
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub | |
Quando si costruisce modelli di apprendimento automatico, è necessario scegliere vari iperparametri , come ad esempio il tasso di abbandono in un livello o il tasso di apprendimento. Queste decisioni influiscono sulle metriche del modello, come l'accuratezza. Pertanto, un passaggio importante nel flusso di lavoro dell'apprendimento automatico consiste nell'identificare i migliori iperparametri per il tuo problema, che spesso implica la sperimentazione. Questo processo è noto come "ottimizzazione degli iperparametri" o "ottimizzazione degli iperparametri".
Il dashboard HParams in TensorBoard fornisce diversi strumenti per aiutare con questo processo di identificazione dell'esperimento migliore o dei set di iperparametri più promettenti.
Questo tutorial si concentrerà sui seguenti passaggi:
- Configurazione dell'esperimento e riepilogo di HParams
- Adapt TensorFlow viene eseguito per registrare iperparametri e metriche
- Avvia le esecuzioni e registrale tutte in una directory principale
- Visualizza i risultati nella dashboard HParams di TensorBoard
Inizia installando TF 2.0 e caricando l'estensione per notebook TensorBoard:
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Clear any logs from previous runsrm -rf ./logs/
Importa TensorFlow e il plugin TensorBoard HParams:
import tensorflow as tf
from tensorboard.plugins.hparams import api as hp
Scarica il FashionMNIST set di dati e scalarla:
fashion_mnist = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step
1. Configurazione dell'esperimento e riepilogo dell'esperimento HParams
Sperimenta con tre iperparametri nel modello:
- Numero di unità nel primo strato denso
- Tasso di abbandono nel livello di abbandono
- Ottimizzatore
Elenca i valori da provare e registra una configurazione dell'esperimento su TensorBoard. Questo passaggio è facoltativo: puoi fornire informazioni sul dominio per abilitare un filtro più preciso degli iperparametri nell'interfaccia utente e puoi specificare quali metriche devono essere visualizzate.
HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32]))
HP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.2))
HP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd']))
METRIC_ACCURACY = 'accuracy'
with tf.summary.create_file_writer('logs/hparam_tuning').as_default():
hp.hparams_config(
hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],
metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],
)
Se si sceglie di saltare questo passaggio, è possibile utilizzare una stringa letterale, ovunque si sarebbe altrimenti utilizzare un HParam valore: per esempio, hparams['dropout'] invece di hparams[HP_DROPOUT] .
2. Adapt TensorFlow viene eseguito per registrare iperparametri e metriche
Il modello sarà abbastanza semplice: due strati densi con uno strato di eliminazione tra di loro. Il codice di training sembrerà familiare, anche se gli iperparametri non sono più hardcoded. Invece, i iperparametri sono forniti in un hparams Dizionario e utilizzati in tutto la funzione di formazione:
def train_test_model(hparams):
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),
tf.keras.layers.Dropout(hparams[HP_DROPOUT]),
tf.keras.layers.Dense(10, activation=tf.nn.softmax),
])
model.compile(
optimizer=hparams[HP_OPTIMIZER],
loss='sparse_categorical_crossentropy',
metrics=['accuracy'],
)
model.fit(x_train, y_train, epochs=1) # Run with 1 epoch to speed things up for demo purposes
_, accuracy = model.evaluate(x_test, y_test)
return accuracy
Per ogni esecuzione, registra un riepilogo hparams con gli iperparametri e la precisione finale:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)
Quando si addestrano i modelli Keras, è possibile utilizzare i callback invece di scriverli direttamente:
model.fit(
...,
callbacks=[
tf.keras.callbacks.TensorBoard(logdir), # log metrics
hp.KerasCallback(logdir, hparams), # log hparams
],
)
3. Avvia le esecuzioni e registrale tutte in un'unica directory principale
Ora puoi provare più esperimenti, addestrando ciascuno con un diverso set di iperparametri.
