
| | |  Zobacz źródło w GitHub Zobacz źródło w GitHub |
W tym przewodniku przedstawiono Swift dla TensorFlow poprzez utworzenie modelu uczenia maszynowego, który kategoryzuje kwiaty tęczówki według gatunku. Wykorzystuje Swift dla TensorFlow do:
- Zbuduj model,
- Trenuj ten model na przykładowych danych i
- Użyj modelu, aby dokonać przewidywań dotyczących nieznanych danych.
Programowanie TensorFlow
W tym przewodniku wykorzystano te ogólne koncepcje Swift for TensorFlow:
- Importuj dane za pomocą interfejsu API Epochs.
- Twórz modele, korzystając z abstrakcji Swift.
- Używaj bibliotek Pythona, korzystając ze współdziałania języka Swift z językiem Python, gdy nie są dostępne czyste biblioteki Swift.
Ten samouczek ma strukturę podobną do wielu programów TensorFlow:
- Importuj i analizuj zestawy danych.
- Wybierz typ modelu.
- Trenuj model.
- Oceń skuteczność modelu.
- Użyj przeszkolonego modelu, aby dokonać prognoz.
Program instalacyjny
Skonfiguruj importy
Zaimportuj TensorFlow i kilka przydatnych modułów Pythona.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
Problem klasyfikacji tęczówki
Wyobraź sobie, że jesteś botanikiem szukającym zautomatyzowanego sposobu kategoryzowania każdego znalezionego kwiatu irysa. Uczenie maszynowe udostępnia wiele algorytmów służących do statystycznej klasyfikacji kwiatów. Na przykład zaawansowany program do uczenia maszynowego mógłby klasyfikować kwiaty na podstawie zdjęć. Nasze ambicje są skromniejsze – będziemy klasyfikować kwiaty irysa na podstawie długości i szerokości działek i płatków .
Rodzaj Iris obejmuje około 300 gatunków, ale w naszym programie sklasyfikowane zostaną tylko trzy następujące:
- Irys setosa
- Iris Virginia
- Irys wielobarwny
 |
| Rycina 1. Iris setosa (autor: Radomil , CC BY-SA 3.0), Iris versicolor (autor: Dlanglois , CC BY-SA 3.0) i Iris virginica (autor: Frank Mayfield , CC BY-SA 2.0). |
Na szczęście ktoś stworzył już zbiór danych obejmujący 120 kwiatów irysa wraz z wymiarami działek i płatków. Jest to klasyczny zbiór danych popularny w przypadku problemów z klasyfikacją uczenia maszynowego dla początkujących.
Zaimportuj i przeanalizuj zestaw danych szkoleniowych
Pobierz plik zestawu danych i przekonwertuj go na strukturę, z której będzie mógł korzystać ten program Swift.
Pobierz zbiór danych
Pobierz plik zestawu danych szkoleniowych z http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Sprawdź dane
Ten zestaw danych iris_training.csv jest zwykłym plikiem tekstowym przechowującym dane tabelaryczne sformatowane jako wartości rozdzielane przecinkami (CSV). Przyjrzyjmy się pierwszym 5 wpisom.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
Z tego widoku zbioru danych zwróć uwagę na następujące kwestie:
- Pierwsza linia to nagłówek zawierający informacje o zbiorze danych:
- Łącznie jest 120 przykładów. Każdy przykład ma cztery funkcje i jedną z trzech możliwych nazw etykiet.
- Kolejne wiersze to rekordy danych, po jednym przykładzie w wierszu, gdzie:
- Pierwsze cztery pola to cechy : są to cechy przykładu. W tym przypadku pola zawierają liczby zmiennoprzecinkowe reprezentujące pomiary kwiatów.
- Ostatnia kolumna to etykieta : jest to wartość, którą chcemy przewidzieć. W przypadku tego zbioru danych jest to wartość całkowita 0, 1 lub 2 odpowiadająca nazwie kwiatu.
