
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin |
Bu defter dayalı İngiliz çeviri İspanyolca için sekans (seq2seq) modeline ilişkin diziyi trenler Dikkat tabanlı Sinir Makine Çevirisi Yaklaşımlar Etkili . Bu, aşağıdakiler hakkında biraz bilgi sahibi olduğunu varsayan gelişmiş bir örnektir:
- Diziden diziye modeller
- Keras katmanının altındaki TensorFlow temelleri:
- Tensörlerle doğrudan çalışma
- Özel Yazma
keras.Modeller vekeras.layers
Bu mimari biraz modası geçmiş olsa da durumu (gitmeden önce dikkat mekanizmalarının daha derin bir anlayış elde etmek yoluyla çalışmalarına çok yararlı bir proje hala Transformers ).
"? ¿Todavia estan en casa" Bu defterde modeli eğitim sonra, örneğin, bir İspanyol cümle giriş yapabilmek ve İngilizce çevirisini dönecektir: "Evde hala"
Elde edilen model olarak ihraç olan tf.saved_model diğer TensorFlow ortamlarda kullanılabilir, böylece.
Bir oyuncak örneği için çeviri kalitesi makul, ancak oluşturulan dikkat grafiği belki daha ilginç. Bu, çeviri yaparken giriş cümlesinin hangi bölümlerinin modelin dikkatini çektiğini gösterir:
Kurmak
pip install tensorflow_text
import numpy as np
import typing
from typing import Any, Tuple
import tensorflow as tf
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
Bu öğretici, sıfırdan birkaç katman oluşturur; özel ve yerleşik uygulamalar arasında geçiş yapmak istiyorsanız bu değişkeni kullanın.
use_builtins = True
Bu öğretici, şekilleri yanlış almanın kolay olduğu birçok düşük seviye API kullanır. Bu sınıf, öğretici boyunca şekilleri kontrol etmek için kullanılır.
Şekil denetleyicisi
class ShapeChecker():
def __init__(self):
# Keep a cache of every axis-name seen
self.shapes = {}
def __call__(self, tensor, names, broadcast=False):
if not tf.executing_eagerly():
return
if isinstance(names, str):
names = (names,)
shape = tf.shape(tensor)
rank = tf.rank(tensor)
if rank != len(names):
raise ValueError(f'Rank mismatch:\n'
f' found {rank}: {shape.numpy()}\n'
f' expected {len(names)}: {names}\n')
for i, name in enumerate(names):
if isinstance(name, int):
old_dim = name
else:
old_dim = self.shapes.get(name, None)
new_dim = shape[i]
if (broadcast and new_dim == 1):
continue
if old_dim is None:
# If the axis name is new, add its length to the cache.
self.shapes[name] = new_dim
continue
if new_dim != old_dim:
raise ValueError(f"Shape mismatch for dimension: '{name}'\n"
f" found: {new_dim}\n"
f" expected: {old_dim}\n")
Veri
Biz tarafından sağlanan bir dil veri kümesi kullanacağız http://www.manythings.org/anki/ Bu veri kümesi biçiminde dil çeviri çifti içerir:
May I borrow this book? ¿Puedo tomar prestado este libro?
Kullanılabilir çeşitli dilleri var, ancak İngilizce-İspanyolca veri setini kullanacağız.
Veri kümesini indirin ve hazırlayın
Kolaylık olması açısından, bu veri kümesinin bir kopyasını Google Cloud'da barındırdık, ancak kendi kopyanızı da indirebilirsiniz. Veri kümesini indirdikten sonra, verileri hazırlamak için atacağımız adımlar şunlardır:
- Her cümleye belirteç bir başlangıç ve bitiş ekleyin.
- Özel karakterleri kaldırarak cümleleri temizleyin.
- Bir kelime indeksi ve ters kelime indeksi oluşturun (kelime → id ve id → kelimeden eşlenen sözlükler).
- Her cümleyi maksimum uzunluğa yapıştırın.
# Download the file
import pathlib
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = pathlib.Path(path_to_zip).parent/'spa-eng/spa.txt'
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip 2646016/2638744 [==============================] - 0s 0us/step 2654208/2638744 [==============================] - 0s 0us/step
def load_data(path):
text = path.read_text(encoding='utf-8')
lines = text.splitlines()
pairs = [line.split('\t') for line in lines]
inp = [inp for targ, inp in pairs]
targ = [targ for targ, inp in pairs]
return targ, inp
targ, inp = load_data(path_to_file)
print(inp[-1])
Si quieres sonar como un hablante nativo, debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un músico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado.
print(targ[-1])
If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
Bir tf.data veri kümesi oluşturun
Dizeleri bu dizilerden bir oluşturabilir tf.data.Dataset olduğunu karıştırır ve toplu bunları verimli bir şekilde dizeleri:
BUFFER_SIZE = len(inp)
BATCH_SIZE = 64
dataset = tf.data.Dataset.from_tensor_slices((inp, targ)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
for example_input_batch, example_target_batch in dataset.take(1):
print(example_input_batch[:5])
print()
print(example_target_batch[:5])
break
tf.Tensor( [b'No s\xc3\xa9 lo que quiero.' b'\xc2\xbfDeber\xc3\xada repetirlo?' b'Tard\xc3\xa9 m\xc3\xa1s de 2 horas en traducir unas p\xc3\xa1ginas en ingl\xc3\xa9s.' b'A Tom comenz\xc3\xb3 a temerle a Mary.' b'Mi pasatiempo es la lectura.'], shape=(5,), dtype=string) tf.Tensor( [b"I don't know what I want." b'Should I repeat it?' b'It took me more than two hours to translate a few pages of English.' b'Tom became afraid of Mary.' b'My hobby is reading.'], shape=(5,), dtype=string)
Metin ön işleme
Bu eğitimde amaçlarından biri bir olarak ihraç edilebilir bir model oluşturmaktır tf.saved_model . O ihraç modeli kullanışlı hale getirmek için onu almalı tf.string girdileri ve iade tf.string çıkışları: Tüm metin işleme modeli içinde gerçekleşir.
Standardizasyon
Model, sınırlı bir kelime dağarcığına sahip çok dilli metinlerle ilgilenmektedir. Bu nedenle, giriş metnini standartlaştırmak önemli olacaktır.
İlk adım, aksanlı karakterleri bölmek ve uyumluluk karakterlerini ASCII eşdeğerleriyle değiştirmek için Unicode normalleştirmesidir.
tensorflow_text paketi unicode normalleştirmek işlemi içerir:
example_text = tf.constant('¿Todavía está en casa?')
print(example_text.numpy())
print(tf_text.normalize_utf8(example_text, 'NFKD').numpy())
b'\xc2\xbfTodav\xc3\xada est\xc3\xa1 en casa?' b'\xc2\xbfTodavi\xcc\x81a esta\xcc\x81 en casa?'
