
अवलोकन
TensorBoard की मुख्य विशेषता इसका इंटरैक्टिव GUI है। हालांकि, उपयोगकर्ताओं को कभी कभी प्रोग्राम के रूप में TensorBoard में संग्रहीत डेटा लॉग, इस तरह के पद-हॉक विश्लेषण प्रदर्शन और लॉग डेटा के लिए कस्टम दृश्यावलोकन बनाने जैसे उद्देश्यों के लिए पढ़ना चाहते हैं।
2.3 का समर्थन करता है उपयोग के इस मामले TensorBoard साथ tensorboard.data.experimental.ExperimentFromDev() यह TensorBoard के लिए कार्यक्रम संबंधी उपयोग की अनुमति देता अदिश लॉग । यह पृष्ठ इस नए एपीआई के मूल उपयोग को प्रदर्शित करता है।
सेट अप
आदेश कार्यक्रम संबंधी एपीआई का उपयोग करने के लिए, सुनिश्चित करें कि आप को स्थापित कर pandas के साथ tensorboard ।
हम इस्तेमाल करेंगे matplotlib और seaborn इस गाइड में कस्टम भूखंडों के लिए है, लेकिन आप का विश्लेषण और कल्पना करने के लिए अपनी पसंद के उपकरण चुन सकते हैं DataFrame रों।
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
एक के रूप में TensorBoard scalars लोड हो रहा है pandas.DataFrame
एक बार एक TensorBoard logdir TensorBoard.dev पर अपलोड कर दिया गया है, यह है कि हम क्या एक प्रयोग के रूप में उल्लेख हो जाता है। प्रत्येक प्रयोग की एक विशिष्ट आईडी होती है, जो प्रयोग के TensorBoard.dev URL में पाई जा सकती है। : नीचे हमारे प्रदर्शन के लिए, हम पर एक TensorBoard.dev प्रयोग का उपयोग करेगा https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df एक है pandas.DataFrame प्रयोग के सभी अदिश लॉग होता है।
के स्तंभों DataFrame हैं:
-
run: मूल logdir की कोई उप निर्देशिका के प्रत्येक रन मेल खाती है। इस प्रयोग में, प्रत्येक रन एक दिए गए ऑप्टिमाइज़र प्रकार (एक प्रशिक्षण हाइपरपैरामीटर) के साथ MNIST डेटासेट पर एक कन्वेन्शनल न्यूरल नेटवर्क (CNN) के पूर्ण प्रशिक्षण से होता है। यहDataFrameकई ऐसे रन है, जो विभिन्न प्रकार के अनुकूलक के तहत बार-बार प्रशिक्षण रन के अनुरूप होता है। -
tag: इस वर्णन करता है किvalueहै कि एक ही पंक्ति में अर्थ है, कौन-सी मीट्रिक मान पंक्ति में प्रतिनिधित्व करता है। : इस प्रयोग में, हम केवल दो अद्वितीय टैग नहीं हैepoch_accuracyऔरepoch_lossसटीकता और नुकसान मैट्रिक्स क्रमशः के लिए। -
step: यह एक संख्या है कि अपने समय में इसी पंक्ति के सीरियल आदेश को दर्शाता है। यहाँstepवास्तव में युग संख्या दर्शाता है। आप के अलावा टाइम स्टांप प्राप्त करने के लिए चाहते हैं, तोstepमान, आप खोजशब्द तर्क का उपयोग कर सकतेinclude_wall_time=Trueजब बुलाget_scalars()। -
value: इस ब्याज की वास्तविक संख्यात्मक मूल्य है। जैसा कि ऊपर वर्णित है, प्रत्येकvalueइस विशेष रूप सेDataFrameया तो एक हानि या एक सटीकता, पर निर्भर करता है हैtagपंक्ति के।
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
एक धुरी (विस्तृत रूप) डेटाफ़्रेम प्राप्त करना