Zapiszmy to w kodzie:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Każda etykieta jest powiązana z nazwą ciągu (na przykład „setosa”), ale uczenie maszynowe zazwyczaj opiera się na wartościach liczbowych. Numery etykiet są odwzorowywane na nazwaną reprezentację, taką jak:
-
0: Irys setosa -
1: Irys versicolor -
2: Iris Virginia
Aby uzyskać więcej informacji na temat funkcji i etykiet, zobacz sekcję terminologii ML w przyspieszonym kursie uczenia maszynowego .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Utwórz zbiór danych za pomocą interfejsu API Epochs
Swift for TensorFlow Epochs API to interfejs API wysokiego poziomu do odczytywania danych i przekształcania ich w formę używaną do szkolenia.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Ponieważ pobrane przez nas zbiory danych są w formacie CSV, napiszmy funkcję ładującą dane w postaci listy obiektów IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Możemy teraz użyć funkcji ładowania CSV, aby załadować zestaw danych szkoleniowych i utworzyć obiekt TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
Obiekt TrainingEpochs jest nieskończoną sekwencją epok. Każda epoka zawiera IrisBatch es. Przyjrzyjmy się pierwszemu elementowi pierwszej epoki.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
Zwróć uwagę, że funkcje pierwszych przykładów batchSize są pogrupowane (lub wsadowe ) w firstTrainFeatures , a etykiety dla pierwszych przykładów batchSize są wsadowe w firstTrainLabels .
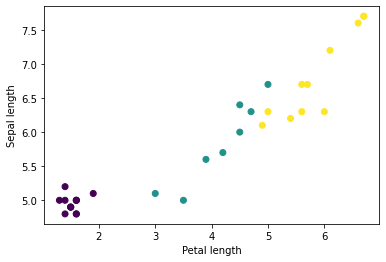
Możesz zacząć widzieć niektóre klastry, wykreślając kilka funkcji z partii, używając matplotlib Pythona:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
Use `print()` to show values.
Wybierz typ modelu
Dlaczego modelowy?
Model to relacja pomiędzy elementami a etykietą. W przypadku problemu klasyfikacji tęczówki model definiuje związek między wymiarami działek i płatków a przewidywanym gatunkiem tęczówki. Niektóre proste modele można opisać kilkoma liniami algebry, ale złożone modele uczenia maszynowego mają dużą liczbę parametrów, które trudno podsumować.
Czy możesz określić związek między czterema cechami a gatunkiem tęczówki bez korzystania z uczenia maszynowego? To znaczy, czy możesz użyć tradycyjnych technik programowania (na przykład wielu instrukcji warunkowych) do stworzenia modelu? Być może – jeśli przeanalizujesz zbiór danych wystarczająco długo, aby określić powiązania między wymiarami płatków i działek dla konkretnego gatunku. Staje się to trudne – a może niemożliwe – w przypadku bardziej skomplikowanych zbiorów danych. Dobre podejście do uczenia maszynowego określa model dla Ciebie . Jeśli do odpowiedniego typu modelu uczenia maszynowego wprowadzisz wystarczającą liczbę reprezentatywnych przykładów, program sam ustali zależności.
Wybierz model
Musimy wybrać rodzaj modelu do trenowania. Rodzajów modeli jest wiele, a wybranie dobrego wymaga doświadczenia. W tym samouczku do rozwiązania problemu klasyfikacji tęczówki wykorzystano sieć neuronową. Sieci neuronowe mogą znajdować złożone relacje między funkcjami a etykietą. Jest to wykres o dużej strukturze, podzielony na jedną lub więcej ukrytych warstw . Każda warstwa ukryta składa się z jednego lub większej liczby neuronów . Istnieje kilka kategorii sieci neuronowych, a ten program wykorzystuje gęstą lub w pełni połączoną sieć neuronową : neurony w jednej warstwie otrzymują połączenia wejściowe od każdego neuronu w poprzedniej warstwie. Na przykład rysunek 2 ilustruje gęstą sieć neuronową składającą się z warstwy wejściowej, dwóch warstw ukrytych i warstwy wyjściowej:
