
ملخص
الميزة الرئيسية لـ TensorBoard هي واجهة المستخدم الرسومية التفاعلية. ومع ذلك، المستخدمين يريدون أحيانا لقراءة سجلات البيانات المخزنة في TensorBoard، لأغراض مثل أداء ما بعد خاص التحليلات وخلق تصورات مخصصة لبيانات السجل برمجيا.
TensorBoard 2.3 يدعم هذا الاستخدام الحال مع tensorboard.data.experimental.ExperimentFromDev() . انها تسمح بالوصول المبرمج إلى TensorBoard في سجلات العددية . توضح هذه الصفحة الاستخدام الأساسي لواجهة برمجة التطبيقات الجديدة هذه.
اقامة
من أجل استخدام API البرنامجي، تأكد من تثبيت pandas جنبا إلى جنب مع tensorboard .
سنستخدم matplotlib و seaborn لقطع مخصصة في هذا الدليل، ولكن يمكنك اختيار الأداة المفضلة لتحليل وتصور DataFrame الصورة.
pip install tensorboard pandaspip install matplotlib seaborn
from packaging import version
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
from scipy import stats
import tensorboard as tb
major_ver, minor_ver, _ = version.parse(tb.__version__).release
assert major_ver >= 2 and minor_ver >= 3, \
"This notebook requires TensorBoard 2.3 or later."
print("TensorBoard version: ", tb.__version__)
TensorBoard version: 2.3.0a20200626
تحميل سكالارس TensorBoard باعتباره pandas.DataFrame
مرة واحدة وقد تم تحميلها على logdir TensorBoard إلى TensorBoard.dev، يصبح ما نشير إليه على سبيل التجربة. تحتوي كل تجربة على معرّف فريد يمكن العثور عليه في عنوان URL الخاص بـ TensorBoard.dev للتجربة. لمظاهرة لدينا أدناه، سوف نستخدم التجربة TensorBoard.dev في: https://tensorboard.dev/experiment/c1KCv3X3QvGwaXfgX1c4tg
experiment_id = "c1KCv3X3QvGwaXfgX1c4tg"
experiment = tb.data.experimental.ExperimentFromDev(experiment_id)
df = experiment.get_scalars()
df
df هو pandas.DataFrame الذي يحتوي على كافة السجلات العددية من التجربة.
أعمدة DataFrame هي:
-
run: تشغيل كل يتوافق مع دليل فرعي من logdir الأصلي. في هذه التجربة ، يكون كل تشغيل من تدريب كامل لشبكة عصبية تلافيفية (CNN) على مجموعة بيانات MNIST بنوع مُحسِّن معين (معلمة تدريب فائقة). هذاDataFrameيحتوي على العديد من هذه أشواط، والتي تتوافق مع أشواط التدريب المتكرر تحت أنواع مختلفة محسن. -
tag: هذا يصف ماvalueفي نفس الوسائل صف واحد، وهذا هو، ما هي القيمة متري يمثل في الصف. في هذه التجربة، لدينا علامات فريدة اثنين فقط:epoch_accuracyوepoch_lossعن دقة وفقدان المقاييس على التوالي. -
step: هذا هو الرقم الذي يعكس الترتيب التسلسلي للالصف المقابل في شوطه. هناstepالواقع يشير إلى عدد الحقبة. إذا كنت ترغب في الحصول على الطوابع الزمنية بالإضافة إلىstepالقيم، يمكنك استخدام الوسيطة الكلمةinclude_wall_time=Trueعند استدعاءget_scalars(). -
value: هذه هي القيمة العددية الفعلية للاهتمام. كما هو موضح أعلاه، كلvalueفي هذا الخصوصDataFrameإما خسارة أو دقة، اعتمادا علىtagالصف.
