
| | |  Voir la source sur GitHub Voir la source sur GitHub |
Ce portable forme une séquence à la séquence (seq2seq) modèle pour l' espagnol vers l' anglais basé sur les approches efficaces de Neural traduction automatique en fonction de l' attention- . Il s'agit d'un exemple avancé qui suppose une certaine connaissance de :
- Séquence à séquencer des modèles
- Principes fondamentaux de TensorFlow sous la couche Keras :
- Travailler directement avec des tenseurs
- L' écriture personnalisée
keras.Models etkeras.layers
Bien que cette architecture est quelque peu dépassée , il est encore un projet très utile au travail par le biais d'obtenir une meilleure compréhension des mécanismes d'attention (avant de passer à des transformateurs ).
Après la formation du modèle dans ce cahier, vous serez en mesure d'entrer une phrase espagnole, comme et retourner la traduction anglaise « ¿todavia estan en casa? »: « Êtes - vous toujours à la maison »
Le modèle qui en résulte est exportables comme tf.saved_model , de sorte qu'il peut être utilisé dans d' autres environnements de tensorflow.
La qualité de la traduction est raisonnable pour un exemple de jouet, mais le diagramme d'attention généré est peut-être plus intéressant. Cela montre quelles parties de la phrase d'entrée ont l'attention du modèle lors de la traduction :
Installer
pip install tensorflow_text
import numpy as np
import typing
from typing import Any, Tuple
import tensorflow as tf
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
Ce didacticiel crée quelques couches à partir de zéro, utilisez cette variable si vous souhaitez basculer entre les implémentations personnalisées et intégrées.
use_builtins = True
Ce tutoriel utilise beaucoup d'API de bas niveau où il est facile de se tromper de formes. Cette classe est utilisée pour vérifier les formes tout au long du didacticiel.
Vérificateur de forme
class ShapeChecker():
def __init__(self):
# Keep a cache of every axis-name seen
self.shapes = {}
def __call__(self, tensor, names, broadcast=False):
if not tf.executing_eagerly():
return
if isinstance(names, str):
names = (names,)
shape = tf.shape(tensor)
rank = tf.rank(tensor)
if rank != len(names):
raise ValueError(f'Rank mismatch:\n'
f' found {rank}: {shape.numpy()}\n'
f' expected {len(names)}: {names}\n')
for i, name in enumerate(names):
if isinstance(name, int):
old_dim = name
else:
old_dim = self.shapes.get(name, None)
new_dim = shape[i]
if (broadcast and new_dim == 1):
continue
if old_dim is None:
# If the axis name is new, add its length to the cache.
self.shapes[name] = new_dim
continue
if new_dim != old_dim:
raise ValueError(f"Shape mismatch for dimension: '{name}'\n"
f" found: {new_dim}\n"
f" expected: {old_dim}\n")
Les données
Nous allons utiliser un ensemble de données de langue fournie par http://www.manythings.org/anki/ Cet ensemble de données contient des paires de traduction dans le format suivant :
May I borrow this book? ¿Puedo tomar prestado este libro?
Ils ont une variété de langues disponibles, mais nous utiliserons l'ensemble de données anglais-espagnol.
Télécharger et préparer le jeu de données
Pour plus de commodité, nous avons hébergé une copie de cet ensemble de données sur Google Cloud, mais vous pouvez également télécharger votre propre copie. Après avoir téléchargé l'ensemble de données, voici les étapes à suivre pour préparer les données :
- Ajouter un jeton début et la fin de chaque phrase.
- Nettoyez les phrases en supprimant les caractères spéciaux.
- Créez un index de mots et un index de mots inversé (mappage de dictionnaires de mot → id et id → mot).
- Complétez chaque phrase jusqu'à une longueur maximale.
# Download the file
import pathlib
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = pathlib.Path(path_to_zip).parent/'spa-eng/spa.txt'
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip 2646016/2638744 [==============================] - 0s 0us/step 2654208/2638744 [==============================] - 0s 0us/step
def load_data(path):
text = path.read_text(encoding='utf-8')
lines = text.splitlines()
pairs = [line.split('\t') for line in lines]
inp = [inp for targ, inp in pairs]
targ = [targ for targ, inp in pairs]
return targ, inp
targ, inp = load_data(path_to_file)
print(inp[-1])
Si quieres sonar como un hablante nativo, debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un músico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado.
print(targ[-1])
If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
Créer un ensemble de données tf.data
A partir de ces tableaux de chaînes , vous pouvez créer une tf.data.Dataset de chaînes battages et lots eux efficacement:
BUFFER_SIZE = len(inp)
BATCH_SIZE = 64
dataset = tf.data.Dataset.from_tensor_slices((inp, targ)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
for example_input_batch, example_target_batch in dataset.take(1):
print(example_input_batch[:5])
print()
print(example_target_batch[:5])
break
tf.Tensor( [b'No s\xc3\xa9 lo que quiero.' b'\xc2\xbfDeber\xc3\xada repetirlo?' b'Tard\xc3\xa9 m\xc3\xa1s de 2 horas en traducir unas p\xc3\xa1ginas en ingl\xc3\xa9s.' b'A Tom comenz\xc3\xb3 a temerle a Mary.' b'Mi pasatiempo es la lectura.'], shape=(5,), dtype=string) tf.Tensor( [b"I don't know what I want." b'Should I repeat it?' b'It took me more than two hours to translate a few pages of English.' b'Tom became afraid of Mary.' b'My hobby is reading.'], shape=(5,), dtype=string)
Prétraitement de texte
L' un des objectifs de ce tutoriel est de construire un modèle qui peut être exporté en tant que tf.saved_model . Pour ce modèle exporté utile , il devrait prendre tf.string entrées, et le retour tf.string sorties: Tout le traitement de texte se produit à l' intérieur du modèle.
Standardisation
Le modèle traite du texte multilingue avec un vocabulaire limité. Il sera donc important de standardiser le texte saisi.
La première étape est la normalisation Unicode pour diviser les caractères accentués et remplacer les caractères de compatibilité par leurs équivalents ASCII.
Le tensorflow_text paquet contient une opération de normaliser unicode:
example_text = tf.constant('¿Todavía está en casa?')
print(example_text.numpy())
print(tf_text.normalize_utf8(example_text, 'NFKD').numpy())
b'\xc2\xbfTodav\xc3\xada est\xc3\xa1 en casa?' b'\xc2\xbfTodavi\xcc\x81a esta\xcc\x81 en casa?'