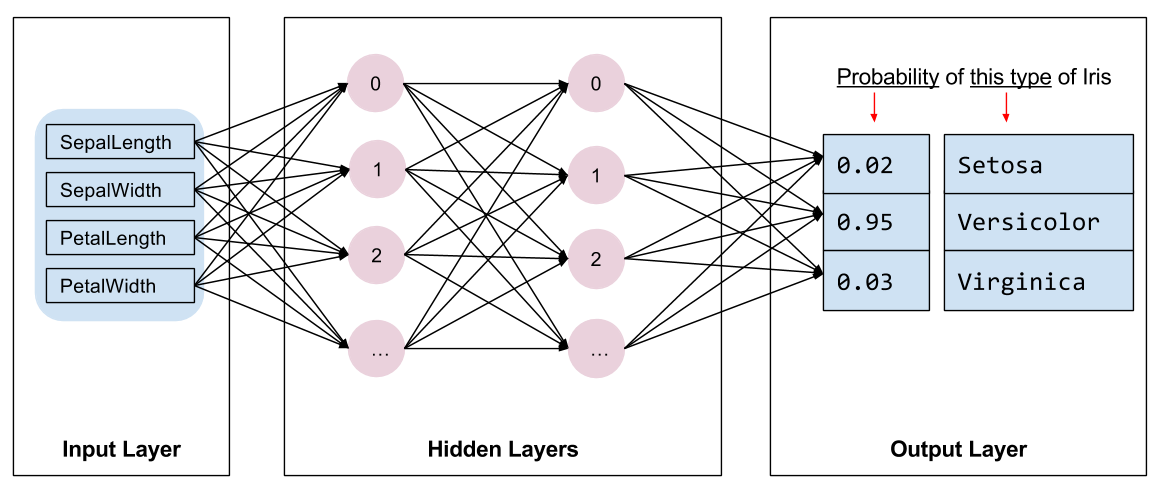 |
| Rysunek 2. Sieć neuronowa z funkcjami, ukrytymi warstwami i przewidywaniami. |
Kiedy model z rysunku 2 jest trenowany i zasilany nieopisanym przykładem, daje trzy przewidywania: prawdopodobieństwo, że ten kwiat jest danym gatunkiem irysa. To przewidywanie nazywa się wnioskowaniem . W tym przykładzie suma przewidywań wyników wynosi 1,0. Na rysunku 2 prognoza ta przedstawia się następująco: 0.02 dla Iris setosa , 0.95 dla Iris versicolor i 0.03 dla Iris virginica . Oznacza to, że model przewiduje – z prawdopodobieństwem 95% – że przykładowym kwiatem bez etykiety jest Iris versicolor .
Utwórz model, korzystając z biblioteki Swift for TensorFlow Deep Learning
Biblioteka głębokiego uczenia się Swift for TensorFlow definiuje prymitywne warstwy i konwencje ich łączenia, co ułatwia budowanie modeli i eksperymentowanie.
Model to struct zgodna z Layer , co oznacza, że definiuje metodę callAsFunction(_:) która odwzorowuje wejściowe Tensor na wyjściowe Tensor . Metoda callAsFunction(_:) często po prostu sekwencjonuje dane wejściowe przez podwarstwy. Zdefiniujmy IrisModel , który sekwencjonuje dane wejściowe przez trzy podwarstwy Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
Funkcja aktywacji określa wyjściowy kształt każdego węzła w warstwie. Te nieliniowości są istotne – bez nich model byłby odpowiednikiem pojedynczej warstwy. Dostępnych jest wiele aktywacji, ale ReLU jest wspólne dla warstw ukrytych.
Idealna liczba warstw ukrytych i neuronów zależy od problemu i zbioru danych. Podobnie jak wiele aspektów uczenia maszynowego, wybranie najlepszego kształtu sieci neuronowej wymaga połączenia wiedzy i eksperymentów. Ogólna zasada jest taka, że zwiększenie liczby ukrytych warstw i neuronów zazwyczaj tworzy potężniejszy model, który wymaga większej ilości danych do efektywnego uczenia.
Korzystanie z modelu
Rzućmy okiem na to, co ten model robi z zestawem funkcji:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Tutaj każdy przykład zwraca logit dla każdej klasy.
Aby przekonwertować te logity na prawdopodobieństwo dla każdej klasy, użyj funkcji softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Biorąc argmax między klasami, otrzymujemy przewidywany indeks klasy. Jednak model nie został jeszcze przeszkolony, więc nie są to dobre prognozy.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Trenuj model
Uczenie to etap uczenia maszynowego, podczas którego model jest stopniowo optymalizowany lub model uczy się zbioru danych. Celem jest poznanie wystarczającej wiedzy o strukturze zbioru danych szkoleniowych, aby móc przewidywać niewidoczne dane. Jeśli dowiesz się zbyt wiele o zbiorze danych szkoleniowych, przewidywania będą działać tylko w przypadku danych, które widział i nie będzie można ich uogólniać. Problem ten nazywa się nadmiernym dopasowaniem — przypomina zapamiętywanie odpowiedzi zamiast zrozumienia, jak rozwiązać problem.
