدريب مخصص
إجراء التدريب أعلاه بسيط ، لكنه لا يمنحك الكثير من التحكم. إنه يستخدم إجبار المعلم الذي يمنع التنبؤات السيئة من العودة إلى النموذج ، لذلك لا يتعلم النموذج أبدًا التعافي من الأخطاء.
الآن بعد أن رأيت كيفية تشغيل النموذج يدويًا بعد ذلك ، ستقوم بتنفيذ حلقة التدريب. يعطي هذا نقطة بداية إذا كنت تريد ، على سبيل المثال ، تنفيذ تعلم المنهج للمساعدة في استقرار ناتج الحلقة المفتوحة للنموذج.
أهم جزء في حلقة التدريب المخصصة هو وظيفة خطوة القطار.
استخدم tf.GradientTape لتتبع التدرجات. يمكنك معرفة المزيد حول هذا الأسلوب من خلال قراءة دليل التنفيذ الحثيث .
الإجراء الأساسي هو:
- نفّذ النموذج واحسب الخسارة ضمن شريط
tf.GradientTape. - احسب التحديثات وقم بتطبيقها على النموذج باستخدام المحسن.
class CustomTraining(MyModel):
@tf.function
def train_step(self, inputs):
inputs, labels = inputs
with tf.GradientTape() as tape:
predictions = self(inputs, training=True)
loss = self.loss(labels, predictions)
grads = tape.gradient(loss, model.trainable_variables)
self.optimizer.apply_gradients(zip(grads, model.trainable_variables))
return {'loss': loss}
يتبع التنفيذ الموضح أعلاه لطريقة train_step اصطلاحات train_step في train_step . هذا اختياري ، لكنه يسمح لك بتغيير سلوك خطوة القطار مع الاستمرار في استخدام أساليب keras ' Model.compile و Model.fit .
model = CustomTraining(
vocab_size=len(ids_from_chars.get_vocabulary()),
embedding_dim=embedding_dim,
rnn_units=rnn_units)
model.compile(optimizer = tf.keras.optimizers.Adam(),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True))
model.fit(dataset, epochs=1)
172/172 [==============================] - 7s 24ms/step - loss: 2.6916 <keras.callbacks.History at 0x7fbb9c5ade90>
أو إذا كنت بحاجة إلى مزيد من التحكم ، فيمكنك كتابة حلقة التدريب المخصصة الكاملة الخاصة بك:
EPOCHS = 10
mean = tf.metrics.Mean()
for epoch in range(EPOCHS):
start = time.time()
mean.reset_states()
for (batch_n, (inp, target)) in enumerate(dataset):
logs = model.train_step([inp, target])
mean.update_state(logs['loss'])
if batch_n % 50 == 0:
template = f"Epoch {epoch+1} Batch {batch_n} Loss {logs['loss']:.4f}"
print(template)
# saving (checkpoint) the model every 5 epochs
if (epoch + 1) % 5 == 0:
model.save_weights(checkpoint_prefix.format(epoch=epoch))
print()
print(f'Epoch {epoch+1} Loss: {mean.result().numpy():.4f}')
print(f'Time taken for 1 epoch {time.time() - start:.2f} sec')
print("_"*80)
model.save_weights(checkpoint_prefix.format(epoch=epoch))
Epoch 1 Batch 0 Loss 2.1412 Epoch 1 Batch 50 Loss 2.0362 Epoch 1 Batch 100 Loss 1.9721 Epoch 1 Batch 150 Loss 1.8361 Epoch 1 Loss: 1.9732 Time taken for 1 epoch 5.90 sec ________________________________________________________________________________ Epoch 2 Batch 0 Loss 1.8170 Epoch 2 Batch 50 Loss 1.6815 Epoch 2 Batch 100 Loss 1.6288 Epoch 2 Batch 150 Loss 1.6625 Epoch 2 Loss: 1.6989 Time taken for 1 epoch 5.19 sec ________________________________________________________________________________ Epoch 3 Batch 0 Loss 1.6405 Epoch 3 Batch 50 Loss 1.5635 Epoch 3 Batch 100 Loss 1.5912 Epoch 3 Batch 150 Loss 1.5241 Epoch 3 Loss: 1.5428 Time taken for 1 epoch 5.33 sec ________________________________________________________________________________ Epoch 4 Batch 0 Loss 1.4469 Epoch 4 Batch 50 Loss 1.4512 Epoch 4 Batch 100 Loss 1.4748 Epoch 4 Batch 150 Loss 1.4077 Epoch 4 Loss: 1.4462 Time taken for 1 epoch 5.30 sec ________________________________________________________________________________ Epoch 5 Batch 0 Loss 1.3798 Epoch 5 Batch 50 Loss 1.3727 Epoch 5 Batch 100 Loss 1.3793 Epoch 5 Batch 150 Loss 1.3883 Epoch 5 Loss: 1.3793 Time taken for 1 epoch 5.41 sec ________________________________________________________________________________ Epoch 6 Batch 0 Loss 1.3024 Epoch 6 Batch 50 Loss 1.3325 Epoch 6 Batch 100 Loss 1.3483 Epoch 6 Batch 150 Loss 1.3362 Epoch 6 Loss: 1.3283 Time taken for 1 epoch 5.34 sec ________________________________________________________________________________ Epoch 7 Batch 0 Loss 1.2669 Epoch 7 Batch 50 Loss 1.2864 Epoch 7 Batch 100 Loss 1.2498 Epoch 7 Batch 150 Loss 1.2482 Epoch 7 Loss: 1.2832 Time taken for 1 epoch 5.27 sec ________________________________________________________________________________ Epoch 8 Batch 0 Loss 1.2289 Epoch 8 Batch 50 Loss 1.2577 Epoch 8 Batch 100 Loss 1.2070 Epoch 8 Batch 150 Loss 1.2333 Epoch 8 Loss: 1.2436 Time taken for 1 epoch 5.18 sec ________________________________________________________________________________ Epoch 9 Batch 0 Loss 1.2138 Epoch 9 Batch 50 Loss 1.2410 Epoch 9 Batch 100 Loss 1.1898 Epoch 9 Batch 150 Loss 1.2157 Epoch 9 Loss: 1.2038 Time taken for 1 epoch 5.23 sec ________________________________________________________________________________ Epoch 10 Batch 0 Loss 1.1200 Epoch 10 Batch 50 Loss 1.1545 Epoch 10 Batch 100 Loss 1.1688 Epoch 10 Batch 150 Loss 1.1748 Epoch 10 Loss: 1.1642 Time taken for 1 epoch 5.53 sec ________________________________________________________________________________