
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub |
คู่มือนี้จะแนะนำ Swift สำหรับ TensorFlow โดยการสร้างโมเดลการเรียนรู้ของเครื่องที่จัดหมวดหมู่ดอกไอริสตามสายพันธุ์ ใช้ Swift สำหรับ TensorFlow เพื่อ:
- สร้างแบบจำลอง
- ฝึกโมเดลนี้กับข้อมูลตัวอย่าง และ
- ใช้แบบจำลองเพื่อคาดการณ์เกี่ยวกับข้อมูลที่ไม่รู้จัก
การเขียนโปรแกรมเทนเซอร์โฟลว์
คู่มือนี้ใช้แนวคิด Swift สำหรับ TensorFlow ระดับสูงเหล่านี้:
- นำเข้าข้อมูลด้วย Epochs API
- สร้างโมเดลโดยใช้ Swift abstractions
- ใช้ไลบรารี Python โดยใช้การทำงานร่วมกันของ Python ของ Swift เมื่อไม่มีไลบรารี Swift ที่แท้จริง
บทช่วยสอนนี้มีโครงสร้างเหมือนกับโปรแกรม TensorFlow หลายโปรแกรม:
- นำเข้าและแยกวิเคราะห์ชุดข้อมูล
- เลือกประเภทของรุ่น
- ฝึกโมเดล
- ประเมินประสิทธิภาพของแบบจำลอง
- ใช้แบบจำลองที่ผ่านการฝึกอบรมเพื่อคาดการณ์
โปรแกรมติดตั้ง
กำหนดค่าการนำเข้า
นำเข้า TensorFlow และโมดูล Python ที่มีประโยชน์
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
ปัญหาการจำแนกม่านตา
ลองนึกภาพคุณเป็นนักพฤกษศาสตร์ที่กำลังมองหาวิธีอัตโนมัติในการจัดหมวดหมู่ดอกไอริสแต่ละดอกที่คุณพบ การเรียนรู้ของเครื่องมีอัลกอริธึมมากมายในการจำแนกดอกไม้ตามสถิติ ตัวอย่างเช่น โปรแกรมแมชชีนเลิร์นนิงที่ซับซ้อนสามารถจำแนกดอกไม้ตามรูปถ่ายได้ ความทะเยอทะยานของเรานั้นเรียบง่ายยิ่งขึ้น—เราจะจำแนกดอกไอริสตามการวัดความยาวและความกว้างของ กลีบเลี้ยง และ กลีบดอก
สกุลไอริสมีประมาณ 300 สปีชีส์ แต่โปรแกรมของเราจะจำแนกประเภทเพียง 3 ชนิดต่อไปนี้:
- ไอริส เซโตซา
- ไอริส เวอร์จิกา
- ไอริส เวอร์ซิคัลเลอร์
 |
| รูปที่ 1 Iris setosa (โดย Radomil , CC BY-SA 3.0), Iris versicolor , (โดย Dlanglois , CC BY-SA 3.0) และ Iris virginica (โดย Frank Mayfield , CC BY-SA 2.0) |
โชคดีที่มีคนสร้าง ชุดข้อมูลดอกไอริส 120 ดอก พร้อมการวัดกลีบเลี้ยงและกลีบดอกไว้แล้ว นี่คือชุดข้อมูลแบบคลาสสิกซึ่งเป็นที่นิยมสำหรับปัญหาการจำแนกประเภท Machine Learning ระดับเริ่มต้น
นำเข้าและแยกวิเคราะห์ชุดข้อมูลการฝึกอบรม
ดาวน์โหลดไฟล์ชุดข้อมูลและแปลงเป็นโครงสร้างที่โปรแกรม Swift นี้สามารถใช้ได้
ดาวน์โหลดชุดข้อมูล
ดาวน์โหลดไฟล์ชุดข้อมูลการฝึกอบรมจาก http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
ตรวจสอบข้อมูล