Problem klasyfikacji tęczówki jest przykładem nadzorowanego uczenia maszynowego : model jest szkolony na przykładach zawierających etykiety. W przypadku nienadzorowanego uczenia maszynowego przykłady nie zawierają etykiet. Zamiast tego model zazwyczaj znajduje wzorce wśród elementów.
Wybierz funkcję straty
Zarówno etap uczenia, jak i oceny wymagają obliczenia straty modelu. Mierzy to, w jakim stopniu przewidywania modelu odbiegają od pożądanej etykiety, innymi słowy, jak źle radzi sobie model. Chcemy zminimalizować lub zoptymalizować tę wartość.
Nasz model obliczy stratę za pomocą funkcji softmaxCrossEntropy(logits:labels:) która pobiera przewidywania prawdopodobieństwa klasy modelu i żądaną etykietę, a następnie zwraca średnią stratę w przykładach.
Obliczmy stratę dla bieżącego, nieprzetrenowanego modelu:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Utwórz optymalizator
Optymalizator stosuje obliczone gradienty do zmiennych modelu, aby zminimalizować funkcję loss . Można myśleć o funkcji straty jak o zakrzywionej powierzchni (patrz rysunek 3), a my chcemy znaleźć jej najniższy punkt, spacerując. Nachylenie wskazuje w kierunku najbardziej stromego podjazdu – więc pojedziemy w przeciwnym kierunku i zejdziemy w dół. Iteracyjnie obliczając stratę i gradient dla każdej partii, dostosujemy model podczas uczenia. Stopniowo model znajdzie najlepszą kombinację wag i odchylenia, aby zminimalizować straty. Im mniejsza strata, tym lepsze przewidywania modelu.
 |
| Rysunek 3. Algorytmy optymalizacji wizualizowane w czasie w przestrzeni 3D. (Źródło: klasa Stanford CS231n , licencja MIT, zdjęcie: Alec Radford ) |
Swift dla TensorFlow ma wiele algorytmów optymalizacyjnych dostępnych do szkolenia. Model ten wykorzystuje optymalizator SGD, który implementuje algorytm stochastycznego gradientu opadania (SGD). learningRate ustawia rozmiar kroku, który należy wykonać dla każdej iteracji w dół. Jest to hiperparametr , który często będziesz dostosowywać, aby uzyskać lepsze wyniki.
let optimizer = SGD(for: model, learningRate: 0.01)
Użyjmy optimizer , aby wykonać pojedynczy krok opadania gradientu. Najpierw obliczamy gradient straty względem modelu:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
Następnie przekazujemy obliczony gradient do optymalizatora, który odpowiednio aktualizuje zmienne różniczkowe modelu:
optimizer.update(&model, along: grads)
Jeśli ponownie obliczymy stratę, powinna ona być mniejsza, ponieważ stopniowe opadanie gradientu (zwykle) zmniejsza stratę:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Pętla treningowa
Gdy wszystkie elementy są na swoim miejscu, model jest gotowy do treningu! Pętla szkoleniowa wprowadza przykłady zestawu danych do modelu, co pomaga w tworzeniu lepszych przewidywań. Poniższy blok kodu konfiguruje następujące kroki szkoleniowe:
- Iteruj po każdej epoce . Epoka to jedno przejście przez zbiór danych.
- W obrębie epoki wykonaj iterację po każdej partii w epoce szkoleniowej
- Zbierz partię i pobierz jej funkcje (
x) i etykietę (y). - Korzystając z cech zebranej partii, dokonaj prognozy i porównaj ją z etykietą. Zmierz niedokładność prognozy i wykorzystaj ją do obliczenia strat i gradientów modelu.
- Użyj opadania gradientu, aby zaktualizować zmienne modelu.
- Śledź niektóre statystyki w celu wizualizacji.
- Powtórz dla każdej epoki.
