
Katastrofalne zdarzenia z udziałem NaN mogą czasami wystąpić podczas programu TensorFlow, paraliżując procesy uczenia modelu. Podstawowa przyczyna takich zdarzeń jest często niejasna, szczególnie w przypadku modeli o nietrywialnych rozmiarach i złożoności. Aby ułatwić debugowanie tego typu błędów modelu, TensorBoard 2.3+ (wraz z TensorFlow 2.3+) udostępnia wyspecjalizowany pulpit nawigacyjny o nazwie Debugger V2. Tutaj pokazujemy, jak korzystać z tego narzędzia, naprawiając prawdziwy błąd związany z NaN w sieci neuronowej napisany w TensorFlow.
Techniki przedstawione w tym samouczku mają zastosowanie do innych typów działań związanych z debugowaniem, takich jak sprawdzanie kształtów tensora czasu wykonywania w złożonych programach. Ten samouczek skupia się na NaN ze względu na ich stosunkowo dużą częstotliwość występowania.
Obserwuję błąd
Kod źródłowy programu TF2, który będziemy debugować, jest dostępny na GitHubie . Przykładowy program jest również spakowany w pakiecie pip tensorflow (wersja 2.3+) i można go wywołać za pomocą:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2
Ten program TF2 tworzy percepcję wielowarstwową (MLP) i uczy ją rozpoznawania obrazów MNIST . W tym przykładzie celowo użyto niskopoziomowego API TF2 do zdefiniowania niestandardowych konstrukcji warstw, funkcji straty i pętli szkoleniowej, ponieważ prawdopodobieństwo wystąpienia błędów NaN jest większe, gdy używamy tego bardziej elastycznego, ale bardziej podatnego na błędy API, niż gdy używamy łatwiejszego -w użyciu, ale nieco mniej elastyczne interfejsy API wysokiego poziomu, takie jak tf.keras .
Program drukuje dokładność testu po każdym etapie szkolenia. W konsoli widzimy, że dokładność testu utknęła na poziomie bliskim szansy (~0,1) po pierwszym kroku. Z pewnością nie jest to sposób, w jaki oczekuje się zachowania uczenia modelu: oczekujemy, że dokładność będzie stopniowo zbliżać się do 1,0 (100%) w miarę zwiększania kroku.
Accuracy at step 0: 0.216
Accuracy at step 1: 0.098
Accuracy at step 2: 0.098
Accuracy at step 3: 0.098
...
Można przypuszczać, że przyczyną tego problemu jest niestabilność liczbowa, taka jak NaN lub nieskończoność. Jak jednak możemy potwierdzić, że tak naprawdę jest i jak znaleźć operację TensorFlow (op) odpowiedzialną za generowanie niestabilności numerycznej? Aby odpowiedzieć na te pytania, zinstrumentujmy błędny program za pomocą Debuggera V2.
Instrumentacja kodu TensorFlow za pomocą Debuggera V2
tf.debugging.experimental.enable_dump_debug_info() to punkt wejścia API Debuggera V2. Instrumentuje program TF2 za pomocą pojedynczej linii kodu. Na przykład dodanie poniższej linii na początku programu spowoduje zapisanie informacji debugowania w katalogu dziennika (logdir) pod adresem /tmp/tfdbg2_logdir. Informacje debugowania obejmują różne aspekty środowiska wykonawczego TensorFlow. W TF2 obejmuje pełną historię szybkiego wykonywania, budowanie grafów wykonywane przez @tf.function , wykonywanie wykresów, wartości tensora wygenerowane przez zdarzenia wykonania, a także lokalizację kodu (ślady stosu Pythona) tych zdarzeń . Bogactwo informacji debugowania umożliwia użytkownikom zawężenie zakresu niejasnych błędów.
tf.debugging.experimental.enable_dump_debug_info(
"/tmp/tfdbg2_logdir",
tensor_debug_mode="FULL_HEALTH",
circular_buffer_size=-1)
Argument tensor_debug_mode kontroluje, jakie informacje debuger V2 wyodrębnia z każdego tensora chętnie lub w grafie. „FULL_HEALTH” to tryb, który przechwytuje następujące informacje o każdym tensorze typu zmiennoprzecinkowego (np. powszechnie spotykanym typie float32 i mniej powszechnym typie bfloat16 ):
- Typ D
- Stopień
- Całkowita liczba elementów
- Podział elementów zmiennoprzecinkowych na następujące kategorie: ujemnie skończony (
-), zero (0), dodatnio skończony (+), ujemna nieskończoność (-∞), dodatnia nieskończoność (+∞) iNaN.