ชุดข้อมูล iris_training.csv นี้ เป็นไฟล์ข้อความธรรมดาที่จัดเก็บข้อมูลแบบตารางที่จัดรูปแบบเป็นค่าที่คั่นด้วยเครื่องหมายจุลภาค (CSV) มาดู 5 รายการแรกกัน
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
จากมุมมองของชุดข้อมูลนี้ ให้สังเกตสิ่งต่อไปนี้:
- บรรทัดแรกคือส่วนหัวที่มีข้อมูลเกี่ยวกับชุดข้อมูล:
- มีทั้งหมด 120 ตัวอย่าง แต่ละตัวอย่างมีคุณลักษณะสี่ประการและหนึ่งในสามชื่อป้ายกำกับที่เป็นไปได้
- แถวต่อมาคือบันทึกข้อมูล หนึ่ง ตัวอย่าง ต่อบรรทัด โดยที่:
มาเขียนมันออกมาเป็นโค้ด:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
แต่ละป้ายกำกับเชื่อมโยงกับชื่อสตริง (เช่น "setosa") แต่โดยทั่วไปแล้วการเรียนรู้ของเครื่องจะขึ้นอยู่กับค่าตัวเลข หมายเลขป้ายกำกับจะถูกแมปกับการแสดงชื่อ เช่น:
-
0: ไอริส เซโตซ่า -
1: ไอริส เวอร์ซิคัลเลอร์ -
2: ไอริส เวอร์จิกา
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับคุณสมบัติและป้ายกำกับ โปรดดู ส่วนคำศัพท์ ML ของ Machine Learning Crash Course
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
สร้างชุดข้อมูลโดยใช้ Epochs API
Epochs API ของ Swift สำหรับ TensorFlow เป็น API ระดับสูงสำหรับการอ่านข้อมูลและแปลงเป็นรูปแบบที่ใช้สำหรับการฝึกอบรม
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
เนื่องจากชุดข้อมูลที่เราดาวน์โหลดอยู่ในรูปแบบ CSV มาเขียนฟังก์ชันเพื่อโหลดข้อมูลเป็นรายการของออบเจ็กต์ IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
ตอนนี้เราสามารถใช้ฟังก์ชันการโหลด CSV เพื่อโหลดชุดข้อมูลการฝึกอบรมและสร้างออบเจ็กต์ TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
ออบเจ็กต์ TrainingEpochs เป็นลำดับของยุคที่ไม่มีที่สิ้นสุด แต่ละยุคประกอบด้วย IrisBatch es มาดูองค์ประกอบแรกของยุคแรกกันดีกว่า
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
โปรดสังเกตว่าฟีเจอร์สำหรับตัวอย่าง batchSize แรกจะถูกจัดกลุ่มไว้ด้วยกัน (หรือ เป็นแบตช์ ) ลงใน firstTrainFeatures และป้ายกำกับสำหรับตัวอย่าง batchSize แรกจะถูกแบทช์เป็น firstTrainLabels
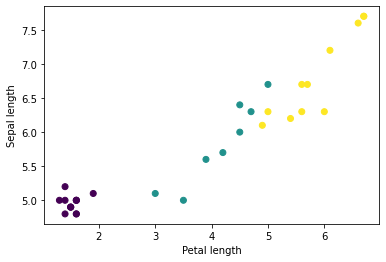
คุณสามารถเริ่มเห็นคลัสเตอร์บางส่วนได้โดยการวางแผนคุณสมบัติบางอย่างจากแบตช์ โดยใช้ matplotlib ของ Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
เลือกประเภทของรุ่น
ทำไมต้องเป็นนางแบบ?
