
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub |
В этом руководстве рассматривается Swift для TensorFlow путем создания модели машинного обучения, которая классифицирует цветы ириса по видам. Он использует Swift для TensorFlow, чтобы:
- Постройте модель,
- Обучите эту модель на примерах данных и
- Используйте модель, чтобы делать прогнозы относительно неизвестных данных.
Программирование TensorFlow
В этом руководстве используются эти высокоуровневые концепции Swift для TensorFlow:
- Импортируйте данные с помощью Epochs API.
- Создавайте модели, используя абстракции Swift.
- Используйте библиотеки Python, используя совместимость Swift с Python, когда чистые библиотеки Swift недоступны.
Это руководство структурировано, как и многие программы TensorFlow:
- Импортируйте и анализируйте наборы данных.
- Выберите тип модели.
- Обучите модель.
- Оцените эффективность модели.
- Используйте обученную модель для прогнозирования.
Программа установки
Настройка импорта
Импортируйте TensorFlow и некоторые полезные модули Python.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
Проблема классификации радужной оболочки
Представьте, что вы ботаник, ищущий автоматизированный способ классифицировать каждый найденный цветок ириса. Машинное обучение предоставляет множество алгоритмов для статистической классификации цветов. Например, сложная программа машинного обучения могла бы классифицировать цветы на основе фотографий. Наши амбиции более скромные — мы собираемся классифицировать цветы ириса по длине и ширине их чашелистиков и лепестков .
Род Iris насчитывает около 300 видов, но наша программа классифицирует только следующие три:
- Ирис сетоза
- Ирис виргинский
- Ирис разноцветный
 |
| Рисунок 1. Iris setosa (от Radomil , CC BY-SA 3.0), Iris versicolor (от Dlanglois , CC BY-SA 3.0) и Iris Virginica (от Frank Mayfield , CC BY-SA 2.0). |
К счастью, кто-то уже создал набор данных из 120 цветов ириса с размерами чашелистиков и лепестков. Это классический набор данных, который популярен среди начинающих специалистов по классификации машинного обучения.
Импортируйте и анализируйте набор обучающих данных.
Загрузите файл набора данных и преобразуйте его в структуру, которую может использовать эта программа Swift.
Загрузите набор данных
Загрузите файл набора обучающих данных по адресу http://download.tensorflow.org/data/iris_training.csv.
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Проверьте данные
Этот набор данных, iris_training.csv , представляет собой обычный текстовый файл, в котором хранятся табличные данные в формате значений, разделенных запятыми (CSV). Давайте посмотрим первые 5 записей.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
Из этого представления набора данных обратите внимание на следующее:
- Первая строка представляет собой заголовок, содержащий информацию о наборе данных:
- Всего примеров 120. Каждый пример имеет четыре функции и одно из трех возможных названий меток.
- Последующие строки представляют собой записи данных, по одному примеру в каждой строке, где:
- Первые четыре поля — это характеристики : это характеристики примера. Здесь поля содержат числа с плавающей запятой, представляющие размеры цветка.
- Последний столбец — это метка : это значение, которое мы хотим спрогнозировать. Для этого набора данных это целое значение 0, 1 или 2, соответствующее названию цветка.
Запишем это в коде:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Каждая метка связана с именем строки (например, «setosa»), но машинное обучение обычно основано на числовых значениях. Номера меток сопоставляются с именованным представлением, например:
-
0: Ирис сетоза -
1: Ирис разноцветный -
2: Ирис виргинский
Дополнительные сведения о функциях и метках см. в разделе «Терминология машинного обучения» ускоренного курса машинного обучения .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Создайте набор данных с помощью API Epochs.
Swift для Epochs API TensorFlow — это API высокого уровня для чтения данных и преобразования их в форму, используемую для обучения.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Поскольку загруженные нами наборы данных имеют формат CSV, давайте напишем функцию для загрузки данных в виде списка объектов IrisBatch.
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Теперь мы можем использовать функцию загрузки CSV для загрузки набора обучающих данных и создания объекта TrainingEpochs .
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
Объект TrainingEpochs представляет собой бесконечную последовательность эпох. Каждая эпоха содержит файлы IrisBatch . Давайте посмотрим на первый элемент первой эпохи.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
Обратите внимание, что функции для первых примеров batchSize сгруппированы (или упакованы ) в firstTrainFeatures , а метки для первых примеров batchSize объединены в firstTrainLabels .
