
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Tổng quat
Các thuật toán học máy thường tốn kém về mặt tính toán. Do đó, điều quan trọng là phải định lượng hiệu suất của ứng dụng học máy của bạn để đảm bảo rằng bạn đang chạy phiên bản tối ưu nhất cho mô hình của mình. Sử dụng TensorFlow Profiler để lập hồ sơ việc thực thi mã TensorFlow của bạn.
Thành lập
from datetime import datetime
from packaging import version
import os
Các TensorFlow Profiler đòi hỏi phiên bản mới nhất của TensorFlow và TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
Xác nhận rằng TensorFlow có thể truy cập GPU.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Đào tạo mô hình phân loại hình ảnh với lệnh gọi lại TensorBoard
Trong hướng dẫn này, bạn khám phá những khả năng của TensorFlow Profiler bằng cách bắt hồ sơ cá nhân thực hiện thu được bằng cách đào tạo một mô hình để hình ảnh classify trong dataset MNIST .
Sử dụng bộ dữ liệu TensorFlow để nhập dữ liệu đào tạo và chia nó thành các bộ đào tạo và kiểm tra.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
Xử lý trước dữ liệu đào tạo và kiểm tra bằng cách chuẩn hóa các giá trị pixel nằm trong khoảng từ 0 đến 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
Tạo mô hình phân loại ảnh bằng Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Tạo một lệnh gọi lại TensorBoard để nắm bắt các cấu hình hiệu suất và gọi nó trong khi đào tạo mô hình.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
Sử dụng TensorFlow Profiler để lập hồ sơ hiệu suất đào tạo mô hình
TensorFlow Profiler được nhúng trong TensorBoard. Tải TensorBoard bằng phép thuật Colab và khởi chạy nó. Xem hồ sơ thực hiện bằng cách điều hướng đến tab Profile.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
