
| | |  Ver fonte no GitHub Ver fonte no GitHub |
Este guia apresenta o Swift para TensorFlow criando um modelo de aprendizado de máquina que categoriza flores de íris por espécie. Ele usa Swift para TensorFlow para:
- Construa um modelo,
- Treine este modelo com dados de exemplo e
- Use o modelo para fazer previsões sobre dados desconhecidos.
Programação do TensorFlow
Este guia usa estes conceitos de alto nível do Swift para TensorFlow:
- Importe dados com a API Epochs.
- Construa modelos usando abstrações Swift.
- Use bibliotecas Python usando a interoperabilidade Python do Swift quando bibliotecas Swift puras não estiverem disponíveis.
Este tutorial está estruturado como muitos programas TensorFlow:
- Importe e analise os conjuntos de dados.
- Selecione o tipo de modelo.
- Treine o modelo.
- Avalie a eficácia do modelo.
- Use o modelo treinado para fazer previsões.
Programa de configuração
Configurar importações
Importe o TensorFlow e alguns módulos Python úteis.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
O problema de classificação da íris
Imagine que você é um botânico em busca de uma maneira automatizada de categorizar cada flor de íris que encontrar. O aprendizado de máquina fornece muitos algoritmos para classificar flores estatisticamente. Por exemplo, um programa sofisticado de aprendizado de máquina poderia classificar flores com base em fotografias. Nossas ambições são mais modestas: classificaremos as flores da íris com base nas medidas de comprimento e largura de suas sépalas e pétalas .
O gênero Iris abrange cerca de 300 espécies, mas nosso programa classificará apenas as três seguintes:
- Iris setosa
- Íris virgem
- Íris versicolor
 |
| Figura 1. Iris setosa (por Radomil , CC BY-SA 3.0), Iris versicolor , (por Dlanglois , CC BY-SA 3.0) e Iris virginica (por Frank Mayfield , CC BY-SA 2.0). |
Felizmente, alguém já criou um conjunto de dados de 120 flores de íris com medidas de sépalas e pétalas. Este é um conjunto de dados clássico popular para problemas de classificação de aprendizado de máquina para iniciantes.
Importe e analise o conjunto de dados de treinamento
Baixe o arquivo do conjunto de dados e converta-o em uma estrutura que possa ser usada por este programa Swift.
Baixe o conjunto de dados
Baixe o arquivo do conjunto de dados de treinamento em http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Inspecione os dados
Este conjunto de dados, iris_training.csv , é um arquivo de texto simples que armazena dados tabulares formatados como valores separados por vírgula (CSV). Vejamos as primeiras 5 entradas.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
A partir desta visualização do conjunto de dados, observe o seguinte:
- A primeira linha é um cabeçalho contendo informações sobre o conjunto de dados:
- Existem 120 exemplos no total. Cada exemplo possui quatro recursos e um dos três nomes de rótulo possíveis.
- As linhas subsequentes são registros de dados, um exemplo por linha, onde:
- Os primeiros quatro campos são recursos : são características de um exemplo. Aqui, os campos contêm números flutuantes que representam as medidas das flores.
- A última coluna é o rótulo : este é o valor que queremos prever. Para este conjunto de dados, é um valor inteiro de 0, 1 ou 2 que corresponde ao nome de uma flor.
Vamos escrever isso em código:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Cada rótulo está associado ao nome da string (por exemplo, "setosa"), mas o aprendizado de máquina normalmente depende de valores numéricos. Os números dos rótulos são mapeados para uma representação nomeada, como:
-
0: Íris setosa -
1: Íris versicolor -
2: Íris virgem
Para obter mais informações sobre recursos e rótulos, consulte a seção Terminologia de ML do Curso intensivo de aprendizado de máquina .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Crie um conjunto de dados usando a API Epochs
A API Epochs do Swift for TensorFlow é uma API de alto nível para ler dados e transformá-los em um formulário usado para treinamento.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Como os conjuntos de dados que baixamos estão no formato CSV, vamos escrever uma função para carregar os dados como uma lista de objetos IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Agora podemos usar a função de carregamento CSV para carregar o conjunto de dados de treinamento e criar um objeto TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
O objeto TrainingEpochs é uma sequência infinita de épocas. Cada época contém IrisBatch es. Vejamos o primeiro elemento da primeira época.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
Observe que os recursos dos primeiros exemplos batchSize são agrupados (ou agrupados em lote ) em firstTrainFeatures e que os rótulos dos primeiros exemplos batchSize são agrupados em firstTrainLabels .