La normalisation Unicode sera la première étape de la fonction de normalisation de texte :
def tf_lower_and_split_punct(text):
# Split accecented characters.
text = tf_text.normalize_utf8(text, 'NFKD')
text = tf.strings.lower(text)
# Keep space, a to z, and select punctuation.
text = tf.strings.regex_replace(text, '[^ a-z.?!,¿]', '')
# Add spaces around punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿]', r' \0 ')
# Strip whitespace.
text = tf.strings.strip(text)
text = tf.strings.join(['[START]', text, '[END]'], separator=' ')
return text
print(example_text.numpy().decode())
print(tf_lower_and_split_punct(example_text).numpy().decode())
¿Todavía está en casa? [START] ¿ todavia esta en casa ? [END]
Vectorisation de texte
Cette fonction de normalisation sera enveloppé dans une tf.keras.layers.TextVectorization couche qui va gérer l'extraction du vocabulaire et de la conversion du texte d'entrée à des séquences de jetons.
max_vocab_size = 5000
input_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
La TextVectorization couche et bien d' autres couches de pré - traitement ont une adapt la méthode. Cette méthode lit une époque des données de formation et travaille beaucoup comme Model.fix . Cette adapt méthode initialise la couche sur la base des données. Ici, il détermine le vocabulaire :
input_text_processor.adapt(inp)
# Here are the first 10 words from the vocabulary:
input_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'que', 'de', 'el', 'a', 'no']
C'est l'espagnol TextVectorization couche, construire maintenant et .adapt() la version anglaise:
output_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
output_text_processor.adapt(targ)
output_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'the', 'i', 'to', 'you', 'tom']
Désormais, ces couches peuvent convertir un lot de chaînes en un lot d'ID de jeton :
example_tokens = input_text_processor(example_input_batch)
example_tokens[:3, :10]
<tf.Tensor: shape=(3, 10), dtype=int64, numpy=
array([[ 2, 9, 17, 22, 5, 48, 4, 3, 0, 0],
[ 2, 13, 177, 1, 12, 3, 0, 0, 0, 0],
[ 2, 120, 35, 6, 290, 14, 2134, 506, 2637, 14]])>
La get_vocabulary méthode peut être utilisée pour convertir les ID de jeton retour au texte:
input_vocab = np.array(input_text_processor.get_vocabulary())
tokens = input_vocab[example_tokens[0].numpy()]
' '.join(tokens)
'[START] no se lo que quiero . [END] '
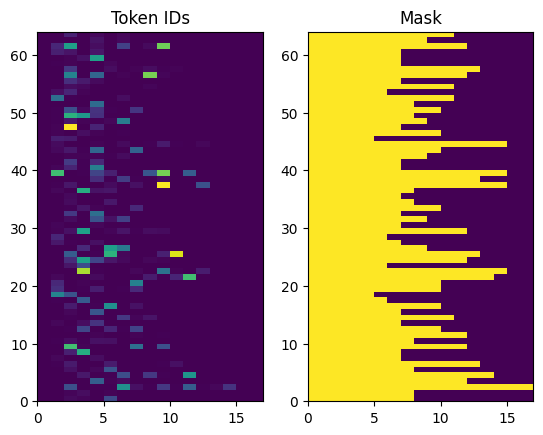
Les ID de jeton renvoyés sont remplis de zéros. Cela peut facilement être transformé en masque:
plt.subplot(1, 2, 1)
plt.pcolormesh(example_tokens)
plt.title('Token IDs')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')
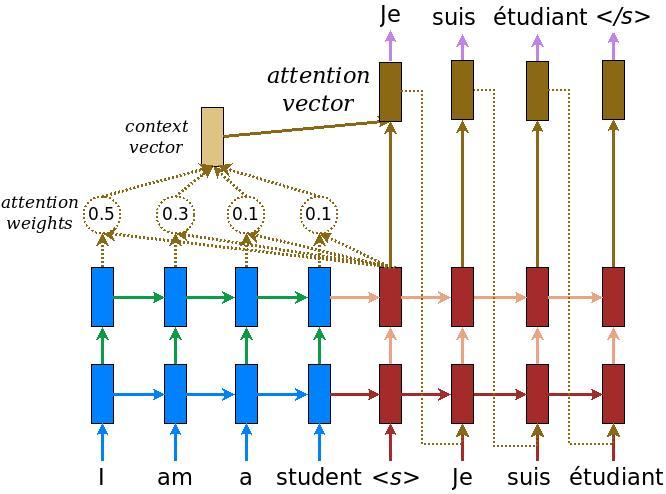
Le modèle encodeur/décodeur
Le schéma suivant montre une vue d'ensemble du modèle. A chaque pas de temps, la sortie du décodeur est combinée avec une somme pondérée sur l'entrée codée, pour prédire le mot suivant. Le diagramme et les formules sont de papier de Luong .
Avant de commencer, définissez quelques constantes pour le modèle :
embedding_dim = 256
units = 1024
L'encodeur
Commencez par construire l'encodeur, la partie bleue du schéma ci-dessus.
L'encodeur :
- Prend une liste d'ID de jeton (de
input_text_processor). - Un vecteur lève les yeux vers l' intégration pour chaque jeton ( L' utilisation d' un
layers.Embedding). - Traite les incorporations dans une nouvelle séquence ( en utilisant un
layers.GRU). - Retour:
- La séquence traitée. Cela sera transmis à la tête d'attention.
- L'état interne. Ceci sera utilisé pour initialiser le décodeur
class Encoder(tf.keras.layers.Layer):
def __init__(self, input_vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.enc_units = enc_units
self.input_vocab_size = input_vocab_size
# The embedding layer converts tokens to vectors
self.embedding = tf.keras.layers.Embedding(self.input_vocab_size,
embedding_dim)
# The GRU RNN layer processes those vectors sequentially.
self.gru = tf.keras.layers.GRU(self.enc_units,
# Return the sequence and state
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, tokens, state=None):
shape_checker = ShapeChecker()
shape_checker(tokens, ('batch', 's'))
# 2. The embedding layer looks up the embedding for each token.
vectors = self.embedding(tokens)
shape_checker(vectors, ('batch', 's', 'embed_dim'))
# 3. The GRU processes the embedding sequence.
# output shape: (batch, s, enc_units)
# state shape: (batch, enc_units)
output, state = self.gru(vectors, initial_state=state)
shape_checker(output, ('batch', 's', 'enc_units'))
shape_checker(state, ('batch', 'enc_units'))
# 4. Returns the new sequence and its state.
return output, state
Voici comment cela s'articule jusqu'à présent :
# Convert the input text to tokens.
example_tokens = input_text_processor(example_input_batch)
# Encode the input sequence.
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
example_enc_output, example_enc_state = encoder(example_tokens)
print(f'Input batch, shape (batch): {example_input_batch.shape}')
print(f'Input batch tokens, shape (batch, s): {example_tokens.shape}')
print(f'Encoder output, shape (batch, s, units): {example_enc_output.shape}')
print(f'Encoder state, shape (batch, units): {example_enc_state.shape}')
Input batch, shape (batch): (64,) Input batch tokens, shape (batch, s): (64, 14) Encoder output, shape (batch, s, units): (64, 14, 1024) Encoder state, shape (batch, units): (64, 1024)
L'encodeur renvoie son état interne afin que son état puisse être utilisé pour initialiser le décodeur.
Il est également courant qu'un RNN renvoie son état afin qu'il puisse traiter une séquence sur plusieurs appels. Vous en verrez plus en construisant le décodeur.
La tête d'attention
Le décodeur utilise l'attention pour se concentrer sélectivement sur des parties de la séquence d'entrée. L'attention prend une séquence de vecteurs en entrée pour chaque exemple et renvoie un vecteur "attention" pour chaque exemple. Cette couche d'attention est similaire à une layers.GlobalAveragePoling1D mais la couche d'attention effectue une moyenne pondérée.
