
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Przegląd
Algorytmy uczenia maszynowego są zazwyczaj drogie obliczeniowo. Dlatego ważne jest, aby określić ilościowo wydajność aplikacji uczenia maszynowego, aby upewnić się, że korzystasz z najbardziej zoptymalizowanej wersji swojego modelu. Użyj TensorFlow Profiler, aby sprofilować wykonanie kodu TensorFlow.
Ustawiać
from datetime import datetime
from packaging import version
import os
TensorFlow Profiler wymaga najnowsze wersje TensorFlow i TensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
Upewnij się, że TensorFlow może uzyskać dostęp do GPU.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
Trenuj model klasyfikacji obrazów za pomocą wywołań zwrotnych TensorBoard
W tym samouczku zbadać możliwości w TensorFlow Profiler przez uchwycenie profil wydajności uzyskany poprzez szkolenie model do klasyfikacji obrazów w zbiorze MNIST .
Użyj zestawów danych TensorFlow, aby zaimportować dane uczące i podzielić je na zestawy uczące i testowe.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
Wstępnie przetwórz dane treningowe i testowe, normalizując wartości pikseli w zakresie od 0 do 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
Utwórz model klasyfikacji obrazów za pomocą Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
Utwórz wywołanie zwrotne TensorBoard, aby przechwycić profile wydajności i wywołaj je podczas trenowania modelu.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
Użyj narzędzia TensorFlow Profiler do profilowania wydajności uczenia modelu
TensorFlow Profiler jest wbudowany w TensorBoard. Załaduj TensorBoard za pomocą magii Colab i uruchom go. Przeglądać profile wydajności przechodząc do zakładki Profil.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
Profil wydajności tego modelu jest podobny do poniższego obrazu.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
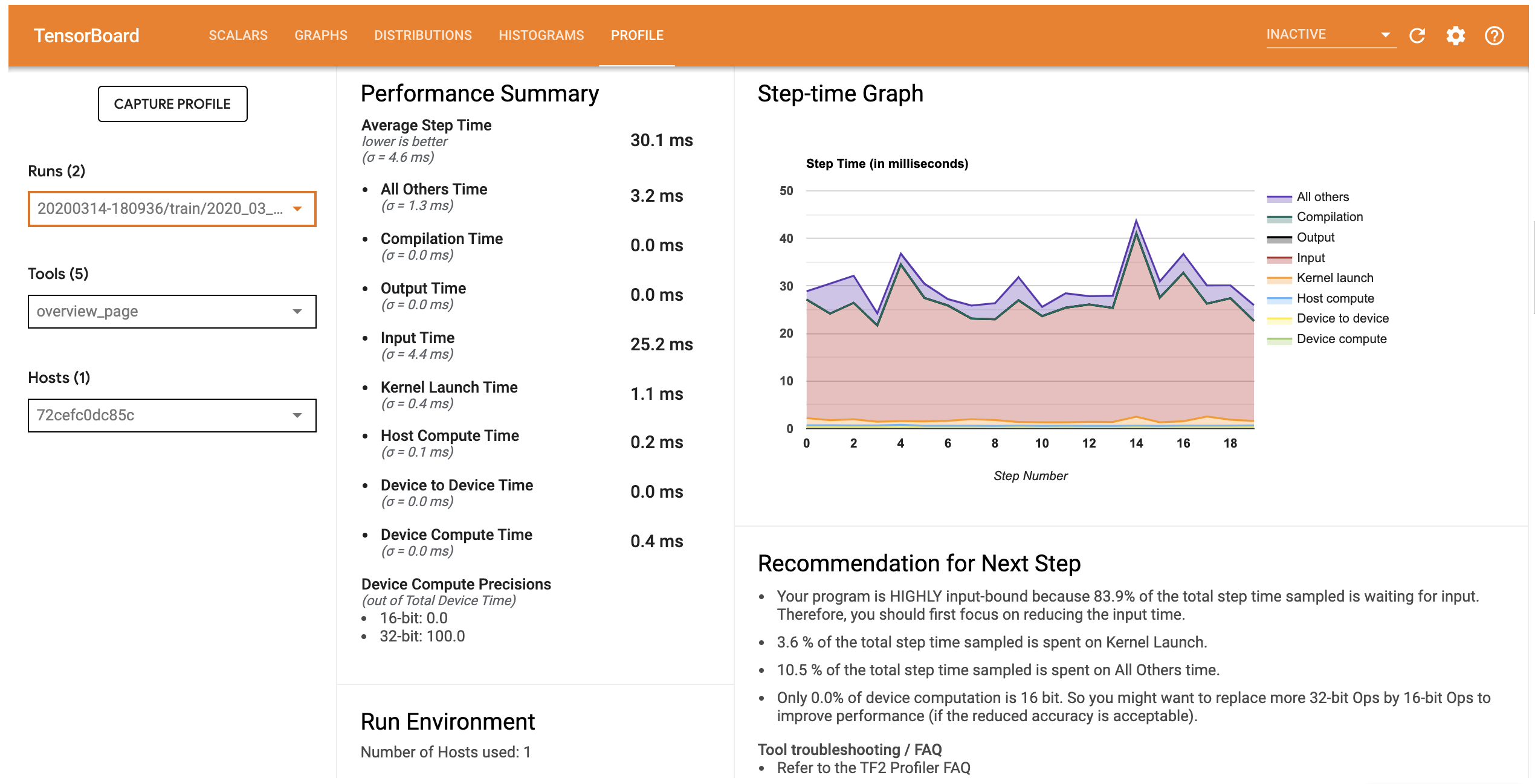
