
| | |  Voir la source sur GitHub Voir la source sur GitHub | |
Aperçu
Les algorithmes d'apprentissage automatique sont généralement coûteux en temps de calcul. Il est donc vital de quantifier les performances de votre application de machine learning pour vous assurer que vous exécutez la version la plus optimisée de votre modèle. Utilisez le profileur TensorFlow pour profiler l'exécution de votre code TensorFlow.
Installer
from datetime import datetime
from packaging import version
import os
Le tensorflow Profiler nécessite les dernières versions de tensorflow et TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
Confirmez que TensorFlow peut accéder au GPU.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Entraîner un modèle de classification d'images avec des rappels TensorBoard
Dans ce tutoriel, vous explorez les capacités du Générateur de profils tensorflow en capturant le profil de performance obtenu par la formation d' un modèle aux images Classifier dans le jeu de données MNIST .
Utilisez des ensembles de données TensorFlow pour importer les données d'entraînement et les diviser en ensembles d'entraînement et de test.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
Prétraitez les données d'apprentissage et de test en normalisant les valeurs de pixel entre 0 et 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
Créez le modèle de classification d'images à l'aide de Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Créez un rappel TensorBoard pour capturer des profils de performances et appelez-le lors de l'entraînement du modèle.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
Utiliser le profileur TensorFlow pour profiler les performances d'entraînement du modèle
Le profileur TensorFlow est intégré à TensorBoard. Chargez TensorBoard à l'aide de la magie Colab et lancez-le. Consultez les profils de performance en accédant à l'onglet Profil.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
Le profil de performance de ce modèle est similaire à l'image ci-dessous.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
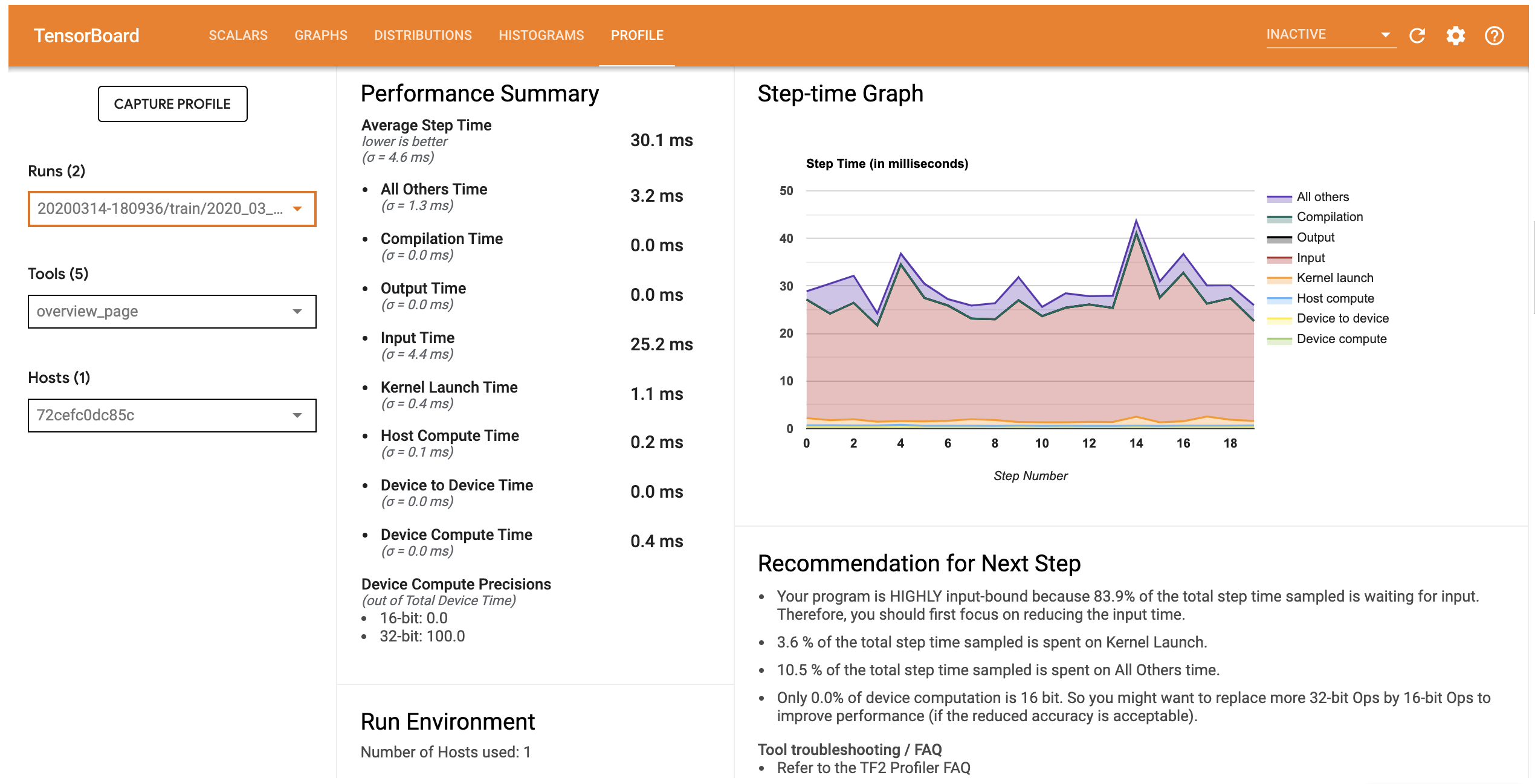
L'onglet Profil ouvre la page de présentation qui vous montre un résumé de haut niveau de performance de votre modèle. En regardant le graphique pas à pas sur la droite, vous pouvez voir que le modèle est fortement lié à l'entrée (c'est-à-dire qu'il passe beaucoup de temps dans le graphique d'entrée des données). La page Présentation vous donne également des recommandations sur les prochaines étapes potentielles que vous pouvez suivre pour optimiser les performances de votre modèle.