Regardons comment cela fonctionne :


Où:
- \(s\) est l'index du codeur.
- \(t\) est l'indice du décodeur.
- \(\alpha_{ts}\) est le poids d'attention.
- \(h_s\) est la séquence des sorties du codeur étant assisté à (l'attention « clé » et « valeur » dans la terminologie du transformateur).
- \(h_t\) est l'état de décodeur assistant à la séquence (l'attention « requête » dans la terminologie du transformateur).
- \(c_t\) est le vecteur de contexte résultant.
- \(a_t\) est le résultat final combinant le « contexte » et « requête ».
Les équations :
- Calcule le poids de l' attention, \(\alpha_{ts}\), en tant que softmax à travers la séquence de sortie de l'encodeur.
- Calcule le vecteur de contexte comme la somme pondérée des sorties du codeur.
Est le dernier \(score\) fonction. Son travail consiste à calculer un score logit scalaire pour chaque paire clé-requête. Il existe deux approches communes :
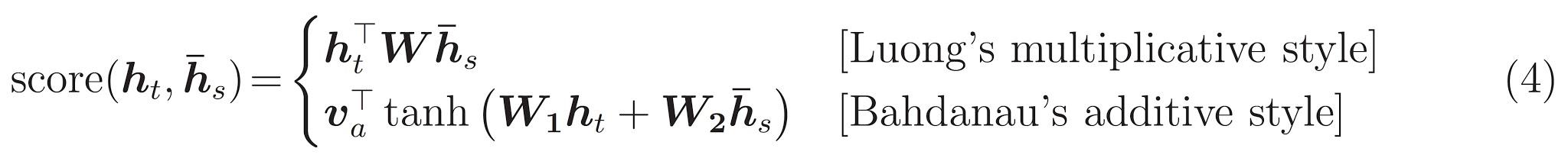
Ce tutoriel utilise l' attention additif de Bahdanau . Tensorflow comprend les mises en œuvre à la fois comme layers.Attention et layers.AdditiveAttention . La classe ci - dessous les poignées de matrices de poids dans une paire de layers.Dense couches, et appelle la mise en œuvre de builtin.
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
# For Eqn. (4), the Bahdanau attention
self.W1 = tf.keras.layers.Dense(units, use_bias=False)
self.W2 = tf.keras.layers.Dense(units, use_bias=False)
self.attention = tf.keras.layers.AdditiveAttention()
def call(self, query, value, mask):
shape_checker = ShapeChecker()
shape_checker(query, ('batch', 't', 'query_units'))
shape_checker(value, ('batch', 's', 'value_units'))
shape_checker(mask, ('batch', 's'))
# From Eqn. (4), `W1@ht`.
w1_query = self.W1(query)
shape_checker(w1_query, ('batch', 't', 'attn_units'))
# From Eqn. (4), `W2@hs`.
w2_key = self.W2(value)
shape_checker(w2_key, ('batch', 's', 'attn_units'))
query_mask = tf.ones(tf.shape(query)[:-1], dtype=bool)
value_mask = mask
context_vector, attention_weights = self.attention(
inputs = [w1_query, value, w2_key],
mask=[query_mask, value_mask],
return_attention_scores = True,
)
shape_checker(context_vector, ('batch', 't', 'value_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
return context_vector, attention_weights
Tester la couche Attention
Créer une BahdanauAttention couche:
attention_layer = BahdanauAttention(units)
Cette couche prend 3 entrées :
- La
query: Ce sera généré par le décodeur, plus tard. - La
value: Ce sera la sortie du codeur. - Le
mask: Pour exclure le rembourrage,example_tokens != 0
(example_tokens != 0).shape
TensorShape([64, 14])
L'implémentation vectorisée de la couche attention vous permet de passer un lot de séquences de vecteurs de requête et un lot de séquence de vecteurs de valeur. Le résultat est:
- Un lot de séquences de vecteurs de résultats de la taille des requêtes.
- Une attention par lots des cartes, avec la taille
(query_length, value_length).
# Later, the decoder will generate this attention query
example_attention_query = tf.random.normal(shape=[len(example_tokens), 2, 10])
# Attend to the encoded tokens
context_vector, attention_weights = attention_layer(
query=example_attention_query,
value=example_enc_output,
mask=(example_tokens != 0))
print(f'Attention result shape: (batch_size, query_seq_length, units): {context_vector.shape}')
print(f'Attention weights shape: (batch_size, query_seq_length, value_seq_length): {attention_weights.shape}')
Attention result shape: (batch_size, query_seq_length, units): (64, 2, 1024) Attention weights shape: (batch_size, query_seq_length, value_seq_length): (64, 2, 14)
Les poids d'attention doit correspondre exactement à 1.0 pour chaque séquence.
Voici les poids d'attention à travers les séquences à t=0 :
plt.subplot(1, 2, 1)
plt.pcolormesh(attention_weights[:, 0, :])
plt.title('Attention weights')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')

En raison de l'initialisation petite aléatoire les poids d'attention sont tous près de 1/(sequence_length) . Si vous effectuez un zoom sur les poids pour une seule séquence, vous pouvez voir qu'il ya une petite variation que le modèle peut apprendre à développer et exploiter.
attention_weights.shape
TensorShape([64, 2, 14])
attention_slice = attention_weights[0, 0].numpy()
attention_slice = attention_slice[attention_slice != 0]
plt.suptitle('Attention weights for one sequence')
plt.figure(figsize=(12, 6))
a1 = plt.subplot(1, 2, 1)
plt.bar(range(len(attention_slice)), attention_slice)
# freeze the xlim
plt.xlim(plt.xlim())
plt.xlabel('Attention weights')
a2 = plt.subplot(1, 2, 2)
plt.bar(range(len(attention_slice)), attention_slice)
plt.xlabel('Attention weights, zoomed')
# zoom in
top = max(a1.get_ylim())
zoom = 0.85*top
a2.set_ylim([0.90*top, top])
a1.plot(a1.get_xlim(), [zoom, zoom], color='k')
[<matplotlib.lines.Line2D at 0x7fb42c5b1090>] <Figure size 432x288 with 0 Axes>

Le décodeur
Le travail du décodeur consiste à générer des prédictions pour le prochain jeton de sortie.
- Le décodeur reçoit la sortie complète du codeur.
- Il utilise un RNN pour garder une trace de ce qu'il a généré jusqu'à présent.
- Il utilise sa sortie RNN comme requête à l'attention sur la sortie de l'encodeur, produisant le vecteur de contexte.
- Il combine la sortie RNN et le vecteur de contexte en utilisant l'équation 3 (ci-dessous) pour générer le "vecteur d'attention".
- Il génère des prédictions logit pour le prochain jeton en fonction du "vecteur d'attention".

