
| | |  Kaynağı GitHub'da görüntüle Kaynağı GitHub'da görüntüle |
Bu kılavuz, iris çiçeklerini türlere göre kategorize eden bir makine öğrenimi modeli oluşturarak TensorFlow için Swift'i tanıtmaktadır. TensorFlow için Swift'i aşağıdaki amaçlarla kullanır:
- Bir model oluşturun,
- Bu modeli örnek veriler üzerinde eğitin ve
- Bilinmeyen veriler hakkında tahminlerde bulunmak için modeli kullanın.
TensorFlow programlama
Bu kılavuz, TensorFlow konseptleri için şu üst düzey Swift'i kullanır:
- Epochs API ile verileri içe aktarın.
- Swift soyutlamalarını kullanarak modeller oluşturun.
- Saf Swift kitaplıkları mevcut olmadığında Swift'in Python birlikte çalışabilirliğini kullanarak Python kitaplıklarını kullanın.
Bu eğitim birçok TensorFlow programı gibi yapılandırılmıştır:
- Veri kümelerini içe aktarın ve ayrıştırın.
- Modelin türünü seçin.
- Modeli eğitin.
- Modelin etkinliğini değerlendirin.
- Tahminlerde bulunmak için eğitilmiş modeli kullanın.
Kurulum programı
İçe aktarmaları yapılandırma
TensorFlow'u ve bazı yararlı Python modüllerini içe aktarın.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
İris sınıflandırma problemi
Bulduğunuz her iris çiçeğini sınıflandırmanın otomatik bir yolunu arayan bir botanikçi olduğunuzu hayal edin. Makine öğrenimi, çiçekleri istatistiksel olarak sınıflandırmak için birçok algoritma sağlar. Örneğin, karmaşık bir makine öğrenimi programı, çiçekleri fotoğraflara göre sınıflandırabilir. Hedeflerimiz daha mütevazı; iris çiçeklerini, çanak yaprakları ve taç yapraklarının uzunluk ve genişlik ölçümlerine göre sınıflandıracağız.
İris cinsi yaklaşık 300 tür içerir, ancak programımız yalnızca aşağıdaki üçünü sınıflandıracaktır:
- İris setosa
- iris virginica
- Çok renkli iris
 |
| Şekil 1. Iris setosa ( Radomil , CC BY-SA 3.0), Iris versicolor , ( Dlanglois , CC BY-SA 3.0) ve Iris virginica ( Frank Mayfield , CC BY-SA 2.0). |
Neyse ki birileri sepal ve petal ölçümleriyle birlikte 120 iris çiçeğinden oluşan bir veri seti oluşturdu. Bu, başlangıç seviyesindeki makine öğrenimi sınıflandırma problemleri için popüler olan klasik bir veri kümesidir.
Eğitim veri kümesini içe aktarın ve ayrıştırın
Veri kümesi dosyasını indirin ve bu Swift programının kullanabileceği bir yapıya dönüştürün.
Veri kümesini indirin
Eğitim veri kümesi dosyasını http://download.tensorflow.org/data/iris_training.csv adresinden indirin.
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Verileri inceleyin
Bu veri kümesi, iris_training.csv , virgülle ayrılmış değerler (CSV) olarak biçimlendirilmiş tablo verilerini depolayan düz bir metin dosyasıdır. İlk 5 girişe bakalım.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
Veri kümesinin bu görünümünden aşağıdakilere dikkat edin:
- İlk satır, veri kümesiyle ilgili bilgileri içeren bir başlıktır:
- Toplam 120 örnek var. Her örnekte dört özellik ve üç olası etiket adından biri bulunur.
- Sonraki satırlar, her satıra bir örnek olacak şekilde veri kayıtlarıdır; burada:
- İlk dört alan özelliklerdir : bunlar bir örneğin özellikleridir. Burada alanlar çiçek ölçümlerini temsil eden kayan sayıları tutar.
- Son sütun etikettir : tahmin etmek istediğimiz değer budur. Bu veri kümesi için çiçek adına karşılık gelen 0, 1 veya 2 tamsayı değeridir.
Bunu kodla yazalım:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Her etiket dize adıyla ilişkilendirilir (örneğin, "setosa"), ancak makine öğrenimi genellikle sayısal değerlere dayanır. Etiket numaraları aşağıdaki gibi adlandırılmış bir gösterimle eşlenir:
-
0: İris setosa -
1: Çok renkli iris -
2: İris virginica
Özellikler ve etiketler hakkında daha fazla bilgi için Makine Öğrenimi Hızlandırılmış Kursu'nun ML Terminolojisi bölümüne bakın.