แบบจำลอง คือความสัมพันธ์ระหว่างคุณลักษณะและป้ายกำกับ สำหรับปัญหาการจำแนกม่านตา แบบจำลองจะกำหนดความสัมพันธ์ระหว่างการวัดกลีบเลี้ยงและกลีบดอกกับชนิดของม่านตาที่คาดการณ์ไว้ โมเดลง่ายๆ บางโมเดลสามารถอธิบายได้ด้วยพีชคณิตเพียงไม่กี่บรรทัด แต่โมเดลการเรียนรู้ของเครื่องที่ซับซ้อนมีพารามิเตอร์จำนวนมากซึ่งยากต่อการสรุป
คุณสามารถระบุความสัมพันธ์ระหว่างคุณสมบัติทั้งสี่กับสายพันธุ์ม่านตา โดยไม่ต้อง ใช้การเรียนรู้ของเครื่องได้หรือไม่ นั่นคือ คุณสามารถใช้เทคนิคการเขียนโปรแกรมแบบดั้งเดิม (เช่น ข้อความสั่งแบบมีเงื่อนไขจำนวนมาก) เพื่อสร้างโมเดลได้หรือไม่ บางที หากคุณวิเคราะห์ชุดข้อมูลนานพอที่จะระบุความสัมพันธ์ระหว่างการวัดกลีบดอกและกลีบเลี้ยงกับสายพันธุ์ใดสายพันธุ์หนึ่ง และสิ่งนี้กลายเป็นเรื่องยาก—อาจเป็นไปไม่ได้—ในชุดข้อมูลที่ซับซ้อนมากขึ้น แนวทางการเรียนรู้ของเครื่องที่ดี จะกำหนดโมเดลสำหรับคุณ หากคุณป้อนตัวอย่างที่เป็นตัวแทนเพียงพอในประเภทโมเดลการเรียนรู้ของเครื่องที่เหมาะสม โปรแกรมจะค้นหาความสัมพันธ์ให้คุณ
เลือกรุ่น
เราจำเป็นต้องเลือกประเภทของโมเดลที่จะฝึก มีโมเดลหลายประเภทและการเลือกรุ่นที่ดีต้องใช้ประสบการณ์ บทช่วยสอนนี้ใช้โครงข่ายประสาทเทียมเพื่อแก้ปัญหาการจำแนกม่านตา โครงข่ายประสาทเทียม สามารถค้นหาความสัมพันธ์ที่ซับซ้อนระหว่างฟีเจอร์และป้ายกำกับได้ เป็นกราฟที่มีโครงสร้างสูง ซึ่งจัดเป็น เลเยอร์ที่ซ่อนอยู่ หนึ่งเลเยอร์ขึ้นไป แต่ละเลเยอร์ที่ซ่อนอยู่ประกอบด้วย เซลล์ประสาท ตั้งแต่หนึ่งตัวขึ้นไป โครงข่ายประสาทเทียมมีหลายประเภท และโปรแกรมนี้ใช้ โครงข่ายประสาทเทียมที่หนาแน่นหรือเชื่อมต่อกันอย่างสมบูรณ์ : เซลล์ประสาทในชั้นเดียวจะได้รับการเชื่อมต่ออินพุตจาก ทุก เซลล์ประสาทในชั้นก่อนหน้า ตัวอย่างเช่น รูปที่ 2 แสดงให้เห็นถึงโครงข่ายประสาทเทียมที่หนาแน่นซึ่งประกอบด้วยเลเยอร์อินพุต เลเยอร์ที่ซ่อนอยู่ 2 ชั้น และเลเยอร์เอาท์พุต:
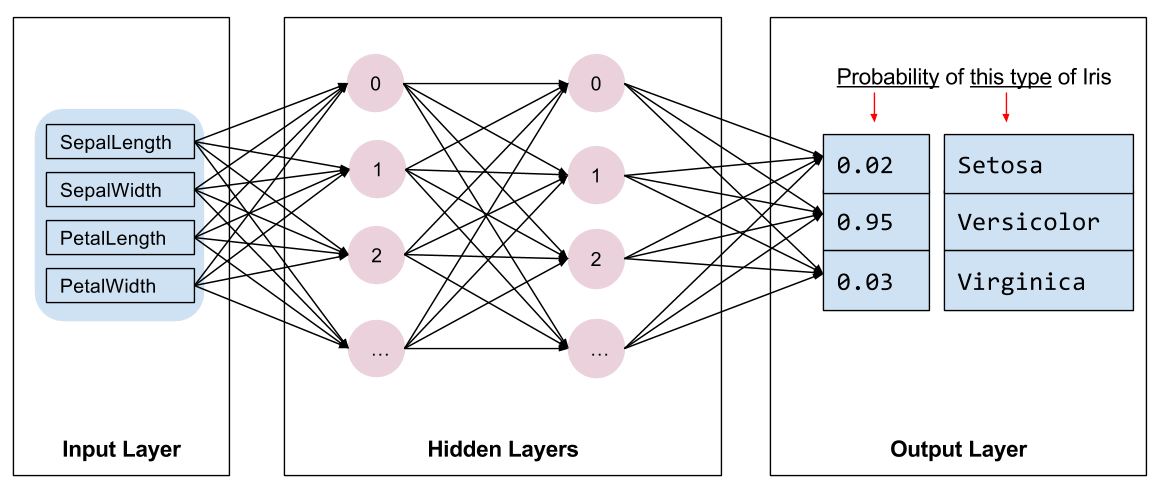 |
| รูปที่ 2 โครงข่ายประสาทเทียมที่มีคุณสมบัติ เลเยอร์ที่ซ่อนอยู่ และการคาดคะเน |