Tryb „FULL_HEALTH” jest odpowiedni do debugowania błędów związanych z NaN i nieskończonością. Poniżej znajdziesz inne obsługiwane tensor_debug_mode s.
Argument circular_buffer_size kontroluje liczbę zdarzeń tensorowych zapisywanych w katalogu logdir. Domyślną wartością jest 1000, co powoduje zapisanie na dysku tylko ostatnich 1000 tensorów przed końcem oprzyrządowanego programu TF2. To domyślne zachowanie zmniejsza obciążenie debugera, poświęcając kompletność danych debugowania. Jeśli preferowana jest kompletność, jak w tym przypadku, możemy wyłączyć bufor cykliczny, ustawiając argument na wartość ujemną (np. tutaj -1).
Przykład debug_mnist_v2 wywołuje enable_dump_debug_info() przekazując do niej flagi wiersza poleceń. Aby ponownie uruchomić nasz problematyczny program TF2 z włączonym instrumentem do debugowania, wykonaj:
python -m tensorflow.python.debug.examples.v2.debug_mnist_v2 \
--dump_dir /tmp/tfdbg2_logdir --dump_tensor_debug_mode FULL_HEALTH
Uruchamianie GUI Debuggera V2 w TensorBoard
Uruchomienie programu z instrumentacją debugera tworzy katalog logdir w /tmp/tfdbg2_logdir. Możemy uruchomić TensorBoard i wskazać go na logdir za pomocą:
tensorboard --logdir /tmp/tfdbg2_logdir
W przeglądarce internetowej przejdź do strony TensorBoard pod adresem http://localhost:6006. Wtyczka „Debugger V2” będzie domyślnie nieaktywna, dlatego wybierz ją z menu „Nieaktywne wtyczki” w prawym górnym rogu. Po wybraniu powinno wyglądać następująco:
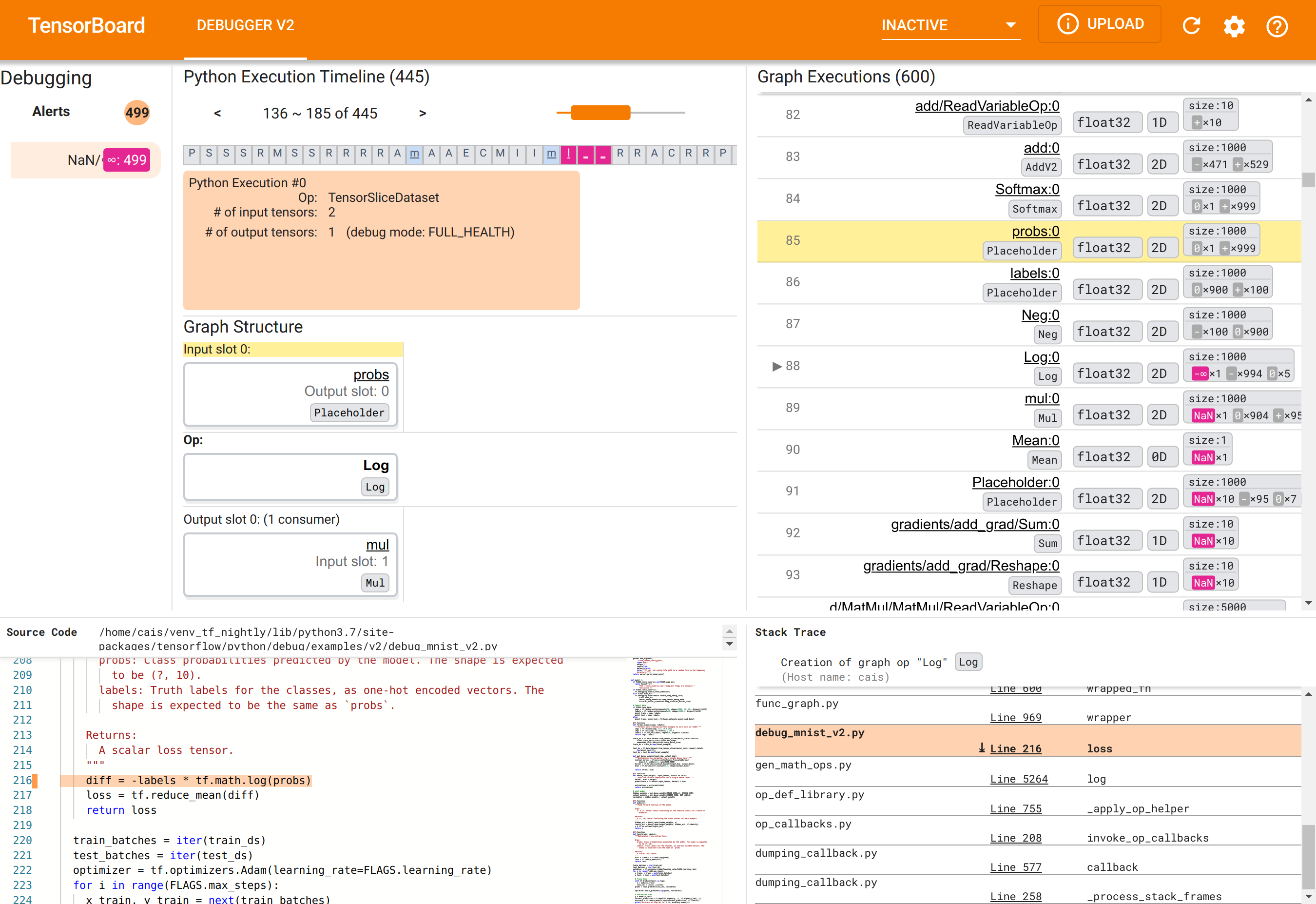
Korzystanie z interfejsu graficznego Debuggera V2 w celu znalezienia głównej przyczyny NaN
GUI Debuggera V2 w TensorBoard jest podzielone na sześć sekcji:
- Alerty : ta sekcja w lewym górnym rogu zawiera listę zdarzeń „alertowych” wykrytych przez debuger w danych debugowania z instrumentowanego programu TensorFlow. Każdy alert wskazuje na pewną anomalię wymagającą uwagi. W naszym przypadku w tej sekcji wyróżniono 499 zdarzeń NaN/∞ wyraźnym różowo-czerwonym kolorem. Potwierdza to nasze podejrzenie, że model nie uczy się z powodu obecności NaN i/lub nieskończoności w jego wewnętrznych wartościach tensora. Wkrótce zajmiemy się tymi alertami.