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Epochs API'sini kullanarak veri kümesi oluşturma
TensorFlow'un Epochs API'si için Swift, verileri okumak ve bunları eğitim için kullanılan bir forma dönüştürmek için kullanılan üst düzey bir API'dir.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
İndirdiğimiz veri setleri CSV formatında olduğundan IrisBatch nesnelerinin listesi halinde veriyi yükleyecek bir fonksiyon yazalım.
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Artık eğitim veri kümesini yüklemek ve bir TrainingEpochs nesnesi oluşturmak için CSV yükleme işlevini kullanabiliriz
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
TrainingEpochs nesnesi sonsuz bir çağ dizisidir. Her çağ IrisBatch es'i içerir. İlk çağın ilk unsuruna bakalım.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
İlk batchSize örneklerine ilişkin özelliklerin, firstTrainFeatures içinde birlikte gruplandırıldığına (veya toplu olarak ) ve ilk batchSize örneklerine ilişkin etiketlerin, firstTrainLabels içinde toplu olarak oluşturulduğuna dikkat edin.
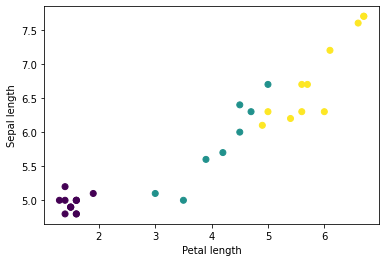
Python'un matplotlib'ini kullanarak gruptan birkaç özelliğin grafiğini çizerek bazı kümeleri görmeye başlayabilirsiniz:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
Model türünü seçin
Neden modeli?
Model, özellikler ile etiket arasındaki ilişkidir. İris sınıflandırma problemi için model, sepal ve petal ölçümleri ile tahmin edilen iris türleri arasındaki ilişkiyi tanımlar. Bazı basit modeller birkaç satırlık cebirle açıklanabilir, ancak karmaşık makine öğrenimi modelleri özetlemesi zor olan çok sayıda parametreye sahiptir.
Makine öğrenimini kullanmadan dört özellik ile iris türü arasındaki ilişkiyi belirleyebilir misiniz? Yani, bir model oluşturmak için geleneksel programlama tekniklerini (örneğin, birçok koşullu ifade) kullanabilir misiniz? Belki de veri setini, belirli bir türün petal ve sepal ölçümleri arasındaki ilişkileri belirleyecek kadar uzun süre analiz ettiyseniz. Ve bu, daha karmaşık veri kümelerinde zor, hatta imkansız hale geliyor. İyi bir makine öğrenimi yaklaşımı sizin için modeli belirler . Doğru makine öğrenimi model türüne yeterince temsili örnek verirseniz program sizin için ilişkileri çözecektir.
Modeli seçin
Eğitilecek model türünü seçmemiz gerekiyor. Pek çok model türü vardır ve iyi bir model seçmek tecrübe gerektirir. Bu eğitimde iris sınıflandırma problemini çözmek için bir sinir ağı kullanılıyor. Sinir ağları, özellikler ve etiket arasındaki karmaşık ilişkileri bulabilir. Bir veya daha fazla gizli katman halinde düzenlenmiş, yüksek düzeyde yapılandırılmış bir grafiktir. Her gizli katman bir veya daha fazla nörondan oluşur. Sinir ağlarının çeşitli kategorileri vardır ve bu program yoğun veya tam bağlantılı bir sinir ağı kullanır: bir katmandaki nöronlar, önceki katmandaki her nörondan girdi bağlantıları alır. Örneğin, Şekil 2'de bir giriş katmanı, iki gizli katman ve bir çıkış katmanından oluşan yoğun bir sinir ağı gösterilmektedir:
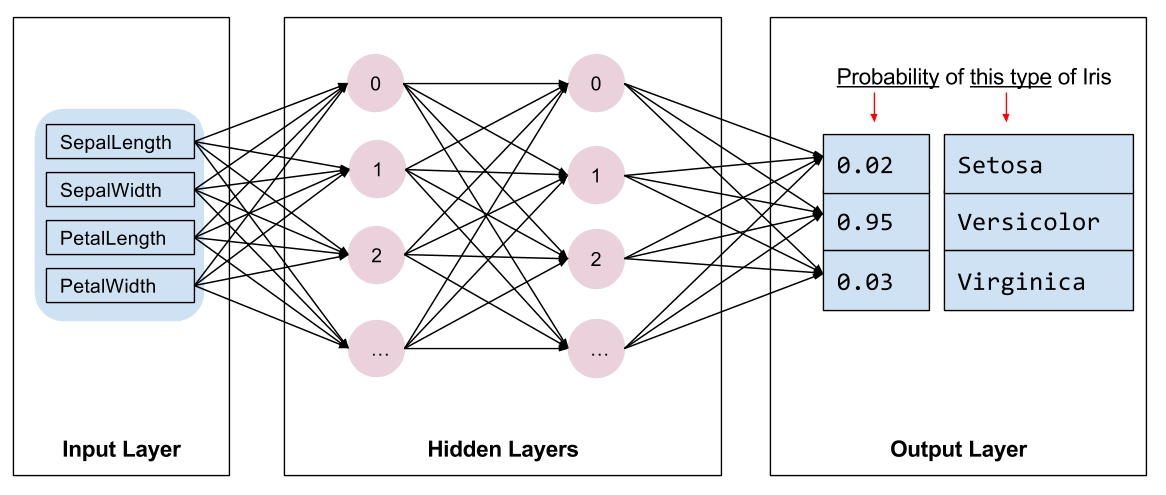 |
| Şekil 2. Özellikleri, gizli katmanları ve tahminleri olan bir sinir ağı. |
Şekil 2'deki model eğitilip etiketlenmemiş bir örnekle beslendiğinde üç tahmin sağlar: Bu çiçeğin verilen iris türü olma olasılığı. Bu tahmine çıkarım denir. Bu örnekte çıktı tahminlerinin toplamı 1,0'dır. Şekil 2'de bu tahmin şu şekilde ayrılıyor: Iris setosa için 0.02 , Iris versicolor için 0.95 ve Iris virginica için 0.03 . Bu, modelin etiketlenmemiş bir örnek çiçeğin Iris versicolor olduğunu %95 olasılıkla tahmin ettiği anlamına gelir.
TensorFlow Derin Öğrenme Kitaplığı için Swift'i kullanarak bir model oluşturun
Swift for TensorFlow Derin Öğrenme Kitaplığı, bunları bir araya getirmek için ilkel katmanları ve kuralları tanımlar; bu da model oluşturmayı ve deneme yapmayı kolaylaştırır.
Model, Layer ile uyumlu bir struct ; bu, giriş Tensor çıkış Tensor eşleştiren bir callAsFunction(_:) yöntemini tanımladığı anlamına gelir. callAsFunction(_:) yöntemi genellikle girişi alt katmanlar aracılığıyla basitçe sıralar. Girişi üç Dense alt katman aracılığıyla sıralayan bir IrisModel tanımlayalım.
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
Aktivasyon fonksiyonu katmandaki her düğümün çıktı şeklini belirler. Bu doğrusal olmama durumları önemlidir; bunlar olmadan model tek bir katmana eşdeğer olacaktır. Çok sayıda aktivasyon mevcuttur ancak ReLU, gizli katmanlar için ortaktır.
İdeal gizli katman ve nöron sayısı soruna ve veri kümesine bağlıdır. Makine öğreniminin birçok yönü gibi, sinir ağının en iyi şeklini seçmek de bilgi ve denemenin bir karışımını gerektirir. Genel bir kural olarak, gizli katmanların ve nöronların sayısını artırmak genellikle daha güçlü bir model oluşturur ve bu da etkili bir şekilde eğitim için daha fazla veri gerektirir.
Modeli kullanma
Bu modelin bir dizi özelliğe neler yaptığına hızlıca bir göz atalım:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Burada her örnek, her sınıf için bir logit döndürür.
Bu logitleri her sınıf için bir olasılığa dönüştürmek için softmax işlevini kullanın:
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
argmax sınıflar arasında almak bize tahmin edilen sınıf indeksini verir. Ancak model henüz eğitilmediğinden bunlar iyi tahminler değil.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Modeli eğitin
Eğitim, modelin kademeli olarak optimize edildiği veya modelin veri kümesini öğrendiği makine öğreniminin aşamasıdır. Amaç, görünmeyen veriler hakkında tahminler yapmak için eğitim veri kümesinin yapısı hakkında yeterince bilgi edinmektir. Eğitim veri kümesi hakkında çok fazla şey öğrenirseniz tahminler yalnızca gördüğü veriler için işe yarar ve genelleştirilemez. Bu soruna aşırı uyum denir; bu, bir sorunun nasıl çözüleceğini anlamak yerine cevapları ezberlemek gibidir.