Pour comprendre où le goulot d'étranglement se produit dans la canalisation d'entrée, sélectionnez la visionneuse de trace dans le menu Outils menu déroulant à gauche. Le Trace Viewer vous montre une chronologie des différents événements qui se sont produits sur le CPU et le GPU pendant la période de profilage.
La visionneuse de traces affiche plusieurs groupes d'événements sur l'axe vertical. Chaque groupe d'événements a plusieurs pistes horizontales, remplies d'événements de trace. La piste est une chronologie d'événements pour les événements exécutés sur un thread ou un flux GPU. Les événements individuels sont les blocs rectangulaires colorés sur les pistes de la chronologie. Le temps passe de gauche à droite. Naviguer dans les événements de trace en utilisant les raccourcis clavier W (zoom avant), S (zoom arrière), A (défilement vers la gauche) et D (droit de défilement).
Un seul rectangle représente un événement de trace. Sélectionnez l'icône du curseur de la souris dans la barre d'outils flottante (ou utilisez le raccourci clavier 1 ) et cliquez sur l'événement de trace pour l' analyser. Cela affichera des informations sur l'événement, telles que son heure de début et sa durée.
En plus de cliquer, vous pouvez faire glisser la souris pour sélectionner un groupe d'événements de trace. Cela vous donnera une liste de tous les événements dans cette zone ainsi qu'un résumé de l'événement. Utilisez le M clé pour mesurer la durée des événements sélectionnés.
Les événements de trace sont collectés à partir de :
- CPU: les événements CPU sont affichés sous un groupe d'événements appelé
/host:CPU. Chaque piste représente un thread sur le CPU. Les événements CPU incluent les événements de pipeline d'entrée, les événements de planification d'opérations GPU, les événements d'exécution d'opérations CPU, etc. - GPU: les événements GPU sont affichés sous groupes d'événements préfixées par
/device:GPU:. Chaque groupe d'événements représente un flux sur le GPU.
Déboguer les goulots d'étranglement des performances
Utilisez Trace Viewer pour localiser les goulots d'étranglement des performances dans votre pipeline d'entrée. L'image ci-dessous est un instantané du profil de performance.