Você pode começar a ver alguns clusters plotando alguns recursos do lote, usando o matplotlib do Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()

Use `print()` to show values.
Selecione o tipo de modelo
Por que modelo?
Um modelo é um relacionamento entre recursos e o rótulo. Para o problema de classificação da íris, o modelo define a relação entre as medidas das sépalas e pétalas e as espécies de íris previstas. Alguns modelos simples podem ser descritos com algumas linhas de álgebra, mas modelos complexos de aprendizado de máquina possuem um grande número de parâmetros que são difíceis de resumir.
Você poderia determinar a relação entre as quatro características e as espécies de íris sem usar aprendizado de máquina? Ou seja, você poderia usar técnicas de programação tradicionais (por exemplo, muitas instruções condicionais) para criar um modelo? Talvez – se você analisasse o conjunto de dados por tempo suficiente para determinar as relações entre as medidas das pétalas e das sépalas para uma espécie específica. E isso se torna difícil — talvez impossível — em conjuntos de dados mais complicados. Uma boa abordagem de aprendizado de máquina determina o modelo para você . Se você inserir exemplos representativos suficientes no tipo de modelo de aprendizado de máquina correto, o programa descobrirá os relacionamentos para você.
Selecione o modelo
Precisamos selecionar o tipo de modelo a treinar. Existem muitos tipos de modelos e escolher um bom exige experiência. Este tutorial usa uma rede neural para resolver o problema de classificação da íris. As redes neurais podem encontrar relações complexas entre os recursos e o rótulo. É um gráfico altamente estruturado, organizado em uma ou mais camadas ocultas . Cada camada oculta consiste em um ou mais neurônios . Existem várias categorias de redes neurais e este programa usa uma rede neural densa ou totalmente conectada : os neurônios de uma camada recebem conexões de entrada de cada neurônio da camada anterior. Por exemplo, a Figura 2 ilustra uma rede neural densa que consiste em uma camada de entrada, duas camadas ocultas e uma camada de saída:
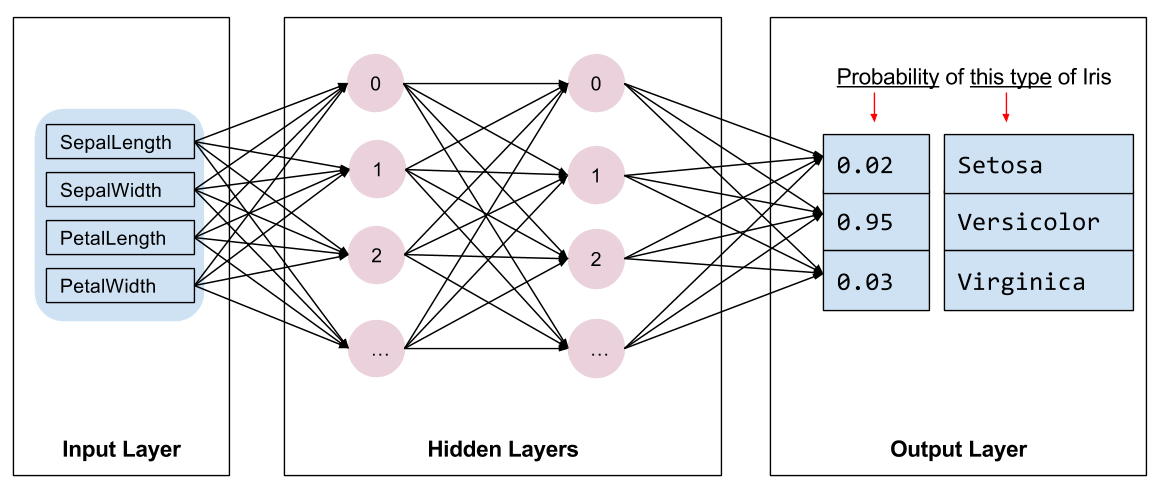 |
| Figura 2. Uma rede neural com recursos, camadas ocultas e previsões. |
Quando o modelo da Figura 2 é treinado e alimentado com um exemplo não rotulado, ele produz três previsões: a probabilidade de esta flor ser da espécie de íris fornecida. Essa previsão é chamada de inferência . Para este exemplo, a soma das previsões de saída é 1,0. Na Figura 2, essa previsão se divide em: 0.02 para Iris setosa , 0.95 para Iris versicolor e 0.03 para Iris virginica . Isso significa que o modelo prevê - com 95% de probabilidade - que um exemplo de flor não rotulado é uma Iris versicolor .
