
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
ملخص
عادة ما تكون خوارزميات التعلم الآلي باهظة الثمن من الناحية الحسابية. لذلك من الضروري تحديد أداء تطبيق التعلم الآلي الخاص بك للتأكد من أنك تقوم بتشغيل الإصدار الأمثل من النموذج الخاص بك. استخدم TensorFlow Profiler لتوصيف تنفيذ كود TensorFlow الخاص بك.
يثبت
from datetime import datetime
from packaging import version
import os
وTensorFlow التعريف يحتاج إلى أحدث إصدارات TensorFlow وTensorBoard ( >=2.2 ).
pip install -U tensorboard_plugin_profile
import tensorflow as tf
print("TensorFlow version: ", tf.__version__)
TensorFlow version: 2.2.0-dev20200405
تأكد من أن TensorFlow يمكنه الوصول إلى وحدة معالجة الرسومات.
device_name = tf.test.gpu_device_name()
if not device_name:
raise SystemError('GPU device not found')
print('Found GPU at: {}'.format(device_name))
Found GPU at: /device:GPU:0
قم بتدريب نموذج تصنيف الصورة باستخدام عمليات رد نداء TensorBoard
في هذا البرنامج التعليمي، يمكنك استكشاف قدرات TensorFlow التعريف عن طريق الاستفادة من التعريف الأداء التي تم الحصول عليها عن طريق تدريب نموذجا الصور يصنف في مجموعة البيانات MNIST .
استخدم مجموعات بيانات TensorFlow لاستيراد بيانات التدريب وتقسيمها إلى مجموعات تدريب واختبار.
import tensorflow_datasets as tfds
tfds.disable_progress_bar()
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead set data_dir=gs://tfds-data/datasets. Downloading and preparing dataset mnist/3.0.0 (download: 11.06 MiB, generated: Unknown size, total: 11.06 MiB) to /root/tensorflow_datasets/mnist/3.0.0... Dataset mnist downloaded and prepared to /root/tensorflow_datasets/mnist/3.0.0. Subsequent calls will reuse this data.
قم بإجراء معالجة مسبقة لبيانات التدريب والاختبار عن طريق تطبيع قيم البكسل لتكون بين 0 و 1.
def normalize_img(image, label):
"""Normalizes images: `uint8` -> `float32`."""
return tf.cast(image, tf.float32) / 255., label
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
قم بإنشاء نموذج تصنيف الصور باستخدام Keras.
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(
loss='sparse_categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy']
)
قم بإنشاء رد اتصال TensorBoard لالتقاط ملفات تعريف الأداء واستدعائها أثناء تدريب النموذج.
# Create a TensorBoard callback
logs = "logs/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tboard_callback = tf.keras.callbacks.TensorBoard(log_dir = logs,
histogram_freq = 1,
profile_batch = '500,520')
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 11s 22ms/step - loss: 0.3684 - accuracy: 0.8981 - val_loss: 0.1971 - val_accuracy: 0.9436 Epoch 2/2 50/469 [==>...........................] - ETA: 9s - loss: 0.2014 - accuracy: 0.9439WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow/python/ops/summary_ops_v2.py:1271: stop (from tensorflow.python.eager.profiler) is deprecated and will be removed after 2020-07-01. Instructions for updating: use `tf.profiler.experimental.stop` instead. 469/469 [==============================] - 11s 24ms/step - loss: 0.1685 - accuracy: 0.9525 - val_loss: 0.1376 - val_accuracy: 0.9595 <tensorflow.python.keras.callbacks.History at 0x7f23919a6a58>
استخدم TensorFlow Profiler لتشكيل نموذج أداء التدريب
تم تضمين ملف التعريف TensorFlow في TensorBoard. قم بتحميل TensorBoard باستخدام Colab magic وقم بتشغيله. عرض ملامح الأداء من خلال الانتقال إلى علامة التبويب الملف.
# Load the TensorBoard notebook extension.
%load_ext tensorboard
ملف تعريف الأداء لهذا النموذج مشابه للصورة أدناه.