เมื่อแบบจำลองจากรูปที่ 2 ได้รับการฝึกและป้อนตัวอย่างที่ไม่มีป้ายกำกับ จะทำให้เกิดการคาดการณ์ได้ 3 แบบ คือ ความน่าจะเป็นที่ดอกไม้ชนิดนี้จะเป็นพันธุ์ไอริสที่กำหนด การทำนายนี้เรียกว่า การอนุมาน สำหรับตัวอย่างนี้ ผลรวมของการทำนายผลลัพธ์คือ 1.0 ในรูปที่ 2 การทำนายนี้แบ่งออกเป็น: 0.02 สำหรับ Iris setosa , 0.95 สำหรับ Iris versicolor และ 0.03 สำหรับ Iris virginica ซึ่งหมายความว่าแบบจำลองคาดการณ์ (ด้วยความน่าจะเป็น 95%) ว่าดอกไม้ตัวอย่างที่ไม่มีป้ายกำกับคือดอก ไอริสหลากสี
สร้างแบบจำลองโดยใช้ Swift สำหรับ TensorFlow Deep Learning Library
ไลบรารีการเรียนรู้เชิงลึกของ Swift สำหรับ TensorFlow กำหนดเลเยอร์ดั้งเดิมและแบบแผนในการรวมเข้าด้วยกัน ซึ่งทำให้ง่ายต่อการสร้างแบบจำลองและการทดลอง
โมเดลคือ struct ที่สอดคล้องกับ Layer ซึ่งหมายความว่าโมเดลจะกำหนดเมธอด callAsFunction(_:) ที่จับคู่อินพุต Tensor s กับเอาต์พุต Tensor s เมธอด callAsFunction(_:) มักจะจัดลำดับอินพุตผ่านเลเยอร์ย่อย เรามากำหนด IrisModel ที่จะจัดลำดับอินพุตผ่านเลเยอร์ย่อย Dense สามชั้น
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
ฟังก์ชั่นการเปิดใช้งานจะกำหนดรูปร่างเอาต์พุตของแต่ละโหนดในเลเยอร์ การไม่เชิงเส้นเหล่านี้มีความสำคัญ หากไม่มีสิ่งเหล่านั้น แบบจำลองก็จะเทียบเท่ากับเลเยอร์เดียว มีการเปิดใช้งานหลายอย่าง แต่ ReLU เป็นเรื่องปกติสำหรับเลเยอร์ที่ซ่อนอยู่
จำนวนเลเยอร์และเซลล์ประสาทที่ซ่อนอยู่ในอุดมคตินั้นขึ้นอยู่กับปัญหาและชุดข้อมูล เช่นเดียวกับแง่มุมต่างๆ ของการเรียนรู้ของเครื่อง การเลือกรูปแบบที่ดีที่สุดของโครงข่ายประสาทเทียมต้องอาศัยความรู้และการทดลองผสมผสานกัน ตามหลักทั่วไปแล้ว การเพิ่มจำนวนเลเยอร์และเซลล์ประสาทที่ซ่อนอยู่มักจะสร้างแบบจำลองที่ทรงพลังยิ่งขึ้น ซึ่งต้องใช้ข้อมูลมากขึ้นเพื่อฝึกฝนอย่างมีประสิทธิภาพ
การใช้แบบจำลอง
มาดูกันว่าโมเดลนี้ทำอะไรกับฟีเจอร์ต่างๆ บ้าง:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