Zmienna epochCount określa liczbę pętli w zbiorze danych. Wbrew intuicji dłuższe szkolenie modelu nie gwarantuje lepszego modelu. epochCount to hiperparametr , który można dostroić. Wybór właściwej liczby zwykle wymaga zarówno doświadczenia, jak i eksperymentowania.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
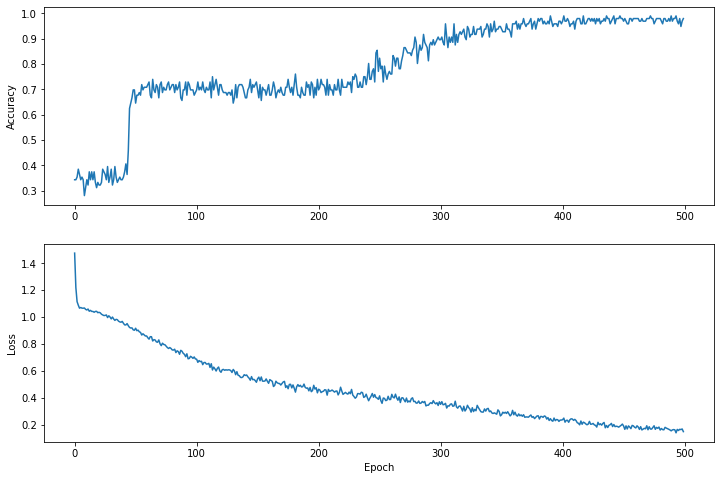
Wizualizuj funkcję straty w czasie
Chociaż pomocne jest wydrukowanie postępu uczenia się modelu, często bardziej pomocne jest obserwowanie tego postępu. Podstawowe wykresy możemy tworzyć za pomocą modułu matplotlib Pythona.
Interpretacja tych wykresów wymaga pewnego doświadczenia, ale naprawdę chcesz zobaczyć, jak straty maleją, a dokładność wzrasta.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
Use `print()` to show values.
Należy zauważyć, że oś Y wykresów nie jest oparta na zerach.
Oceń skuteczność modelu
Teraz, gdy model został już przeszkolony, możemy uzyskać statystyki dotyczące jego wydajności.
Ocena oznacza określenie, jak skutecznie model formułuje prognozy. Aby określić skuteczność modelu w klasyfikacji tęczówki, przekaż do modelu pomiary działek i płatków i poproś model o przewidzenie, jaki gatunek tęczówki reprezentują. Następnie porównaj przewidywania modelu z rzeczywistą etykietą. Na przykład model, który wybrał właściwy gatunek na połowie przykładów wejściowych, ma dokładność 0.5 . Rysunek 4 przedstawia nieco bardziej efektywny model, w którym 4 z 5 przewidywań jest poprawnych przy 80% dokładności:
| Przykładowe funkcje | Etykieta | Przewidywanie modelu | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1,5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6,0 | 3.4 | 4,5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4,0 | 1.3 | 1 | 1 |
| Rysunek 4. Klasyfikator tęczówki o dokładności 80%. | |||||
Skonfiguruj testowy zestaw danych
Ocena modelu jest podobna do uczenia modelu. Największą różnicą jest to, że przykłady pochodzą z osobnego zestawu testowego , a nie ze zbioru szkoleniowego. Aby rzetelnie ocenić skuteczność modelu, przykłady użyte do oceny modelu muszą różnić się od przykładów użytych do uczenia modelu.
Konfiguracja testowego zbioru danych jest podobna do konfiguracji szkoleniowego zbioru danych. Pobierz zestaw testowy z http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Teraz załaduj go do tablicy plików IrisBatch :
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Oceń model na testowym zestawie danych
W przeciwieństwie do etapu uczenia, model ocenia tylko jedną epokę danych testowych. W poniższej komórce kodu iterujemy po każdym przykładzie w zestawie testowym i porównujemy przewidywania modelu z rzeczywistą etykietą. Służy do pomiaru dokładności modelu w całym zestawie testowym.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
Już na pierwszej partii widzimy np., że model jest zazwyczaj poprawny:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Użyj przeszkolonego modelu, aby dokonać prognoz
Wytrenowaliśmy model i wykazaliśmy, że jest on dobry – choć nie doskonały – w klasyfikacji gatunków tęczówki. Teraz użyjmy przeszkolonego modelu, aby dokonać pewnych przewidywań na przykładach bez etykiet ; to znaczy na przykładach, które zawierają funkcje, ale nie etykietę.
W rzeczywistości nieoznaczone przykłady mogą pochodzić z wielu różnych źródeł, w tym aplikacji, plików CSV i kanałów danych. Na razie ręcznie udostępnimy trzy przykłady bez etykiet, aby przewidzieć ich etykiety. Przypomnijmy, że numery etykiet są odwzorowywane na nazwaną reprezentację jako:
-
0: Irys setosa -
1: Irys versicolor -
2: Iris Virginia
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])