# Launch TensorBoard and navigate to the Profile tab to view performance profile
%tensorboard --logdir=logs
<IPython.core.display.Javascript object>
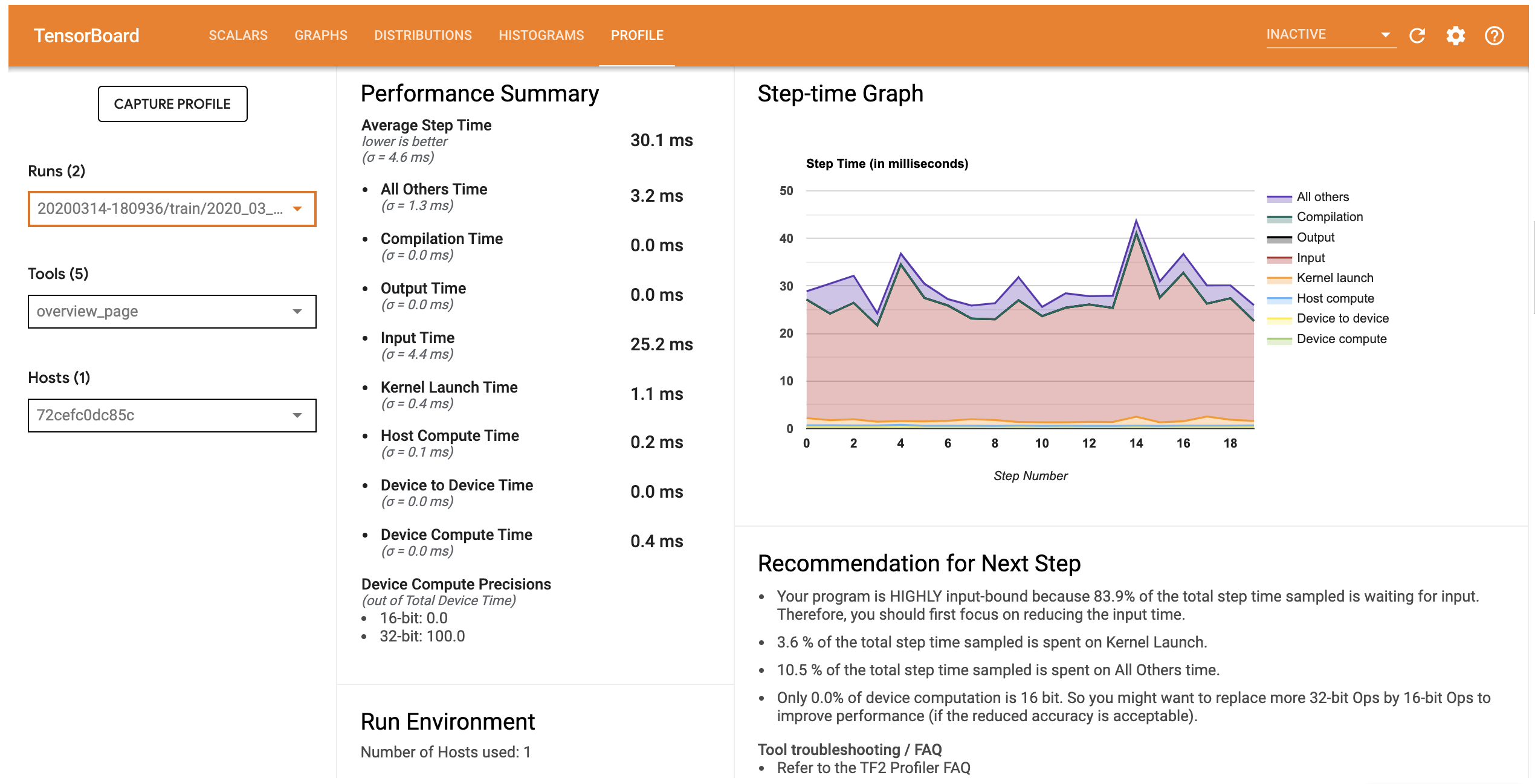
علامة التبويب الملف يفتح صفحة نظرة عامة الذي يظهر لك ملخص رفيع المستوى من الأداء النموذج الخاص بك. بالنظر إلى الرسم البياني Step-time على اليمين ، يمكنك أن ترى أن النموذج مرتبط بدرجة عالية بالإدخال (أي أنه يقضي الكثير من الوقت في خط إدخال البيانات). توفر لك صفحة النظرة العامة أيضًا توصيات بشأن الخطوات التالية المحتملة التي يمكنك اتباعها لتحسين أداء النموذج الخاص بك.
لفهم أين يحدث عنق الزجاجة الأداء في خط أنابيب المدخلات، وتحديد عارض تتبع من أدوات القائمة المنسدلة على اليسار. يعرض لك Trace Viewer مخططًا زمنيًا للأحداث المختلفة التي حدثت على وحدة المعالجة المركزية ووحدة معالجة الرسومات أثناء فترة التوصيف.