ที่นี่ แต่ละตัวอย่างจะส่งคืน logit สำหรับแต่ละคลาส
หากต้องการแปลงบันทึกเหล่านี้เป็นความน่าจะเป็นสำหรับแต่ละคลาส ให้ใช้ฟังก์ชัน softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
การใช้ argmax ข้ามคลาสจะทำให้เราได้ดัชนีคลาสที่คาดการณ์ไว้ แต่แบบจำลองยังไม่ได้รับการฝึก ดังนั้นสิ่งเหล่านี้จึงไม่ใช่การคาดการณ์ที่ดี
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
ฝึกโมเดล
การฝึกอบรม เป็นขั้นตอนของแมชชีนเลิร์นนิงเมื่อโมเดลค่อยๆ ปรับให้เหมาะสม หรือโมเดล เรียนรู้ ชุดข้อมูล เป้าหมายคือการเรียนรู้เพียงพอเกี่ยวกับโครงสร้างของชุดข้อมูลการฝึกอบรมเพื่อคาดการณ์ข้อมูลที่มองไม่เห็น หากคุณเรียนรู้ มากเกินไป เกี่ยวกับชุดข้อมูลการฝึกอบรม การคาดการณ์จะใช้ได้เฉพาะกับข้อมูลที่เห็นและไม่สามารถสรุปได้ ปัญหานี้เรียกว่า การกระชับมากเกินไป เหมือนกับการท่องจำคำตอบแทนที่จะทำความเข้าใจวิธีแก้ปัญหา
ปัญหาการจำแนกม่านตาเป็นตัวอย่างหนึ่งของ การเรียนรู้ของเครื่องภายใต้การดูแล : โมเดลได้รับการฝึกอบรมจากตัวอย่างที่มีป้ายกำกับ ใน การเรียนรู้ของเครื่องแบบไม่มีผู้ดูแล ตัวอย่างจะไม่มีป้ายกำกับ แต่โดยทั่วไปแล้วโมเดลจะค้นหารูปแบบระหว่างคุณลักษณะต่างๆ แทน
เลือกฟังก์ชันการสูญเสีย
ทั้งขั้นตอนการฝึกอบรมและการประเมินผลจำเป็นต้องคำนวณ การสูญเสีย ของแบบจำลอง วิธีนี้จะวัดว่าการคาดการณ์ของแบบจำลองนั้นมาจากป้ายกำกับที่ต้องการมากน้อยเพียงใด หรืออีกนัยหนึ่งคือประสิทธิภาพของแบบจำลองนั้นแย่เพียงใด เราต้องการลดหรือปรับค่านี้ให้เหมาะสมที่สุด
แบบจำลองของเราจะคำนวณการสูญเสียโดยใช้ฟังก์ชัน softmaxCrossEntropy(logits:labels:) ซึ่งใช้การคาดการณ์ความน่าจะเป็นของคลาสของโมเดลและป้ายกำกับที่ต้องการ แล้วส่งคืนการสูญเสียโดยเฉลี่ยในตัวอย่างต่างๆ
มาคำนวณการสูญเสียสำหรับโมเดลที่ไม่ได้รับการฝึกในปัจจุบัน:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
สร้างเครื่องมือเพิ่มประสิทธิภาพ