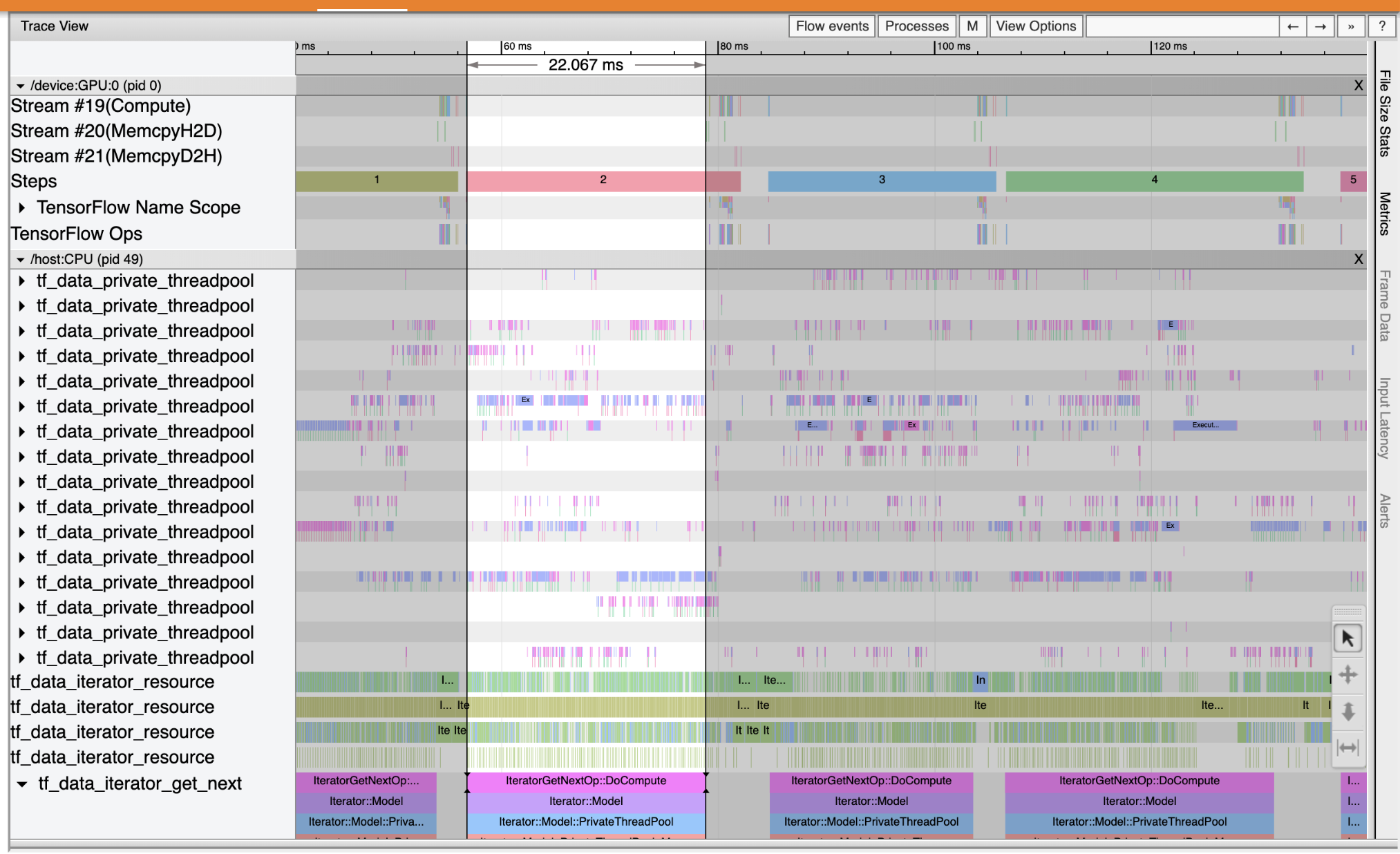
En regardant les traces d'événements, vous pouvez voir que le GPU est inactif alors que le tf_data_iterator_get_next op est en cours d' exécution sur la CPU. Cette opération est responsable du traitement des données d'entrée et de leur envoi au GPU pour la formation. En règle générale, c'est une bonne idée de toujours garder le périphérique (GPU/TPU) actif.
Utilisez le tf.data API pour optimiser la conduite d'entrée. Dans ce cas, mettons en cache l'ensemble de données d'entraînement et prélevons les données pour garantir qu'il y a toujours des données disponibles pour le GPU à traiter. Voir ici pour plus de détails sur l' utilisation tf.data pour optimiser vos conduites d'entrée.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Entraînez à nouveau le modèle et capturez le profil de performances en réutilisant le rappel d'avant.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
Relance TensorBoard et ouvrez l'onglet Profil d'observer le profil de performance pour le pipeline d'entrée mis à jour.