يعرض عارض التتبع مجموعات أحداث متعددة على المحور الرأسي. تحتوي كل مجموعة حدث على مسارات أفقية متعددة ، مليئة بأحداث التتبع. المسار عبارة عن مخطط زمني لحدث الأحداث المنفذة في سلسلة رسائل أو دفق GPU. الأحداث الفردية هي الكتل الملونة والمستطيلة على مسارات الخط الزمني. يتحرك الوقت من اليسار إلى اليمين. انتقل الأحداث تتبع باستخدام اختصارات لوحة المفاتيح W (تكبير)، S (تصغير)، A (يقم التمرير)، و D (التمرير إلى اليمين).
يمثل مستطيل واحد حدث تتبع. حدد رمز مؤشر الماوس في شريط الأدوات العائمة (أو استخدام اختصار لوحة المفاتيح 1 ) وفوق الحدث تتبع لتحليلها. سيعرض هذا معلومات حول الحدث ، مثل وقت بدئه ومدته.
بالإضافة إلى النقر ، يمكنك سحب الماوس لتحديد مجموعة من أحداث التتبع. سيعطيك هذا قائمة بجميع الأحداث في تلك المنطقة جنبًا إلى جنب مع ملخص الحدث. استخدام M المفتاح لقياس المدة الزمنية للأحداث محددة.
يتم جمع أحداث التتبع من:
- وحدة المعالجة المركزية: يتم عرض الأحداث CPU تحت جماعة حدث مسمى
/host:CPU. يمثل كل مسار موضوعًا على وحدة المعالجة المركزية. تتضمن أحداث وحدة المعالجة المركزية أحداث مسار الإدخال ، وأحداث جدولة تشغيل وحدة معالجة الرسومات (OP) ، وأحداث تنفيذ تشغيل وحدة المعالجة المركزية ، إلخ. - يتم عرض الأحداث GPU تحت مجموعة الحدث مسبوقة من قبل: GPU
/device:GPU:. تمثل كل مجموعة حدث دفقًا واحدًا على وحدة معالجة الرسومات.
تصحيح أخطاء الأداء
استخدم عارض التتبع لتحديد مواضع الاختناقات في الأداء في خط أنابيب الإدخال. الصورة أدناه هي لقطة لملف تعريف الأداء.
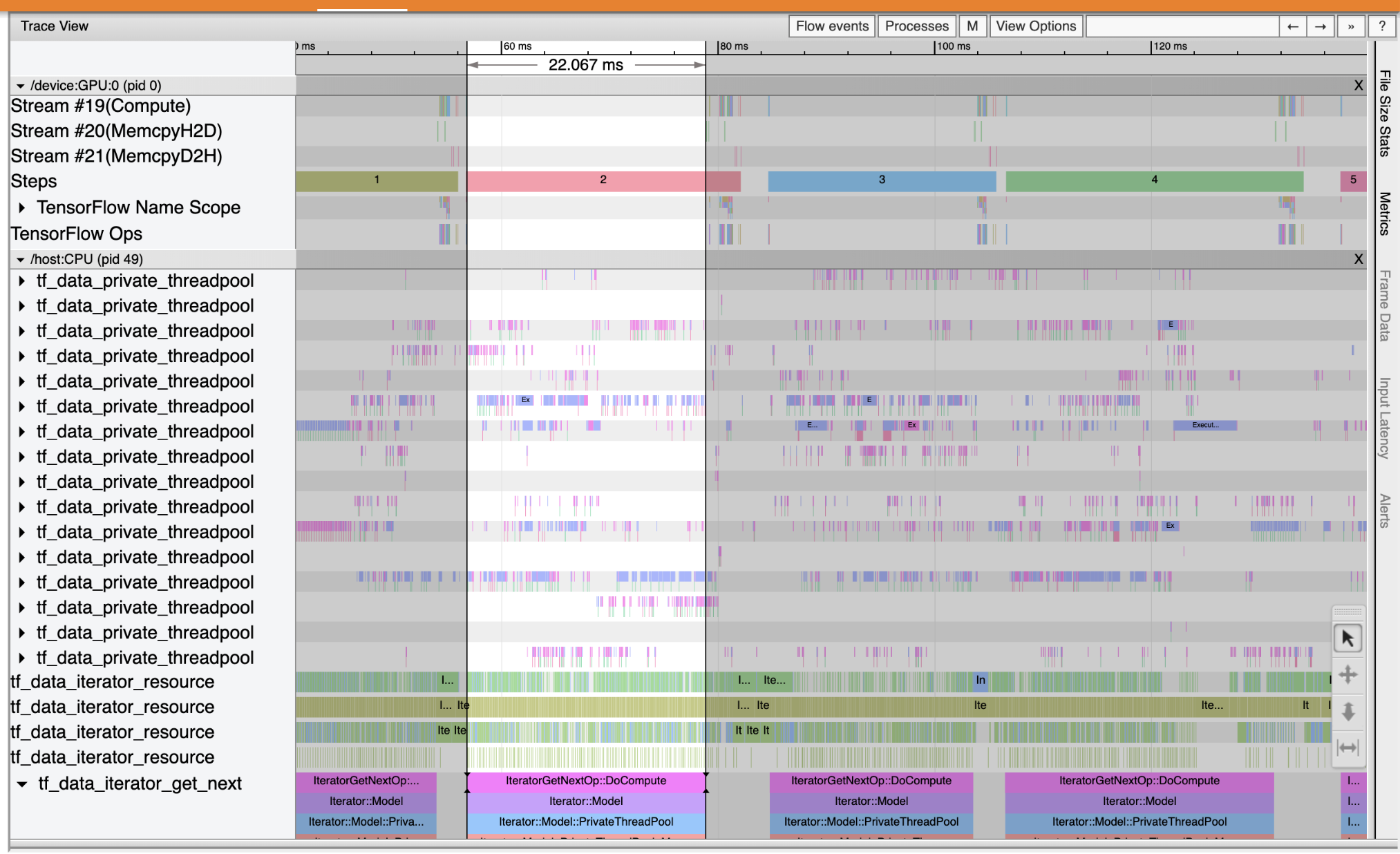
وعند النظر إلى آثار الحدث، يمكنك أن ترى أن GPU غير نشط في حين أن tf_data_iterator_get_next المرجع قيد التشغيل على وحدة المعالجة المركزية. هذا المرجع مسؤول عن معالجة بيانات الإدخال وإرسالها إلى GPU للتدريب. كقاعدة عامة ، من الجيد إبقاء الجهاز نشطًا دائمًا (GPU / TPU).