Вы можете начать видеть некоторые кластеры, построив график нескольких функций из пакета, используя matplotlib Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
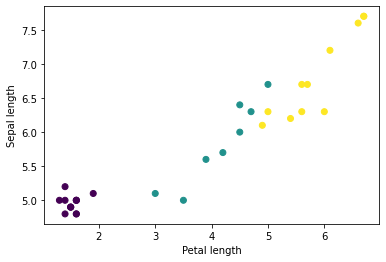
Use `print()` to show values.
Выберите тип модели
Почему модель?
Модель — это связь между функциями и меткой. Для задачи классификации ирисов модель определяет взаимосвязь между размерами чашелистиков и лепестков и прогнозируемым видом ирисов. Некоторые простые модели можно описать несколькими строками алгебры, но сложные модели машинного обучения имеют большое количество параметров, которые сложно суммировать.
Сможете ли вы определить связь между четырьмя признаками и видами ирисов без использования машинного обучения? То есть, можете ли вы использовать традиционные методы программирования (например, множество условных операторов) для создания модели? Возможно, если вы проанализировали набор данных достаточно долго, чтобы определить взаимосвязь между размерами лепестков и чашелистиков для конкретного вида. И это становится трудным, а может быть, и невозможным для более сложных наборов данных. Хороший подход к машинному обучению определяет модель для вас . Если вы введете достаточно репрезентативных примеров в модель машинного обучения нужного типа, программа выяснит взаимосвязи за вас.
Выберите модель
Нам нужно выбрать тип модели для обучения. Существует много типов моделей, и выбор хорошей требует опыта. В этом уроке нейронная сеть используется для решения проблемы классификации радужной оболочки. Нейронные сети могут находить сложные связи между функциями и меткой. Это высокоструктурированный график, организованный в один или несколько скрытых слоев . Каждый скрытый слой состоит из одного или нескольких нейронов . Существует несколько категорий нейронных сетей, и эта программа использует плотную или полносвязную нейронную сеть : нейроны одного слоя получают входные соединения от каждого нейрона предыдущего слоя. Например, на рисунке 2 показана плотная нейронная сеть, состоящая из входного слоя, двух скрытых слоев и выходного слоя:
 |
| Рисунок 2. Нейронная сеть с функциями, скрытыми слоями и прогнозами. |
Когда модель на рисунке 2 обучается и ей передается немаркированный пример, она дает три прогноза: вероятность того, что этот цветок принадлежит данному виду ирисов. Это предсказание называется умозаключением . В этом примере сумма выходных прогнозов равна 1,0. На рисунке 2 этот прогноз выглядит следующим образом: 0.02 для Iris setosa , 0.95 для Iris versicolor и 0.03 для Iris Virginica . Это означает, что модель предсказывает – с вероятностью 95% – что немаркированный пример цветка — это ирис разноцветный .
Создайте модель, используя Swift для библиотеки глубокого обучения TensorFlow.
Библиотека глубокого обучения Swift для TensorFlow определяет примитивные слои и соглашения для их соединения, что упрощает создание моделей и экспериментирование.
Модель — это struct , соответствующая Layer , что означает, что она определяет метод callAsFunction(_:) , который сопоставляет входные Tensor с выходными Tensor . Метод callAsFunction(_:) часто просто упорядочивает входные данные по подслоям. Давайте определим IrisModel , которая упорядочивает входные данные через три подслоя Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
Функция активации определяет выходную форму каждого узла слоя. Эти нелинейности важны — без них модель была бы эквивалентна одному слою. Существует множество доступных активаций, но ReLU обычно используется для скрытых слоев.
Идеальное количество скрытых слоев и нейронов зависит от проблемы и набора данных. Как и во многих аспектах машинного обучения, выбор лучшей формы нейронной сети требует сочетания знаний и экспериментов. Как правило, увеличение количества скрытых слоев и нейронов обычно создает более мощную модель, для эффективного обучения которой требуется больше данных.
Использование модели
Давайте кратко рассмотрим, что эта модель делает с рядом функций:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Здесь каждый пример возвращает логит для каждого класса.