Unicode normalleştirme, metin standardizasyon işlevindeki ilk adım olacaktır:
def tf_lower_and_split_punct(text):
# Split accecented characters.
text = tf_text.normalize_utf8(text, 'NFKD')
text = tf.strings.lower(text)
# Keep space, a to z, and select punctuation.
text = tf.strings.regex_replace(text, '[^ a-z.?!,¿]', '')
# Add spaces around punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿]', r' \0 ')
# Strip whitespace.
text = tf.strings.strip(text)
text = tf.strings.join(['[START]', text, '[END]'], separator=' ')
return text
print(example_text.numpy().decode())
print(tf_lower_and_split_punct(example_text).numpy().decode())
¿Todavía está en casa? [START] ¿ todavia esta en casa ? [END]
Metin Vektörleştirme
Bu standardizasyon işlevi sarılmış olan tf.keras.layers.TextVectorization jeton dizilerine kelime çıkarma ve giriş metin dönüştürme idare edecek bir tabaka.
max_vocab_size = 5000
input_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
TextVectorization tabakası ve diğer ön işleme tabakalar sahip adapt yöntem. Bu yöntem eğitim verileri zamanında bir devre okur ve gibi bir çok çalışır Model.fix . Bu adapt edilen verilerin dayalı katın başlatır. Burada kelime dağarcığını belirler:
input_text_processor.adapt(inp)
# Here are the first 10 words from the vocabulary:
input_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'que', 'de', 'el', 'a', 'no']
Bu İspanyol'dur TextVectorization kurmak ve şimdi, tabaka .adapt() İngilizce tek:
output_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
output_text_processor.adapt(targ)
output_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'the', 'i', 'to', 'you', 'tom']
Artık bu katmanlar, bir dizi diziyi bir dizi simge kimliğine dönüştürebilir:
example_tokens = input_text_processor(example_input_batch)
example_tokens[:3, :10]
<tf.Tensor: shape=(3, 10), dtype=int64, numpy=
array([[ 2, 9, 17, 22, 5, 48, 4, 3, 0, 0],
[ 2, 13, 177, 1, 12, 3, 0, 0, 0, 0],
[ 2, 120, 35, 6, 290, 14, 2134, 506, 2637, 14]])>
get_vocabulary yöntem metne geri belirteç kimlikleri dönüştürmek için kullanılabilir:
input_vocab = np.array(input_text_processor.get_vocabulary())
tokens = input_vocab[example_tokens[0].numpy()]
' '.join(tokens)
'[START] no se lo que quiero . [END] '
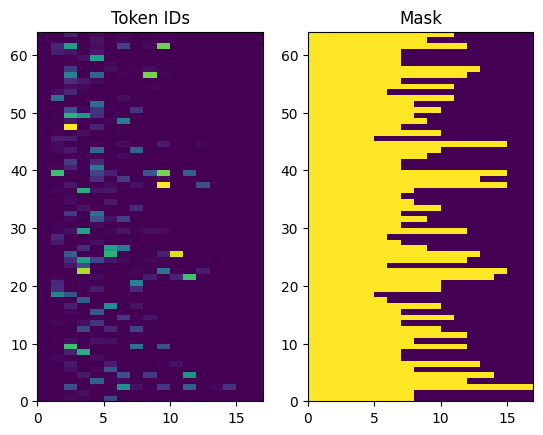
Döndürülen belirteç kimlikleri sıfır dolguludur. Bu kolayca bir maskeye dönüştürülebilir:
plt.subplot(1, 2, 1)
plt.pcolormesh(example_tokens)
plt.title('Token IDs')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')
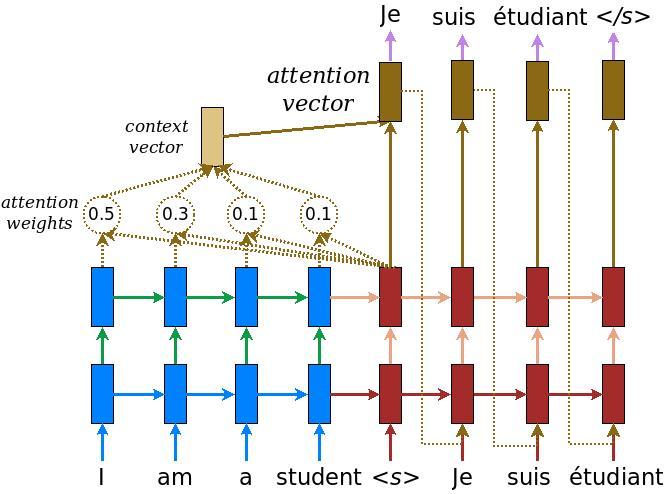
Kodlayıcı/kod çözücü modeli
Aşağıdaki diyagram modele genel bir bakış gösterir. Her zaman adımında, kod çözücünün çıkışı, bir sonraki kelimeyi tahmin etmek için kodlanmış giriş üzerinden ağırlıklı bir toplamla birleştirilir. Diyagramı ve formüller vardır Luong en kağıt .
İçeri girmeden önce model için birkaç sabit tanımlayın:
embedding_dim = 256
units = 1024
kodlayıcı
Yukarıdaki diyagramın mavi kısmı olan kodlayıcıyı oluşturarak başlayın.
kodlayıcı:
- (Dan belirteç kimlikleri listesi Alır
input_text_processor). - Her bir simge için bir gömme vektör yukarı bakar (bir kullanma
layers.Embedding). - Yeni bir dizi halinde katıştırmalarını (a kullanarak işler
layers.GRU). - İadeler:
- İşlenmiş sıra. Bu, dikkat başlığına iletilecektir.
- İç durum. Bu, kod çözücüyü başlatmak için kullanılacaktır.
class Encoder(tf.keras.layers.Layer):
def __init__(self, input_vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.enc_units = enc_units
self.input_vocab_size = input_vocab_size
# The embedding layer converts tokens to vectors
self.embedding = tf.keras.layers.Embedding(self.input_vocab_size,
embedding_dim)
# The GRU RNN layer processes those vectors sequentially.
self.gru = tf.keras.layers.GRU(self.enc_units,
# Return the sequence and state
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, tokens, state=None):
shape_checker = ShapeChecker()
shape_checker(tokens, ('batch', 's'))
# 2. The embedding layer looks up the embedding for each token.
vectors = self.embedding(tokens)
shape_checker(vectors, ('batch', 's', 'embed_dim'))
# 3. The GRU processes the embedding sequence.
# output shape: (batch, s, enc_units)
# state shape: (batch, enc_units)
output, state = self.gru(vectors, initial_state=state)
shape_checker(output, ('batch', 's', 'enc_units'))
shape_checker(state, ('batch', 'enc_units'))
# 4. Returns the new sequence and its state.
return output, state
Şimdiye kadar nasıl bir araya geldiği aşağıda açıklanmıştır:
# Convert the input text to tokens.
example_tokens = input_text_processor(example_input_batch)
# Encode the input sequence.
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
example_enc_output, example_enc_state = encoder(example_tokens)
print(f'Input batch, shape (batch): {example_input_batch.shape}')
print(f'Input batch tokens, shape (batch, s): {example_tokens.shape}')
print(f'Encoder output, shape (batch, s, units): {example_enc_output.shape}')
print(f'Encoder state, shape (batch, units): {example_enc_state.shape}')
Input batch, shape (batch): (64,) Input batch tokens, shape (batch, s): (64, 14) Encoder output, shape (batch, s, units): (64, 14, 1024) Encoder state, shape (batch, units): (64, 1024)
Kodlayıcı, durumunun kod çözücüyü başlatmak için kullanılabilmesi için dahili durumunu döndürür.