استخدام tf.data API لتحسين خط أنابيب الإدخال. في هذه الحالة ، دعنا نخزن مجموعة بيانات التدريب مؤقتًا ونقوم بجلب البيانات مسبقًا للتأكد من وجود بيانات متاحة دائمًا لمعالجتها وحدة معالجة الرسومات. انظر هنا لمزيد من التفاصيل حول استخدام tf.data لتحسين خطوط أنابيب الإدخال.
(ds_train, ds_test), ds_info = tfds.load(
'mnist',
split=['train', 'test'],
shuffle_files=True,
as_supervised=True,
with_info=True,
)
ds_train = ds_train.map(normalize_img)
ds_train = ds_train.batch(128)
ds_train = ds_train.cache()
ds_train = ds_train.prefetch(tf.data.experimental.AUTOTUNE)
ds_test = ds_test.map(normalize_img)
ds_test = ds_test.batch(128)
ds_test = ds_test.cache()
ds_test = ds_test.prefetch(tf.data.experimental.AUTOTUNE)
تدريب النموذج مرة أخرى والتقاط ملف تعريف الأداء عن طريق إعادة استخدام رد الاتصال من قبل.
model.fit(ds_train,
epochs=2,
validation_data=ds_test,
callbacks = [tboard_callback])
Epoch 1/2 469/469 [==============================] - 10s 22ms/step - loss: 0.1194 - accuracy: 0.9658 - val_loss: 0.1116 - val_accuracy: 0.9680 Epoch 2/2 469/469 [==============================] - 1s 3ms/step - loss: 0.0918 - accuracy: 0.9740 - val_loss: 0.0979 - val_accuracy: 0.9712 <tensorflow.python.keras.callbacks.History at 0x7f23908762b0>
إعادة إطلاق TensorBoard وفتح الملف علامة التبويب لمراقبة الشخصي لأداء خط أنابيب المدخلات التي تم تحديثها.
ملف تعريف الأداء للنموذج مع خط أنابيب الإدخال الأمثل مشابه للصورة أدناه.