Voici le Decoder classe et son initialiseur. L'initialiseur crée toutes les couches nécessaires.
class Decoder(tf.keras.layers.Layer):
def __init__(self, output_vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.dec_units = dec_units
self.output_vocab_size = output_vocab_size
self.embedding_dim = embedding_dim
# For Step 1. The embedding layer convets token IDs to vectors
self.embedding = tf.keras.layers.Embedding(self.output_vocab_size,
embedding_dim)
# For Step 2. The RNN keeps track of what's been generated so far.
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
# For step 3. The RNN output will be the query for the attention layer.
self.attention = BahdanauAttention(self.dec_units)
# For step 4. Eqn. (3): converting `ct` to `at`
self.Wc = tf.keras.layers.Dense(dec_units, activation=tf.math.tanh,
use_bias=False)
# For step 5. This fully connected layer produces the logits for each
# output token.
self.fc = tf.keras.layers.Dense(self.output_vocab_size)
L' call méthode de cette couche prend et renvoie plusieurs tenseurs. Organisez-les en classes de conteneurs simples :
class DecoderInput(typing.NamedTuple):
new_tokens: Any
enc_output: Any
mask: Any
class DecoderOutput(typing.NamedTuple):
logits: Any
attention_weights: Any
Voici la mise en œuvre de l' call méthode:
def call(self,
inputs: DecoderInput,
state=None) -> Tuple[DecoderOutput, tf.Tensor]:
shape_checker = ShapeChecker()
shape_checker(inputs.new_tokens, ('batch', 't'))
shape_checker(inputs.enc_output, ('batch', 's', 'enc_units'))
shape_checker(inputs.mask, ('batch', 's'))
if state is not None:
shape_checker(state, ('batch', 'dec_units'))
# Step 1. Lookup the embeddings
vectors = self.embedding(inputs.new_tokens)
shape_checker(vectors, ('batch', 't', 'embedding_dim'))
# Step 2. Process one step with the RNN
rnn_output, state = self.gru(vectors, initial_state=state)
shape_checker(rnn_output, ('batch', 't', 'dec_units'))
shape_checker(state, ('batch', 'dec_units'))
# Step 3. Use the RNN output as the query for the attention over the
# encoder output.
context_vector, attention_weights = self.attention(
query=rnn_output, value=inputs.enc_output, mask=inputs.mask)
shape_checker(context_vector, ('batch', 't', 'dec_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
# Step 4. Eqn. (3): Join the context_vector and rnn_output
# [ct; ht] shape: (batch t, value_units + query_units)
context_and_rnn_output = tf.concat([context_vector, rnn_output], axis=-1)
# Step 4. Eqn. (3): `at = tanh(Wc@[ct; ht])`
attention_vector = self.Wc(context_and_rnn_output)
shape_checker(attention_vector, ('batch', 't', 'dec_units'))
# Step 5. Generate logit predictions:
logits = self.fc(attention_vector)
shape_checker(logits, ('batch', 't', 'output_vocab_size'))
return DecoderOutput(logits, attention_weights), state
Decoder.call = call
Le codeur traite la séquence d'entrée complète avec un seul appel à son RNN. Cette mise en œuvre du décodeur peut le faire aussi bien pour une formation efficace. Mais ce tutoriel exécutera le décodeur en boucle pour plusieurs raisons :
- Flexibilité : l'écriture de la boucle vous donne un contrôle direct sur la procédure d'entraînement.
- Clarté: Il est possible de faire des tours de masquage et d' utiliser
layers.RNNoutfa.seq2seqAPI pour emballer tout cela en un seul appel. Mais l'écrire sous forme de boucle peut être plus clair.- Une formation gratuite boucle est démontrée dans la génération de texte tutiorial.
Essayez maintenant d'utiliser ce décodeur.
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
Le décodeur prend 4 entrées.
-
new_tokens- Le dernier jeton généré. Initialiser le décodeur avec le"[START]"jeton. -
enc_output- généré par leEncoder. -
mask- Un tenseur booléen indiquant oùtokens != 0 -
state- Le précédentstatede sortie du décodeur (l'état interne du décodeur RNN). PassezNoneà zéro l' initialiser. Le papier d'origine l'initialise à partir de l'état RNN final de l'encodeur.
# Convert the target sequence, and collect the "[START]" tokens
example_output_tokens = output_text_processor(example_target_batch)
start_index = output_text_processor.get_vocabulary().index('[START]')
first_token = tf.constant([[start_index]] * example_output_tokens.shape[0])
# Run the decoder
dec_result, dec_state = decoder(
inputs = DecoderInput(new_tokens=first_token,
enc_output=example_enc_output,
mask=(example_tokens != 0)),
state = example_enc_state
)
print(f'logits shape: (batch_size, t, output_vocab_size) {dec_result.logits.shape}')
print(f'state shape: (batch_size, dec_units) {dec_state.shape}')
logits shape: (batch_size, t, output_vocab_size) (64, 1, 5000) state shape: (batch_size, dec_units) (64, 1024)
Exemple de jeton en fonction des logits :
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
Décodez le jeton comme premier mot de la sortie :
vocab = np.array(output_text_processor.get_vocabulary())
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['already'],
['plants'],
['pretended'],
['convince'],
['square']], dtype='<U16')
Utilisez maintenant le décodeur pour générer un deuxième ensemble de logits.
- Passez la même
enc_outputetmask, ceux - ci n'ont pas changé. - Transmettre le jeton échantillonnée
new_tokens. - Passez le
decoder_statele décodeur est revenu la dernière fois, de sorte que le RNN continue avec une mémoire de l' endroit où il l' avait laissé la dernière fois.
dec_result, dec_state = decoder(
DecoderInput(sampled_token,
example_enc_output,
mask=(example_tokens != 0)),
state=dec_state)
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['nap'],
['mean'],
['worker'],
['passage'],
['baked']], dtype='<U16')
Entraînement
Maintenant que vous disposez de tous les composants du modèle, il est temps de commencer à entraîner le modèle. Tu auras besoin:
- Une fonction de perte et un optimiseur pour effectuer l'optimisation.
- Une fonction d'étape d'apprentissage définissant comment mettre à jour le modèle pour chaque lot d'entrée/cible.
- Une boucle d'entraînement pour piloter l'entraînement et enregistrer des points de contrôle.
Définir la fonction de perte
class MaskedLoss(tf.keras.losses.Loss):
def __init__(self):
self.name = 'masked_loss'
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def __call__(self, y_true, y_pred):
shape_checker = ShapeChecker()
shape_checker(y_true, ('batch', 't'))
shape_checker(y_pred, ('batch', 't', 'logits'))
# Calculate the loss for each item in the batch.
loss = self.loss(y_true, y_pred)
shape_checker(loss, ('batch', 't'))
# Mask off the losses on padding.
mask = tf.cast(y_true != 0, tf.float32)
shape_checker(mask, ('batch', 't'))
loss *= mask
# Return the total.
return tf.reduce_sum(loss)
Mettre en œuvre l'étape de formation
Commencez par une classe de modèle, le processus de formation sera mis en œuvre la train_step méthode sur ce modèle. Voir Personnalisation convient pour les détails.