เครื่องมือเพิ่มประสิทธิภาพ จะใช้การไล่ระดับสีที่คำนวณกับตัวแปรของโมเดลเพื่อลดฟังก์ชัน loss น้อยที่สุด คุณสามารถนึกถึงฟังก์ชันการสูญเสียเป็นพื้นผิวโค้ง (ดูรูปที่ 3) และเราต้องการหาจุดต่ำสุดโดยการเดินไปรอบๆ การไล่ระดับสีจะชี้ไปในทิศทางที่ลาดชันที่สุด ดังนั้นเราจะเดินทางในทิศทางตรงกันข้ามและเคลื่อนตัวลงจากเนินเขา ด้วยการคำนวณการสูญเสียและการไล่ระดับสีซ้ำๆ สำหรับแต่ละชุด เราจะปรับแบบจำลองระหว่างการฝึก แบบจำลองจะค่อยๆ ค้นหาการผสมผสานระหว่างน้ำหนักและความลำเอียงที่ดีที่สุดเพื่อลดการสูญเสียให้เหลือน้อยที่สุด และยิ่งสูญเสียน้อยเท่าใด การคาดการณ์ของแบบจำลองก็จะยิ่งดีขึ้นเท่านั้น
 |
| รูปที่ 3 อัลกอริธึมการปรับให้เหมาะสมที่มองเห็นเมื่อเวลาผ่านไปในพื้นที่ 3 มิติ (ที่มา: Stanford class CS231n , ใบอนุญาต MIT, เครดิตรูปภาพ: Alec Radford ) |
Swift สำหรับ TensorFlow มี อัลกอริธึมการปรับให้เหมาะสม มากมายสำหรับการฝึกอบรม แบบจำลองนี้ใช้เครื่องมือเพิ่มประสิทธิภาพ SGD ที่ใช้อัลกอริ ทึม Stochastic Gradient Descent (SGD) learningRate จะกำหนดขนาดก้าวที่จะใช้สำหรับการวนซ้ำแต่ละครั้งลงเขา นี่คือ ไฮเปอร์พารามิเตอร์ ที่คุณจะปรับโดยทั่วไปเพื่อให้ได้ผลลัพธ์ที่ดีขึ้น
let optimizer = SGD(for: model, learningRate: 0.01)
ลองใช้ optimizer เพื่อทำตามขั้นตอนการไล่ระดับสีเดียว ขั้นแรก เราคำนวณความชันของการสูญเสียตามแบบจำลอง:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
ต่อไป เราส่งต่อการไล่ระดับสีที่เราเพิ่งคำนวณไปยังเครื่องมือเพิ่มประสิทธิภาพ ซึ่งจะอัปเดตตัวแปรอนุพันธ์ของโมเดลตามนั้น:
optimizer.update(&model, along: grads)
หากเราคำนวณการสูญเสียอีกครั้ง มันควรจะน้อยลง เนื่องจากขั้นตอนการไล่ระดับลง (ปกติ) จะลดการสูญเสีย:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
ห่วงการฝึกอบรม
เมื่อชิ้นส่วนทั้งหมดเข้าที่แล้ว โมเดลก็พร้อมสำหรับการฝึก! ลูปการฝึกอบรมจะป้อนตัวอย่างชุดข้อมูลลงในโมเดลเพื่อช่วยในการคาดการณ์ได้ดีขึ้น บล็อกโค้ดต่อไปนี้จะตั้งค่าขั้นตอนการฝึกอบรมเหล่านี้:
- ทำซ้ำในแต่ละ ยุค ยุคคือหนึ่งการส่งผ่านชุดข้อมูล