- Oś czasu wykonania Pythona : jest to górna połowa górnej i środkowej sekcji. Przedstawia pełną historię gorliwej realizacji operacji oraz wykresy. Każde pole osi czasu jest oznaczone początkową literą nazwy operacji lub wykresu (np. „T” dla operacji „TensorSliceDataset”, „m” dla funkcji „model”
tf.function). Możemy poruszać się po tej osi czasu za pomocą przycisków nawigacyjnych i paska przewijania nad osią czasu. - Wykonywanie wykresu : ta sekcja, znajdująca się w prawym górnym rogu GUI, będzie kluczowa dla naszego zadania debugowania. Zawiera historię wszystkich tensorów typu zmiennoprzecinkowego obliczonych wewnątrz grafów (tj. skompilowanych przez
@tf-functions). - Struktura wykresu (dolna połowa górnej środkowej sekcji), Kod źródłowy (lewa dolna sekcja) i Stack Trace (dolna prawa sekcja) są początkowo puste. Ich zawartość zostanie zapełniona podczas interakcji z GUI. Te trzy sekcje będą również odgrywać ważną rolę w naszym zadaniu debugowania.
Po zapoznaniu się z organizacją interfejsu użytkownika wykonajmy następujące kroki, aby dowiedzieć się, dlaczego pojawiły się NaN. Najpierw kliknij alert NaN/∞ w sekcji Alerty. Spowoduje to automatyczne przewinięcie listy 600 tensorów grafów w sekcji Wykonywanie wykresu i skupienie się na numerze 88, który jest tensorem o nazwie Log:0 wygenerowanym przez Log (logarytm naturalny) op. Wyraźny różowo-czerwony kolor podkreśla element -∞ spośród 1000 elementów tensora 2D float32. Jest to pierwszy tensor w historii wykonania programu TF2, który zawierał dowolny NaN lub nieskończoność: tensory obliczone wcześniej nie zawierały NaN ani ∞; wiele (właściwie większość) obliczonych później tensorów zawiera NaN. Możemy to potwierdzić przewijając w górę i w dół listę wykonania wykresu. Ta obserwacja stanowi silną wskazówkę, że Log op jest źródłem niestabilności numerycznej w tym programie TF2.