İris sınıflandırma problemi denetimli makine öğreniminin bir örneğidir: model, etiket içeren örneklerden eğitilir. Denetimsiz makine öğreniminde örnekler etiket içermez. Bunun yerine model genellikle özellikler arasında kalıplar bulur.
Bir kayıp fonksiyonu seçin
Hem eğitim hem de değerlendirme aşamalarında modelin kaybını hesaplamak gerekir. Bu, bir modelin tahminlerinin istenen etiketten ne kadar saptığını, başka bir deyişle modelin ne kadar kötü performans gösterdiğini ölçer. Bu değeri en aza indirmek veya optimize etmek istiyoruz.
Modelimiz, modelin sınıf olasılık tahminlerini ve istenilen etiketi alan ve örnekler genelinde ortalama kaybı döndüren softmaxCrossEntropy(logits:labels:) fonksiyonunu kullanarak kaybını hesaplayacaktır.
Mevcut eğitimsiz modelin kaybını hesaplayalım:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Bir optimize edici oluşturun
Bir optimize edici, loss fonksiyonunu en aza indirmek için hesaplanan gradyanları modelin değişkenlerine uygular. Kayıp fonksiyonunu eğri bir yüzey olarak düşünebilirsiniz (bkz. Şekil 3) ve etrafta dolaşarak en düşük noktasını bulmak istiyoruz. Eğimler en dik yükseliş yönünü gösteriyor; bu yüzden ters yönde ilerleyip tepeden aşağı doğru ilerleyeceğiz. Her parti için kaybı ve eğimi yinelemeli olarak hesaplayarak modeli eğitim sırasında ayarlayacağız. Yavaş yavaş model, kaybı en aza indirmek için en iyi ağırlık ve sapma kombinasyonunu bulacaktır. Kayıp ne kadar düşük olursa modelin tahminleri de o kadar iyi olur.
 |
| Şekil 3. 3B alanda zaman içinde görselleştirilen optimizasyon algoritmaları. (Kaynak: Stanford sınıfı CS231n , MIT Lisansı, Resim kredisi: Alec Radford ) |
Swift for TensorFlow, eğitim için birçok optimizasyon algoritmasına sahiptir. Bu model , stokastik gradyan iniş (SGD) algoritmasını uygulayan SGD optimize ediciyi kullanır. learningRate yokuş aşağı her yineleme için atılacak adım boyutunu ayarlar. Bu, daha iyi sonuçlar elde etmek için genellikle ayarlayacağınız bir hiper parametredir .
let optimizer = SGD(for: model, learningRate: 0.01)
Tek bir degrade iniş adımı atmak için optimizer kullanalım. İlk olarak modele göre kaybın eğimini hesaplıyoruz:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
Daha sonra, az önce hesapladığımız gradyanı, modelin türevlenebilir değişkenlerini buna göre güncelleyen optimize ediciye iletiyoruz:
optimizer.update(&model, along: grads)
Kaybı tekrar hesaplarsak daha küçük olması gerekir çünkü gradyan iniş adımları (genellikle) kaybı azaltır:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Eğitim döngüsü
Tüm parçalar yerine oturduğunda model eğitime hazır! Bir eğitim döngüsü, daha iyi tahminler yapmasına yardımcı olmak için veri kümesi örneklerini modele besler. Aşağıdaki kod bloğu bu eğitim adımlarını ayarlar:
- Her çağda yineleyin. Bir dönem, veri kümesindeki bir geçiştir.
- Bir dönem içinde, eğitim dönemindeki her partiyi yineleyin
- Grubu harmanlayın ve özelliklerini (
x) ve etiketini (y) alın. - Harmanlanan grubun özelliklerini kullanarak bir tahmin yapın ve bunu etiketle karşılaştırın. Tahminin yanlışlığını ölçün ve bunu modelin kaybını ve gradyanlarını hesaplamak için kullanın.
- Modelin değişkenlerini güncellemek için degrade inişini kullanın.
- Görselleştirme için bazı istatistikleri takip edin.