Zakładka Profile otwiera stronę, która pokazuje podsumowanie wysokiego poziomu skuteczności modelu przeglądania. Patrząc na wykres krokowy po prawej stronie, można zauważyć, że model jest silnie powiązany z danymi wejściowymi (tj. spędza dużo czasu w linii wprowadzania danych). Strona Przegląd zawiera również zalecenia dotyczące potencjalnych dalszych kroków, które można wykonać, aby zoptymalizować wydajność modelu.
Aby zrozumieć, gdzie pojawia się wąskim gardłem wydajności w rurociągu wejściowym wybierz Trace Viewer z Narzędzi rozwijanej po lewej stronie. Przeglądarka śledzenia pokazuje oś czasu różnych zdarzeń, które wystąpiły na procesorze i procesorze graficznym w okresie profilowania.
Przeglądarka śledzenia pokazuje wiele grup zdarzeń na osi pionowej. Każda grupa zdarzeń ma wiele ścieżek poziomych wypełnionych zdarzeniami śledzenia. Ścieżka to oś czasu zdarzenia dla zdarzeń wykonywanych w wątku lub strumieniu GPU. Poszczególne wydarzenia to kolorowe, prostokątne bloki na ścieżkach osi czasu. Czas płynie od lewej do prawej. Nawigacja zdarzeń śledzenia za pomocą skrótów klawiaturowych W (zoom in), S (pomniejszyć), (przewijania z lewej) i A D (przewijania w prawo).
Pojedynczy prostokąt reprezentuje zdarzenie śledzenia. Wybierz ikonę kursorem myszy na pływającym pasku narzędzi (lub użyj skrótu klawiaturowego 1 ) i kliknij zdarzenie śledzenia, aby je analizować. Spowoduje to wyświetlenie informacji o zdarzeniu, takich jak czas jego rozpoczęcia i czas trwania.
Oprócz kliknięcia możesz przeciągnąć myszą, aby wybrać grupę zdarzeń śledzenia. Spowoduje to wyświetlenie listy wszystkich wydarzeń w tym obszarze wraz z podsumowaniem wydarzenia. Użyj M klawisz, aby zmierzyć czas trwania wybranych wydarzeń.
Zdarzenia śledzenia są zbierane z:
- CPU: CPU zdarzenia są wyświetlane w ramach grupy zdarzenie o nazwie
/host:CPU. Każda ścieżka reprezentuje wątek na procesorze. Zdarzenia procesora obejmują zdarzenia potoku wejściowego, zdarzenia planowania operacji GPU (op), zdarzenia wykonania operacji procesora itp. - GPU: GPU zdarzenia są wyświetlane w ramach grup zdarzeń przez prefiksem
/device:GPU:. Każda grupa zdarzeń reprezentuje jeden strumień na GPU.
Debugowanie wąskich gardeł wydajności
Użyj przeglądarki śledzenia, aby zlokalizować wąskie gardła wydajności w potoku wejściowym. Poniższy obraz to migawka profilu wydajności.