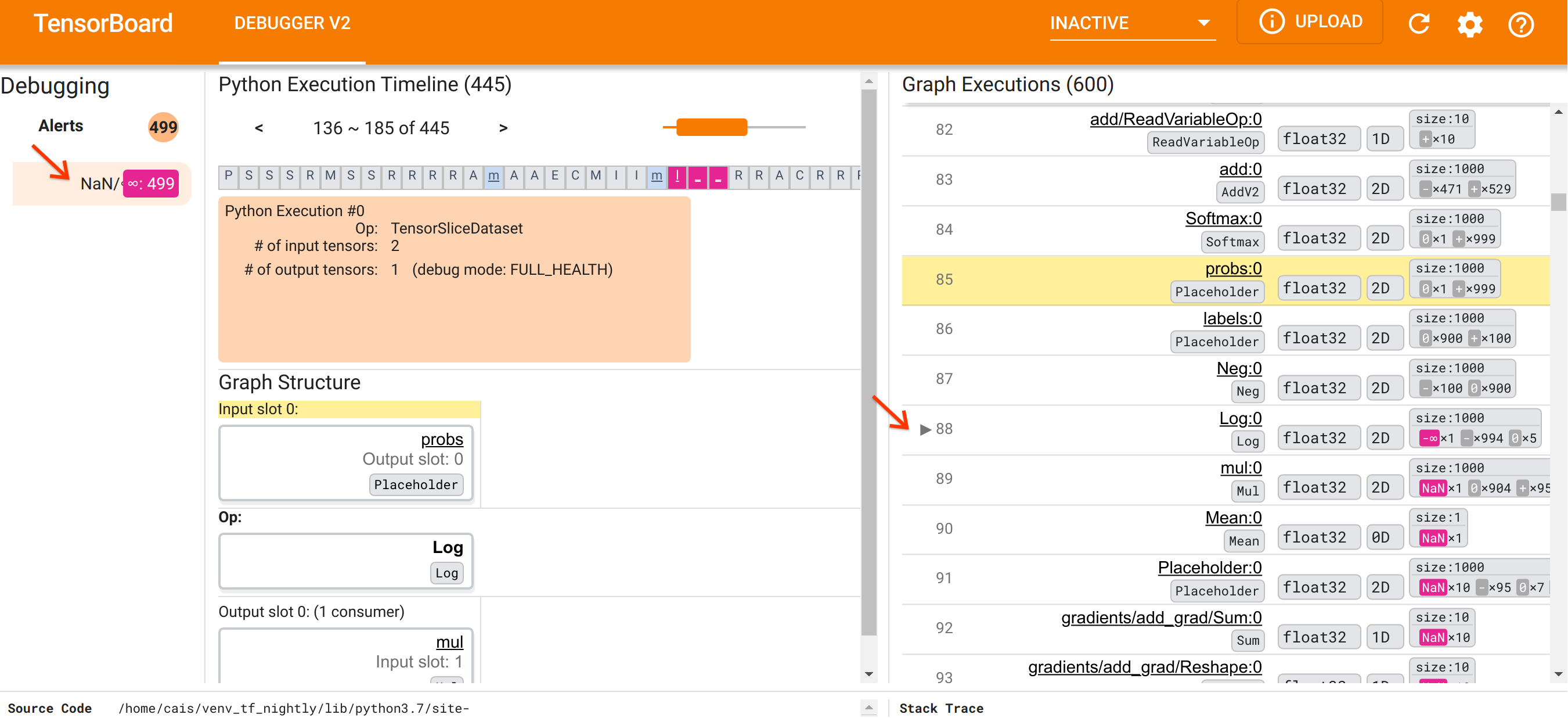
Dlaczego ten Log op wypluwa -∞? Odpowiedź na to pytanie wymaga sprawdzenia danych wejściowych do op. Kliknięcie nazwy tensora ( Log:0 ) powoduje wyświetlenie prostej, ale pouczającej wizualizacji otoczenia Log op na jego wykresie TensorFlow w sekcji Struktura wykresu. Zwróć uwagę na kierunek przepływu informacji od góry do dołu. Sama operacja jest pokazana pogrubioną czcionką pośrodku. Bezpośrednio nad nim widzimy opcję Placeholder, która stanowi jedyne wejście do operacji Log . Gdzie znajduje się tensor generowany przez ten symbol zastępczy probs na liście wykonania wykresu? Używając żółtego koloru tła jako pomocy wizualnej, możemy zobaczyć, że tensor probs:0 znajduje się trzy wiersze powyżej tensora Log:0 , czyli w wierszu 85.