- Her dönem için tekrarlayın.
epochCount değişkeni, veri kümesi koleksiyonu üzerinde döngü sayısıdır. Sezgilerin aksine, bir modeli daha uzun süre eğitmek daha iyi bir model garanti etmez. epochCount , ayarlayabileceğiniz bir hiperparametredir . Doğru numarayı seçmek genellikle hem deneyim hem de deneme gerektirir.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
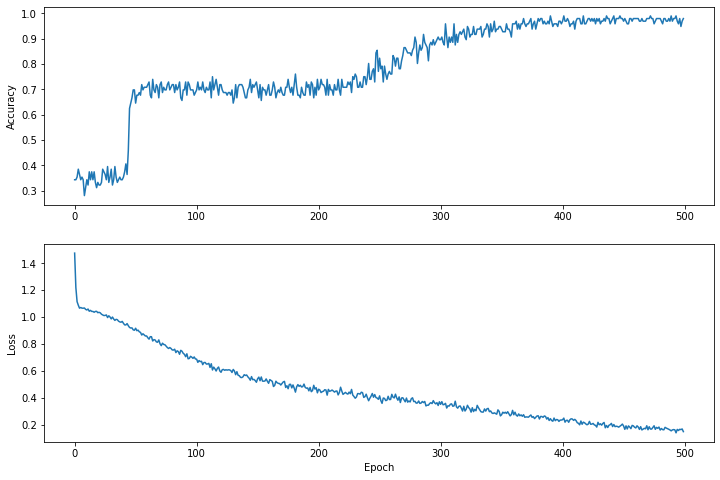
Zaman içindeki kayıp fonksiyonunu görselleştirin
Modelin eğitim ilerlemesini yazdırmak yararlı olsa da, bu ilerlemeyi görmek genellikle daha yararlı olur. Python'un matplotlib modülünü kullanarak temel grafikler oluşturabiliriz.
Bu grafikleri yorumlamak biraz deneyim gerektirir, ancak gerçekten kaybın azaldığını ve doğruluğun arttığını görmek istiyorsunuz.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
Grafiklerin y eksenlerinin sıfır tabanlı olmadığını unutmayın.
Modelin etkililiğini değerlendirin
Artık model eğitildiğine göre performansına ilişkin bazı istatistikler alabiliriz.
Değerlendirme, modelin ne kadar etkili tahminlerde bulunduğunu belirlemek anlamına gelir. Modelin iris sınıflandırmasındaki etkinliğini belirlemek için, bazı sepal ve petal ölçümlerini modele aktarın ve modelden hangi iris türlerini temsil ettiklerini tahmin etmesini isteyin. Daha sonra modelin öngörüsünü gerçek etiketle karşılaştırın. Örneğin, girdi örneklerinin yarısında doğru türü seçen bir modelin doğruluğu 0.5 . Şekil 4, 5 tahminden 4'ünün %80 doğrulukla doğru çıktığı, biraz daha etkili bir modeli göstermektedir:
| Örnek özellikler | Etiket | Model tahmini | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Şekil 4. %80 doğruluğa sahip bir iris sınıflandırıcı. | |||||
Test veri kümesini kurun
Modelin değerlendirilmesi modelin eğitilmesine benzer. En büyük fark, örneklerin eğitim seti yerine ayrı bir test setinden gelmesidir. Bir modelin etkinliğini adil bir şekilde değerlendirmek için, bir modeli değerlendirmek için kullanılan örneklerin, modeli eğitmek için kullanılan örneklerden farklı olması gerekir.
Test veri kümesinin kurulumu, eğitim veri kümesinin kurulumuna benzer. Test setini http://download.tensorflow.org/data/iris_test.csv adresinden indirin:
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Şimdi onu bir IrisBatch es dizisine yükleyin:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Test veri kümesindeki modeli değerlendirin
Eğitim aşamasından farklı olarak model, test verilerinin yalnızca tek bir dönemini değerlendirir. Aşağıdaki kod hücresinde, test kümesindeki her örnek üzerinde yineliyoruz ve modelin öngörüsünü gerçek etiketle karşılaştırıyoruz. Bu, tüm test seti boyunca modelin doğruluğunu ölçmek için kullanılır.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
İlk partide örneğin modelin genellikle doğru olduğunu görebiliriz:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Tahminlerde bulunmak için eğitilmiş modeli kullanma
Bir model eğittik ve bunun iris türlerini sınıflandırmada iyi ama mükemmel olmadığını gösterdik. Şimdi etiketlenmemiş örnekler üzerinde bazı tahminler yapmak için eğitilmiş modeli kullanalım; yani, özellikler içeren ancak etiket içermeyen örneklerde.
Gerçek hayatta etiketlenmemiş örnekler; uygulamalar, CSV dosyaları ve veri akışları dahil olmak üzere birçok farklı kaynaktan gelebilir. Şimdilik, etiketlerini tahmin etmek için üç etiketlenmemiş örneği manuel olarak sunacağız. Hatırlayın, etiket numaraları adlandırılmış bir gösterimle şu şekilde eşlenir:
-
0: İris setosa -
1: Çok renkli iris -
2: İris virginica
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])