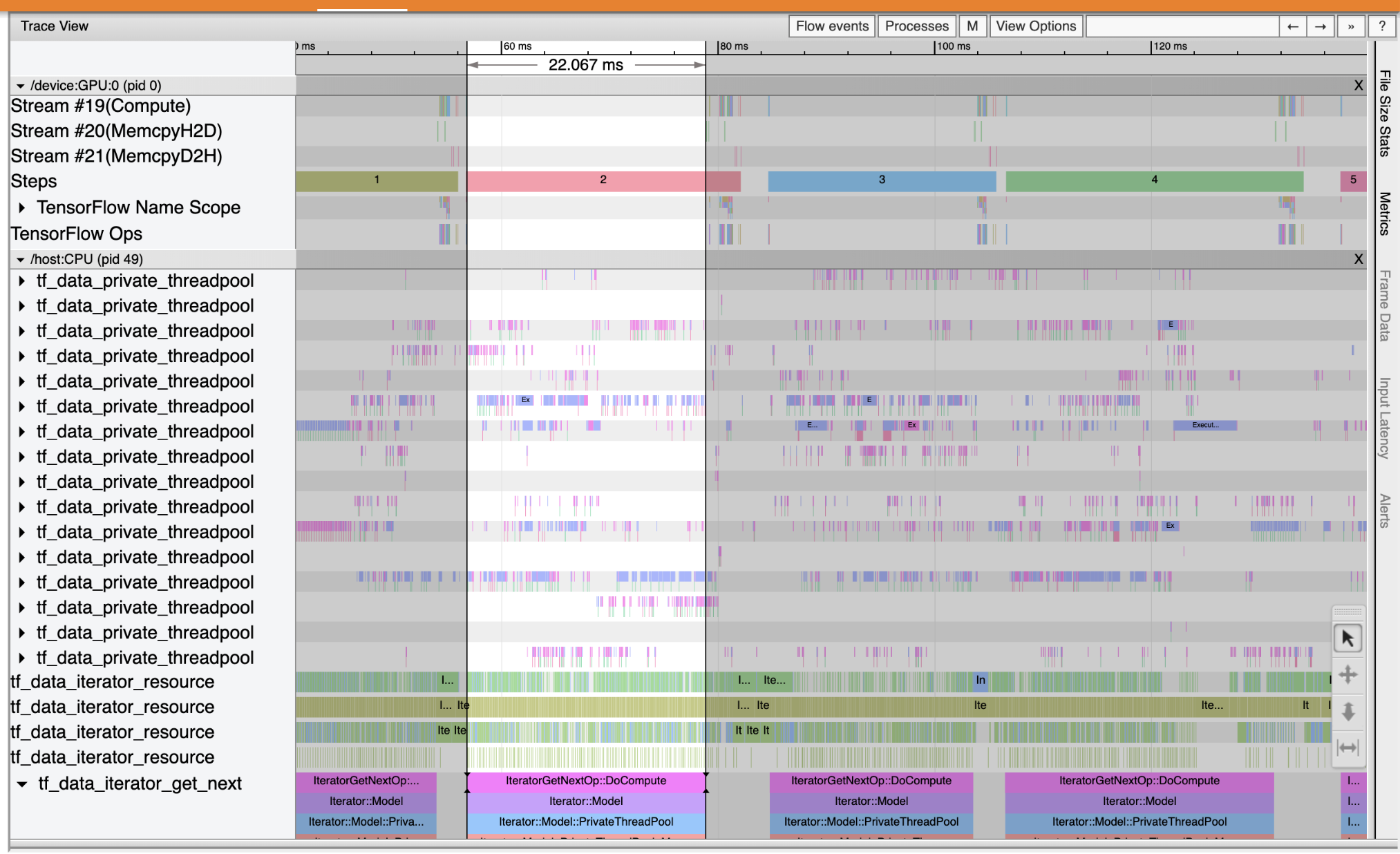
Patrząc na ślady zdarzeń, można zobaczyć, że GPU jest nieaktywna, podczas gdy tf_data_iterator_get_next op działa na CPU. Ta operacja odpowiada za przetwarzanie danych wejściowych i wysyłanie ich do GPU w celu przeszkolenia. Zgodnie z ogólną zasadą, dobrym pomysłem jest utrzymywanie zawsze aktywnego urządzenia (GPU/TPU).
Użyj tf.data API w celu optymalizacji rurociągu wejściowego. W takim przypadku zbuforujmy treningowy zestaw danych i pobierzmy dane z wyprzedzeniem, aby upewnić się, że zawsze są dostępne dane do przetworzenia przez procesor GPU. Zobacz tutaj po więcej informacji na temat korzystania tf.data zoptymalizować rurociągi wejściowych.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
Ponownie przeszkol model i przechwyć profil wydajności, ponownie wykorzystując wywołanie zwrotne z poprzedniego.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
Re-launch TensorBoard i otworzyć zakładkę Profil obserwować profil wydajności dla zaktualizowanego rurociągu wejściowym.