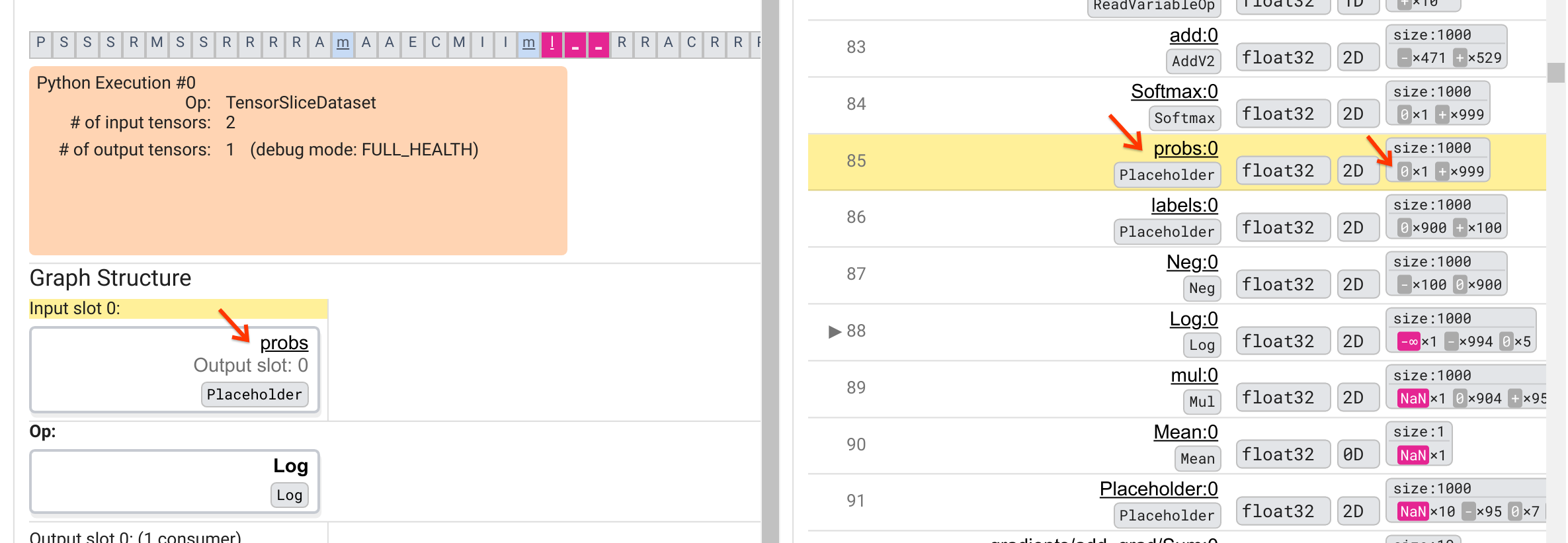
Dokładniejsze spojrzenie na numeryczny podział tensora probs:0 w wierszu 85 pokazuje, dlaczego jego konsument Log:0 generuje -∞: Spośród 1000 elementów probs:0 jeden element ma wartość 0. -∞ to wynik obliczenia logarytmu naturalnego wynoszącego 0! Jeśli uda nam się w jakiś sposób zapewnić, że operacja Log będzie wystawiona wyłącznie na pozytywne sygnały wejściowe, będziemy w stanie zapobiec wystąpieniu NaN/∞. Można to osiągnąć stosując obcinanie (np. używając tf.clip_by_value() ) na tensorze probs Placeholder.