print(df["run"].unique())
print(df["tag"].unique())
['adam,run_1/train' 'adam,run_1/validation' 'adam,run_2/train' 'adam,run_2/validation' 'adam,run_3/train' 'adam,run_3/validation' 'adam,run_4/train' 'adam,run_4/validation' 'adam,run_5/train' 'adam,run_5/validation' 'rmsprop,run_1/train' 'rmsprop,run_1/validation' 'rmsprop,run_2/train' 'rmsprop,run_2/validation' 'rmsprop,run_3/train' 'rmsprop,run_3/validation' 'rmsprop,run_4/train' 'rmsprop,run_4/validation' 'rmsprop,run_5/train' 'rmsprop,run_5/validation' 'sgd,run_1/train' 'sgd,run_1/validation' 'sgd,run_2/train' 'sgd,run_2/validation' 'sgd,run_3/train' 'sgd,run_3/validation' 'sgd,run_4/train' 'sgd,run_4/validation' 'sgd,run_5/train' 'sgd,run_5/validation'] ['epoch_accuracy' 'epoch_loss']
الحصول على إطار بيانات محوري (عريض)
في تجربتنا، والعلامات اثنين ( epoch_loss و epoch_accuracy ) موجودة في نفس مجموعة من الخطوات في كل شوط. وهذا يجعل من الممكن الحصول على "واسعة على شكل" DataFrame مباشرة من get_scalars() باستخدام pivot=True حجة الكلمة. على نطاق واسع شكل DataFrame لديه كل علامات وشملت كأعمدة من DataFrame، الذي هو أكثر ملاءمة للعمل مع في بعض الحالات بما في ذلك هذا واحد.
ومع ذلك، حذار من أنه إذا لم يتم استيفاء شرط وجود مجموعات موحدة من القيم خطوة في جميع العلامات في جميع أشواط، وذلك باستخدام pivot=True سوف يؤدي إلى خطأ.
dfw = experiment.get_scalars(pivot=True)
dfw
لاحظ أن بدلا من عمود واحد "القيمة"، وشكل واسع DataFrame تشمل العلامات اثنين (مقاييس)، وأعمدته صراحة: epoch_accuracy و epoch_loss .
حفظ DataFrame كملف CSV
pandas.DataFrame ديه قابلية التشغيل البيني جيدة مع CSV . يمكنك تخزينه كملف CSV محلي وإعادة تحميله لاحقًا. على سبيل المثال:
csv_path = '/tmp/tb_experiment_1.csv'
dfw.to_csv(csv_path, index=False)
dfw_roundtrip = pd.read_csv(csv_path)
pd.testing.assert_frame_equal(dfw_roundtrip, dfw)
أداء التصور المخصص والتحليل الإحصائي
# Filter the DataFrame to only validation data, which is what the subsequent
# analyses and visualization will be focused on.
dfw_validation = dfw[dfw.run.str.endswith("/validation")]
# Get the optimizer value for each row of the validation DataFrame.
optimizer_validation = dfw_validation.run.apply(lambda run: run.split(",")[0])
plt.figure(figsize=(16, 6))
plt.subplot(1, 2, 1)
sns.lineplot(data=dfw_validation, x="step", y="epoch_accuracy",
hue=optimizer_validation).set_title("accuracy")
plt.subplot(1, 2, 2)
sns.lineplot(data=dfw_validation, x="step", y="epoch_loss",
hue=optimizer_validation).set_title("loss")
Text(0.5, 1.0, 'loss')
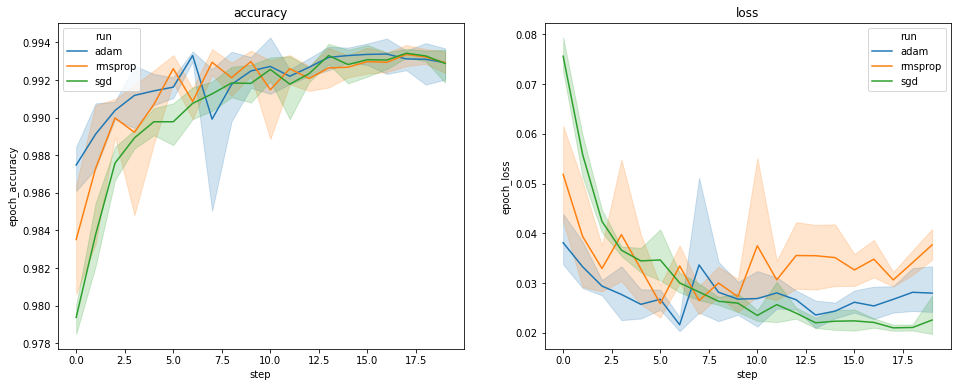
تعرض المؤامرات أعلاه الدورات الزمنية لدقة التحقق وفقدان التحقق من الصحة. يُظهر كل منحنى المتوسط عبر 5 عمليات تشغيل تحت نوع مُحسِّن. وبفضل ميزة مدمجة في ل seaborn.lineplot() ، كل منحنى كما يعرض ± 1 الانحراف المعياري حول المتوسط، مما يعطينا شعور واضح للتغير في هذه المنحنيات وأهمية الفروق بين أنواع محسن الثلاثة. لم يتم دعم تصور التباين هذا في واجهة المستخدم الرسومية لـ TensorBoard.