Profil wydajności modelu ze zoptymalizowanym potokiem wejściowym jest podobny do poniższego obrazu.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
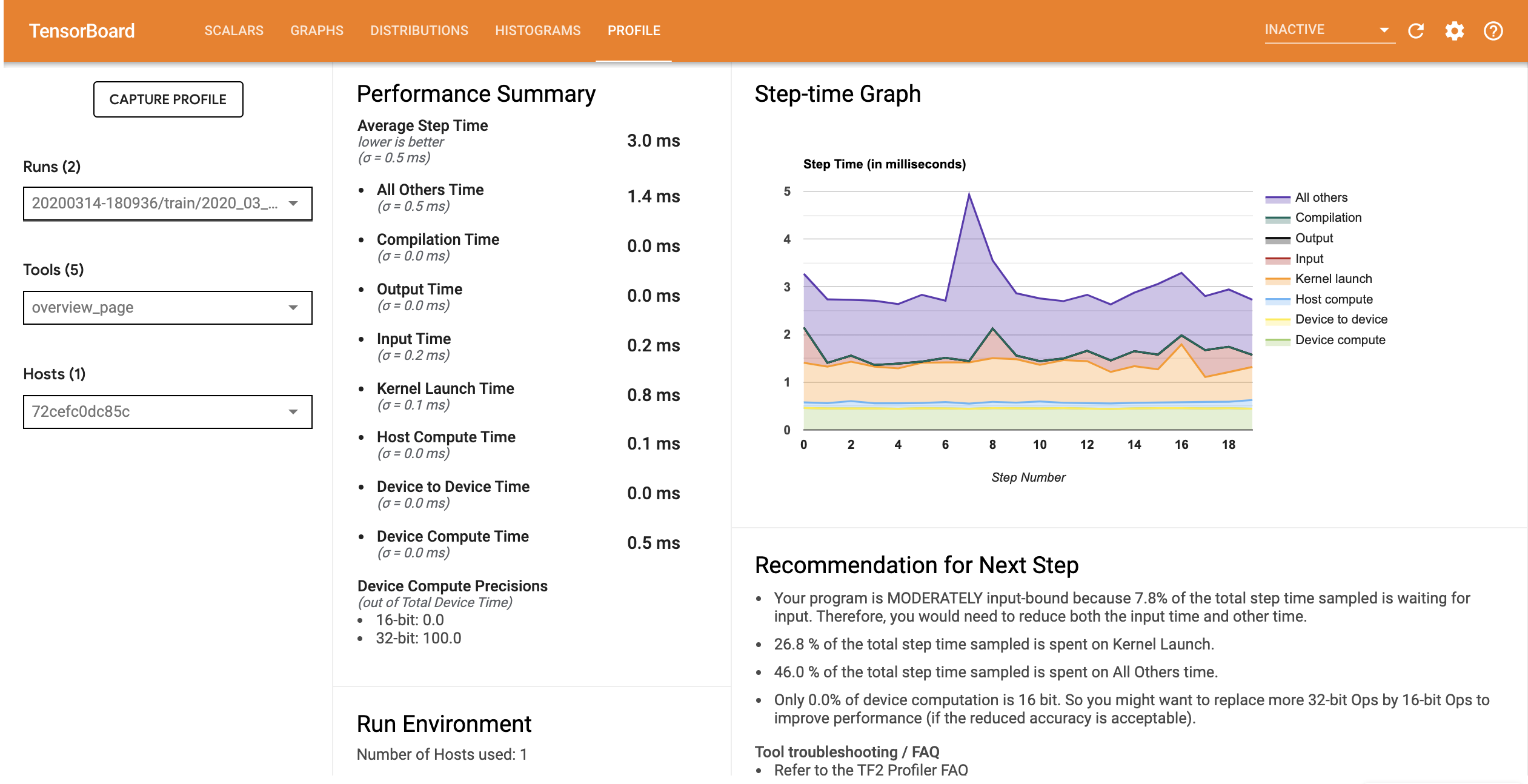
Na stronie Przegląd można zobaczyć, że średni czas kroku uległ skróceniu, podobnie jak czas kroku wejściowego. Wykres krokowy wskazuje również, że model nie jest już silnie związany z danymi wejściowymi. Otwórz przeglądarkę śledzenia, aby zbadać zdarzenia śledzenia za pomocą zoptymalizowanego potoku wejściowego.
