
genel bakış
TensorBoard'un ana özelliği etkileşimli GUI'sidir. Ancak, kullanıcılar bazen programlı böyle post-hoc analizler gerçekleştirerek ve günlük verilerinin, özel görselleştirme oluşturmak gibi amaçlarla TensorBoard saklanan veri günlükleri, okumak istiyorum.
2.3 destekler, bu kullanım durumunda TensorBoard tensorboard.data.experimental.ExperimentFromDev() . Bu TensorBoard en programlı erişim sağlar sayıl günlükleri . Bu sayfa, bu yeni API'nin temel kullanımını gösterir.
Kurmak
Programatik API kullanmak için, emin make install pandas yanında tensorboard .
Biz kullanacağız matplotlib ve seaborn bu kılavuzda özel araziler için, ancak analiz etmek ve görselleştirmek için tercih aracını seçebilir DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Bir şekilde TensorBoard skalarlar yükleniyor pandas.DataFrame
Bir TensorBoard LogDir TensorBoard.dev aktarıldıktan sonra, biz bir deney olarak bakın ne hale gelir. Her denemenin, denemenin TensorBoard.dev URL'sinde bulunabilecek benzersiz bir kimliği vardır. : Aşağıda verdiğimiz gösteri için, bir TensorBoard.dev deneyi kullanacak https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df bir olan pandas.DataFrame deneyinin tüm sayıl günlükleri içerir.
Sütunları DataFrame şunlardır:
-
run: Her çalıştırma tekabül orijinal LogDir bir alt için. Bu deneyde, her çalıştırma, belirli bir optimize edici türüyle (bir eğitim hiper parametresi) MNIST veri kümesindeki bir evrişimsel sinir ağının (CNN) eksiksiz bir eğitimindendir. BuDataFramefarklı iyileştirici türleri altında tekrarlanan eğitim ishal karşılık birden böyle çalışır içerir. -
tag: Bu açıklarvalueaynı satır araçlarında, metrik hangi değer satırda temsil eder. Bu deneyde, yalnızca iki eşsiz etiketlerine sahipepoch_accuracyveepoch_losssırasıyla doğruluk ve kaybı metrikleri. -
step: Bu, çalışma karşılık gelen sıranın seri düzeni yansıtan bir sayıdır. İştestepaslında dönem sayısını gösterir. Eğer ek olarak damgaları elde etmek istersenizstepdeğerlerine, anahtar kelime argüman kullanabilirsinizinclude_wall_time=Trueçağrılırkenget_scalars(). -
value: Bu ilgi, gerçek sayısal bir değerdir. Yukarıda tarif edildiği gibi, her birvalue, bu özellikleDataFramebağlı olarak, ya bir ya da kayıp bir doğruluğutagsıranın.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Özetlenmiş (geniş biçimli) bir DataFrame alma
Yaptığımız denemelerde, iki etiketleri ( epoch_loss ve epoch_accuracy ) her çalışma adımların aynı sette mevcuttur. Bu durum, bir "geniş bir form" elde edilmesini mümkün kılar DataFrame şirketinden gelen get_scalars() kullanarak pivot=True anahtar değişken. Geniş biçimli DataFrame bu da dahil bazı durumlarda çalışmak daha uygun olur DataFrame, sütunları olarak dahil tüm etiketlere sahip.
Ancak, Bütün çalışmalarda tüm etiketlere adım değerlerinin tek tip setleri sahip koşulu kullanılarak yerine getirilmediği takdirde sakının pivot=True bir hataya neden olur.
dfw = experiment.get_scalars(pivot=True)
dfw
: Yerine tek bir "değer" sütununun, geniş biçimli DataFrame açıkça onun sütun olarak iki etiket (metrik) içerdiğini Bildirimi epoch_accuracy ve epoch_loss .
DataFrame'i CSV olarak kaydetme
pandas.DataFrame ile iyi çalışabilirliği vardır CSV . Yerel bir CSV dosyası olarak saklayabilir ve daha sonra tekrar yükleyebilirsiniz. Örneğin:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Özel görselleştirme ve istatistiksel analiz gerçekleştirme
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
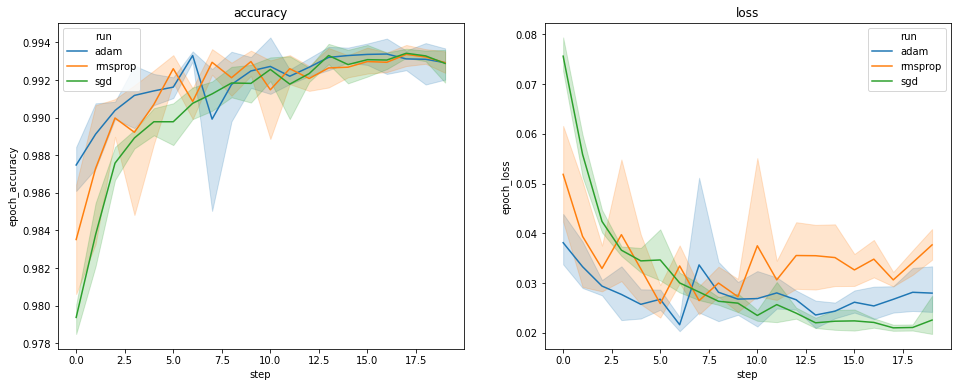
Yukarıdaki grafikler, doğrulama doğruluğu ve doğrulama kaybının zaman dilimlerini göstermektedir. Her eğri, bir optimize edici türü altındaki 5 çalıştırmanın ortalamasını gösterir. Bir dahili özelliği sayesinde seaborn.lineplot() , her biri, aynı zamanda eğri, bize bu eğrilerin değişkenlik ve üç iyileştirici türleri arasında anlamlı farklılıklar olduğunu net bir şekilde anlaması veren ortalama yaklaşık ekranların ± 1 standart sapma. Bu değişkenlik görselleştirmesi henüz TensorBoard'ın GUI'sinde desteklenmemektedir.
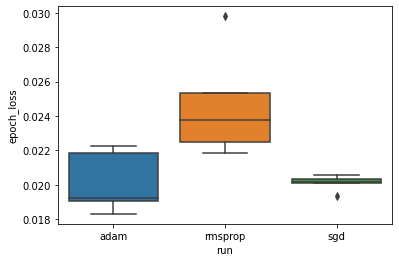
Minimum doğrulama kaybının "adam", "rmsprop" ve "sgd" optimize ediciler arasında önemli ölçüde farklılık gösterdiği hipotezini incelemek istiyoruz. Bu nedenle, optimize edicilerin her biri için minimum doğrulama kaybı için bir DataFrame çıkarıyoruz.
Ardından, minimum doğrulama kayıplarındaki farkı görselleştirmek için bir kutu grafiği yaparız.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Bu nedenle, 0,05 anlamlılık düzeyinde, analizimiz, deneyimize dahil edilen diğer iki optimize ediciye kıyasla rmsprop optimize edicide minimum doğrulama kaybının önemli ölçüde daha yüksek (yani daha kötü) olduğu hipotezimizi doğrulamaktadır.
Özet olarak, bu öğretici olarak sayıl verilere erişmek için nasıl bir örnek sağlar panda.DataFrame ler TensorBoard.dev dan. Size yapabileceğiniz esnek ve güçlü analiz ve görselleştirme tür gösterir DataFrame s.