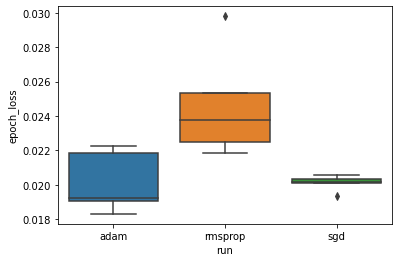
نريد دراسة الفرضية القائلة بأن الحد الأدنى من فقدان التحقق يختلف اختلافًا كبيرًا بين أدوات تحسين "adam" و "rmsprop" و "sgd". لذلك نقوم باستخراج DataFrame للحد الأدنى من فقدان التحقق من الصحة تحت كل من المُحسِنين.
ثم نقوم بعمل boxplot لتصور الفرق في الحد الأدنى من خسائر التحقق من الصحة.
adam_min_val_loss = dfw_validation.loc[optimizer_validation=="adam", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
rmsprop_min_val_loss = dfw_validation.loc[optimizer_validation=="rmsprop", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
sgd_min_val_loss = dfw_validation.loc[optimizer_validation=="sgd", :].groupby(
"run", as_index=False).agg({"epoch_loss": "min"})
min_val_loss = pd.concat([adam_min_val_loss, rmsprop_min_val_loss, sgd_min_val_loss])
sns.boxplot(data=min_val_loss, y="epoch_loss",
x=min_val_loss.run.apply(lambda run: run.split(",")[0]))
<matplotlib.axes._subplots.AxesSubplot at 0x7f5e017c8150>
# Perform pairwise comparisons between the minimum validation losses
# from the three optimizers.
_, p_adam_vs_rmsprop = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
rmsprop_min_val_loss["epoch_loss"])
_, p_adam_vs_sgd = stats.ttest_ind(
adam_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
_, p_rmsprop_vs_sgd = stats.ttest_ind(
rmsprop_min_val_loss["epoch_loss"],
sgd_min_val_loss["epoch_loss"])
print("adam vs. rmsprop: p = %.4f" % p_adam_vs_rmsprop)
print("adam vs. sgd: p = %.4f" % p_adam_vs_sgd)
print("rmsprop vs. sgd: p = %.4f" % p_rmsprop_vs_sgd)
adam vs. rmsprop: p = 0.0244 adam vs. sgd: p = 0.9749 rmsprop vs. sgd: p = 0.0135
لذلك ، عند مستوى أهمية 0.05 ، يؤكد تحليلنا فرضيتنا القائلة بأن الحد الأدنى من فقدان التحقق أعلى بكثير (أي أسوأ) في مُحسِّن rmsprop مقارنة بالمحسِنين الآخرين المتضمنين في تجربتنا.
وباختصار، يوفر هذا البرنامج التعليمي مثال عن كيفية الوصول إلى البيانات العددية كما panda.DataFrame الصورة من TensorBoard.dev. انه يوضح نوع من التحليلات مرنة وقوية والتصور يمكنك القيام به مع DataFrame الصورة.