Bir RNN'nin, bir diziyi birden çok çağrı üzerinden işleyebilmesi için durumunu döndürmesi de yaygındır. Dekoderi oluştururken bundan daha fazlasını göreceksiniz.
dikkat kafa
Kod çözücü, giriş dizisinin bölümlerine seçici olarak odaklanmak için dikkati kullanır. Dikkat, her örnek için girdi olarak bir dizi vektör alır ve her örnek için bir "dikkat" vektörü döndürür. Bu dikkat tabaka benzer layers.GlobalAveragePoling1D ama dikkat tabakası ağırlıklı ortalama gerçekleştirir.
Bunun nasıl çalıştığına bakalım:


Neresi:
- \(s\) kodlayıcı endeksidir.
- \(t\) dekoder endeksidir.
- \(\alpha_{ts}\) dikkat ağırlık.
- \(h_s\) kodlayıcı çıkışlarının dizisi (dikkat "anahtar" ve transformatörün terminolojisinde "değeri") katıldı ediliyor.
- \(h_t\) dizisi (transformatör terminolojisinde dikkat "sorgusu") devam eden çözücü durumudur.
- \(c_t\) elde edilen bağlam vektörüdür.
- \(a_t\) "bağlam" ve "bir sorgu" birleştirme son verilir.
denklemler:
- Dikkat ağırlıkları, hesaplar \(\alpha_{ts}\)kodlayıcının çıkış dizisinin boyunca, SoftMax olarak,.
- Bağlam vektörünü kodlayıcı çıktılarının ağırlıklı toplamı olarak hesaplar.
Son bir \(score\) fonksiyonu. Görevi, her bir anahtar-sorgu çifti için bir skaler logit puanı hesaplamaktır. İki yaygın yaklaşım vardır:
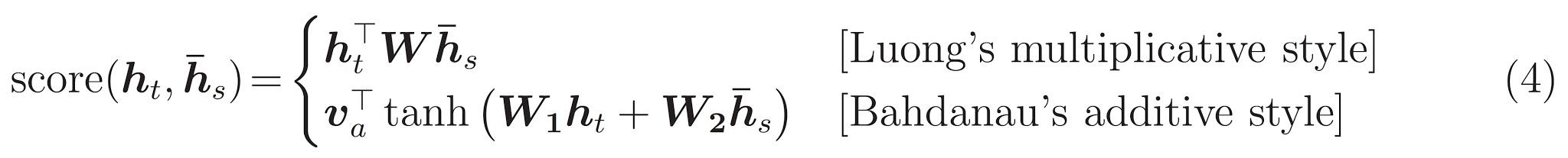
Bu öğretici kullanan Bahdanau en katkı dikkatini . TensorFlow her ikisinin uygulamaları içeren layers.Attention ve layers.AdditiveAttention . Kolları altındaki sınıfı bir çift ağırlık matrisleri layers.Dense tabakaları ve yerleşik uygulanmasını gerektirir.
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
# For Eqn. (4), the Bahdanau attention
self.W1 = tf.keras.layers.Dense(units, use_bias=False)
self.W2 = tf.keras.layers.Dense(units, use_bias=False)
self.attention = tf.keras.layers.AdditiveAttention()
def call(self, query, value, mask):
shape_checker = ShapeChecker()
shape_checker(query, ('batch', 't', 'query_units'))
shape_checker(value, ('batch', 's', 'value_units'))
shape_checker(mask, ('batch', 's'))
# From Eqn. (4), `W1@ht`.
w1_query = self.W1(query)
shape_checker(w1_query, ('batch', 't', 'attn_units'))
# From Eqn. (4), `W2@hs`.
w2_key = self.W2(value)
shape_checker(w2_key, ('batch', 's', 'attn_units'))
query_mask = tf.ones(tf.shape(query)[:-1], dtype=bool)
value_mask = mask
context_vector, attention_weights = self.attention(
inputs = [w1_query, value, w2_key],
mask=[query_mask, value_mask],
return_attention_scores = True,
)
shape_checker(context_vector, ('batch', 't', 'value_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
return context_vector, attention_weights
Dikkat katmanını test edin
Bir oluşturun BahdanauAttention tabakası:
attention_layer = BahdanauAttention(units)
Bu katman 3 girdi alır:
-
query: Bu, daha sonra, dekoder tarafından oluşturulur. -
value: Bu kodlayıcı çıktısı olacak. -
mask: dolgu dışlamak içinexample_tokens != 0
(example_tokens != 0).shape
TensorShape([64, 14])
Dikkat katmanının vektörleştirilmiş uygulaması, bir dizi sorgu vektörü dizisini ve bir dizi değer vektörü dizisini iletmenize izin verir. Sonuç:
- Bir dizi sonuç vektörü, sorguların boyutunu gösterir.
- Bir yığın dikkat boyutu ile, haritalar
(query_length, value_length).
# Later, the decoder will generate this attention query
example_attention_query = tf.random.normal(shape=[len(example_tokens), 2, 10])
# Attend to the encoded tokens
context_vector, attention_weights = attention_layer(
query=example_attention_query,
value=example_enc_output,
mask=(example_tokens != 0))
print(f'Attention result shape: (batch_size, query_seq_length, units): {context_vector.shape}')
print(f'Attention weights shape: (batch_size, query_seq_length, value_seq_length): {attention_weights.shape}')
Attention result shape: (batch_size, query_seq_length, units): (64, 2, 1024) Attention weights shape: (batch_size, query_seq_length, value_seq_length): (64, 2, 14)
Dikkat ağırlıkları toplamı gerekir 1.0 her dizisi için.
Burada en dizileri boyunca dikkat ağırlıklarıdır t=0 :
plt.subplot(1, 2, 1)
plt.pcolormesh(attention_weights[:, 0, :])
plt.title('Attention weights')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')

Çünkü küçük rasgele başlatma dikkat ağırlıkları tüm yakın olan 1/(sequence_length) . Tek bir sırası için ağırlıklar yakınlaştırmak varsa, modeli genişletmek için öğrenmek ve istismar olduğunu bazı küçük farklılıklar olduğuna görebiliriz.
attention_weights.shape
TensorShape([64, 2, 14])
attention_slice = attention_weights[0, 0].numpy()
attention_slice = attention_slice[attention_slice != 0]
plt.suptitle('Attention weights for one sequence')
plt.figure(figsize=(12, 6))
a1 = plt.subplot(1, 2, 1)
plt.bar(range(len(attention_slice)), attention_slice)
# freeze the xlim
plt.xlim(plt.xlim())
plt.xlabel('Attention weights')
a2 = plt.subplot(1, 2, 2)
plt.bar(range(len(attention_slice)), attention_slice)
plt.xlabel('Attention weights, zoomed')
# zoom in
top = max(a1.get_ylim())
zoom = 0.85*top
a2.set_ylim([0.90*top, top])
a1.plot(a1.get_xlim(), [zoom, zoom], color='k')
[<matplotlib.lines.Line2D at 0x7fb42c5b1090>] <Figure size 432x288 with 0 Axes>

kod çözücü
Kod çözücünün işi, bir sonraki çıktı belirteci için tahminler oluşturmaktır.
- Kod çözücü, kodlayıcı çıktısının tamamını alır.
- Şimdiye kadar ne ürettiğini takip etmek için bir RNN kullanır.
- RNN çıktısını, kodlayıcının çıktısı üzerinden dikkat çekmek için sorgu olarak kullanır ve bağlam vektörünü üretir.
