
סקירה כללית
המאפיין העיקרי של TensorBoard הוא ה- GUI האינטראקטיבי שלו. עם זאת, משתמשים לפעמים רוצה לקרוא את יומני נתונים תוכניתי מאוחסן TensorBoard, למטרות כגון ביצוע פוסט-הוק ניתוחים ויצירת חזותיים מותאמים אישית של נתוני יומן.
TensorBoard 2.3 תומך מקרה השימוש הזה עם tensorboard.data.experimental.ExperimentFromDev() . זה מאפשר גישה תוכניתית של TensorBoard יומני סקלר . דף זה מדגים את השימוש הבסיסי של ה- API החדש הזה.
להכין
כדי להשתמש ב- API התכנותי, הקפד להתקין pandas לצד tensorboard .
נשתמש matplotlib ו seaborn עבור חלקות מנהג במדריך זה, אבל אתה יכול לבחור הכלי המועדף שלך כדי לנתח ולהציג DataFrame ים.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
טוען scalars TensorBoard בתור pandas.DataFrame
פעם logdir TensorBoard הועלתה TensorBoard.dev, הוא הופך להיות מה שאנחנו מכנים כניסוי. לכל ניסוי יש מזהה ייחודי, אותו ניתן למצוא בכתובת ה- TensorBoard.dev של הניסוי. להדגמה שלנו להלן, נשתמש בניסוי TensorBoard.dev ב: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df הוא pandas.DataFrame המכיל את כל יומני סקלר של הניסוי.
עמודי DataFrame הם:
-
run: כל אחד מהם מקביל ריצה בספריית משנה של logdir המקורי. בניסוי זה, כל ריצה היא מתוך אימון מלא של רשת עצבית מתפתחת (CNN) במערך הנתונים של MNIST עם סוג נתון אופטימיזציה נתון (היפרפרמטר אימון). זהDataFrameמכיל ריצות מרובות כגון, אשר מתאימות ריצות אימונים חוזרים ונשנים תחת סוגים שונים האופטימיזציה. -
tag: זה מתאר מהvalueבאותו האמצעי בשורה, כי הוא, מה מטר הערך מייצג בשורה. בניסוי זה, יש לנו רק שני תגים ייחודיים:epoch_accuracyוepoch_lossעבור מדדי הדיוק ואובדן בהתאמה. -
step: זהו מספר שמשקף את סדר סדרתי של השורה המתאימה הריצה שלה. הנהstepבעצם מתייחס למספר עידן. אם ברצונך לקבל את חותמות זמן נוסף עלstepערכים, אתה יכול להשתמש בטיעון מילתinclude_wall_time=Trueכאשר קוראיםget_scalars(). -
value: זהו הערך המספרי האמיתי של עניין. כפי שתואר לעיל, כלvalueבפרט זהDataFrameהוא או הפסד או דיוק, תלויtagשל השורה.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
קבלת DataFrame (צורה רחבה)
בניסוי שלנו, את שני התגים ( epoch_loss ו epoch_accuracy ) נוכחים באותו סט של צעדים בכל ריצה. זה מאפשר לקבל "רחב-טופס" DataFrame ישירות get_scalars() על ידי שימוש pivot=True טיעון מילות מפתח. מנהל-טופס DataFrame יש כל התגים שלה כלול עמודות של DataFrame, וזה יותר נוח לעבוד עם ובמקרים מסוימים כולל זו הנוכחית.
עם זאת, צריך להיזהר כי אם התנאי של החזקת מכשירים אחידים של ערכי צעד בכול תגיות בכול ריצות לא נפגש, באמצעות pivot=True תגרום לשגיאה.
dfw = experiment.get_scalars(pivot=True)
dfw
שים לב כי במקום טור "ערך" יחיד, DataFrame הרחב-הטופס כולל שני תגים (מדדים) כעמוד שלה במפורש: epoch_accuracy ו epoch_loss .
שמירת ה- DataFrame כ- CSV
pandas.DataFrame יש יכולת פעולה הדדית טובה עם CSV . אתה יכול לאחסן אותו כקובץ CSV מקומי ולטעון אותו מאוחר יותר. לדוגמה:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
ביצוע ויזואליזציה וניתוח סטטיסטי בהתאמה אישית
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
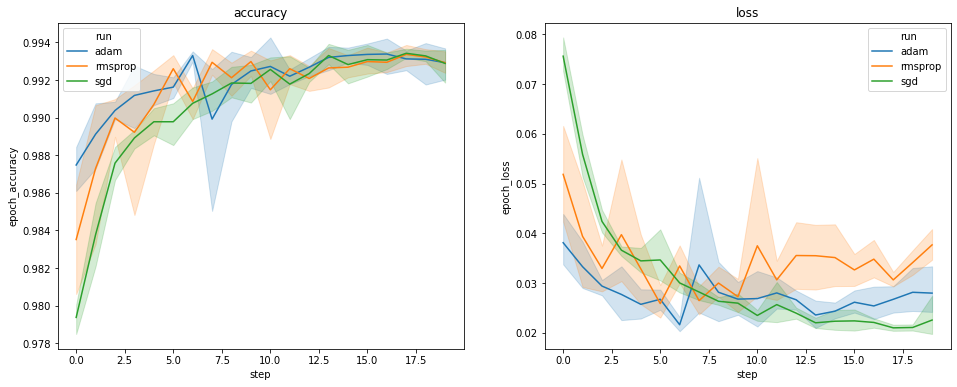
החלקות לעיל מציגות את זמני הזמן של דיוק האימות ואובדן האימות. כל עקומה מציגה את הממוצע על פני 5 ריצות תחת סוג אופטימיזציה. הודות תכונה מובנית של seaborn.lineplot() , כל עקומה גם מציג ± 1 סטיית התקן סביב הממוצע, אשר נותן לנו תחושה ברורה של השתנות עקומות אלה ואת המשמעות של ההבדלים בין סוגי האופטימיזציה שלוש. הדמיה זו של השתנות עדיין אינה נתמכת ב- GUI של TensorBoard.
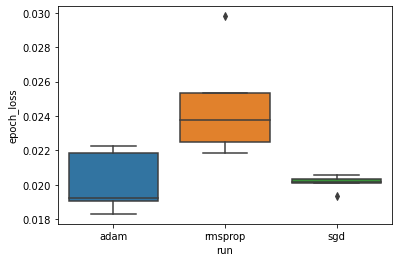
ברצוננו ללמוד את ההשערה כי אובדן האימות המינימלי שונה באופן משמעותי בין ה"אדם "," rmsprop "ו-" sgd ". אז אנו מחלצים DataFrame עבור אובדן האימות המינימלי תחת כל אחד מהאופטימיזורים.
לאחר מכן אנו מכינים קרטל לדימוי ההבדל בהפסדי האימות המינימליים.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
לכן, ברמת מובהקות של 0.05, הניתוח שלנו מאשר את השערתנו כי אובדן האימות המינימלי גבוה משמעותית (כלומר גרוע יותר) במייעל rmsprop בהשוואה לשני האופטימיזורים האחרים הכלולים בניסוי שלנו.
לסיכום, הדרכה זו מדגימה כיצד לגשת לנתונים סקלר כמו panda.DataFrame ים מ TensorBoard.dev. זה מדגים את סוג של ניתוחים גמישים ורבי עוצמה להדמיה אתה יכול לעשות עם DataFrame ים.