Crie um modelo usando a biblioteca Swift for TensorFlow Deep Learning
A biblioteca de aprendizado profundo Swift para TensorFlow define camadas primitivas e convenções para conectá-las, o que facilita a construção de modelos e experimentos.
Um modelo é uma struct que está em conformidade com Layer , o que significa que ele define um método callAsFunction(_:) que mapeia Tensor s de entrada para Tensor s de saída. O método callAsFunction(_:) geralmente simplesmente sequencia a entrada por meio de subcamadas. Vamos definir um IrisModel que sequencia a entrada por meio de três subcamadas Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
A função de ativação determina o formato de saída de cada nó da camada. Estas não linearidades são importantes – sem elas o modelo seria equivalente a uma única camada. Existem muitas ativações disponíveis, mas ReLU é comum para camadas ocultas.
O número ideal de camadas e neurônios ocultos depende do problema e do conjunto de dados. Como muitos aspectos do aprendizado de máquina, escolher o melhor formato da rede neural requer uma mistura de conhecimento e experimentação. Como regra geral, aumentar o número de camadas e neurônios ocultos normalmente cria um modelo mais poderoso, que requer mais dados para um treinamento eficaz.
Usando o modelo
Vamos dar uma olhada rápida no que esse modelo faz com um conjunto de recursos:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Aqui, cada exemplo retorna um logit para cada classe.
Para converter esses logits em probabilidade para cada classe, use a função softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Pegar o argmax entre classes nos dá o índice de classe previsto. Porém, o modelo ainda não foi treinado, então essas não são boas previsões.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Treine o modelo
O treinamento é o estágio do aprendizado de máquina em que o modelo é gradualmente otimizado ou o modelo aprende o conjunto de dados. O objetivo é aprender o suficiente sobre a estrutura do conjunto de dados de treinamento para fazer previsões sobre dados não vistos. Se você aprender muito sobre o conjunto de dados de treinamento, as previsões funcionarão apenas para os dados vistos e não serão generalizáveis. Esse problema é chamado de overfitting — é como memorizar as respostas em vez de entender como resolver um problema.
O problema de classificação da íris é um exemplo de aprendizado de máquina supervisionado : o modelo é treinado a partir de exemplos que contêm rótulos. No aprendizado de máquina não supervisionado , os exemplos não contêm rótulos. Em vez disso, o modelo normalmente encontra padrões entre os recursos.
Escolha uma função de perda
As etapas de treinamento e avaliação precisam calcular a perda do modelo. Isso mede o quão longe as previsões de um modelo estão do rótulo desejado, em outras palavras, o quão ruim está o desempenho do modelo. Queremos minimizar ou otimizar esse valor.
Nosso modelo calculará sua perda usando a função softmaxCrossEntropy(logits:labels:) que pega as previsões de probabilidade de classe do modelo e o rótulo desejado e retorna a perda média entre os exemplos.
Vamos calcular a perda para o modelo não treinado atual:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Crie um otimizador
Um otimizador aplica os gradientes calculados às variáveis do modelo para minimizar a função loss . Você pode pensar na função de perda como uma superfície curva (veja a Figura 3) e queremos encontrar seu ponto mais baixo caminhando por ela. Os gradientes apontam na direção da subida mais íngreme – então viajaremos na direção oposta e desceremos a colina. Calculando iterativamente a perda e o gradiente de cada lote, ajustaremos o modelo durante o treinamento. Gradualmente, o modelo encontrará a melhor combinação de pesos e vieses para minimizar a perda. E quanto menor a perda, melhores serão as previsões do modelo.
 |
| Figura 3. Algoritmos de otimização visualizados ao longo do tempo no espaço 3D. (Fonte: Stanford class CS231n , licença MIT, crédito da imagem: Alec Radford ) |
Swift for TensorFlow tem muitos algoritmos de otimização disponíveis para treinamento. Este modelo usa o otimizador SGD que implementa o algoritmo de descida gradiente estocástica (SGD). O learningRate define o tamanho do passo a ser dado para cada iteração descendo a colina. Este é um hiperparâmetro que você normalmente ajustará para obter melhores resultados.
let optimizer = SGD(for: model, learningRate: 0.01)
Vamos usar optimizer para realizar uma única etapa de descida do gradiente. Primeiro, calculamos o gradiente da perda em relação ao modelo:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
A seguir, passamos o gradiente que acabamos de calcular para o otimizador, que atualiza as variáveis diferenciáveis do modelo de acordo:
optimizer.update(&model, along: grads)
Se calcularmos a perda novamente, ela deverá ser menor, porque as etapas de descida do gradiente (geralmente) diminuem a perda:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Ciclo de treinamento
Com todas as peças no lugar, o modelo está pronto para o treino! Um loop de treinamento alimenta o modelo com exemplos de conjuntos de dados para ajudá-lo a fazer melhores previsões. O bloco de código a seguir configura estas etapas de treinamento:
- Itere em cada época . Uma época é uma passagem pelo conjunto de dados.
