
Обзор
Главная особенность TensorBoard - интерактивный графический интерфейс. Тем не менее, пользователи иногда необходимо программно читать журналы данных , хранящиеся в TensorBoard, для таких целей, как выполнение ретроспективного анализа и создания пользовательских визуализаций данных журнала.
TensorBoard 2.3 поддерживает этот вариант использования с tensorboard.data.experimental.ExperimentFromDev() . Это позволяет программный доступ к TensorBoard в скалярных бревна . На этой странице демонстрируется базовое использование этого нового API.
Настраивать
Для того , чтобы использовать программный API, убедитесь , что вы установите pandas вместе tensorboard .
Мы будем использовать matplotlib и seaborn для пользовательских участков в данном руководстве, но вы можете выбрать нужный инструмент для анализа и визуализации DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Загрузка TensorBoard скаляры как pandas.DataFrame
После того, как TensorBoard LogDir был загружен TensorBoard.dev, он становится тем, что мы имеем в виду в качестве эксперимента. У каждого эксперимента есть уникальный идентификатор, который можно найти в URL-адресе эксперимента TensorBoard.dev. Для нашей демонстрации ниже, мы будем использовать TensorBoard.dev эксперимент по адресу: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df является pandas.DataFrame , который содержит все скалярные журналы эксперимента.
Столбцы DataFrame являются:
-
run: каждый прогон соответствует поддиректории оригинального LogDir. В этом эксперименте каждый запуск основан на полном обучении сверточной нейронной сети (CNN) на наборе данных MNIST с заданным типом оптимизатора (обучающий гиперпараметр). ЭтоDataFrameсодержит несколько таких трасс, которые соответствуют повторных прогонов обучения в различных типах оптимизатора. -
tag: это описывает то , чтоvalueв одних и тех же средствах строк, то есть, что метрика значения представляет в строке. В этом эксперименте мы имеем только две уникальные метки:epoch_accuracyиepoch_lossдля точности и потерь метрик соответственно. -
step: Это число , которое отражает последовательный порядок соответствующей строки в ее перспективе. Здесьstepна самом деле относится к числу эпохи. Если вы хотите , чтобы получить временные метки в дополнении кstepзначениям, вы можете использовать ключевой слово аргументаinclude_wall_time=Trueпри вызовеget_scalars(). -
value: Это фактическое численное значение интереса. Как описано выше, каждоеvalueв данном конкретномDataFrameявляется либо потери или точность, в зависимости отtagстроки.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Получение развернутого (широкоформатного) DataFrame
В нашем эксперименте две метки ( epoch_loss и epoch_accuracy ) присутствуют в той же последовательности шагов в каждом цикле. Это дает возможность получить «широкую-форму» DataFrame непосредственно из get_scalars() с помощью pivot=True аргумента ключевого слова. Широкая форма DataFrame имеет все тег включен в качестве столбцов DataFrame, что более удобно работать с в некоторых случаях , в том числе и этот.
Тем не менее, нужно учитывать , что если условие наличия единых наборов ступенчатых значений во всех тегах во всех опытах не выполняется, используя pivot=True приведет к ошибке.
dfw = experiment.get_scalars(pivot=True)
dfw
Обратите внимание , что вместо одного столбца «значения», широкоугольный форма DataFrame включает в себя две метки (метрики) в качестве столбцов в явном виде: epoch_accuracy и epoch_loss .
Сохранение DataFrame как CSV
pandas.DataFrame имеет хорошую совместимость с CSV . Вы можете сохранить его как локальный CSV-файл и загрузить его позже. Например:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Выполнение пользовательской визуализации и статистического анализа
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
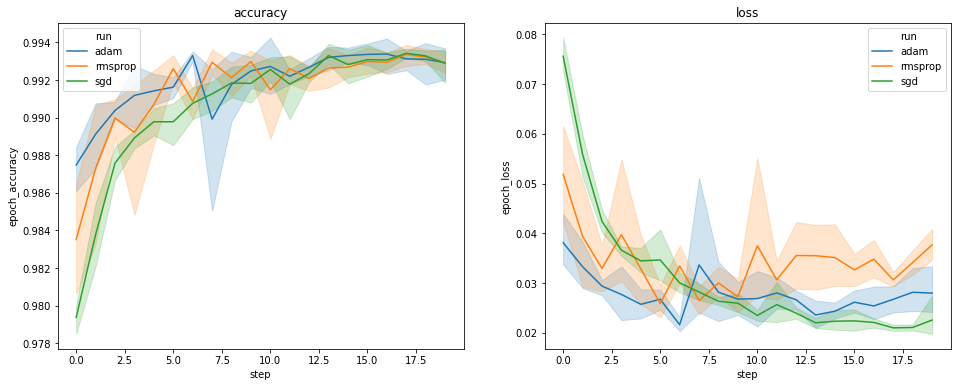
На графиках выше показаны временные рамки точности валидации и потери валидации. Каждая кривая показывает среднее значение по 5 прогонам для определенного типа оптимизатора. Благодаря встроенной в особенности seaborn.lineplot() , каждая кривая также показывает ± 1 стандартное отклонение вокруг среднего, что дает нам четкое представление о вариативности этих кривых и значимости различий между тремя типами оптимизатора. Эта визуализация изменчивости еще не поддерживается в графическом интерфейсе TensorBoard.
Мы хотим изучить гипотезу о том, что минимальные потери при проверке значительно различаются между оптимизаторами «adam», «rmsprop» и «sgd». Таким образом, мы извлекаем DataFrame для минимальной потери проверки для каждого из оптимизаторов.
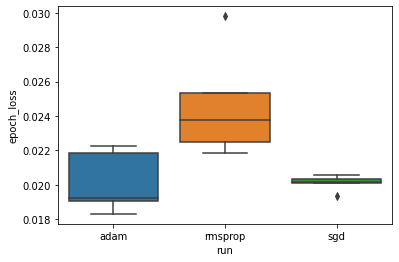
Затем мы делаем коробчатую диаграмму, чтобы визуализировать разницу в минимальных потерях при проверке.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Таким образом, при уровне значимости 0,05 наш анализ подтверждает нашу гипотезу о том, что минимальные потери при проверке значительно выше (т. Е. Хуже) в оптимизаторе среднеквадратичного отклонения по сравнению с двумя другими оптимизаторами, включенными в наш эксперимент.
Таким образом, этот учебник дает пример того , как получить доступ к скалярным данным в виде panda.DataFrame с от TensorBoard.dev. Он демонстрирует вид гибких и мощных анализа и визуализации вы можете сделать с DataFrame s.