%tensorboard --logdir=logs
Reusing TensorBoard on port 6006 (pid 750), started 0:00:12 ago. (Use '!kill 750' to kill it.) <IPython.core.display.Javascript object>
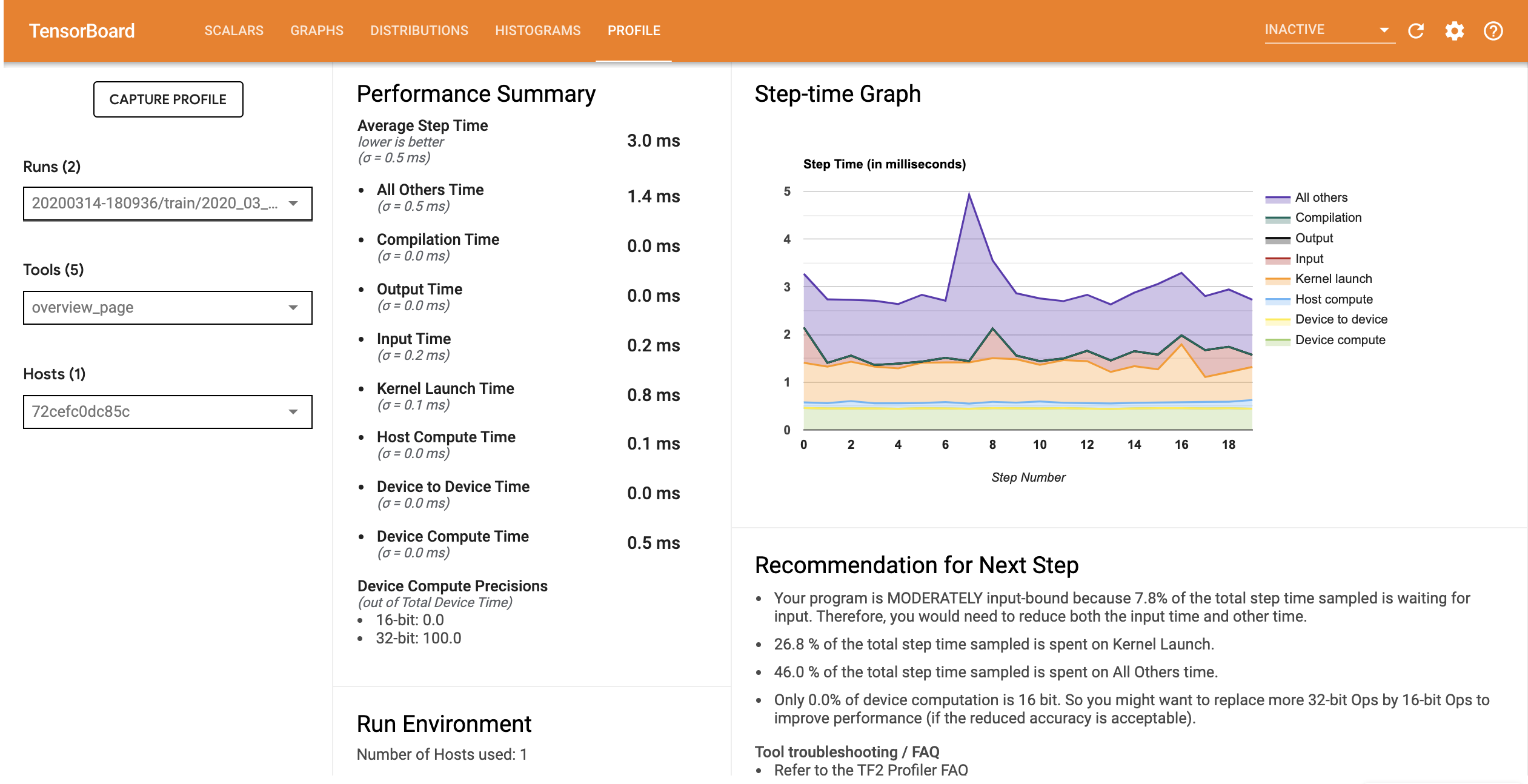
من صفحة نظرة عامة ، يمكنك أن ترى أن متوسط وقت الخطوة قد انخفض كما هو الحال في وقت خطوة الإدخال. يشير الرسم البياني لوقت الخطوة أيضًا إلى أن النموذج لم يعد مرتبطًا بشكل كبير بالمدخلات. افتح Trace Viewer لفحص أحداث التتبع باستخدام خط أنابيب الإدخال الأمثل.