Cấu hình hiệu suất cho mô hình này tương tự như hình ảnh bên dưới.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
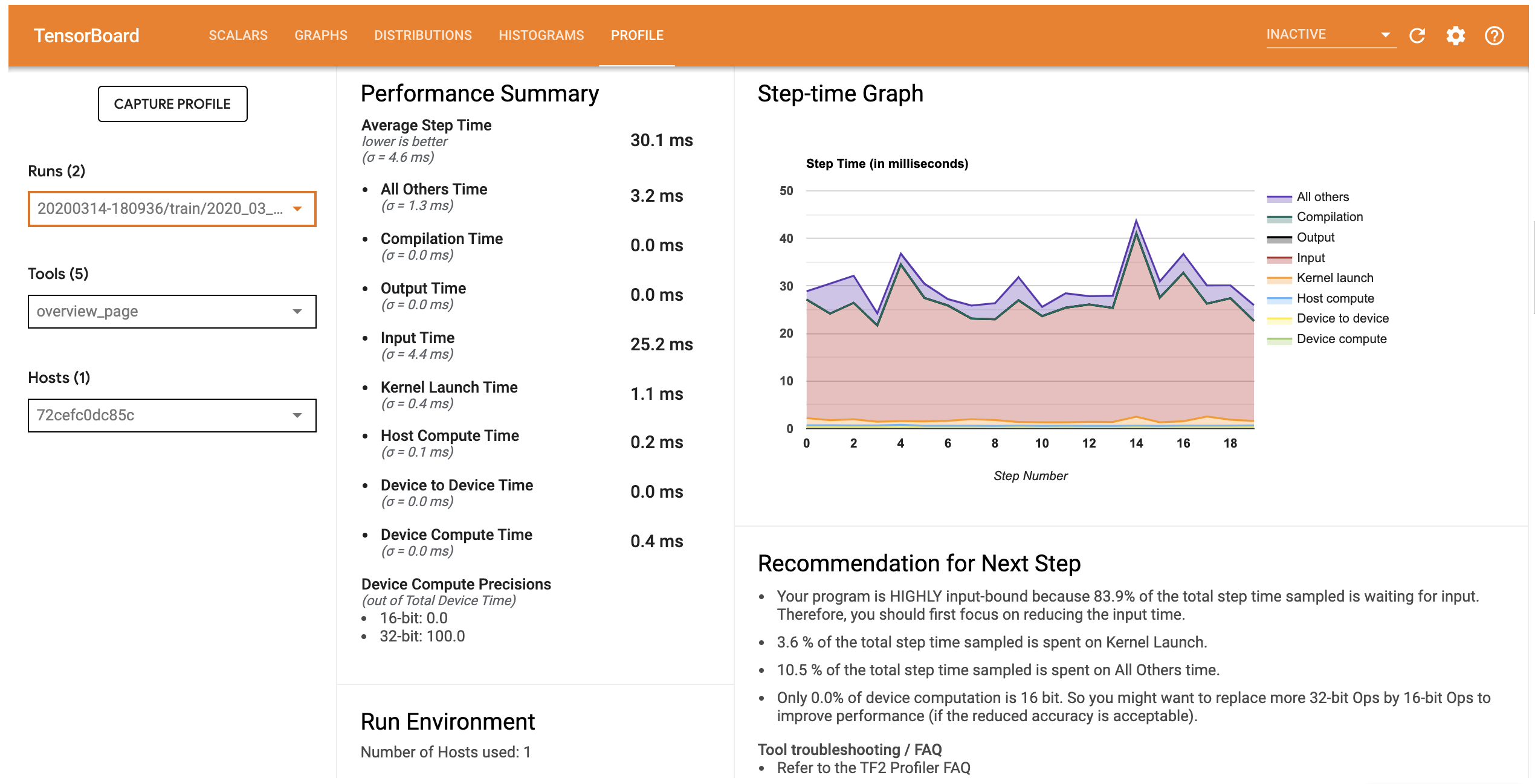
Các hồ sơ tab mở trang Tổng quan mà chương trình bạn một bản tóm tắt cấp cao về hiệu suất mô hình của bạn. Nhìn vào Biểu đồ thời gian ở bên phải, bạn có thể thấy rằng mô hình có giới hạn đầu vào cao (nghĩa là nó dành nhiều thời gian cho đường ống nhập dữ liệu). Trang Tổng quan cũng cung cấp cho bạn các đề xuất về các bước tiếp theo tiềm năng mà bạn có thể làm theo để tối ưu hóa hiệu suất mô hình của mình.
Để hiểu nơi mà các nút cổ chai hiệu suất xảy ra trong các đường ống đầu vào, chọn Viewer Trace từ các công cụ thả xuống ở bên trái. Trình xem theo dõi hiển thị cho bạn dòng thời gian của các sự kiện khác nhau đã xảy ra trên CPU và GPU trong khoảng thời gian lập hồ sơ.
Trình xem theo dõi hiển thị nhiều nhóm sự kiện trên trục tung. Mỗi nhóm sự kiện có nhiều rãnh ngang, chứa đầy các sự kiện theo dõi. Bản nhạc là dòng thời gian sự kiện cho các sự kiện được thực thi trên một luồng hoặc một luồng GPU. Các sự kiện riêng lẻ là các khối hình chữ nhật có màu trên các đường thời gian. Thời gian di chuyển từ trái sang phải. Điều hướng các sự kiện dấu vết bằng cách sử dụng các phím tắt W (phóng to), S (thu nhỏ), A (cuộn trái) và D (di chuyển sang phải).
Một hình chữ nhật đơn đại diện cho một sự kiện theo dõi. Chọn biểu tượng con trỏ chuột vào thanh công cụ nổi (hoặc sử dụng phím tắt 1 ) và nhấp vào sự kiện dấu vết để phân tích nó. Thao tác này sẽ hiển thị thông tin về sự kiện, chẳng hạn như thời gian bắt đầu và thời lượng của sự kiện.