- "Dikkat vektörü" oluşturmak için Denklem 3'ü (aşağıda) kullanarak RNN çıktısını ve bağlam vektörünü birleştirir.
- "Dikkat vektörüne" dayalı olarak bir sonraki belirteç için logit tahminleri üretir.

İşte Decoder sınıfı ve başlatıcı. Başlatıcı, gerekli tüm katmanları oluşturur.
class Decoder(tf.keras.layers.Layer):
def __init__(self, output_vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.dec_units = dec_units
self.output_vocab_size = output_vocab_size
self.embedding_dim = embedding_dim
# For Step 1. The embedding layer convets token IDs to vectors
self.embedding = tf.keras.layers.Embedding(self.output_vocab_size,
embedding_dim)
# For Step 2. The RNN keeps track of what's been generated so far.
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
# For step 3. The RNN output will be the query for the attention layer.
self.attention = BahdanauAttention(self.dec_units)
# For step 4. Eqn. (3): converting `ct` to `at`
self.Wc = tf.keras.layers.Dense(dec_units, activation=tf.math.tanh,
use_bias=False)
# For step 5. This fully connected layer produces the logits for each
# output token.
self.fc = tf.keras.layers.Dense(self.output_vocab_size)
call Bu katman için yöntem alır ve çoklu tensörleri döndürür. Bunları basit konteyner sınıfları halinde düzenleyin:
class DecoderInput(typing.NamedTuple):
new_tokens: Any
enc_output: Any
mask: Any
class DecoderOutput(typing.NamedTuple):
logits: Any
attention_weights: Any
İşte uygulanmasıdır call yöntemiyle:
def call(self,
inputs: DecoderInput,
state=None) -> Tuple[DecoderOutput, tf.Tensor]:
shape_checker = ShapeChecker()
shape_checker(inputs.new_tokens, ('batch', 't'))
shape_checker(inputs.enc_output, ('batch', 's', 'enc_units'))
shape_checker(inputs.mask, ('batch', 's'))
if state is not None:
shape_checker(state, ('batch', 'dec_units'))
# Step 1. Lookup the embeddings
vectors = self.embedding(inputs.new_tokens)
shape_checker(vectors, ('batch', 't', 'embedding_dim'))
# Step 2. Process one step with the RNN
rnn_output, state = self.gru(vectors, initial_state=state)
shape_checker(rnn_output, ('batch', 't', 'dec_units'))
shape_checker(state, ('batch', 'dec_units'))
# Step 3. Use the RNN output as the query for the attention over the
# encoder output.
context_vector, attention_weights = self.attention(
query=rnn_output, value=inputs.enc_output, mask=inputs.mask)
shape_checker(context_vector, ('batch', 't', 'dec_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
# Step 4. Eqn. (3): Join the context_vector and rnn_output
# [ct; ht] shape: (batch t, value_units + query_units)
context_and_rnn_output = tf.concat([context_vector, rnn_output], axis=-1)
# Step 4. Eqn. (3): `at = tanh(Wc@[ct; ht])`
attention_vector = self.Wc(context_and_rnn_output)
shape_checker(attention_vector, ('batch', 't', 'dec_units'))
# Step 5. Generate logit predictions:
logits = self.fc(attention_vector)
shape_checker(logits, ('batch', 't', 'output_vocab_size'))
return DecoderOutput(logits, attention_weights), state
Decoder.call = call
Kodlayıcı onun RNN tek bir çağrı ile tam giriş dizisine işler. Dekoderi bu uygulaması verimli eğitilmesi için de yapabilir. Ancak bu öğretici, kod çözücüyü birkaç nedenden dolayı bir döngüde çalıştıracaktır:
- Esneklik: Döngüyü yazmak, eğitim prosedürü üzerinde doğrudan kontrol sahibi olmanızı sağlar.
- Açıklık: Bu maskeleme hile yapmak ve kullanmak mümkündür
layers.RNNveyatfa.seq2seqTek bir çağrı içine bu tüm paketi için API'ler. Ancak bunu bir döngü olarak yazmak daha net olabilir.- Döngü ücretsiz eğitim gösterilmiştir Metin nesil tutiorial.
Şimdi bu kod çözücüyü kullanmayı deneyin.
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
Kod çözücü 4 giriş alır.
-
new_tokens- Son belirteç oluşturulur. Dekoder başlatma"[START]"belirteç. -
enc_output- Tarafından OluşturulduEncoder. -
mask- Bir boolean tensör yerini gösterentokens != 0 -
state- öncekistatedekoderden çıkışı (kod çözücünün RNN iç durumu). GeçişNonebunu sıfıra başlangıç durumuna. Orijinal kağıt, onu kodlayıcının son RNN durumundan başlatır.
# Convert the target sequence, and collect the "[START]" tokens
example_output_tokens = output_text_processor(example_target_batch)
start_index = output_text_processor.get_vocabulary().index('[START]')
first_token = tf.constant([[start_index]] * example_output_tokens.shape[0])
# Run the decoder
dec_result, dec_state = decoder(
inputs = DecoderInput(new_tokens=first_token,
enc_output=example_enc_output,
mask=(example_tokens != 0)),
state = example_enc_state
)
print(f'logits shape: (batch_size, t, output_vocab_size) {dec_result.logits.shape}')
print(f'state shape: (batch_size, dec_units) {dec_state.shape}')
logits shape: (batch_size, t, output_vocab_size) (64, 1, 5000) state shape: (batch_size, dec_units) (64, 1024)
Logitlere göre bir jeton örneği alın:
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
Çıktının ilk kelimesi olarak belirteci deşifre edin:
vocab = np.array(output_text_processor.get_vocabulary())
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['already'],
['plants'],
['pretended'],
['convince'],
['square']], dtype='<U16')
Şimdi ikinci bir logit kümesi oluşturmak için kod çözücüyü kullanın.
- Aynı geçirin
enc_outputvemaskbu değişmemiştir. - Olarak belirteci örneklenmiş geçmek
new_tokens. - Geçiş
decoder_stateRYSA Son seferinde kaldığı yerden bir bellek ile devam böylece, dekoder son kez döndü.
dec_result, dec_state = decoder(
DecoderInput(sampled_token,
example_enc_output,
mask=(example_tokens != 0)),
state=dec_state)
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['nap'],
['mean'],
['worker'],
['passage'],
['baked']], dtype='<U16')
Eğitim
Artık tüm model bileşenlerine sahip olduğunuza göre, modeli eğitmeye başlama zamanı. İhtiyacın olacak:
- Optimizasyonu gerçekleştirmek için bir kayıp işlevi ve optimize edici.
- Her girdi/hedef grubu için modelin nasıl güncelleneceğini tanımlayan bir eğitim adımı işlevi.
- Eğitimi yürütmek ve kontrol noktalarını kaydetmek için bir eğitim döngüsü.
Kayıp fonksiyonunu tanımlayın
class MaskedLoss(tf.keras.losses.Loss):
def __init__(self):
self.name = 'masked_loss'
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def __call__(self, y_true, y_pred):
shape_checker = ShapeChecker()
shape_checker(y_true, ('batch', 't'))
shape_checker(y_pred, ('batch', 't', 'logits'))
# Calculate the loss for each item in the batch.
loss = self.loss(y_true, y_pred)
shape_checker(loss, ('batch', 't'))
# Mask off the losses on padding.
mask = tf.cast(y_true != 0, tf.float32)
shape_checker(mask, ('batch', 't'))
loss *= mask
# Return the total.
return tf.reduce_sum(loss)
Eğitim adımını uygulayın
Bir örnek sınıfı ile başlayın, eğitim süreci olarak uygulanacaktır train_step bu model üzerinde yöntemle. Bkz Özelleştirme uygun detaylar için.
