
Visión general
La característica principal de TensorBoard es su GUI interactiva. Sin embargo, a veces los usuarios desean leer mediante programación los registros de datos almacenados en TensorBoard, para fines tales como la realización de análisis post-hoc y la creación de visualizaciones personalizadas de los datos de registro.
TensorBoard 2.3 soportes este caso de uso con tensorboard.data.experimental.ExperimentFromDev() . Permite el acceso mediante programación a TensorBoard de registros escalares . Esta página demuestra el uso básico de esta nueva API.
Configuración
Con el fin de utilizar la API de programación, asegúrese de instalar pandas junto tensorboard .
Vamos a utilizar matplotlib y seaborn de parcelas personalizados en esta guía, pero usted puede elegir su herramienta preferida para analizar y visualizar DataFrame s.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
Cargando escalares TensorBoard como pandas.DataFrame
Una vez que un logdir TensorBoard se ha cargado en TensorBoard.dev, se convierte en lo que nos referimos como un experimento. Cada experimento tiene un ID único, que se puede encontrar en la URL de TensorBoard.dev del experimento. Para nuestra demostración a continuación, vamos a utilizar un experimento TensorBoard.dev en: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df es un pandas.DataFrame que contiene todos los registros escalares del experimento.
Las columnas de la DataFrame son:
-
run: cada ejecución corresponde a un subdirectorio del logdir originales. En este experimento, cada ejecución es de un entrenamiento completo de una red neuronal convolucional (CNN) en el conjunto de datos MNIST con un tipo de optimizador determinado (un hiperparámetro de entrenamiento). EstaDataFramecontiene múltiples tales carreras, que corresponden a las carreras de entrenamiento repetidas bajo diferentes tipos optimizador. -
tag: esto describe lo que elvaluede los mismos medios de fila, es decir, cuál es el valor de la métrica representa en la fila. En este experimento, sólo tenemos dos etiquetas únicas:epoch_accuracyyepoch_lossde la exactitud y la pérdida de métricas respectivamente. -
step: Este es un número que refleja el orden de serie de la fila correspondiente en su carrera. Aquístepen realidad se refiere a número de época. Si desea obtener las marcas de tiempo, además de losstepvalores, puede utilizar el argumento de palabra claveinclude_wall_time=Trueal llamarget_scalars(). -
value: Este es el valor numérico real de interés. Como se ha descrito anteriormente, cadavalueen este particularDataFramees o bien una pérdida o una precisión, en función de latagde la fila.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
Obtener un DataFrame pivotado (de formato ancho)
En nuestro experimento, las dos etiquetas ( epoch_loss y epoch_accuracy ) están presentes en el mismo conjunto de pasos en cada ejecución. Esto hace que sea posible obtener un "wide-forma" DataFrame directamente desde get_scalars() mediante el pivot=True argumento de palabra clave. La amplia forma de DataFrame tiene todas sus etiquetas incluyen como columnas de la trama de datos, que es más conveniente trabajar con en algunos casos, incluyendo éste.
Sin embargo, ten en cuenta que si no se cumple la condición de tener conjuntos uniformes de valores de paso a través de todas las etiquetas en todas las carreras, usando pivot=True dará lugar a un error.
dfw = experiment.get_scalars(pivot=True)
dfw
Tenga en cuenta que en lugar de una sola columna "valor", la amplia forma de trama de datos incluye las dos etiquetas (métricas) como sus columnas explícitamente: epoch_accuracy y epoch_loss .
Guardar el DataFrame como CSV
pandas.DataFrame tiene buena interoperabilidad con CSV . Puede almacenarlo como un archivo CSV local y volver a cargarlo más tarde. Por ejemplo:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
Realización de visualización personalizada y análisis estadístico
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
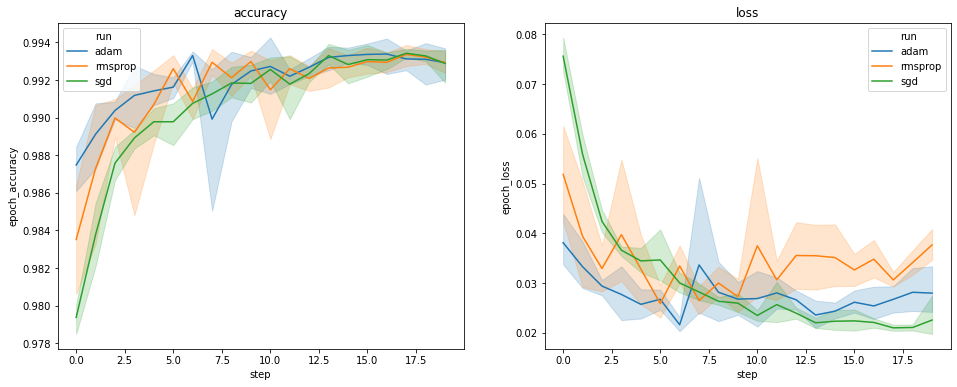
Los gráficos anteriores muestran los ciclos de tiempo de la precisión de la validación y la pérdida de validación. Cada curva muestra el promedio de 5 ejecuciones bajo un tipo de optimizador. Gracias a una característica incorporada de seaborn.lineplot() , cada curva también muestra ± 1 desviación estándar alrededor de la media, lo que nos da una idea clara de la variabilidad de estas curvas y la significación de las diferencias entre los tres tipos del optimizador. Esta visualización de variabilidad aún no es compatible con la GUI de TensorBoard.
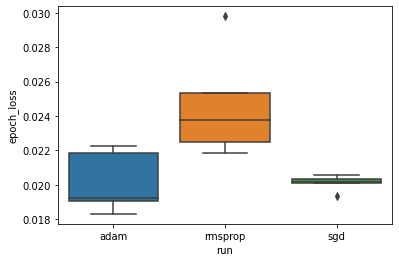
Queremos estudiar la hipótesis de que la pérdida mínima de validación difiere significativamente entre los optimizadores "adam", "rmsprop" y "sgd". Entonces extraemos un DataFrame para la pérdida mínima de validación en cada uno de los optimizadores.
Luego hacemos un diagrama de caja para visualizar la diferencia en las pérdidas mínimas de validación.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
Por lo tanto, a un nivel de significancia de 0.05, nuestro análisis confirma nuestra hipótesis de que la pérdida mínima de validación es significativamente mayor (es decir, peor) en el optimizador rmsprop en comparación con los otros dos optimizadores incluidos en nuestro experimento.
En resumen, este tutorial proporciona un ejemplo de cómo acceder a los datos escalares como panda.DataFrame s de TensorBoard.dev. Esto demuestra el tipo de análisis y visualización flexible y potente que puede hacer con la DataFrame s.