Ici , la train_step méthode est une enveloppe autour de la _train_step mise en œuvre qui viendra plus tard. Cette enveloppe comprend un interrupteur pour activer et désactiver tf.function compilation, pour rendre plus facile le débogage.
class TrainTranslator(tf.keras.Model):
def __init__(self, embedding_dim, units,
input_text_processor,
output_text_processor,
use_tf_function=True):
super().__init__()
# Build the encoder and decoder
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.use_tf_function = use_tf_function
self.shape_checker = ShapeChecker()
def train_step(self, inputs):
self.shape_checker = ShapeChecker()
if self.use_tf_function:
return self._tf_train_step(inputs)
else:
return self._train_step(inputs)
Dans l' ensemble la mise en œuvre de la Model.train_step méthode est la suivante:
- Recevoir un lot de
input_text, target_textdutf.data.Dataset. - Convertissez ces entrées de texte brut en incorporations de jetons et masques.
- Exécutez l'encodeur sur les
input_tokenspour obtenir leencoder_outputetencoder_state. - Initialiser l'état et la perte du décodeur.
- Boucle sur les
target_tokens:- Exécutez le décodeur une étape à la fois.
- Calculez la perte pour chaque étape.
- Cumulez la perte moyenne.
- Calculer le gradient de la perte et utiliser l'optimiseur pour appliquer les mises à jour à du modèle
trainable_variables.
La _preprocess méthode, ajouté ci - dessous, met en œuvre les étapes # 1 et # 2:
def _preprocess(self, input_text, target_text):
self.shape_checker(input_text, ('batch',))
self.shape_checker(target_text, ('batch',))
# Convert the text to token IDs
input_tokens = self.input_text_processor(input_text)
target_tokens = self.output_text_processor(target_text)
self.shape_checker(input_tokens, ('batch', 's'))
self.shape_checker(target_tokens, ('batch', 't'))
# Convert IDs to masks.
input_mask = input_tokens != 0
self.shape_checker(input_mask, ('batch', 's'))
target_mask = target_tokens != 0
self.shape_checker(target_mask, ('batch', 't'))
return input_tokens, input_mask, target_tokens, target_mask
TrainTranslator._preprocess = _preprocess
La _train_step méthode, ajoutée ci - dessous, gère les étapes restantes , sauf pour le décodeur fonctionne réellement:
def _train_step(self, inputs):
input_text, target_text = inputs
(input_tokens, input_mask,
target_tokens, target_mask) = self._preprocess(input_text, target_text)
max_target_length = tf.shape(target_tokens)[1]
with tf.GradientTape() as tape:
# Encode the input
enc_output, enc_state = self.encoder(input_tokens)
self.shape_checker(enc_output, ('batch', 's', 'enc_units'))
self.shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder's state to the encoder's final state.
# This only works if the encoder and decoder have the same number of
# units.
dec_state = enc_state
loss = tf.constant(0.0)
for t in tf.range(max_target_length-1):
# Pass in two tokens from the target sequence:
# 1. The current input to the decoder.
# 2. The target for the decoder's next prediction.
new_tokens = target_tokens[:, t:t+2]
step_loss, dec_state = self._loop_step(new_tokens, input_mask,
enc_output, dec_state)
loss = loss + step_loss
# Average the loss over all non padding tokens.
average_loss = loss / tf.reduce_sum(tf.cast(target_mask, tf.float32))
# Apply an optimization step
variables = self.trainable_variables
gradients = tape.gradient(average_loss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# Return a dict mapping metric names to current value
return {'batch_loss': average_loss}
TrainTranslator._train_step = _train_step
Le _loop_step procédé, ajouté ci - dessous, le décodeur exécute et calcule la perte progressive et nouvel état du décodeur ( dec_state ).
def _loop_step(self, new_tokens, input_mask, enc_output, dec_state):
input_token, target_token = new_tokens[:, 0:1], new_tokens[:, 1:2]
# Run the decoder one step.
decoder_input = DecoderInput(new_tokens=input_token,
enc_output=enc_output,
mask=input_mask)
dec_result, dec_state = self.decoder(decoder_input, state=dec_state)
self.shape_checker(dec_result.logits, ('batch', 't1', 'logits'))
self.shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
self.shape_checker(dec_state, ('batch', 'dec_units'))
# `self.loss` returns the total for non-padded tokens
y = target_token
y_pred = dec_result.logits
step_loss = self.loss(y, y_pred)
return step_loss, dec_state
TrainTranslator._loop_step = _loop_step
Tester l'étape de formation
Construire un TrainTranslator , et le configurer pour la formation en utilisant la Model.compile méthode:
translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
use_tf_function=False)
# Configure the loss and optimizer
translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
Testez le train_step . Pour un modèle de texte comme celui-ci, la perte devrait commencer près de :
np.log(output_text_processor.vocabulary_size())
8.517193191416236
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.5849695>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.55271>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.4929113>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.3296022>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=6.80437>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.000246>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.8740363>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.794589>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.3175836>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.108163>}
CPU times: user 5.49 s, sys: 0 ns, total: 5.49 s
Wall time: 5.45 s
Bien qu'il soit plus facile à déboguer sans tf.function elle donne un coup de pouce de la performance. Alors , maintenant que la _train_step méthode fonctionne, essayez le tf.function -wrapped _tf_train_step , pour optimiser les performances tout en formation:
@tf.function(input_signature=[[tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])]])
def _tf_train_step(self, inputs):
return self._train_step(inputs)
TrainTranslator._tf_train_step = _tf_train_step
translator.use_tf_function = True
Le premier appel sera lent, car il trace la fonction.
translator.train_step([example_input_batch, example_target_batch])
2021-12-04 12:09:48.074769: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.180156: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:09:48.285846: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:09:48.307794: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.425447: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node while/body/_1/while/TensorListPushBack_56 was passed float from while/body/_1/while/decoder_1/gru_3/PartitionedCall:6 incompatible with expected variant.
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.045638>}
Mais après qu'il est généralement 2-3x plus vite que la hâte train_step méthode:
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.1098256>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.169871>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.139249>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.0410743>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.9664454>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.895707>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.8154407>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.7583396>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.6986444>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.640298>}
CPU times: user 4.4 s, sys: 960 ms, total: 5.36 s
Wall time: 1.67 s
Un bon test d'un nouveau modèle est de voir qu'il peut suradapter un seul lot d'entrées. Essayez-le, la perte devrait rapidement revenir à zéro :
losses = []
for n in range(100):
print('.', end='')
logs = translator.train_step([example_input_batch, example_target_batch])
losses.append(logs['batch_loss'].numpy())
print()
plt.plot(losses)
.................................................................................................... [<matplotlib.lines.Line2D at 0x7fb427edf210>]

Maintenant que vous êtes sûr que l'étape d'entraînement fonctionne, créez une nouvelle copie du modèle pour l'entraîner à partir de zéro :
train_translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor)
# Configure the loss and optimizer
train_translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
Former le modèle
Bien qu'il n'y ait rien de mal avec de la rédaction de votre propre boucle de formation sur mesure, la mise en œuvre de la Model.train_step méthode, comme dans la section précédente, vous permet d'exécuter Model.fit et éviter d' écrire tout ce code plaque de la chaudière.