Le profil de performances du modèle avec le pipeline d'entrée optimisé est similaire à l'image ci-dessous.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
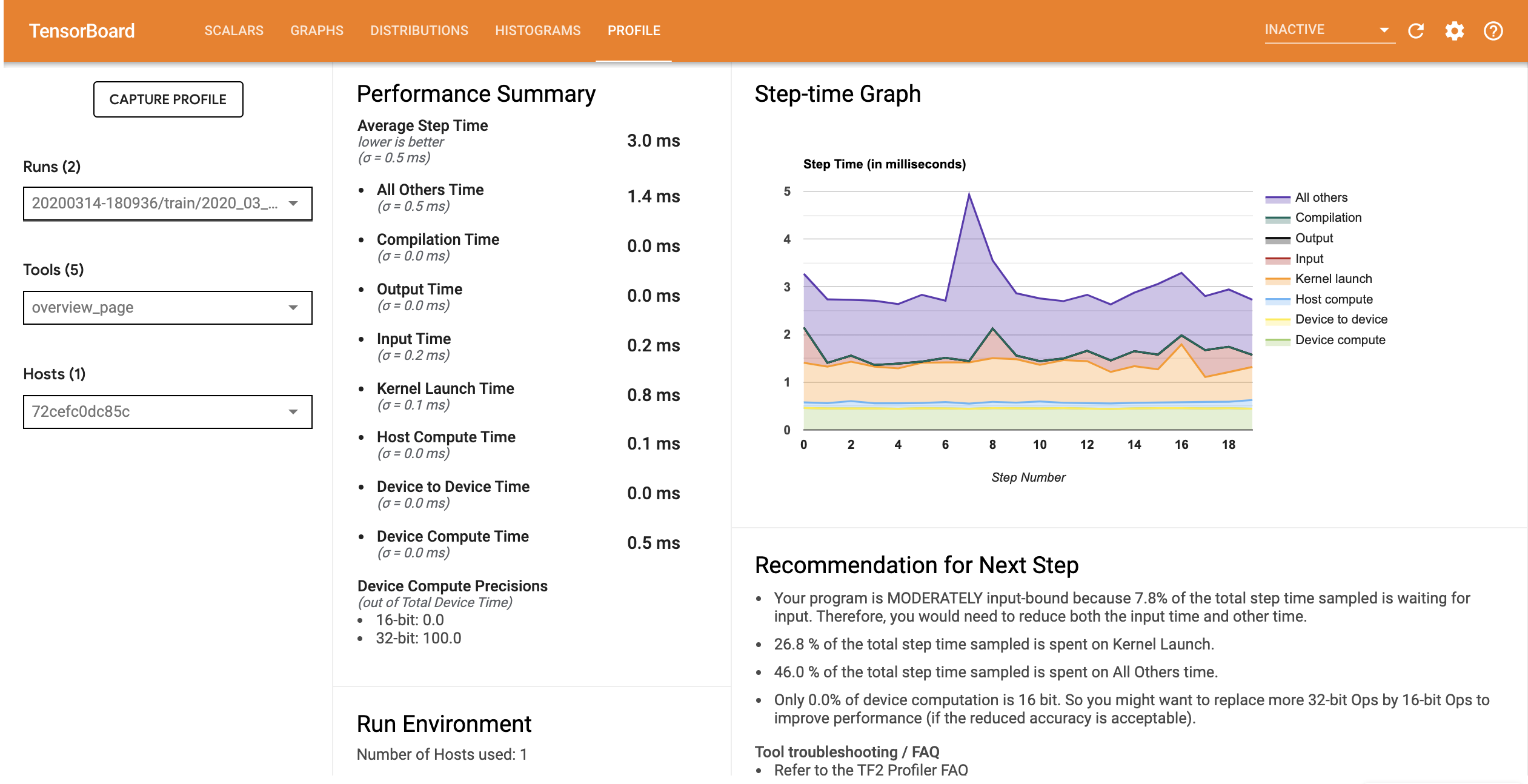
À partir de la page Aperçu, vous pouvez voir que le temps moyen du pas a diminué, tout comme le temps du pas d'entrée. Le graphique pas à pas indique également que le modèle n'est plus fortement lié aux entrées. Ouvrez Trace Viewer pour examiner les événements de trace avec le pipeline d'entrée optimisé.