Ngoài cách nhấp, bạn có thể kéo chuột để chọn một nhóm các sự kiện theo dõi. Điều này sẽ cung cấp cho bạn danh sách tất cả các sự kiện trong khu vực đó cùng với bản tóm tắt sự kiện. Sử dụng M chìa khóa để đo thời gian của các sự kiện đã chọn.
Các sự kiện theo dõi được thu thập từ:
- CPU: Sự kiện CPU được trình bày dưới một nhóm sự kiện tên
/host:CPU. Mỗi rãnh đại diện cho một luồng trên CPU. Sự kiện CPU bao gồm sự kiện đường ống đầu vào, sự kiện lập lịch hoạt động GPU (op), sự kiện thực thi CPU op, v.v. - GPU: Sự kiện GPU được hiển thị dưới nhóm sự kiện bắt đầu bằng
/device:GPU:. Mỗi nhóm sự kiện đại diện cho một luồng trên GPU.
Gỡ lỗi tắc nghẽn hiệu suất
Sử dụng Trình xem theo dõi để xác định vị trí tắc nghẽn hiệu suất trong đường dẫn đầu vào của bạn. Hình ảnh dưới đây là ảnh chụp nhanh của hồ sơ hoạt động.
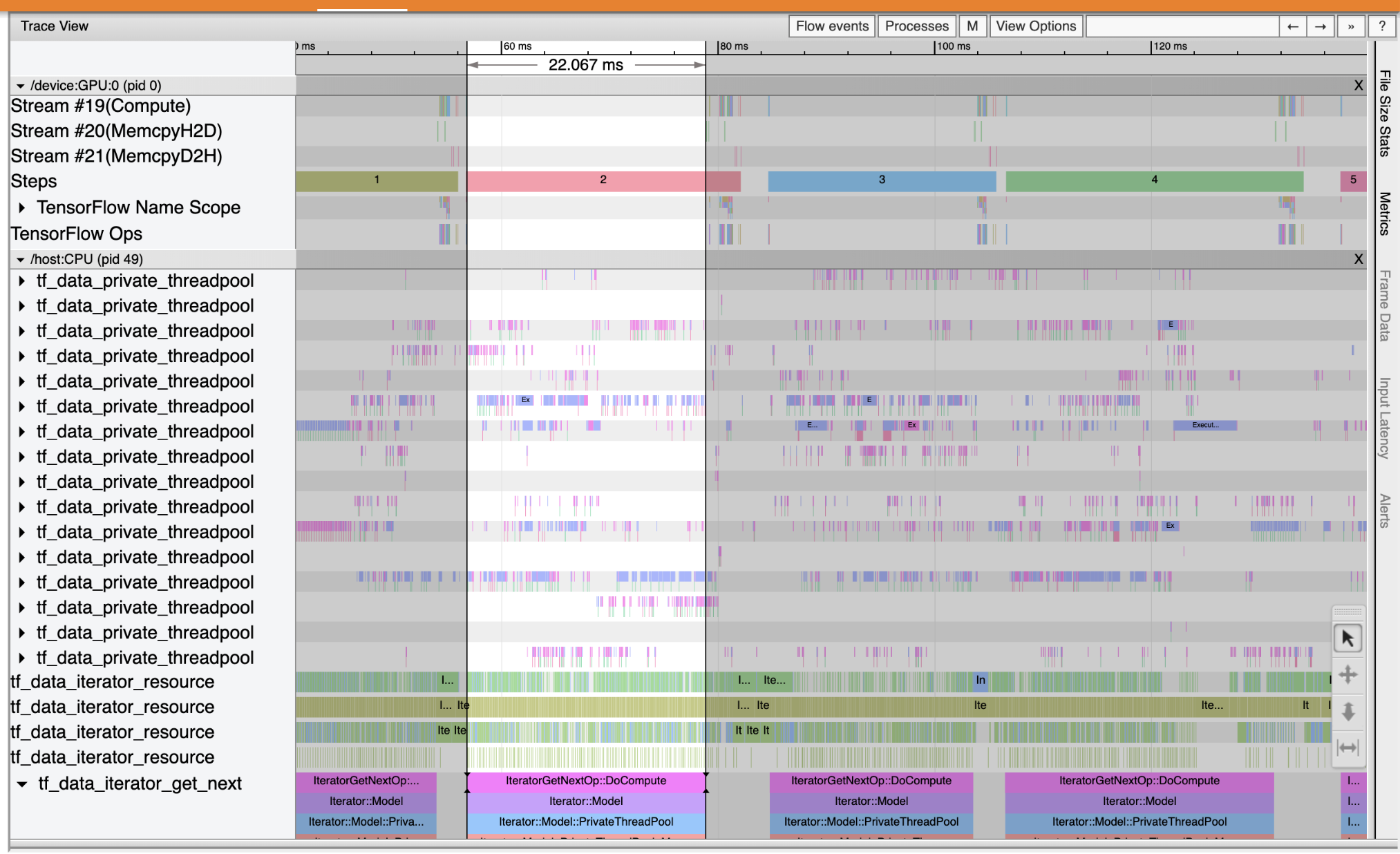
Nhìn vào các dấu vết sự kiện, bạn có thể thấy rằng các GPU không hoạt động trong khi tf_data_iterator_get_next op đang chạy trên CPU. Op này chịu trách nhiệm xử lý dữ liệu đầu vào và gửi nó đến GPU để đào tạo. Theo nguyên tắc chung, bạn nên luôn giữ cho thiết bị (GPU / TPU) hoạt động.
Sử dụng các tf.data API để tối ưu hóa các đường ống đầu vào. Trong trường hợp này, hãy lưu vào bộ nhớ cache tập dữ liệu đào tạo và tìm nạp trước dữ liệu để đảm bảo rằng luôn có sẵn dữ liệu để GPU xử lý. Xem ở đây để biết thêm chi tiết về việc sử dụng tf.data để tối ưu hóa đường ống đầu vào của bạn.