Ce tutoriel seulement les trains pour deux époques, utilisez donc un callbacks.Callback pour recueillir l'histoire des pertes par lots, pour le traçage:
class BatchLogs(tf.keras.callbacks.Callback):
def __init__(self, key):
self.key = key
self.logs = []
def on_train_batch_end(self, n, logs):
self.logs.append(logs[self.key])
batch_loss = BatchLogs('batch_loss')
train_translator.fit(dataset, epochs=3,
callbacks=[batch_loss])
Epoch 1/3
2021-12-04 12:10:11.617839: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:11.737105: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:10:11.855054: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:10:11.878896: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:12.004755: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node StatefulPartitionedCall/while/body/_59/while/TensorListPushBack_56 was passed float from StatefulPartitionedCall/while/body/_59/while/decoder_2/gru_5/PartitionedCall:6 incompatible with expected variant.
1859/1859 [==============================] - 349s 185ms/step - batch_loss: 2.0443
Epoch 2/3
1859/1859 [==============================] - 350s 188ms/step - batch_loss: 1.0382
Epoch 3/3
1859/1859 [==============================] - 343s 184ms/step - batch_loss: 0.8085
<keras.callbacks.History at 0x7fb42c3eda10>
plt.plot(batch_loss.logs)
plt.ylim([0, 3])
plt.xlabel('Batch #')
plt.ylabel('CE/token')
Text(0, 0.5, 'CE/token')
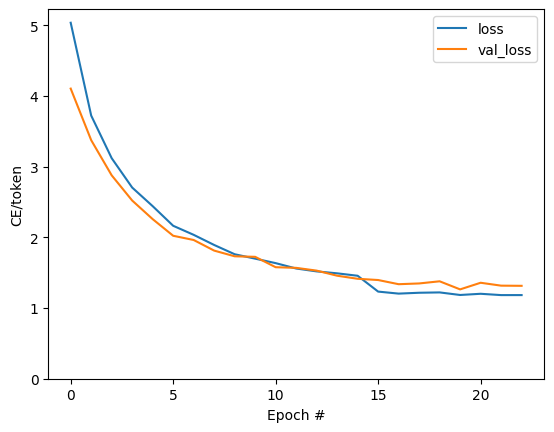
Les sauts visibles dans l'intrigue sont aux limites de l'époque.
Traduire
Maintenant que le modèle est formé, mettre en œuvre une fonction pour exécuter le plein text => text de traduction.
Pour cela , les besoins de modèle pour inverser le text => token IDs mappage fourni par le output_text_processor . Il doit également connaître les identifiants des jetons spéciaux. Tout cela est implémenté dans le constructeur de la nouvelle classe. La mise en œuvre de la méthode de traduction actuelle suivra.
Dans l'ensemble, cela est similaire à la boucle d'apprentissage, sauf que l'entrée du décodeur à chaque pas de temps est un échantillon de la dernière prédiction du décodeur.
class Translator(tf.Module):
def __init__(self, encoder, decoder, input_text_processor,
output_text_processor):
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.output_token_string_from_index = (
tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(),
mask_token='',
invert=True))
# The output should never generate padding, unknown, or start.
index_from_string = tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(), mask_token='')
token_mask_ids = index_from_string(['', '[UNK]', '[START]']).numpy()
token_mask = np.zeros([index_from_string.vocabulary_size()], dtype=np.bool)
token_mask[np.array(token_mask_ids)] = True
self.token_mask = token_mask
self.start_token = index_from_string(tf.constant('[START]'))
self.end_token = index_from_string(tf.constant('[END]'))
translator = Translator(
encoder=train_translator.encoder,
decoder=train_translator.decoder,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:21: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
Convertir les identifiants de jeton en texte
La première méthode à mettre en œuvre est tokens_to_text qui convertit des ID jeton au texte lisible par l' homme.
def tokens_to_text(self, result_tokens):
shape_checker = ShapeChecker()
shape_checker(result_tokens, ('batch', 't'))
result_text_tokens = self.output_token_string_from_index(result_tokens)
shape_checker(result_text_tokens, ('batch', 't'))
result_text = tf.strings.reduce_join(result_text_tokens,
axis=1, separator=' ')
shape_checker(result_text, ('batch'))
result_text = tf.strings.strip(result_text)
shape_checker(result_text, ('batch',))
return result_text
Translator.tokens_to_text = tokens_to_text
Saisissez des identifiants de jeton aléatoires et voyez ce qu'il génère :
example_output_tokens = tf.random.uniform(
shape=[5, 2], minval=0, dtype=tf.int64,
maxval=output_text_processor.vocabulary_size())
translator.tokens_to_text(example_output_tokens).numpy()
array([b'vain mysteries', b'funny ham', b'drivers responding',
b'mysterious ignoring', b'fashion votes'], dtype=object)
Échantillon des prédictions du décodeur
Cette fonction prend les sorties logit du décodeur et échantillonne les ID de jeton de cette distribution :
def sample(self, logits, temperature):
shape_checker = ShapeChecker()
# 't' is usually 1 here.
shape_checker(logits, ('batch', 't', 'vocab'))
shape_checker(self.token_mask, ('vocab',))
token_mask = self.token_mask[tf.newaxis, tf.newaxis, :]
shape_checker(token_mask, ('batch', 't', 'vocab'), broadcast=True)
# Set the logits for all masked tokens to -inf, so they are never chosen.
logits = tf.where(self.token_mask, -np.inf, logits)
if temperature == 0.0:
new_tokens = tf.argmax(logits, axis=-1)
else:
logits = tf.squeeze(logits, axis=1)
new_tokens = tf.random.categorical(logits/temperature,
num_samples=1)
shape_checker(new_tokens, ('batch', 't'))
return new_tokens
Translator.sample = sample
Testez cette fonction sur certaines entrées aléatoires :
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
<tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[4506],
[3577],
[2961],
[4586],
[ 944]])>
Implémenter la boucle de traduction
Voici une implémentation complète de la boucle de traduction de texte en texte.
Cette mise en œuvre recueille les résultats dans les listes de python, avant d' utiliser tf.concat pour les rejoindre en tenseurs.
Cette mise en œuvre statiquement le graphique se déroule vers max_length itérations. C'est bien avec une exécution impatiente en python.
def translate_unrolled(self,
input_text, *,
max_length=50,
return_attention=True,
temperature=1.0):
batch_size = tf.shape(input_text)[0]
input_tokens = self.input_text_processor(input_text)
enc_output, enc_state = self.encoder(input_tokens)
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
result_tokens = []
attention = []
done = tf.zeros([batch_size, 1], dtype=tf.bool)
for _ in range(max_length):
dec_input = DecoderInput(new_tokens=new_tokens,
enc_output=enc_output,
mask=(input_tokens!=0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
attention.append(dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens.append(new_tokens)
if tf.executing_eagerly() and tf.reduce_all(done):
break
# Convert the list of generates token ids to a list of strings.
result_tokens = tf.concat(result_tokens, axis=-1)
result_text = self.tokens_to_text(result_tokens)
if return_attention:
attention_stack = tf.concat(attention, axis=1)
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_unrolled
Exécutez-le sur une simple entrée :
%%time
input_text = tf.constant([
'hace mucho frio aqui.', # "It's really cold here."