İşte train_step yöntemi etrafında sarıcı _train_step sonra gelecek uygulanması. Bu sarıcı açmak ve kapatmak için bir anahtar içermektedir tf.function daha kolay ayıklama yapmak, derleme.
class TrainTranslator(tf.keras.Model):
def __init__(self, embedding_dim, units,
input_text_processor,
output_text_processor,
use_tf_function=True):
super().__init__()
# Build the encoder and decoder
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.use_tf_function = use_tf_function
self.shape_checker = ShapeChecker()
def train_step(self, inputs):
self.shape_checker = ShapeChecker()
if self.use_tf_function:
return self._tf_train_step(inputs)
else:
return self._train_step(inputs)
Genel için uygulama Model.train_step şöyle yöntemle geçerli:
- Bir toplu alma
input_text, target_textgelentf.data.Dataset. - Bu ham metin girişlerini belirteç yerleştirmelerine ve maskelere dönüştürün.
- Üzerinde kodlayıcı Run
input_tokensalmak içinencoder_outputveencoder_state. - Kod çözücü durumunu ve kaybını başlatın.
- Üzerinde Döngü
target_tokens:- Kod çözücüyü her seferinde bir adım çalıştırın.
- Her adım için kaybı hesaplayın.
- Ortalama kaybı toplayın.
- Kaybının eğimi hesaplayın ve modelin yazılımınızı güncellemeniz optimize edici aracını
trainable_variables.
_preprocess yöntem olup, aşağıdaki ilave uygular # 1 ve # 2 adım:
def _preprocess(self, input_text, target_text):
self.shape_checker(input_text, ('batch',))
self.shape_checker(target_text, ('batch',))
# Convert the text to token IDs
input_tokens = self.input_text_processor(input_text)
target_tokens = self.output_text_processor(target_text)
self.shape_checker(input_tokens, ('batch', 's'))
self.shape_checker(target_tokens, ('batch', 't'))
# Convert IDs to masks.
input_mask = input_tokens != 0
self.shape_checker(input_mask, ('batch', 's'))
target_mask = target_tokens != 0
self.shape_checker(target_mask, ('batch', 't'))
return input_tokens, input_mask, target_tokens, target_mask
TrainTranslator._preprocess = _preprocess
_train_step altına eklenir yöntem, aslında dekoderin çalışan haricinde kalan adımları gerçekleştirir:
def _train_step(self, inputs):
input_text, target_text = inputs
(input_tokens, input_mask,
target_tokens, target_mask) = self._preprocess(input_text, target_text)
max_target_length = tf.shape(target_tokens)[1]
with tf.GradientTape() as tape:
# Encode the input
enc_output, enc_state = self.encoder(input_tokens)
self.shape_checker(enc_output, ('batch', 's', 'enc_units'))
self.shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder's state to the encoder's final state.
# This only works if the encoder and decoder have the same number of
# units.
dec_state = enc_state
loss = tf.constant(0.0)
for t in tf.range(max_target_length-1):
# Pass in two tokens from the target sequence:
# 1. The current input to the decoder.
# 2. The target for the decoder's next prediction.
new_tokens = target_tokens[:, t:t+2]
step_loss, dec_state = self._loop_step(new_tokens, input_mask,
enc_output, dec_state)
loss = loss + step_loss
# Average the loss over all non padding tokens.
average_loss = loss / tf.reduce_sum(tf.cast(target_mask, tf.float32))
# Apply an optimization step
variables = self.trainable_variables
gradients = tape.gradient(average_loss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# Return a dict mapping metric names to current value
return {'batch_loss': average_loss}
TrainTranslator._train_step = _train_step
_loop_step yöntem olup, aşağıdaki ilave kod çözücü yürütür ve artan kaybı ve yeni kod çözücü durumunun (hesaplar dec_state ).
def _loop_step(self, new_tokens, input_mask, enc_output, dec_state):
input_token, target_token = new_tokens[:, 0:1], new_tokens[:, 1:2]
# Run the decoder one step.
decoder_input = DecoderInput(new_tokens=input_token,
enc_output=enc_output,
mask=input_mask)
dec_result, dec_state = self.decoder(decoder_input, state=dec_state)
self.shape_checker(dec_result.logits, ('batch', 't1', 'logits'))
self.shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
self.shape_checker(dec_state, ('batch', 'dec_units'))
# `self.loss` returns the total for non-padded tokens
y = target_token
y_pred = dec_result.logits
step_loss = self.loss(y, y_pred)
return step_loss, dec_state
TrainTranslator._loop_step = _loop_step
Eğitim adımını test edin
Bir İnşa TrainTranslator ve kullanma eğitimi için yapılandırmak Model.compile yöntemi:
translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
use_tf_function=False)
# Configure the loss and optimizer
translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
Test edin train_step . Bunun gibi bir metin modeli için kayıp şurada başlamalıdır:
np.log(output_text_processor.vocabulary_size())
8.517193191416236
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.5849695>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.55271>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.4929113>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.3296022>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=6.80437>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.000246>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.8740363>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.794589>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.3175836>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.108163>}
CPU times: user 5.49 s, sys: 0 ns, total: 5.49 s
Wall time: 5.45 s
Bir olmaksızın Hata ayıklamak kolay olsa tf.function bir performans artışı sağlar yapar. Yani şimdi o _train_step yöntemi çalıştığını, denemek tf.function -wrapped _tf_train_step eğitimi sırasında performansını maksimize etmek,:
@tf.function(input_signature=[[tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])]])
def _tf_train_step(self, inputs):
return self._train_step(inputs)
TrainTranslator._tf_train_step = _tf_train_step
translator.use_tf_function = True
İlk çağrı, işlevi izlediği için yavaş olacaktır.
translator.train_step([example_input_batch, example_target_batch])
2021-12-04 12:09:48.074769: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.180156: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:09:48.285846: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:09:48.307794: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.425447: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node while/body/_1/while/TensorListPushBack_56 was passed float from while/body/_1/while/decoder_1/gru_3/PartitionedCall:6 incompatible with expected variant.
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.045638>}
Ama bundan sonra daha hızlı istekli daha genellikle 2-3x var train_step yöntemiyle:
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.1098256>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.169871>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.139249>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.0410743>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.9664454>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.895707>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.8154407>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.7583396>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.6986444>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.640298>}
CPU times: user 4.4 s, sys: 960 ms, total: 5.36 s
Wall time: 1.67 s
Yeni bir modelin iyi bir testi, tek bir girdi kümesine fazla sığabileceğini görmektir. Deneyin, kayıp hızla sıfıra gitmeli:
losses = []
for n in range(100):
print('.', end='')
logs = translator.train_step([example_input_batch, example_target_batch])
losses.append(logs['batch_loss'].numpy())
print()
plt.plot(losses)
.................................................................................................... [<matplotlib.lines.Line2D at 0x7fb427edf210>]

Artık eğitim adımının işe yaradığından emin olduğunuza göre, sıfırdan eğitmek için modelin yeni bir kopyasını oluşturun:
train_translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor)
# Configure the loss and optimizer
train_translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
Modeli eğit
Kendi özel eğitim döngü yazma uygulamakla şeyin yolunda varken Model.train_step önceki bölümde olduğu gibi yöntem, çalıştırmak için izin verir Model.fit ve önlemek hepsi o kazan plakalı FEC.