- ภายในยุคหนึ่ง ทำซ้ำแต่ละชุดในยุคการฝึกอบรม
- จัดเรียงแบทช์และคว้า คุณสมบัติ (
x) และ ป้ายกำกับ (y) - ใช้คุณลักษณะของชุดการจัดเรียง ทำการคาดการณ์และเปรียบเทียบกับป้ายกำกับ วัดความไม่ถูกต้องของการทำนายและใช้ค่านั้นเพื่อคำนวณการสูญเสียและการไล่ระดับสีของโมเดล
- ใช้การไล่ระดับสีเพื่ออัปเดตตัวแปรของโมเดล
- ติดตามสถิติบางอย่างสำหรับการแสดงภาพ
- ทำซ้ำสำหรับแต่ละยุค
ตัวแปร epochCount คือจำนวนครั้งในการวนซ้ำคอลเลกชันชุดข้อมูล การฝึกโมเดลให้นานขึ้นไม่ได้รับประกันว่าโมเดลจะดีขึ้น epochCount เป็น ไฮเปอร์พารามิเตอร์ ที่คุณปรับแต่งได้ การเลือกหมายเลขที่เหมาะสมมักต้องใช้ทั้งประสบการณ์และการทดลอง
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
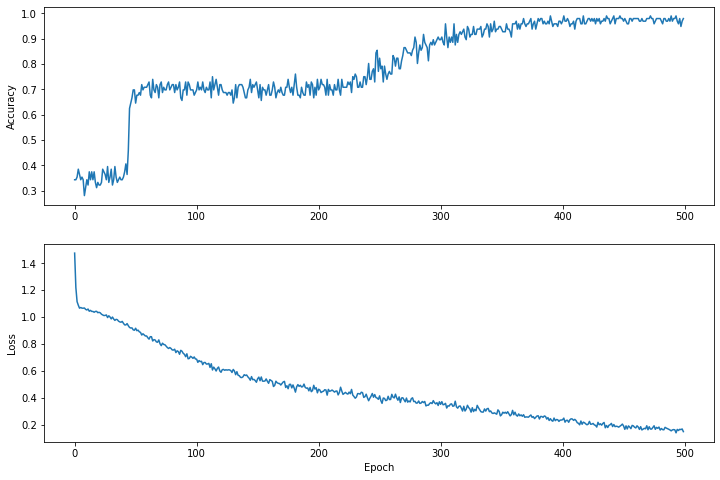
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
เห็นภาพฟังก์ชันการสูญเสียเมื่อเวลาผ่านไป
แม้ว่าการพิมพ์ความคืบหน้าในการฝึกของแบบจำลองจะมีประโยชน์ แต่การดูความคืบหน้านี้มักจะมีประโยชน์ มากกว่า เราสามารถสร้างแผนภูมิพื้นฐานโดยใช้โมดูล matplotlib ของ Python
การตีความแผนภูมิเหล่านี้ต้องใช้ประสบการณ์พอสมควร แต่คุณต้องการเห็นการ สูญเสีย ลดลงและ ความแม่นยำ เพิ่มขึ้น
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
โปรดทราบว่าแกน y ของกราฟไม่ใช่แบบอิงศูนย์
ประเมินประสิทธิภาพของแบบจำลอง
เมื่อโมเดลได้รับการฝึกฝนแล้ว เราก็สามารถรับสถิติเกี่ยวกับประสิทธิภาพของโมเดลได้
การประเมิน หมายถึงการกำหนดว่าแบบจำลองสามารถคาดการณ์ได้อย่างมีประสิทธิภาพเพียงใด ในการพิจารณาประสิทธิภาพของแบบจำลองในการจำแนกม่านตา ให้ส่งการวัดกลีบเลี้ยงและกลีบดอกไม้ไปยังแบบจำลอง และขอให้แบบจำลองคาดการณ์ว่าม่านตานั้นเป็นตัวแทนของสายพันธุ์ใด จากนั้นเปรียบเทียบการทำนายของแบบจำลองกับป้ายกำกับจริง ตัวอย่างเช่น แบบจำลองที่เลือกสายพันธุ์ที่ถูกต้องจากตัวอย่างอินพุตครึ่งหนึ่งมี ความแม่นยำ 0.5 รูปที่ 4 แสดงแบบจำลองที่มีประสิทธิภาพมากกว่าเล็กน้อย โดยได้รับการคาดการณ์ 4 ใน 5 ที่ถูกต้องที่ความแม่นยำ 80%:
| คุณสมบัติตัวอย่าง | ฉลาก | การทำนายแบบจำลอง | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| รูปที่ 4 เครื่องแยกประเภทม่านตาที่มีความแม่นยำ 80% | |||||
ตั้งค่าชุดข้อมูลทดสอบ
การประเมินโมเดลจะคล้ายกับการฝึกโมเดล ความแตกต่างที่ใหญ่ที่สุดคือตัวอย่างมาจาก ชุดทดสอบ แยกต่างหาก แทนที่จะเป็นชุดการฝึก เพื่อประเมินประสิทธิภาพของแบบจำลองอย่างยุติธรรม ตัวอย่างที่ใช้ในการประเมินแบบจำลองจะต้องแตกต่างจากตัวอย่างที่ใช้ในการฝึกแบบจำลอง
การตั้งค่าสำหรับชุดข้อมูลทดสอบจะคล้ายกับการตั้งค่าสำหรับชุดข้อมูลการฝึก ดาวน์โหลดชุดทดสอบได้จาก http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
ตอนนี้โหลดมันลงในอาร์เรย์ของ IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
ประเมินแบบจำลองบนชุดข้อมูลทดสอบ
แบบจำลองจะประเมินข้อมูลการทดสอบเพียง ช่วง เดียวเท่านั้น ซึ่งต่างจากขั้นตอนการฝึกอบรม ในเซลล์โค้ดต่อไปนี้ เราจะวนซ้ำแต่ละตัวอย่างในชุดทดสอบ และเปรียบเทียบการทำนายของแบบจำลองกับป้ายกำกับจริง ใช้เพื่อวัดความแม่นยำของแบบจำลองทั่วทั้งชุดทดสอบ
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
เราเห็นได้ในชุดแรก ตัวอย่างเช่น โมเดลมักจะถูกต้อง:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
ใช้แบบจำลองที่ผ่านการฝึกอบรมเพื่อคาดการณ์
เราได้ฝึกแบบจำลองและแสดงให้เห็นว่าแบบจำลองนั้นดี—แต่ไม่สมบูรณ์แบบ—ในการจำแนกชนิดพันธุ์ไอริส ตอนนี้ ลองใช้โมเดลที่ได้รับการฝึกอบรมเพื่อคาดการณ์ ตัวอย่างที่ไม่มีป้ายกำกับ นั่นคือในตัวอย่างที่มีคุณสมบัติแต่ไม่มีป้ายกำกับ
ในชีวิตจริง ตัวอย่างที่ไม่มีป้ายกำกับอาจมาจากแหล่งที่มาต่างๆ มากมาย รวมถึงแอป ไฟล์ CSV และฟีดข้อมูล สำหรับตอนนี้ เราจะจัดเตรียมตัวอย่างที่ไม่มีป้ายกำกับสามตัวอย่างด้วยตนเองเพื่อคาดการณ์ป้ายกำกับของพวกเขา โปรดจำไว้ว่า หมายเลขฉลากถูกแมปกับการแสดงชื่อดังนี้:
-
0: ไอริส เซโตซ่า -
1: ไอริส เวอร์ซิคัลเลอร์ -
2: ไอริส เวอร์จินิกา
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])