Jesteśmy coraz bliżej rozwiązania błędu, ale to jeszcze nie koniec. Aby zastosować poprawkę, musimy wiedzieć, skąd w kodzie źródłowym Pythona pochodzi operacja Log i jej dane wejściowe zastępcze. Debugger V2 zapewnia pierwszorzędną obsługę śledzenia operacji graficznych i zdarzeń wykonawczych do ich źródła. Kiedy kliknęliśmy tensor Log:0 w wykonywaniu wykresu, sekcja Stack Trace została wypełniona oryginalnym śladem stosu utworzonym przez operację Log . Ślad stosu jest dość duży, ponieważ zawiera wiele ramek z wewnętrznego kodu TensorFlow (np. gen_math_ops.py i dumping_callback.py), które możemy bezpiecznie zignorować w przypadku większości zadań debugowania. Interesująca ramka to linia 216 debug_mnist_v2.py (tj. plik Pythona, który faktycznie próbujemy debugować). Kliknięcie „Linia 216” powoduje wyświetlenie odpowiedniego wiersza kodu w sekcji Kod źródłowy.
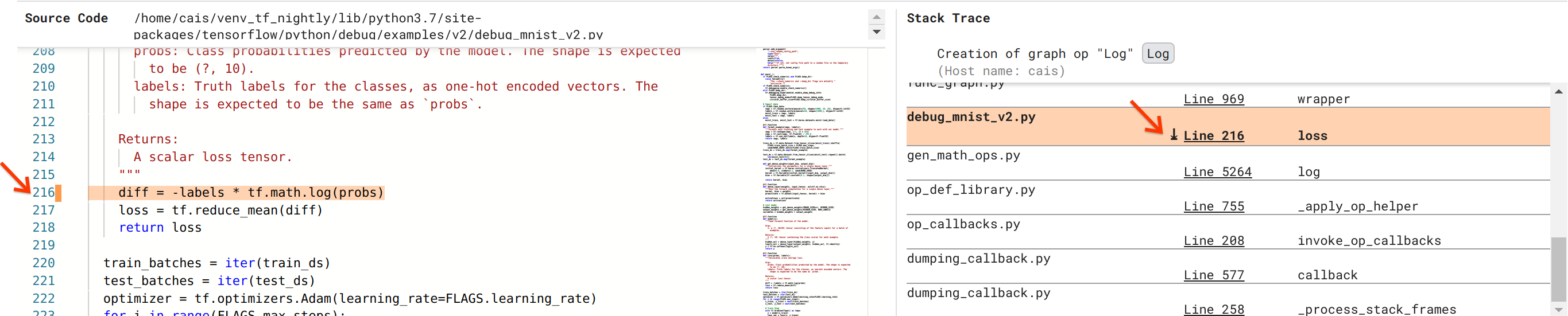
To w końcu prowadzi nas do kodu źródłowego, który utworzył problematyczną operację Log na podstawie danych wejściowych probs . To jest nasza niestandardowa funkcja kategorycznej straty entropii krzyżowej ozdobiona @tf.function , a zatem przekształcona w wykres TensorFlow. Obiekt zastępczy op probs odpowiada pierwszemu argumentowi wejściowemu funkcji straty. Operację Log tworzy się za pomocą wywołania API tf.math.log().
Poprawka polegająca na obcinaniu wartości tego błędu będzie wyglądać mniej więcej tak:
diff = -(labels *
tf.math.log(tf.clip_by_value(probs), 1e-6, 1.))
Rozwiąże to niestabilność numeryczną w tym programie TF2 i sprawi, że MLP będzie pomyślnie trenował. Innym możliwym podejściem do naprawienia niestabilności numerycznej jest użycie tf.keras.losses.CategoricalCrossentropy .
Na tym kończy się nasza podróż od zaobserwowania błędu w modelu TF2 do opracowania zmiany kodu, która naprawia błąd, przy pomocy narzędzia Debugger V2, które zapewnia pełny wgląd w historię wykonania programu TF2 i wykresu oprzyrządowanego programu TF2, w tym podsumowania numeryczne wartości tensorów i powiązań między ops, tensorami i ich oryginalnym kodem źródłowym.
Zgodność sprzętowa Debuggera V2
Debugger V2 obsługuje główny sprzęt szkoleniowy, w tym procesor i procesor graficzny. Obsługiwane jest również szkolenie z wieloma procesorami graficznymi za pomocą tf.distributed.MirroredStrategy . Wsparcie dla TPU jest wciąż na wczesnym etapie i wymaga wezwania
tf.config.set_soft_device_placement(True)
przed wywołaniem enable_dump_debug_info() . Może mieć również inne ograniczenia dotyczące TPU. Jeśli napotkasz problemy podczas korzystania z Debuggera V2, zgłoś błędy na naszej stronie problemów w GitHubie .