'Esta es mi vida.', # "This is my life.""
])
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its a long cold here . this is my life . CPU times: user 165 ms, sys: 4.37 ms, total: 169 ms Wall time: 164 ms
Si vous voulez exporter ce modèle , vous aurez besoin d'envelopper cette méthode dans un tf.function . Cette implémentation de base présente quelques problèmes si vous essayez de le faire :
- Les graphiques résultants sont très volumineux et prennent quelques secondes à créer, enregistrer ou charger.
- Vous ne pouvez pas rompre une boucle statiquement déroulée, il sera toujours courir
max_lengthitérations, même si toutes les sorties sont effectuées. Mais même alors, c'est légèrement plus rapide qu'une exécution impatiente.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
Exécutez le tf.function une fois pour le compiler:
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 18.8 s, sys: 0 ns, total: 18.8 s Wall time: 18.7 s
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 88 ms
[Facultatif] Utiliser une boucle symbolique
def translate_symbolic(self,
input_text,
*,
max_length=50,
return_attention=True,
temperature=1.0):
shape_checker = ShapeChecker()
shape_checker(input_text, ('batch',))
batch_size = tf.shape(input_text)[0]
# Encode the input
input_tokens = self.input_text_processor(input_text)
shape_checker(input_tokens, ('batch', 's'))
enc_output, enc_state = self.encoder(input_tokens)
shape_checker(enc_output, ('batch', 's', 'enc_units'))
shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
shape_checker(new_tokens, ('batch', 't1'))
# Initialize the accumulators
result_tokens = tf.TensorArray(tf.int64, size=1, dynamic_size=True)
attention = tf.TensorArray(tf.float32, size=1, dynamic_size=True)
done = tf.zeros([batch_size, 1], dtype=tf.bool)
shape_checker(done, ('batch', 't1'))
for t in tf.range(max_length):
dec_input = DecoderInput(
new_tokens=new_tokens, enc_output=enc_output, mask=(input_tokens != 0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
attention = attention.write(t, dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
shape_checker(dec_result.logits, ('batch', 't1', 'vocab'))
shape_checker(new_tokens, ('batch', 't1'))
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens = result_tokens.write(t, new_tokens)
if tf.reduce_all(done):
break
# Convert the list of generated token ids to a list of strings.
result_tokens = result_tokens.stack()
shape_checker(result_tokens, ('t', 'batch', 't0'))
result_tokens = tf.squeeze(result_tokens, -1)
result_tokens = tf.transpose(result_tokens, [1, 0])
shape_checker(result_tokens, ('batch', 't'))
result_text = self.tokens_to_text(result_tokens)
shape_checker(result_text, ('batch',))
if return_attention:
attention_stack = attention.stack()
shape_checker(attention_stack, ('t', 'batch', 't1', 's'))
attention_stack = tf.squeeze(attention_stack, 2)
shape_checker(attention_stack, ('t', 'batch', 's'))
attention_stack = tf.transpose(attention_stack, [1, 0, 2])
shape_checker(attention_stack, ('batch', 't', 's'))
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_symbolic
L'implémentation initiale utilisait des listes python pour collecter les sorties. Celui - ci utilise tf.range comme la boucle iterator, ce qui permet tf.autograph de convertir la boucle. Le plus grand changement dans cette mise en œuvre est l'utilisation de tf.TensorArray au lieu de python list à tenseurs Accumulez. tf.TensorArray doit recueillir un nombre variable de tenseurs en mode graphique.
Avec une exécution rapide, cette implémentation fonctionne à égalité avec l'original :
%%time
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 170 ms
Mais quand vous l' envelopper dans un tf.function vous remarquerez deux différences.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
Premièrement: la création graphique est beaucoup plus rapide (~ 10x), car il ne crée pas max_iterations copies du modèle.
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 1.79 s, sys: 0 ns, total: 1.79 s Wall time: 1.77 s
Deuxièmement : la fonction compilée est beaucoup plus rapide sur les petites entrées (5x sur cet exemple), car elle peut sortir de la boucle.
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 40.1 ms, sys: 0 ns, total: 40.1 ms Wall time: 17.1 ms
Visualisez le processus
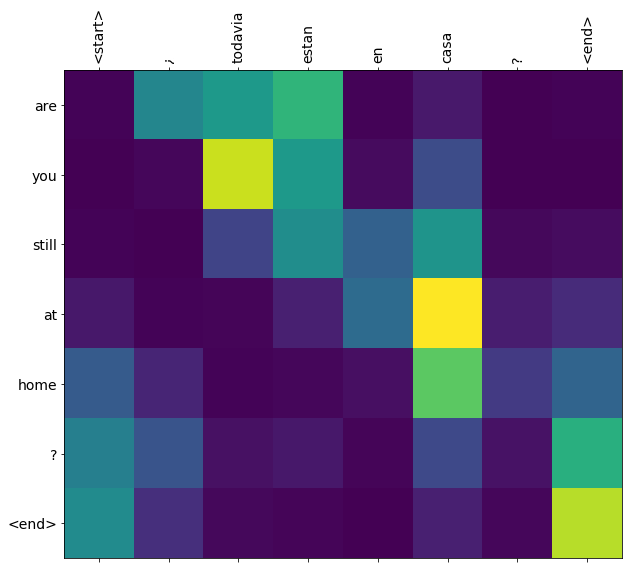
Les poids d'attention renvoyés par la translate méthode show où le modèle était « à la recherche » quand il produit chaque jeton de sortie.