Per semplicità, usa una ricerca a griglia: prova tutte le combinazioni dei parametri discreti e solo i limiti inferiore e superiore del parametro a valori reali. Per scenari più complessi, potrebbe essere più efficace scegliere ogni valore di iperparametro in modo casuale (questa è chiamata ricerca casuale). Ci sono metodi più avanzati che possono essere utilizzati.
Esegui alcuni esperimenti, che richiederanno alcuni minuti:
session_num = 0
for num_units in HP_NUM_UNITS.domain.values:
for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS: num_units,
HP_DROPOUT: dropout_rate,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('--- Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1
--- Starting trial: run-0
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 62us/sample - loss: 0.6872 - accuracy: 0.7564
10000/10000 [==============================] - 0s 35us/sample - loss: 0.4806 - accuracy: 0.8321
--- Starting trial: run-1
{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9428 - accuracy: 0.6769
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6519 - accuracy: 0.7770
--- Starting trial: run-2
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 60us/sample - loss: 0.8158 - accuracy: 0.7078
10000/10000 [==============================] - 0s 36us/sample - loss: 0.5309 - accuracy: 0.8154
--- Starting trial: run-3
{'num_units': 16, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 50us/sample - loss: 1.1465 - accuracy: 0.6019
10000/10000 [==============================] - 0s 36us/sample - loss: 0.7007 - accuracy: 0.7683
--- Starting trial: run-4
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 65us/sample - loss: 0.6178 - accuracy: 0.7849
10000/10000 [==============================] - 0s 38us/sample - loss: 0.4645 - accuracy: 0.8395
--- Starting trial: run-5
{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 55us/sample - loss: 0.8989 - accuracy: 0.6896
10000/10000 [==============================] - 0s 37us/sample - loss: 0.6335 - accuracy: 0.7853
--- Starting trial: run-6
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'adam'}
60000/60000 [==============================] - 4s 64us/sample - loss: 0.6404 - accuracy: 0.7782