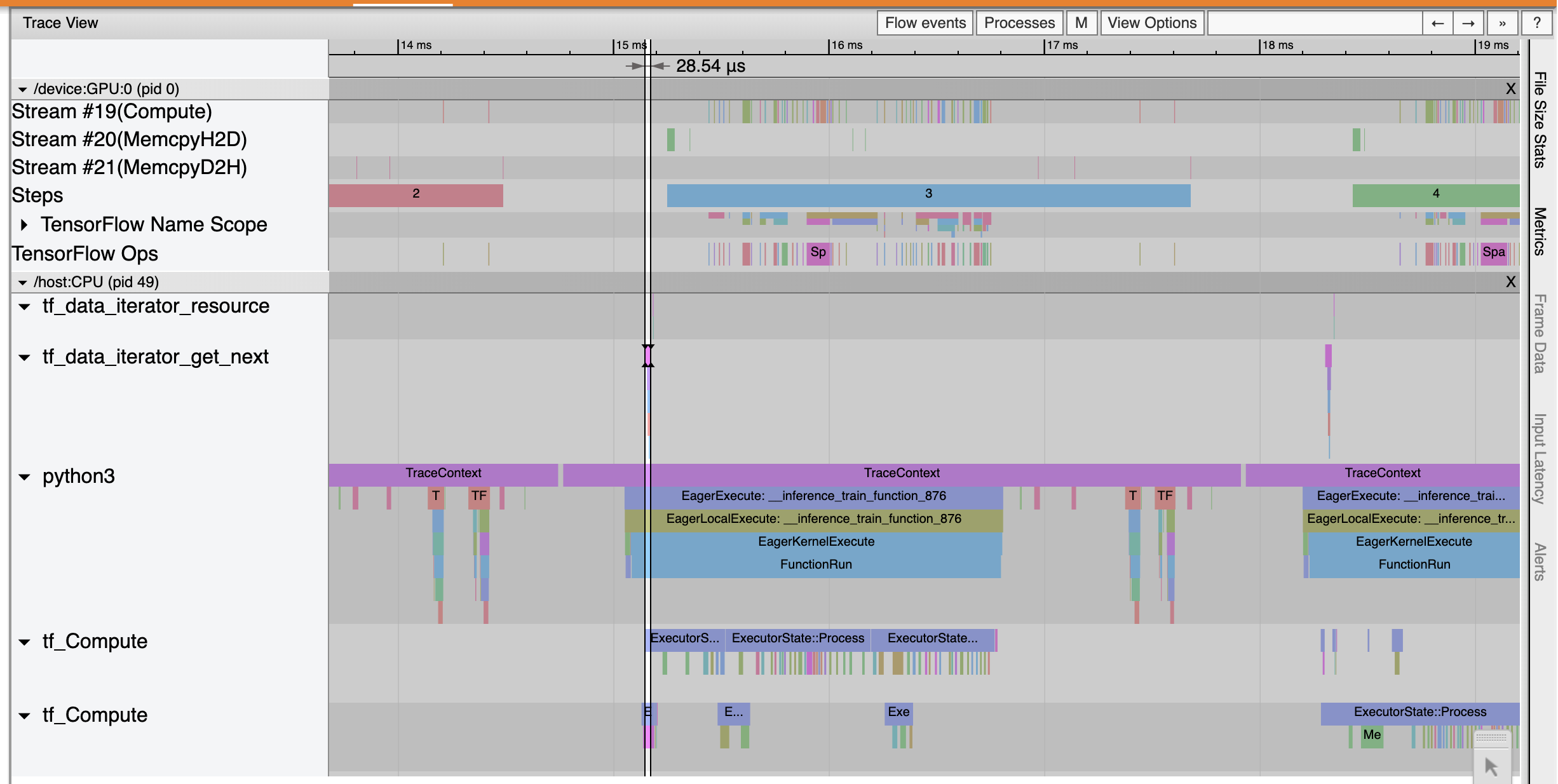
Trace Viewer pokazuje, że tf_data_iterator_get_next op wykonuje operację znacznie szybciej. W związku z tym procesor GPU otrzymuje stały strumień danych w celu przeprowadzenia szkolenia i osiąga znacznie lepsze wykorzystanie dzięki szkoleniu modelu.
Streszczenie
Użyj narzędzia TensorFlow Profiler do profilowania i debugowania wydajności uczenia modelu. Przeczytać podręcznik Profiler i oglądać profilowania wydajności w TF 2 Dyskusja z TensorFlow Dev Summit 2020, aby dowiedzieć się więcej o TensorFlow Profiler.