Ainsi, la somme de l'attention sur l'entrée doit renvoyer tous les uns :
a = result['attention'][0]
print(np.sum(a, axis=-1))
[1.0000001 0.99999994 1. 0.99999994 1. 0.99999994]
Voici la distribution de l'attention pour la première étape de sortie du premier exemple. Notez comment l'attention est maintenant beaucoup plus concentrée qu'elle ne l'était pour le modèle non entraîné :
_ = plt.bar(range(len(a[0, :])), a[0, :])

Comme il existe un alignement approximatif entre les mots d'entrée et de sortie, vous vous attendez à ce que l'attention se concentre près de la diagonale :
plt.imshow(np.array(a), vmin=0.0)
<matplotlib.image.AxesImage at 0x7faf2886ced0>

Voici du code pour créer un meilleur diagramme d'attention :
Points d'attention étiquetés
def plot_attention(attention, sentence, predicted_sentence):
sentence = tf_lower_and_split_punct(sentence).numpy().decode().split()
predicted_sentence = predicted_sentence.numpy().decode().split() + ['[END]']
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
attention = attention[:len(predicted_sentence), :len(sentence)]
ax.matshow(attention, cmap='viridis', vmin=0.0)
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xlabel('Input text')
ax.set_ylabel('Output text')
plt.suptitle('Attention weights')
i=0
plot_attention(result['attention'][i], input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
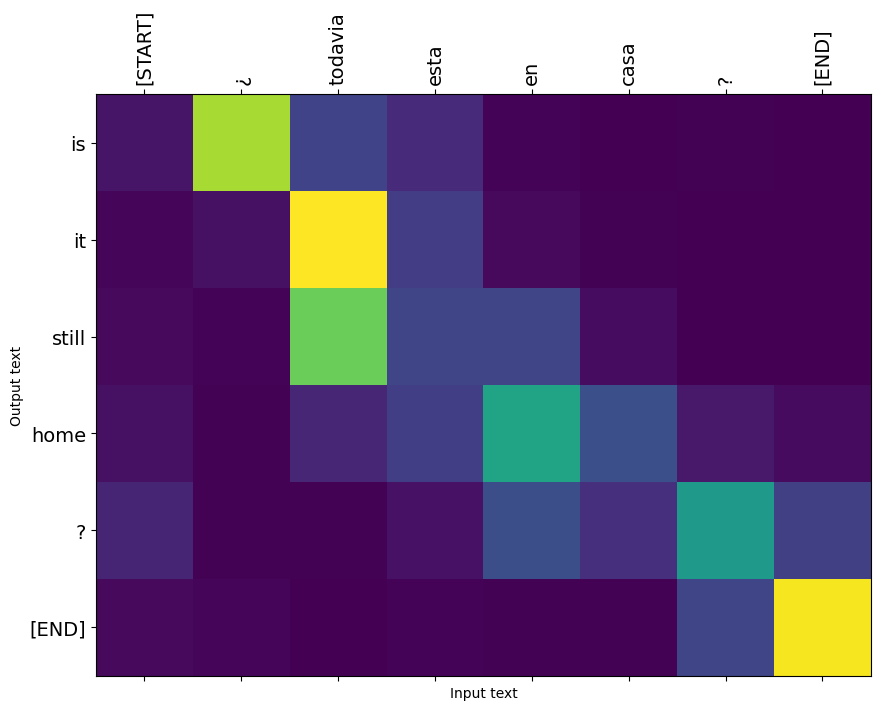
Traduisez quelques phrases supplémentaires et tracez-les :
%%time
three_input_text = tf.constant([
# This is my life.
'Esta es mi vida.',
# Are they still home?
'¿Todavía están en casa?',
# Try to find out.'
'Tratar de descubrir.',
])
result = translator.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? all about killed . CPU times: user 78 ms, sys: 23 ms, total: 101 ms Wall time: 23.1 ms
result['text']
<tf.Tensor: shape=(3,), dtype=string, numpy=
array([b'this is my life .', b'are you still at home ?',
b'all about killed .'], dtype=object)>
i = 0
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 1
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 2
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

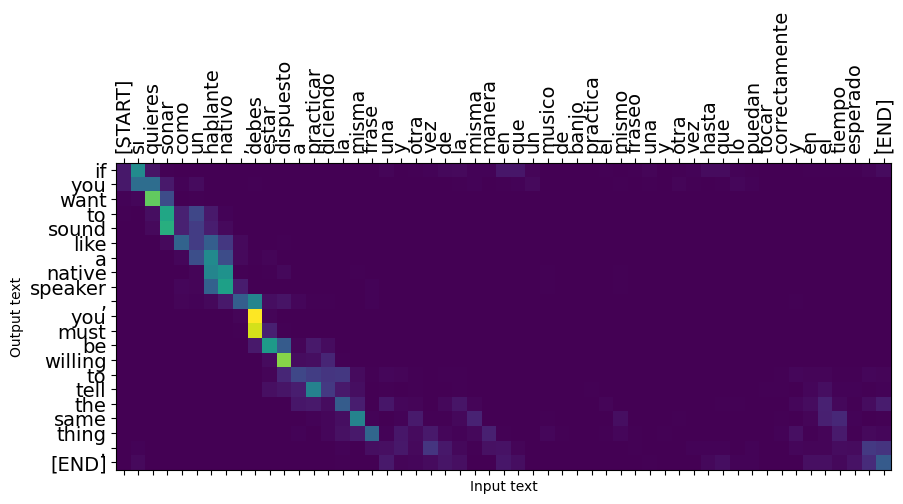
Les phrases courtes fonctionnent souvent bien, mais si l'entrée est trop longue, le modèle perd littéralement sa concentration et cesse de fournir des prédictions raisonnables. Il y a deux raisons principales pour cela:
- Le modèle a été formé en forçant l'enseignant à fournir le bon jeton à chaque étape, quelles que soient les prédictions du modèle. Le modèle pourrait être rendu plus robuste s'il était parfois alimenté par ses propres prédictions.
- Le modèle n'a accès à sa sortie précédente que via l'état RNN. Si l'état RNN est corrompu, le modèle n'a aucun moyen de récupérer. Les transformateurs résoudre ce problème en utilisant l' auto-attention dans le codeur et décodeur.
long_input_text = tf.constant([inp[-1]])
import textwrap
print('Expected output:\n', '\n'.join(textwrap.wrap(targ[-1])))
Expected output: If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
result = translator.tf_translate(long_input_text)
i = 0
plot_attention(result['attention'][i], long_input_text[i], result['text'][i])
_ = plt.suptitle('This never works')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
Exportation
Une fois que vous avez un modèle que vous êtes satisfait de vous voudrez peut - être exporter en tant que tf.saved_model pour une utilisation en dehors de ce programme python qui l'a créé.
Étant donné que le modèle est une sous - classe de tf.Module (par keras.Model ), et toutes les fonctionnalités pour l' exportation est compilé dans un tf.function le modèle doit exporter proprement avec tf.saved_model.save :
Maintenant que la fonction a été tracé il peut être exporté à l' aide saved_model.save :
tf.saved_model.save(translator, 'translator',
signatures={'serving_default': translator.tf_translate})
2021-12-04 12:27:54.310890: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as encoder_2_layer_call_fn, encoder_2_layer_call_and_return_conditional_losses, decoder_2_layer_call_fn, decoder_2_layer_call_and_return_conditional_losses, embedding_4_layer_call_fn while saving (showing 5 of 60). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: translator/assets INFO:tensorflow:Assets written to: translator/assets
reloaded = tf.saved_model.load('translator')
result = reloaded.tf_translate(three_input_text)
%%time
result = reloaded.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? find out about to find out . CPU times: user 42.8 ms, sys: 7.69 ms, total: 50.5 ms Wall time: 20 ms
Prochaines étapes
- Télécharger un jeu de données différentes à expérimenter avec des traductions, par exemple, l' anglais à l' allemand, ou anglais vers le français.
- Expérimentez avec l'entraînement sur un ensemble de données plus important ou en utilisant plus d'époques.
- Essayez le transformateur tutoriel qui met en œuvre une tâche de traduction similaire , mais utilise un transformateur de couches au lieu de RNNs. Cette version utilise également un
text.BertTokenizerpour mettre en œuvre wordpiece tokens. - Jetez un oeil à la tensorflow_addons.seq2seq pour la mise en œuvre de ce genre de séquence modèle de séquence. Le
tfa.seq2seqpackage inclut des fonctionnalités de niveau supérieur commeseq2seq.BeamSearchDecoder.