10000/10000 [==============================] - 0s 37us/sample - loss: 0.4802 - accuracy: 0.8265
--- Starting trial: run-7
{'num_units': 32, 'dropout': 0.2, 'optimizer': 'sgd'}
60000/60000 [==============================] - 3s 54us/sample - loss: 0.9633 - accuracy: 0.6703
10000/10000 [==============================] - 0s 36us/sample - loss: 0.6516 - accuracy: 0.7755
4. Visualizza i risultati nel plugin HParams di TensorBoard
È ora possibile aprire il dashboard di HParams. Avvia TensorBoard e clicca su "HParams" in alto.
%tensorboard --logdir logs/hparam_tuning
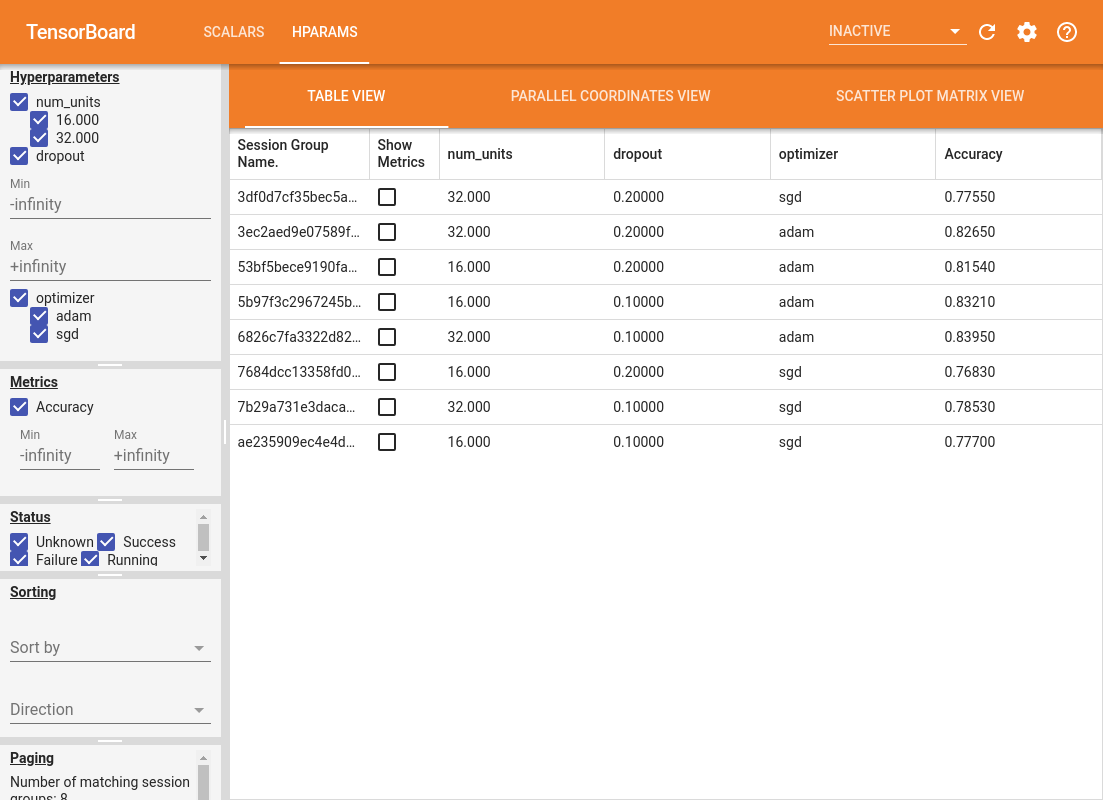
Il riquadro sinistro del dashboard fornisce funzionalità di filtro attive in tutte le viste nel dashboard HParams:
- Filtra quali iperparametri/metriche vengono mostrati nella dashboard
- Filtra quali valori di iperparametri/metriche vengono visualizzati nella dashboard
- Filtra lo stato di esecuzione (in esecuzione, successo, ...)
- Ordina per iperparametro/metrica nella vista tabella
- Numero di gruppi di sessioni da mostrare (utile per il rendimento quando ci sono molti esperimenti)
Il dashboard di HParams ha tre diverse visualizzazioni, con diverse informazioni utili:
- La Table View elenca le piste, i loro iperparametri, e le loro metriche.
- Il Parallel Coordinate View mostra ogni esecuzione come una linea passa attraverso un asse per ogni hyperparemeter e metrica. Fare clic e trascinare il mouse su qualsiasi asse per contrassegnare una regione che evidenzierà solo le piste che la attraversano. Questo può essere utile per identificare quali gruppi di iperparametri sono più importanti. Gli assi stessi possono essere riordinati trascinandoli.
- I Scatter Plot View mostra trame confrontando ogni iperparametro / metrica con ogni metrica. Questo può aiutare a identificare le correlazioni. Fare clic e trascinare per selezionare una regione in un grafico specifico ed evidenziare quelle sessioni negli altri grafici.
È possibile fare clic su una riga della tabella, una linea di coordinate parallele e un mercato del grafico a dispersione per visualizzare un grafico delle metriche in funzione dei passaggi di allenamento per quella sessione (sebbene in questo tutorial venga utilizzato solo un passaggio per ogni esecuzione).