Bu eğitimde çağ bir çift için sadece trenler, bu yüzden bir kullanmak callbacks.Callback planlamaktan, toplu kayıplar tarihini toplamak:
class BatchLogs(tf.keras.callbacks.Callback):
def __init__(self, key):
self.key = key
self.logs = []
def on_train_batch_end(self, n, logs):
self.logs.append(logs[self.key])
batch_loss = BatchLogs('batch_loss')
train_translator.fit(dataset, epochs=3,
callbacks=[batch_loss])
Epoch 1/3
2021-12-04 12:10:11.617839: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:11.737105: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:10:11.855054: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:10:11.878896: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:12.004755: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node StatefulPartitionedCall/while/body/_59/while/TensorListPushBack_56 was passed float from StatefulPartitionedCall/while/body/_59/while/decoder_2/gru_5/PartitionedCall:6 incompatible with expected variant.
1859/1859 [==============================] - 349s 185ms/step - batch_loss: 2.0443
Epoch 2/3
1859/1859 [==============================] - 350s 188ms/step - batch_loss: 1.0382
Epoch 3/3
1859/1859 [==============================] - 343s 184ms/step - batch_loss: 0.8085
<keras.callbacks.History at 0x7fb42c3eda10>
plt.plot(batch_loss.logs)
plt.ylim([0, 3])
plt.xlabel('Batch #')
plt.ylabel('CE/token')
Text(0, 0.5, 'CE/token')
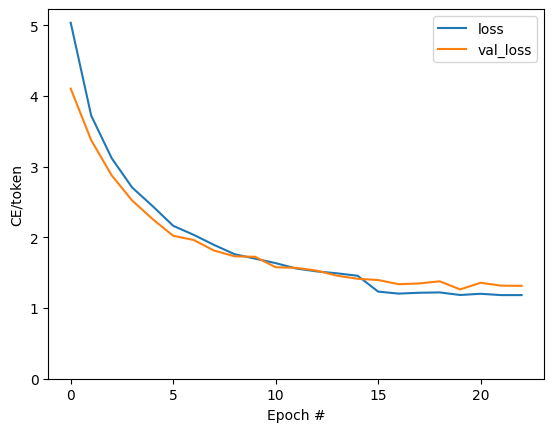
Arsadaki görünür sıçramalar, dönem sınırlarındadır.
Çevirmek
Şimdi modeli eğitimli olduğunu, tam yürütmek için bir işlevi uygulamak text => text çeviri.
Bu modeli ihtiyaç ters çevirmek için için text => token IDs haritalama tarafından sağlanan output_text_processor . Ayrıca özel jetonların kimliklerini de bilmesi gerekir. Bunların hepsi yeni sınıfın yapıcısında uygulanır. Gerçek çeviri yönteminin uygulanması bunu takip edecektir.
Genel olarak bu, her zaman adımında kod çözücüye yapılan girdinin kod çözücünün son tahmininden bir örnek olması dışında eğitim döngüsüne benzer.
class Translator(tf.Module):
def __init__(self, encoder, decoder, input_text_processor,
output_text_processor):
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.output_token_string_from_index = (
tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(),
mask_token='',
invert=True))
# The output should never generate padding, unknown, or start.
index_from_string = tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(), mask_token='')
token_mask_ids = index_from_string(['', '[UNK]', '[START]']).numpy()
token_mask = np.zeros([index_from_string.vocabulary_size()], dtype=np.bool)
token_mask[np.array(token_mask_ids)] = True
self.token_mask = token_mask
self.start_token = index_from_string(tf.constant('[START]'))
self.end_token = index_from_string(tf.constant('[END]'))
translator = Translator(
encoder=train_translator.encoder,
decoder=train_translator.decoder,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:21: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
Belirteç kimliklerini metne dönüştürün
Uygulanması için ilk yöntem olup tokens_to_text , insanlar tarafından okunabilir bir metin belirteç ID'lerinden olan dönüştürür.
def tokens_to_text(self, result_tokens):
shape_checker = ShapeChecker()
shape_checker(result_tokens, ('batch', 't'))
result_text_tokens = self.output_token_string_from_index(result_tokens)
shape_checker(result_text_tokens, ('batch', 't'))
result_text = tf.strings.reduce_join(result_text_tokens,
axis=1, separator=' ')
shape_checker(result_text, ('batch'))
result_text = tf.strings.strip(result_text)
shape_checker(result_text, ('batch',))
return result_text
Translator.tokens_to_text = tokens_to_text
Bazı rastgele belirteç kimlikleri girin ve ne ürettiğini görün:
example_output_tokens = tf.random.uniform(
shape=[5, 2], minval=0, dtype=tf.int64,
maxval=output_text_processor.vocabulary_size())
translator.tokens_to_text(example_output_tokens).numpy()
array([b'vain mysteries', b'funny ham', b'drivers responding',
b'mysterious ignoring', b'fashion votes'], dtype=object)
Kod çözücünün tahminlerinden örnek
Bu işlev, kod çözücünün logit çıktılarını alır ve bu dağıtımdan belirteç kimliklerini örnekler:
def sample(self, logits, temperature):
shape_checker = ShapeChecker()
# 't' is usually 1 here.
shape_checker(logits, ('batch', 't', 'vocab'))
shape_checker(self.token_mask, ('vocab',))
token_mask = self.token_mask[tf.newaxis, tf.newaxis, :]
shape_checker(token_mask, ('batch', 't', 'vocab'), broadcast=True)
# Set the logits for all masked tokens to -inf, so they are never chosen.
logits = tf.where(self.token_mask, -np.inf, logits)
if temperature == 0.0:
new_tokens = tf.argmax(logits, axis=-1)
else:
logits = tf.squeeze(logits, axis=1)
new_tokens = tf.random.categorical(logits/temperature,
num_samples=1)
shape_checker(new_tokens, ('batch', 't'))
return new_tokens
Translator.sample = sample
Bu işlevi bazı rastgele girişlerde test edin:
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
<tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[4506],
[3577],
[2961],
[4586],
[ 944]])>
Çeviri döngüsünü uygulayın
İşte metinden metne çeviri döngüsünün eksiksiz bir uygulaması.
Bu uygulama kullanmadan önce, piton listelerine sonuçları toplayan tf.concat tensörlerin ile birleştirmektir.
Bu uygulama statik olarak ortaya grafiği unrolls max_length tekrarlamalar. Python'da istekli yürütme ile bu sorun değil.
def translate_unrolled(self,
input_text, *,
max_length=50,
return_attention=True,
temperature=1.0):
batch_size = tf.shape(input_text)[0]
input_tokens = self.input_text_processor(input_text)
enc_output, enc_state = self.encoder(input_tokens)
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
result_tokens = []
attention = []
done = tf.zeros([batch_size, 1], dtype=tf.bool)
for _ in range(max_length):
dec_input = DecoderInput(new_tokens=new_tokens,
enc_output=enc_output,
mask=(input_tokens!=0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
attention.append(dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens.append(new_tokens)
if tf.executing_eagerly() and tf.reduce_all(done):
break
# Convert the list of generates token ids to a list of strings.
result_tokens = tf.concat(result_tokens, axis=-1)
result_text = self.tokens_to_text(result_tokens)
if return_attention:
attention_stack = tf.concat(attention, axis=1)
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_unrolled
Basit bir girişte çalıştırın:
%%time
input_text = tf.constant([
'hace mucho frio aqui.', # "It's really cold here."