Zgodność API Debuggera V2
Debugger V2 jest zaimplementowany na stosunkowo niskim poziomie stosu oprogramowania TensorFlow i dlatego jest kompatybilny z tf.keras , tf.data i innymi interfejsami API zbudowanymi na niższych poziomach TensorFlow. Debugger V2 jest również wstecznie kompatybilny z TF1, chociaż oś czasu wykonania Eager będzie pusta dla katalogów debugowania generowanych przez programy TF1.
Wskazówki dotyczące korzystania z API
Często zadawanym pytaniem dotyczącym tego interfejsu API debugowania jest to, gdzie w kodzie TensorFlow należy wstawić wywołanie enable_dump_debug_info() . Zazwyczaj interfejs API powinien zostać wywołany w programie TF2 tak wcześnie, jak to możliwe, najlepiej po wierszach importu Pythona i przed rozpoczęciem tworzenia i wykonywania wykresów. Zapewni to pełne uwzględnienie wszystkich operacji i wykresów zasilających Twój model i jego szkolenie.
Obecnie obsługiwane tryby tensor_debug_mode to: NO_TENSOR , CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH i SHAPE . Różnią się ilością informacji wyodrębnionych z każdego tensora i narzutem wydajności debugowanego programu. Proszę zapoznać się z sekcją args w dokumentacji funkcji enable_dump_debug_info() .
Narzut wydajności
Interfejs API debugowania wprowadza narzut wydajności do oprzyrządowanego programu TensorFlow. Narzut różni się w zależności od tensor_debug_mode , typu sprzętu i charakteru instrumentowanego programu TensorFlow. Jako punkt odniesienia, na GPU, tryb NO_TENSOR dodaje 15% narzutu podczas uczenia modelu Transformera w partii o rozmiarze 64. Procent narzutu dla innych tensor_debug_modes jest wyższy: około 50% dla CURT_HEALTH , CONCISE_HEALTH , FULL_HEALTH i SHAPE tryby. W przypadku procesorów obciążenie jest nieco niższe. W przypadku TPU obciążenie jest obecnie wyższe.
Związek z innymi interfejsami API debugowania TensorFlow
Należy pamiętać, że TensorFlow oferuje inne narzędzia i interfejsy API do debugowania. Możesz przeglądać takie interfejsy API w przestrzeni nazw tf.debugging.* na stronie dokumentacji API. Wśród tych interfejsów API najczęściej używanym jest tf.print() . Kiedy należy używać Debuggera V2, a kiedy zamiast tego należy używać tf.print() ? tf.print() jest wygodna w przypadku, gdy
- wiemy dokładnie, które tensory wydrukować,
- wiemy, gdzie dokładnie w kodzie źródłowym umieścić instrukcje
tf.print(), - liczba takich tensorów nie jest zbyt duża.
W innych przypadkach (np. badanie wielu wartości tensora, sprawdzanie wartości tensora wygenerowanych przez wewnętrzny kod TensorFlow i wyszukiwanie źródła niestabilności numerycznej, jak pokazaliśmy powyżej), Debugger V2 zapewnia szybszy sposób debugowania. Ponadto Debugger V2 zapewnia ujednolicone podejście do sprawdzania tensorów chętnych i tensorów grafów. Dodatkowo dostarcza informacji o strukturze wykresu i lokalizacji kodu, które wykraczają poza możliwości tf.print() .
Innym interfejsem API, którego można użyć do debugowania problemów związanych z ∞ i NaN, jest tf.debugging.enable_check_numerics() . W przeciwieństwie do enable_dump_debug_info() enable_check_numerics() nie zapisuje informacji debugowania na dysku. Zamiast tego po prostu monitoruje ∞ i NaN podczas działania TensorFlow i wyświetla błędy w lokalizacji kodu źródłowego, gdy tylko jakakolwiek operacja wygeneruje tak złe wartości liczbowe. Ma niższy narzut związany z wydajnością w porównaniu do enable_dump_debug_info() , ale nie zapewnia pełnego śledzenia historii wykonywania programu i nie jest wyposażony w graficzny interfejs użytkownika, taki jak Debugger V2.