Per esplorare ulteriormente le funzionalità del dashboard HParams, scarica una serie di log pregenerati con più esperimenti:
wget -q 'https://storage.googleapis.com/download.tensorflow.org/tensorboard/hparams_demo_logs.zip'unzip -q hparams_demo_logs.zip -d logs/hparam_demo
Visualizza questi log in TensorBoard:
%tensorboard --logdir logs/hparam_demo
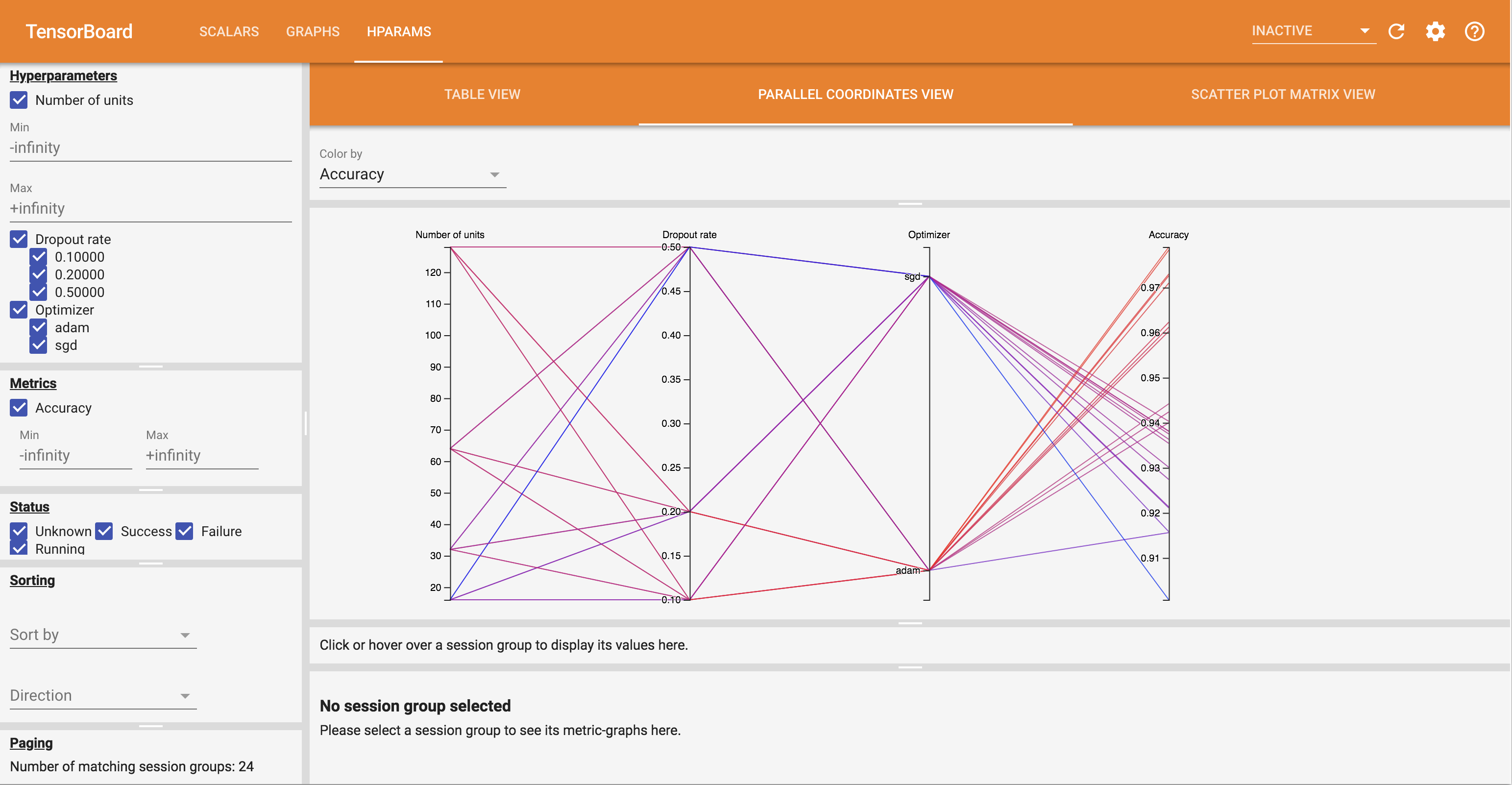
Puoi provare le diverse visualizzazioni nella dashboard di HParams.
Ad esempio, andando alla vista delle coordinate parallele e facendo clic e trascinando sull'asse di precisione, è possibile selezionare le corse con la massima precisione. Poiché queste esecuzioni passano attraverso "adam" nell'asse dell'ottimizzatore, puoi concludere che "adam" ha funzionato meglio di "sgd" in questi esperimenti.