Чтобы преобразовать эти логиты в вероятность для каждого класса, используйте функцию softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Взятие argmax по классам дает нам прогнозируемый индекс класса. Но модель еще не обучена, поэтому это не очень хорошие прогнозы.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Обучение модели
Обучение — это этап машинного обучения, на котором модель постепенно оптимизируется или модель изучает набор данных. Цель состоит в том, чтобы узнать достаточно о структуре набора обучающих данных, чтобы делать прогнозы относительно невидимых данных. Если вы узнаете слишком много о наборе обучающих данных, то прогнозы будут работать только для тех данных, которые он видел, и не будут поддаваться обобщению. Эта проблема называется переоснащением — это похоже на запоминание ответов вместо понимания того, как решить проблему.
Задача классификации радужной оболочки глаза — это пример контролируемого машинного обучения : модель обучается на примерах, содержащих метки. При машинном обучении без учителя примеры не содержат меток. Вместо этого модель обычно находит закономерности среди функций.
Выберите функцию потерь
На этапах обучения и оценки необходимо рассчитать потери модели. Это измеряет, насколько прогнозы модели отличаются от желаемой метки, другими словами, насколько плоха модель. Мы хотим минимизировать или оптимизировать это значение.
Наша модель рассчитает свои потери с помощью функции softmaxCrossEntropy(logits:labels:) которая принимает прогнозы вероятности класса модели и желаемую метку и возвращает средние потери по всем примерам.
Давайте посчитаем потери для текущей необученной модели:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Создать оптимизатор
Оптимизатор применяет вычисленные градиенты к переменным модели, чтобы минимизировать функцию loss . Вы можете представить функцию потерь как изогнутую поверхность (см. рисунок 3), и мы хотим найти ее самую низкую точку, прогуливаясь по ней. Склоны указывают в направлении самого крутого подъема, поэтому мы пойдем в противоположном направлении и спустимся с холма. Итеративно вычисляя потери и градиент для каждой партии, мы будем корректировать модель во время обучения. Постепенно модель найдет лучшее сочетание весов и смещений, чтобы минимизировать потери. И чем меньше потери, тем точнее прогнозы модели.
 |
| Рисунок 3. Алгоритмы оптимизации, визуализированные с течением времени в 3D-пространстве. (Источник: Стэнфордский класс CS231n , лицензия MIT, изображение предоставлено Алеком Рэдфордом ) |
Swift для TensorFlow имеет множество алгоритмов оптимизации, доступных для обучения. Эта модель использует оптимизатор SGD, который реализует алгоритм стохастического градиентного спуска (SGD). learningRate устанавливает размер шага для каждой итерации вниз по склону. Это гиперпараметр , который вы обычно настраиваете для достижения лучших результатов.
let optimizer = SGD(for: model, learningRate: 0.01)
Давайте воспользуемся optimizer , чтобы сделать один шаг градиентного спуска. Сначала мы вычисляем градиент потерь по отношению к модели:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
Затем мы передаем только что рассчитанный градиент оптимизатору, который соответствующим образом обновляет дифференцируемые переменные модели:
optimizer.update(&model, along: grads)
Если мы посчитаем потери еще раз, они должны быть меньше, потому что шаги градиентного спуска (обычно) уменьшают потери:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Тренировочный цикл
Когда все детали на месте, модель готова к обучению! Цикл обучения передает примеры наборов данных в модель, чтобы помочь ей делать более точные прогнозы. Следующий блок кода устанавливает эти этапы обучения:
- Перебирайте каждую эпоху . Эпоха — это один проход по набору данных.
- В течение эпохи перебирайте каждую партию в эпоху обучения.
- Соберите пакет и возьмите его характеристики (
x) и метку (y). - Используя функции сопоставленной партии, сделайте прогноз и сравните его с этикеткой. Измерьте неточность прогноза и используйте ее для расчета потерь и градиентов модели.
- Используйте градиентный спуск, чтобы обновить переменные модели.
- Следите за некоторой статистикой для визуализации.
- Повторите для каждой эпохи.
Переменная epochCount — это количество циклов обработки коллекции набора данных. Как ни странно, более длительное обучение модели не гарантирует лучшую модель. epochCount — это гиперпараметр , который вы можете настроить. Выбор правильного числа обычно требует как опыта, так и экспериментов.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
Визуализируйте функцию потерь с течением времени
Распечатать ход обучения модели полезно, но зачастую полезнее видеть этот прогресс. Мы можем создавать базовые диаграммы, используя модуль Python matplotlib .
