
ภาพรวม
คุณสมบัติหลักของ TensorBoard คือ GUI แบบโต้ตอบ อย่างไรก็ตามผู้ใช้บางครั้งต้องการโปรแกรมอ่านบันทึกข้อมูลที่จัดเก็บใน TensorBoard เพื่อวัตถุประสงค์เช่นการแสดงการโพสต์-hoc การวิเคราะห์และการสร้างการสร้างภาพที่กำหนดเองของข้อมูลเข้าสู่ระบบ
TensorBoard 2.3 รองรับการใช้กรณีนี้กับ tensorboard.data.experimental.ExperimentFromDev() มันช่วยให้สามารถเข้าถึงโปรแกรมเพื่อ TensorBoard ของ บันทึกเกลา หน้านี้แสดงการใช้งานพื้นฐานของ API ใหม่นี้
ติดตั้ง
เพื่อที่จะใช้ API ของการเขียนโปรแกรมให้แน่ใจว่าคุณติดตั้ง pandas ข้าง tensorboard
เราจะใช้ matplotlib และ seaborn สำหรับการแปลงที่กำหนดเองในคู่มือนี้ แต่คุณสามารถเลือกเครื่องมือที่คุณต้องการในการวิเคราะห์และเห็นภาพ DataFrame s
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
โหลดเกลา TensorBoard เป็น pandas.DataFrame
เมื่อ logdir TensorBoard ได้รับการอัปโหลดไปยัง TensorBoard.dev มันจะกลายเป็นสิ่งที่เราเรียกว่าการทดลอง การทดสอบแต่ละรายการมีรหัสที่ไม่ซ้ำกัน ซึ่งสามารถพบได้ใน URL ของ TensorBoard.dev ของการทดสอบ สำหรับการสาธิตของเราดังต่อไปนี้เราจะใช้การทดสอบ TensorBoard.dev ที่: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df เป็น pandas.DataFrame ที่มีบันทึกเกลาทั้งหมดของการทดลอง
คอลัมน์ของ DataFrame คือ:
-
run: การทำงานในแต่ละสอดคล้องกับไดเรกทอรีย่อยของ logdir เดิม ในการทดลองนี้ การวิ่งแต่ละครั้งมาจากการฝึกอบรมที่สมบูรณ์ของ Convolutional Neural Network (CNN) บนชุดข้อมูล MNIST ด้วยประเภทเครื่องมือเพิ่มประสิทธิภาพที่กำหนด (ไฮเปอร์พารามิเตอร์การฝึกอบรม) นี้DataFrameมีวิ่งดังกล่าวหลายซึ่งสอดคล้องกับการฝึกอบรมซ้ำทำงานภายใต้ประเภทเพิ่มประสิทธิภาพที่แตกต่างกัน -
tag: นี้อธิบายว่าสิ่งที่valueในแถวเดียวกันหมายความว่านั่นคือสิ่งที่ชี้วัดความคุ้มค่าหมายในแถว ในการทดลองนี้เรามีเพียงสองแท็กไม่ซ้ำกัน:epoch_accuracyและepoch_lossเพื่อความถูกต้องและการสูญเสียตัวชี้วัดตามลำดับ -
stepนี้เป็นตัวเลขที่สะท้อนให้เห็นถึงการสั่งซื้อแบบอนุกรมของแถวที่สอดคล้องกันในการดำเนินการของ นี่คือstepจริงหมายถึงจำนวนยุค หากคุณต้องการที่จะได้รับการประทับเวลาในนอกเหนือไปจากstepค่าคุณสามารถใช้อาร์กิวเมนต์คำหลักinclude_wall_time=Trueเมื่อโทรget_scalars() -
valueนี้เป็นค่าตัวเลขที่เกิดขึ้นจริงที่น่าสนใจ ตามที่อธิบายไว้ข้างต้นแต่ละvalueในเรื่องนี้โดยเฉพาะอย่างยิ่งDataFrameเป็นทั้งความสูญเสียหรือความถูกต้องขึ้นอยู่กับtagของแถว
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
รับ DataFrame แบบหมุนได้ (แบบกว้าง)