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Đào tạo lại mô hình và nắm bắt hồ sơ hiệu suất bằng cách sử dụng lại lệnh gọi lại từ trước đó.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
Khởi động lại TensorBoard và mở hồ sơ tab để quan sát hồ sơ cá nhân hiệu suất cho các đường ống đầu vào được cập nhật.
Cấu hình hiệu suất cho mô hình với đường ống đầu vào được tối ưu hóa tương tự như hình ảnh bên dưới.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
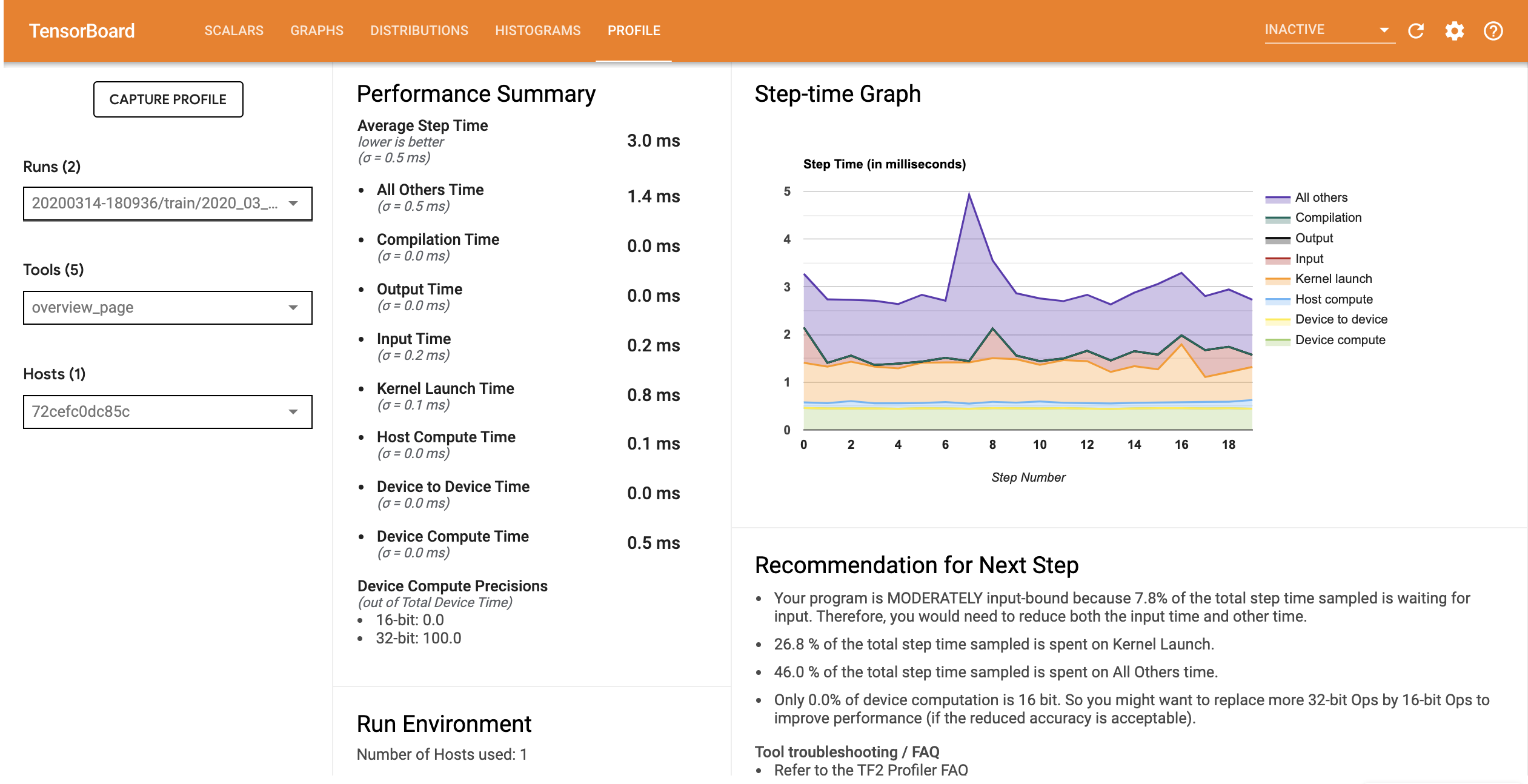
Từ trang Tổng quan, bạn có thể thấy rằng thời gian của Bước trung bình đã giảm xuống cũng như thời gian của Bước nhập liệu. Biểu đồ thời gian theo bước cũng chỉ ra rằng mô hình không còn bị ràng buộc đầu vào cao nữa. Mở Trình xem theo dõi để kiểm tra các sự kiện theo dõi với đường dẫn đầu vào được tối ưu hóa.