'Esta es mi vida.', # "This is my life.""
])
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its a long cold here . this is my life . CPU times: user 165 ms, sys: 4.37 ms, total: 169 ms Wall time: 164 ms
Bu modeli vermek istiyorsanız bir de bu yöntemi kaydırmak gerekir tf.function . Bunu yapmaya çalışırsanız, bu temel uygulamanın birkaç sorunu vardır:
- Ortaya çıkan grafikler çok büyüktür ve oluşturulması, kaydedilmesi veya yüklenmesi birkaç saniye sürer.
- Her zaman çalışacak, böylece bir statik unrolled döngüden bozamam
max_lengthyinelemeleri tüm çıkışlar yapmış olsalar bile,. Ancak o zaman bile, istekli yürütmeden marjinal olarak daha hızlıdır.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
Run tf.function bunu derlemek için bir kez:
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 18.8 s, sys: 0 ns, total: 18.8 s Wall time: 18.7 s
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 88 ms
[İsteğe bağlı] Sembolik bir döngü kullanın
def translate_symbolic(self,
input_text,
*,
max_length=50,
return_attention=True,
temperature=1.0):
shape_checker = ShapeChecker()
shape_checker(input_text, ('batch',))
batch_size = tf.shape(input_text)[0]
# Encode the input
input_tokens = self.input_text_processor(input_text)
shape_checker(input_tokens, ('batch', 's'))
enc_output, enc_state = self.encoder(input_tokens)
shape_checker(enc_output, ('batch', 's', 'enc_units'))
shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
shape_checker(new_tokens, ('batch', 't1'))
# Initialize the accumulators
result_tokens = tf.TensorArray(tf.int64, size=1, dynamic_size=True)
attention = tf.TensorArray(tf.float32, size=1, dynamic_size=True)
done = tf.zeros([batch_size, 1], dtype=tf.bool)
shape_checker(done, ('batch', 't1'))
for t in tf.range(max_length):
dec_input = DecoderInput(
new_tokens=new_tokens, enc_output=enc_output, mask=(input_tokens != 0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
attention = attention.write(t, dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
shape_checker(dec_result.logits, ('batch', 't1', 'vocab'))
shape_checker(new_tokens, ('batch', 't1'))
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens = result_tokens.write(t, new_tokens)
if tf.reduce_all(done):
break
# Convert the list of generated token ids to a list of strings.
result_tokens = result_tokens.stack()
shape_checker(result_tokens, ('t', 'batch', 't0'))
result_tokens = tf.squeeze(result_tokens, -1)
result_tokens = tf.transpose(result_tokens, [1, 0])
shape_checker(result_tokens, ('batch', 't'))
result_text = self.tokens_to_text(result_tokens)
shape_checker(result_text, ('batch',))
if return_attention:
attention_stack = attention.stack()
shape_checker(attention_stack, ('t', 'batch', 't1', 's'))
attention_stack = tf.squeeze(attention_stack, 2)
shape_checker(attention_stack, ('t', 'batch', 's'))
attention_stack = tf.transpose(attention_stack, [1, 0, 2])
shape_checker(attention_stack, ('batch', 't', 's'))
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_symbolic
İlk uygulama, çıktıları toplamak için python listelerini kullandı. Bu kullanımlar tf.range izin döngü iterasyon olarak tf.autograph döngü dönüştürmek. Bu uygulamada en büyük değişiklik kullanılmasıdır tf.TensorArray yerine piton list birikir tansörlerine. tf.TensorArray grafik modunda tensörlerinin değişken sayıda toplamak için gereklidir.
İstekli yürütme ile bu uygulama orijinali ile aynı performansı gösterir:
%%time
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 170 ms
Bir sarın Fakat tf.function iki farklar olduğunu göreceksiniz.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
Birincisi: Grafik oluşturma çok daha hızlıdır (~ 10x), bu yaratmaz çünkü max_iterations modelinin kopyaları.
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 1.79 s, sys: 0 ns, total: 1.79 s Wall time: 1.77 s
İkincisi: Derlenmiş işlev, küçük girdilerde (bu örnekte 5x) çok daha hızlıdır, çünkü döngüden çıkabilir.
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 40.1 ms, sys: 0 ns, total: 40.1 ms Wall time: 17.1 ms
Süreci görselleştirin
Tarafından döndürülen dikkat ağırlıkları translate her çıktı belirteci oluştururken modeldi yöntem gösterisi "görünümlü".
Bu nedenle, girdi üzerindeki dikkatin toplamı, hepsini döndürmelidir:
a = result['attention'][0]
print(np.sum(a, axis=-1))
[1.0000001 0.99999994 1. 0.99999994 1. 0.99999994]
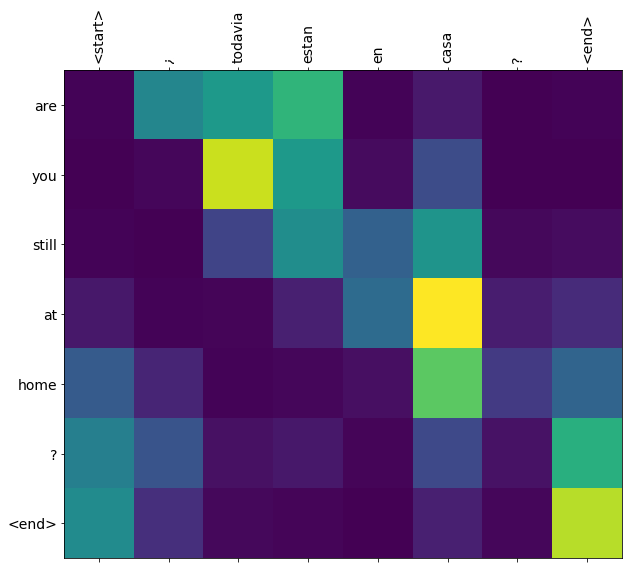
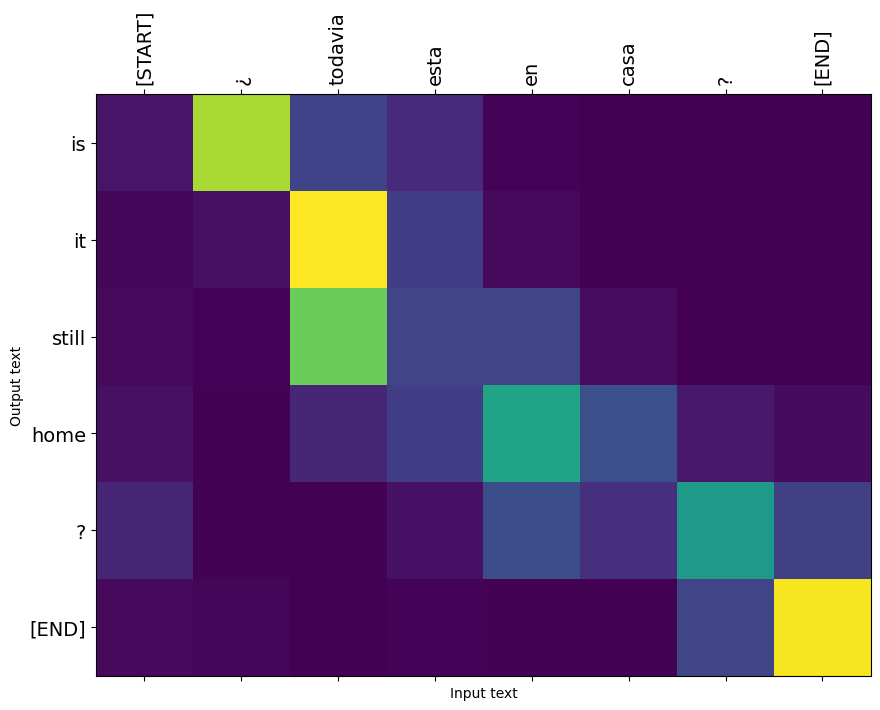
İşte ilk örneğin ilk çıktı adımı için dikkat dağılımı. Dikkatin artık eğitimsiz modele göre çok daha fazla odaklandığına dikkat edin:
_ = plt.bar(range(len(a[0, :])), a[0, :])

Giriş ve çıkış sözcükleri arasında kabaca bir hizalama olduğundan, dikkatin köşegen yakınına odaklanmasını beklersiniz:
plt.imshow(np.array(a), vmin=0.0)
<matplotlib.image.AxesImage at 0x7faf2886ced0>

Daha iyi bir dikkat planı yapmak için bazı kodlar:
Etiketli dikkat grafikleri
def plot_attention(attention, sentence, predicted_sentence):
sentence = tf_lower_and_split_punct(sentence).numpy().decode().split()
predicted_sentence = predicted_sentence.numpy().decode().split() + ['[END]']
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
attention = attention[:len(predicted_sentence), :len(sentence)]
ax.matshow(attention, cmap='viridis', vmin=0.0)
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xlabel('Input text')
ax.set_ylabel('Output text')
plt.suptitle('Attention weights')
i=0
plot_attention(result['attention'][i], input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
Birkaç cümle daha çevirin ve onları çizin:
%%time
three_input_text = tf.constant([
# This is my life.
'Esta es mi vida.',
# Are they still home?
'¿Todavía están en casa?',
# Try to find out.'
'Tratar de descubrir.',
])
result = translator.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? all about killed . CPU times: user 78 ms, sys: 23 ms, total: 101 ms Wall time: 23.1 ms
result['text']
<tf.Tensor: shape=(3,), dtype=string, numpy=
array([b'this is my life .', b'are you still at home ?',
b'all about killed .'], dtype=object)>
i = 0
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 1
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 2
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

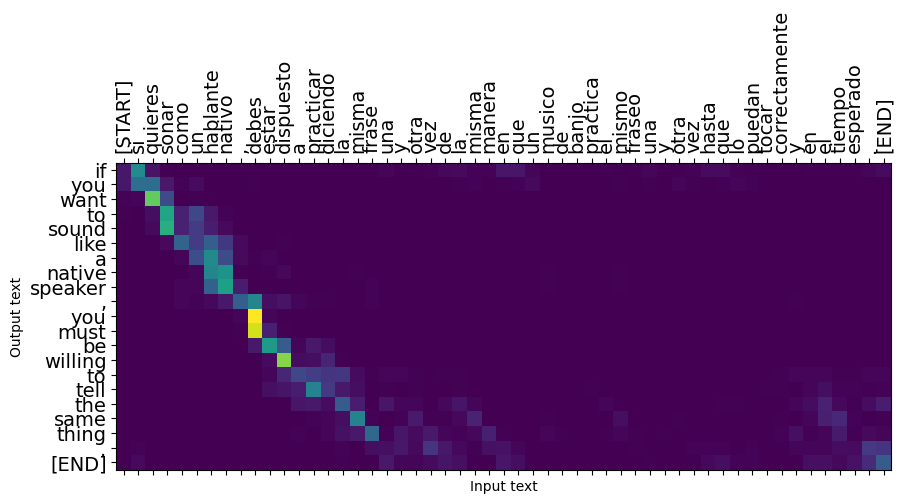
Kısa cümleler genellikle işe yarar, ancak girdi çok uzunsa, model kelimenin tam anlamıyla odağını kaybeder ve makul tahminler sunmayı bırakır. Bunun iki ana nedeni vardır:
- Model, modelin tahminlerinden bağımsız olarak, her adımda doğru belirteci beslemeye zorlayan öğretmenle eğitildi. Model, bazen kendi tahminleriyle beslenseydi daha sağlam hale getirilebilirdi.
- Model, yalnızca RNN durumu aracılığıyla önceki çıktısına erişebilir. RNN durumu bozulursa, modelin kurtarılmasının bir yolu yoktur. Transformers kodlayıcı ve kod çözücü kendinden dikkat kullanarak bunu çöz.
long_input_text = tf.constant([inp[-1]])
import textwrap
print('Expected output:\n', '\n'.join(textwrap.wrap(targ[-1])))
Expected output: If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
result = translator.tf_translate(long_input_text)
i = 0
plot_attention(result['attention'][i], long_input_text[i], result['text'][i])
_ = plt.suptitle('This never works')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
İhracat
Bir kez sizinle şüpheniz yoksa bir model olarak dışa isteyebilirsiniz tf.saved_model oluşturulduğu bu piton programının kullanılması dışından için.
Model bir alt sınıfıdır yana tf.Module (aracılığıyla keras.Model ) ve ihracat için tüm işlevselliği bir derlenmektedir tf.function modeli ile temiz bir şekilde dışa gerekir tf.saved_model.save :
Şimdi işlevi kullanarak ihraç edilebilir takip edildiğini saved_model.save :
tf.saved_model.save(translator, 'translator',
signatures={'serving_default': translator.tf_translate})
2021-12-04 12:27:54.310890: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as encoder_2_layer_call_fn, encoder_2_layer_call_and_return_conditional_losses, decoder_2_layer_call_fn, decoder_2_layer_call_and_return_conditional_losses, embedding_4_layer_call_fn while saving (showing 5 of 60). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: translator/assets INFO:tensorflow:Assets written to: translator/assets
reloaded = tf.saved_model.load('translator')
result = reloaded.tf_translate(three_input_text)
%%time
result = reloaded.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? find out about to find out . CPU times: user 42.8 ms, sys: 7.69 ms, total: 50.5 ms Wall time: 20 ms
Sonraki adımlar
- Farklı veri kümesini indir Fransızlara Almanca veya İngilizce, örneğin, çevirileri deneye İngilizce.
- Daha büyük bir veri kümesinde eğitimle veya daha fazla dönem kullanarak denemeler yapın.
- Deneyin transformatör öğretici benzer çeviri görevi uygular ancak bunun yerine RNNs bir transformatör katmanları kullanır. Bu sürüm aynı zamanda bir kullanır
text.BertTokenizerwordpiece sembolleştirmeyi uygulamaktır. - Göz at tensorflow_addons.seq2seq dizisi modeline dizisinin bu tür uygulamak için.
tfa.seq2seqpaketi gibi üst düzey işlevselliği içerirseq2seq.BeamSearchDecoder.