Интерпретация этих графиков требует некоторого опыта, но вы действительно хотите, чтобы потери снизились, а точность повысилась.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
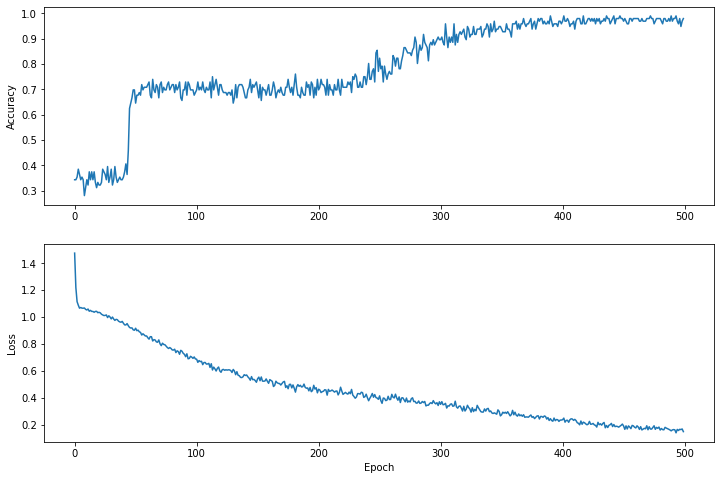
Use `print()` to show values.
Обратите внимание, что оси Y графиков отсчитываются не от нуля.
Оцените эффективность модели
Теперь, когда модель обучена, мы можем получить некоторую статистику ее производительности.
Оценка означает определение того, насколько эффективно модель делает прогнозы. Чтобы определить эффективность модели при классификации ирисов, передайте модели некоторые измерения чашелистиков и лепестков и попросите модель предсказать, какие виды ирисов они представляют. Затем сравните прогноз модели с фактической меткой. Например, модель, которая выбрала правильный вид в половине входных примеров, имеет точность 0.5 . На рисунке 4 показана немного более эффективная модель, позволяющая получить 4 из 5 прогнозов с точностью 80 %.
| Примеры функций | Этикетка | Прогноз модели | |||
|---|---|---|---|---|---|
| 5,9 | 3.0 | 4.3 | 1,5 | 1 | 1 |
| 6,9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1,7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4,5 | 1,6 | 1 | 2 |
| 5,5 | 2,5 | 4.0 | 1.3 | 1 | 1 |
| Рисунок 4. Классификатор радужной оболочки глаза с точностью 80%. | |||||
Настройте тестовый набор данных
Оценка модели аналогична обучению модели. Самая большая разница заключается в том, что примеры взяты из отдельного тестового набора, а не из обучающего набора. Чтобы справедливо оценить эффективность модели, примеры, используемые для оценки модели, должны отличаться от примеров, используемых для обучения модели.
Настройка тестового набора данных аналогична настройке набора обучающих данных. Загрузите набор тестов с http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Теперь загрузите его в массив файлов IrisBatch :
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Оцените модель на тестовом наборе данных.
В отличие от этапа обучения, модель оценивает только одну эпоху тестовых данных. В следующей ячейке кода мы перебираем каждый пример в тестовом наборе и сравниваем прогноз модели с фактической меткой. Это используется для измерения точности модели по всему набору тестов.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
Например, на первой партии мы видим, что модель обычно правильная:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Используйте обученную модель для прогнозирования
Мы обучили модель и продемонстрировали, что она хорошо, но не идеально, классифицирует виды ирисов. Теперь давайте воспользуемся обученной моделью, чтобы сделать некоторые прогнозы на неразмеченных примерах ; то есть на примерах, которые содержат функции, но не метку.
В реальной жизни немаркированные примеры могут быть взяты из множества разных источников, включая приложения, файлы CSV и каналы данных. На данный момент мы собираемся вручную предоставить три примера без меток, чтобы предсказать их метки. Напомним, номера меток сопоставляются с именованным представлением следующим образом:
-
0: Ирис сетоза -
1: Ирис разноцветный -
2: Ирис виргинский
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])