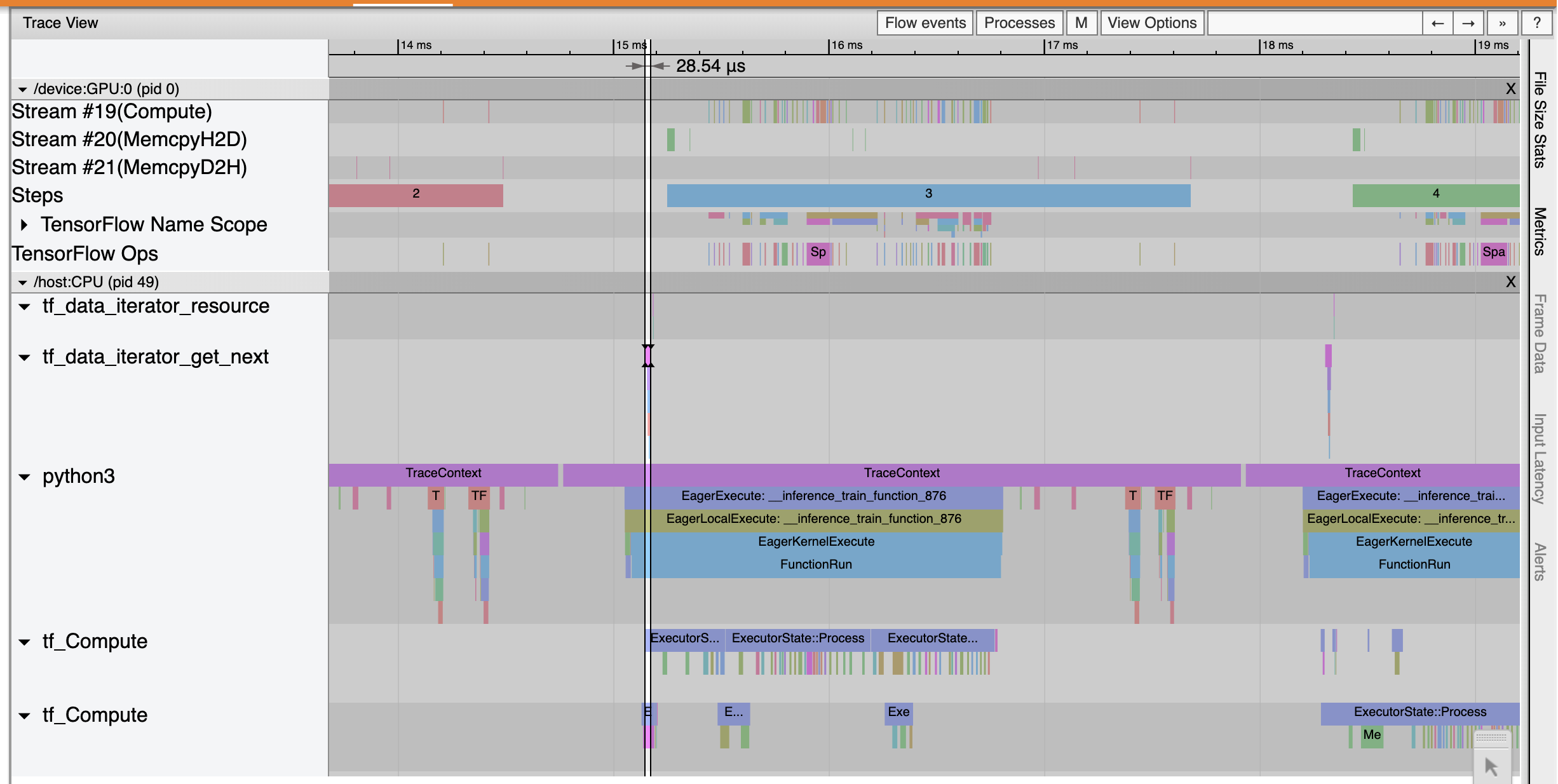
Các chương vết Viewer rằng tf_data_iterator_get_next op thực hiện nhanh hơn nhiều. Do đó, GPU nhận được một luồng dữ liệu ổn định để thực hiện đào tạo và đạt được hiệu suất sử dụng tốt hơn nhiều thông qua đào tạo mô hình.
Bản tóm tắt
Sử dụng TensorFlow Profiler để lập hồ sơ và gỡ lỗi hiệu suất đào tạo mô hình. Đọc hướng dẫn Profiler và xem hồ sơ Hiệu suất trong TF 2 nói chuyện từ Hội nghị thượng đỉnh TensorFlow Dev năm 2020 để tìm hiểu thêm về TensorFlow Profiler.