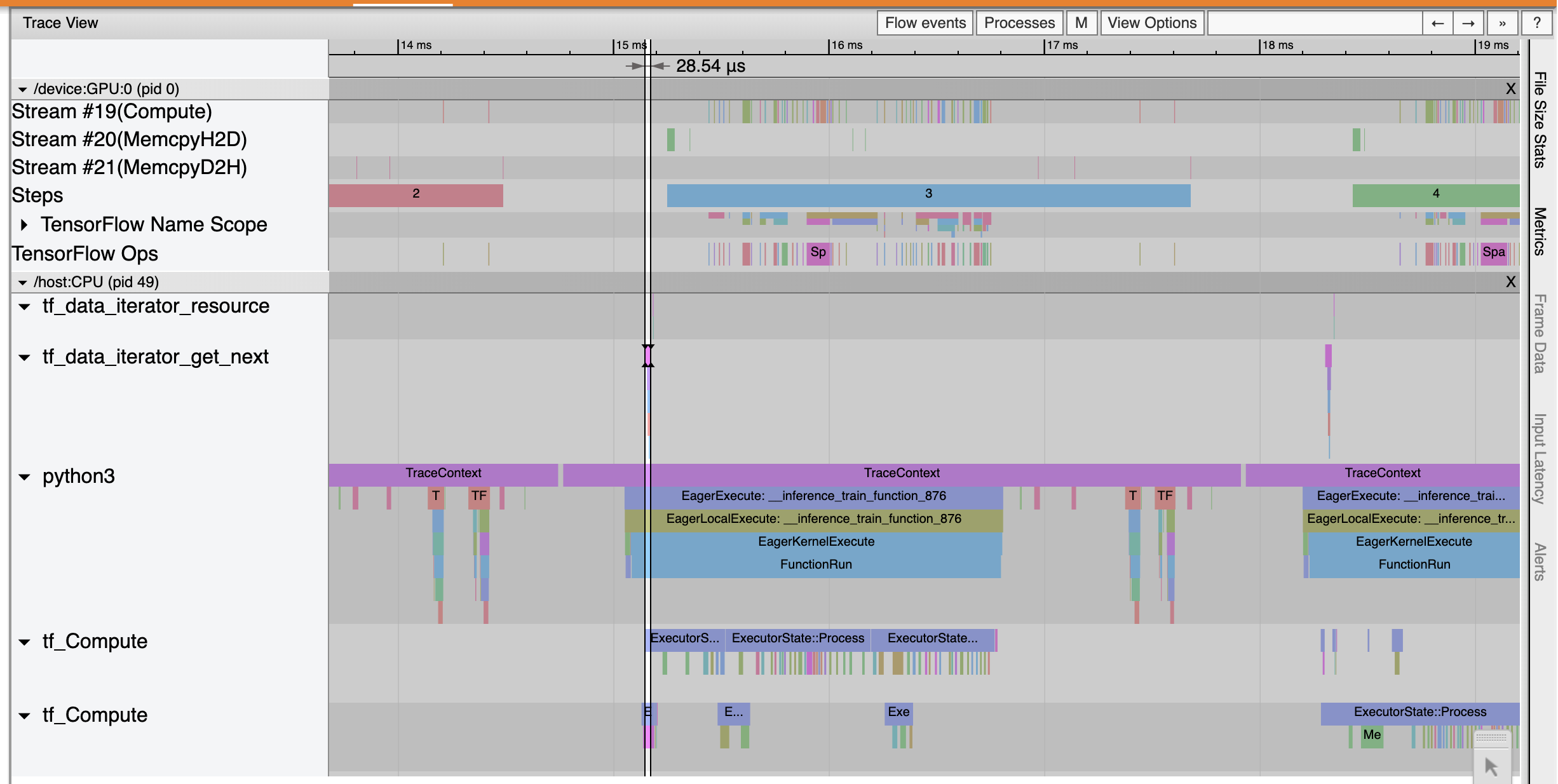
يظهر تتبع عارض أن tf_data_iterator_get_next المرجع تنفيذ أسرع بكثير. لذلك تحصل وحدة معالجة الرسومات (GPU) على دفق مستمر من البيانات لأداء التدريب وتحقيق استخدام أفضل بكثير من خلال تدريب النموذج.
ملخص
استخدم TensorFlow Profiler لملف تعريف وتصحيح أداء تدريب النموذج. قراءة دليل التعريف ومشاهدة التنميط الأداء في TF 2 الحديث عن القمة TensorFlow ديف عام 2020 لمعرفة المزيد عن TensorFlow التعريف.