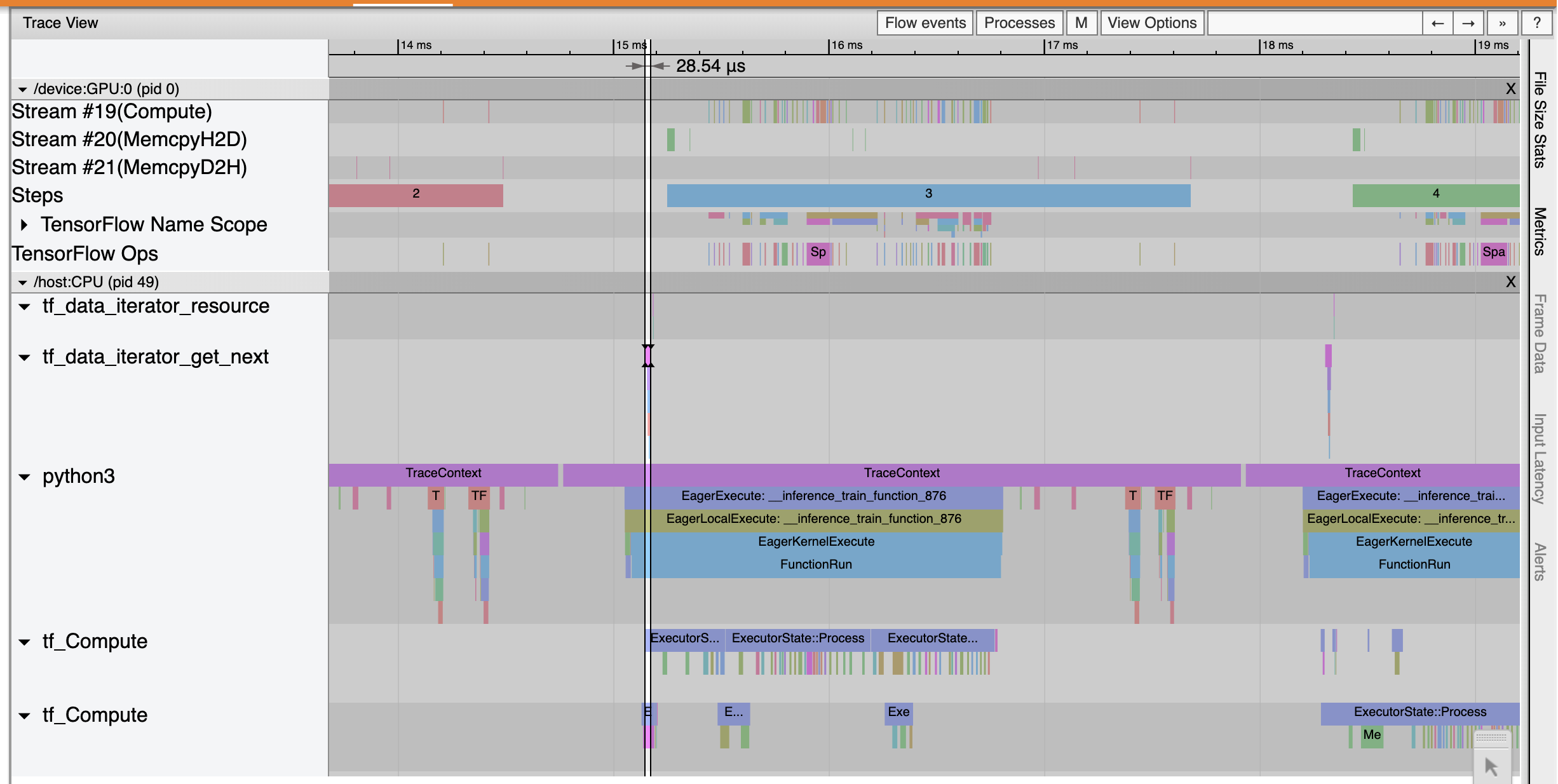
La trace Viewer montre que les tf_data_iterator_get_next op beaucoup plus rapide. Exécute Le GPU obtient donc un flux constant de données pour effectuer l'entraînement et obtient une bien meilleure utilisation grâce à l'entraînement du modèle.
Résumé
Utilisez le profileur TensorFlow pour profiler et déboguer les performances d'entraînement du modèle. Lisez le Guide Profiler et regarder le profil de performance en TF 2 parler du Sommet tensorflow Dev 2020 pour en savoir plus sur le Générateur de profils tensorflow.