- Dentro de uma época, itere cada lote na época de treinamento
- Agrupe o lote e pegue seus recursos (
x) e rótulo (y). - Usando os recursos do lote agrupado, faça uma previsão e compare-a com o rótulo. Meça a imprecisão da previsão e use-a para calcular a perda e os gradientes do modelo.
- Use gradiente descendente para atualizar as variáveis do modelo.
- Acompanhe algumas estatísticas para visualização.
- Repita para cada época.
A variável epochCount é o número de vezes que deve ser feito um loop na coleção do conjunto de dados. Contra-intuitivamente, treinar um modelo por mais tempo não garante um modelo melhor. epochCount é um hiperparâmetro que você pode ajustar. Escolher o número certo geralmente requer experiência e experimentação.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
Visualize a função de perda ao longo do tempo
Embora seja útil imprimir o progresso do treinamento do modelo, muitas vezes é mais útil ver esse progresso. Podemos criar gráficos básicos usando o módulo matplotlib do Python.
Interpretar esses gráficos requer alguma experiência, mas você realmente quer ver a perda diminuir e a precisão aumentar.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()

Use `print()` to show values.
Observe que os eixos y dos gráficos não são baseados em zero.
Avalie a eficácia do modelo
Agora que o modelo está treinado, podemos obter algumas estatísticas sobre seu desempenho.
Avaliar significa determinar a eficácia com que o modelo faz previsões. Para determinar a eficácia do modelo na classificação da íris, passe algumas medidas de sépalas e pétalas para o modelo e peça ao modelo para prever quais espécies de íris elas representam. Em seguida, compare a previsão do modelo com o rótulo real. Por exemplo, um modelo que escolheu as espécies corretas em metade dos exemplos de entrada tem uma precisão de 0.5 . A Figura 4 mostra um modelo um pouco mais eficaz, obtendo 4 de 5 previsões corretas com 80% de precisão:
| Recursos de exemplo | Rótulo | Previsão do modelo | |||
|---|---|---|---|---|---|
| 5.9 | 3,0 | 4.3 | 1,5 | 1 | 1 |
| 6,9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6,0 | 3.4 | 4,5 | 1.6 | 1 | 2 |
| 5.5 | 2,5 | 4,0 | 1.3 | 1 | 1 |
| Figura 4. Um classificador de íris com 80% de precisão. | |||||
Configure o conjunto de dados de teste
Avaliar o modelo é semelhante a treiná-lo. A maior diferença é que os exemplos vêm de um conjunto de testes separado, e não do conjunto de treinamento. Para avaliar de forma justa a eficácia de um modelo, os exemplos usados para avaliar um modelo devem ser diferentes dos exemplos usados para treinar o modelo.
A configuração do conjunto de dados de teste é semelhante à configuração do conjunto de dados de treinamento. Baixe o conjunto de testes em http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Agora carregue-o em um array de IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Avalie o modelo no conjunto de dados de teste
Ao contrário do estágio de treinamento, o modelo avalia apenas uma única época dos dados de teste. Na célula de código a seguir, iteramos cada exemplo no conjunto de teste e comparamos a previsão do modelo com o rótulo real. Isso é usado para medir a precisão do modelo em todo o conjunto de testes.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
Podemos ver no primeiro lote, por exemplo, que o modelo costuma estar correto:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Use o modelo treinado para fazer previsões
Treinamos um modelo e demonstramos que ele é bom – mas não perfeito – na classificação de espécies de íris. Agora vamos usar o modelo treinado para fazer algumas previsões em exemplos não rotulados ; isto é, em exemplos que contêm recursos, mas não um rótulo.
Na vida real, os exemplos não rotulados podem vir de muitas fontes diferentes, incluindo aplicativos, arquivos CSV e feeds de dados. Por enquanto, forneceremos manualmente três exemplos não rotulados para prever seus rótulos. Lembre-se, os números dos rótulos são mapeados para uma representação nomeada como:
-
0: Íris setosa -
1: Íris versicolor -
2: Íris virgem
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])