ในการทดลองของเราสองแท็ก ( epoch_loss และ epoch_accuracy ) ที่มีอยู่ในชุดเดียวกันของขั้นตอนในการทำงานในแต่ละ นี้จะทำให้มันเป็นไปได้ที่จะได้รับ "กว้างรูปแบบ" DataFrame โดยตรงจาก get_scalars() โดยใช้ pivot=True โต้แย้งคำหลัก กว้างฟอร์ม DataFrame มีแท็กทั้งหมดได้รวมเป็นคอลัมน์ของ DataFrame ซึ่งมีความสะดวกมากขึ้นในการทำงานร่วมกับในบางกรณีรวมถึงนี้
แต่ระวังว่าถ้าสภาพของการมีชุดเครื่องแบบของค่าขั้นตอนในแท็กทั้งหมดในการทำงานทั้งหมดจะไม่ได้พบกันโดยใช้ pivot=True จะส่งผลให้เกิดข้อผิดพลาด
dfw = experiment.get_scalars(pivot=True)
dfw
ขอให้สังเกตว่าแทนที่จะเป็นคนเดียว "คุ้มค่า" คอลัมน์กว้างรูปแบบ DataFrame รวมถึงสองแท็ก (ตัวชี้วัด) เป็นคอลัมน์ของมันอย่างชัดเจน: epoch_accuracy และ epoch_loss
การบันทึก DataFrame เป็น CSV
pandas.DataFrame มีการทำงานร่วมกันที่ดีกับ CSV คุณสามารถจัดเก็บเป็นไฟล์ CSV ในเครื่องและโหลดกลับได้ในภายหลัง ตัวอย่างเช่น:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
การแสดงภาพแบบกำหนดเองและการวิเคราะห์ทางสถิติ
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
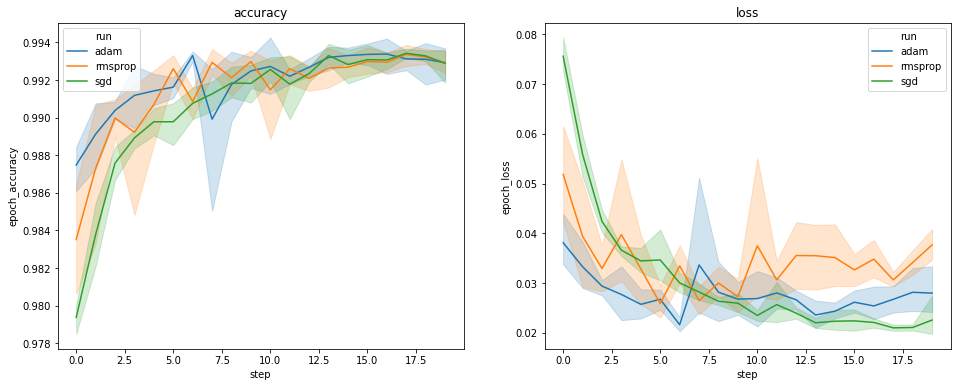
แผนภาพด้านบนแสดงระยะเวลาของความถูกต้องของการตรวจสอบความถูกต้องและความสูญเสียในการตรวจสอบ แต่ละเส้นโค้งแสดงค่าเฉลี่ยของการวิ่ง 5 ครั้งภายใต้ประเภทเครื่องมือเพิ่มประสิทธิภาพ ขอบคุณในตัวคุณสมบัติของ seaborn.lineplot() แต่ละโค้งยังแสดง± 1 ส่วนเบี่ยงเบนมาตรฐานรอบหมายถึงซึ่งทำให้เรามีความรู้สึกที่ชัดเจนของความแปรปรวนในโค้งเหล่านี้และความสำคัญของความแตกต่างระหว่างทั้งสามประเภทเพิ่มประสิทธิภาพ การแสดงความแปรปรวนนี้ยังไม่รองรับใน GUI ของ TensorBoard
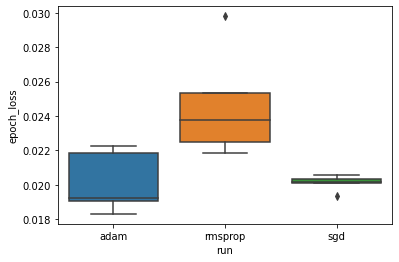
เราต้องการศึกษาสมมติฐานที่ว่าการสูญเสียการตรวจสอบขั้นต่ำแตกต่างกันอย่างมากระหว่างเครื่องมือเพิ่มประสิทธิภาพ "adam", "rmsprop" และ "sgd" ดังนั้นเราจึงแยก DataFrame สำหรับการสูญเสียการตรวจสอบขั้นต่ำภายใต้เครื่องมือเพิ่มประสิทธิภาพแต่ละตัว
จากนั้นเราก็สร้าง boxplot เพื่อให้เห็นภาพความแตกต่างของการสูญเสียการตรวจสอบขั้นต่ำ
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
ดังนั้น ที่ระดับนัยสำคัญที่ 0.05 การวิเคราะห์ของเรายืนยันสมมติฐานของเราว่าการสูญเสียการตรวจสอบขั้นต่ำนั้นสูงขึ้นอย่างมีนัยสำคัญ (กล่าวคือ แย่กว่านั้น) ในตัวเพิ่มประสิทธิภาพ rmsprop เมื่อเทียบกับเครื่องมือเพิ่มประสิทธิภาพอีกสองตัวที่รวมอยู่ในการทดสอบของเรา
โดยสรุปการกวดวิชานี้แสดงให้เห็นตัวอย่างของวิธีการที่จะเข้าถึงข้อมูลเกลาเป็น panda.DataFrame s จาก TensorBoard.dev มันแสดงให้เห็นชนิดของการวิเคราะห์ความยืดหยุ่นและมีประสิทธิภาพและการสร้างภาพที่คุณสามารถทำอะไรกับ DataFrame s