हमारे प्रयोग में, दो टैग ( epoch_loss और epoch_accuracy ) प्रत्येक समय में दिए गए चरणों का एक ही सेट में मौजूद हैं। यह यह संभव एक "व्यापक रूप" प्राप्त करने के लिए बनाता है DataFrame सीधे से get_scalars() का उपयोग करके pivot=True कीवर्ड तर्क। चौड़े रूप DataFrame अपने सभी टैग DataFrame है, जो इसे मिलाकर कुछ मामलों में साथ काम करने के लिए और अधिक सुविधाजनक है के स्तंभों के रूप में शामिल है।
हालांकि, सावधान रहना है कि अगर सभी रन में सभी टैग भर में कदम मूल्यों की वर्दी सेट होने की शर्त को पूरा नहीं किया जाता है, का उपयोग कर pivot=True एक त्रुटि का परिणाम देगा।
dfw = experiment.get_scalars(pivot=True)
dfw
सूचना है कि एक एकल "मूल्य" स्तंभ के बजाय, चौड़े रूप DataFrame स्पष्ट रूप से अपने स्तंभ के रूप में दो टैग (मैट्रिक्स) शामिल हैं: epoch_accuracy और epoch_loss ।
डेटाफ़्रेम को CSV के रूप में सहेजना
pandas.DataFrame के साथ अच्छे अंतर है सीएसवी । आप इसे स्थानीय CSV फ़ाइल के रूप में संग्रहीत कर सकते हैं और बाद में इसे वापस लोड कर सकते हैं। उदाहरण के लिए:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
कस्टम विज़ुअलाइज़ेशन और सांख्यिकीय विश्लेषण करना
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
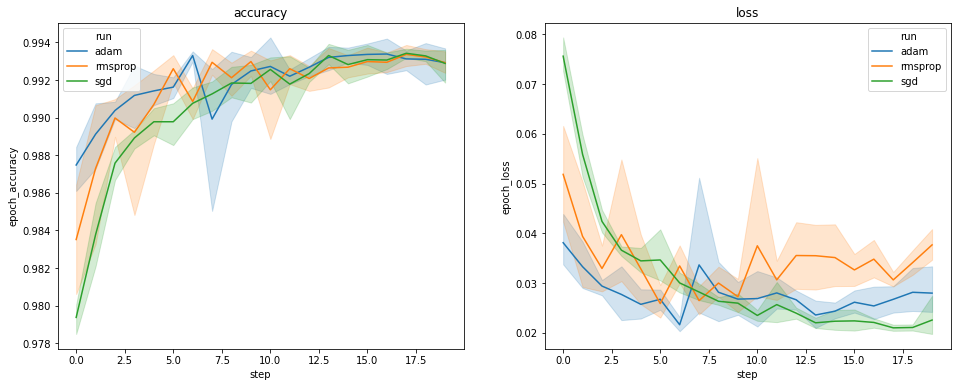
उपरोक्त भूखंड सत्यापन सटीकता और सत्यापन हानि के समय के पाठ्यक्रम दिखाते हैं। प्रत्येक वक्र एक अनुकूलक प्रकार के तहत औसत 5 रन दिखाता है। की एक अंतर्निहित सुविधा के लिए धन्यवाद seaborn.lineplot() , प्रत्येक वक्र भी मतलब के आसपास प्रदर्शित करता है ± 1 मानक विचलन है, जो हमें इन घटता में परिवर्तनशीलता और तीन अनुकूलक प्रकार के बीच मतभेद के महत्व का एक स्पष्ट भावना देता है। परिवर्तनशीलता का यह दृश्य अभी तक TensorBoard के GUI में समर्थित नहीं है।
हम इस परिकल्पना का अध्ययन करना चाहते हैं कि न्यूनतम सत्यापन हानि "एडम", "आरएमएसप्रॉप" और "एसजीडी" अनुकूलकों के बीच काफी भिन्न होती है। इसलिए हम प्रत्येक ऑप्टिमाइज़र के तहत न्यूनतम सत्यापन हानि के लिए डेटाफ़्रेम निकालते हैं।
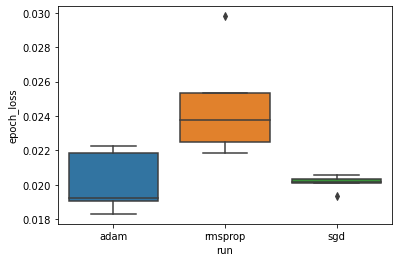
फिर हम न्यूनतम सत्यापन नुकसान में अंतर की कल्पना करने के लिए एक बॉक्सप्लॉट बनाते हैं।
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
इसलिए, 0.05 के महत्व स्तर पर, हमारा विश्लेषण हमारी परिकल्पना की पुष्टि करता है कि हमारे प्रयोग में शामिल अन्य दो ऑप्टिमाइज़र की तुलना में rmsprop ऑप्टिमाइज़र में न्यूनतम सत्यापन हानि काफी अधिक (यानी, बदतर) है।
संक्षेप में, इस ट्यूटोरियल के रूप में अदिश डेटा का उपयोग करने के लिए कैसे का एक उदाहरण देता panda.DataFrame TensorBoard.dev से रों। यह लचीला और शक्तिशाली विश्लेषण और दृश्य आप के साथ क्या कर सकते हैं की तरह दर्शाता है DataFrame रों।