
| | |  Visualizza la fonte su GitHub Visualizza la fonte su GitHub |
Questa guida introduce Swift per TensorFlow creando un modello di apprendimento automatico che classifica i fiori di iris in base alla specie. Utilizza Swift per TensorFlow per:
- Costruisci un modello,
- Addestra questo modello su dati di esempio e
- Utilizza il modello per fare previsioni su dati sconosciuti.
Programmazione TensorFlow
Questa guida utilizza questi concetti di alto livello di Swift per TensorFlow:
- Importa dati con l'API Epochs.
- Costruisci modelli utilizzando le astrazioni Swift.
- Utilizza le librerie Python utilizzando l'interoperabilità Python di Swift quando le librerie Swift pure non sono disponibili.
Questo tutorial è strutturato come molti programmi TensorFlow:
- Importa e analizza i set di dati.
- Seleziona il tipo di modello.
- Addestra il modello.
- Valutare l'efficacia del modello.
- Utilizzare il modello addestrato per fare previsioni.
Programma di installazione
Configura le importazioni
Importa TensorFlow e alcuni utili moduli Python.
import TensorFlow
import PythonKit
// This cell is here to display the plots in a Jupyter Notebook.
// Do not copy it into another environment.
%include "EnableIPythonDisplay.swift"
print(IPythonDisplay.shell.enable_matplotlib("inline"))
('inline', 'module://ipykernel.pylab.backend_inline')
let plt = Python.import("matplotlib.pyplot")
import Foundation
import FoundationNetworking
func download(from sourceString: String, to destinationString: String) {
let source = URL(string: sourceString)!
let destination = URL(fileURLWithPath: destinationString)
let data = try! Data.init(contentsOf: source)
try! data.write(to: destination)
}
Il problema della classificazione dell'iride
Immagina di essere un botanico alla ricerca di un modo automatizzato per classificare ogni fiore di iris che trovi. L’apprendimento automatico fornisce molti algoritmi per classificare statisticamente i fiori. Ad esempio, un sofisticato programma di apprendimento automatico potrebbe classificare i fiori sulla base di fotografie. Le nostre ambizioni sono più modeste: classificheremo i fiori di iris in base alle misure di lunghezza e larghezza dei loro sepali e petali .
Il genere Iris comprende circa 300 specie, ma il nostro programma classificherà solo le seguenti tre:
- Iris setosa
- Iris virginica
- Iris versicolor
 |
| Figura 1. Iris setosa (di Radomil , CC BY-SA 3.0), Iris versicolor , (di Dlanglois , CC BY-SA 3.0) e Iris virginica (di Frank Mayfield , CC BY-SA 2.0). |
Fortunatamente qualcuno ha già creato un set di dati di 120 fiori di iris con le misurazioni dei sepali e dei petali. Si tratta di un set di dati classico, popolare per i problemi di classificazione del machine learning per principianti.
Importa e analizza il set di dati di addestramento
Scarica il file del set di dati e convertilo in una struttura che può essere utilizzata da questo programma Swift.
Scarica il set di dati
Scarica il file del set di dati di addestramento da http://download.tensorflow.org/data/iris_training.csv
let trainDataFilename = "iris_training.csv"
download(from: "http://download.tensorflow.org/data/iris_training.csv", to: trainDataFilename)
Ispezionare i dati
Questo set di dati, iris_training.csv , è un file di testo semplice che memorizza dati tabulari formattati come valori separati da virgole (CSV). Diamo un'occhiata alle prime 5 voci.
let f = Python.open(trainDataFilename)
for _ in 0..<5 {
print(Python.next(f).strip())
}
print(f.close())
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0 None
Da questa vista del set di dati, notare quanto segue:
- La prima riga è un'intestazione contenente informazioni sul set di dati:
- Ci sono 120 esempi totali. Ogni esempio ha quattro caratteristiche e uno dei tre possibili nomi di etichetta.
- Le righe successive sono record di dati, un esempio per riga, dove:
- I primi quattro campi sono caratteristiche : queste sono le caratteristiche di un esempio. Qui, i campi contengono numeri float che rappresentano le misurazioni dei fiori.
- L'ultima colonna è l' etichetta : questo è il valore che vogliamo prevedere. Per questo set di dati è un valore intero pari a 0, 1 o 2 che corrisponde al nome di un fiore.
Scriviamolo nel codice:
let featureNames = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
let labelName = "species"
let columnNames = featureNames + [labelName]
print("Features: \(featureNames)")
print("Label: \(labelName)")
Features: ["sepal_length", "sepal_width", "petal_length", "petal_width"] Label: species
Ogni etichetta è associata al nome della stringa (ad esempio "setosa"), ma l'apprendimento automatico si basa in genere su valori numerici. I numeri delle etichette vengono mappati su una rappresentazione denominata, ad esempio:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virginica
Per ulteriori informazioni su funzionalità ed etichette, vedere la sezione Terminologia ML del corso accelerato di Machine Learning .
let classNames = ["Iris setosa", "Iris versicolor", "Iris virginica"]
Crea un set di dati utilizzando l'API Epochs
L'API Epochs di Swift per TensorFlow è un'API di alto livello per leggere i dati e trasformarli in un modulo utilizzato per l'addestramento.
let batchSize = 32
/// A batch of examples from the iris dataset.
struct IrisBatch {
/// [batchSize, featureCount] tensor of features.
let features: Tensor<Float>
/// [batchSize] tensor of labels.
let labels: Tensor<Int32>
}
/// Conform `IrisBatch` to `Collatable` so that we can load it into a `TrainingEpoch`.
extension IrisBatch: Collatable {
public init<BatchSamples: Collection>(collating samples: BatchSamples)
where BatchSamples.Element == Self {
/// `IrisBatch`es are collated by stacking their feature and label tensors
/// along the batch axis to produce a single feature and label tensor
features = Tensor<Float>(stacking: samples.map{$0.features})
labels = Tensor<Int32>(stacking: samples.map{$0.labels})
}
}
Poiché i set di dati che abbiamo scaricato sono in formato CSV, scriviamo una funzione per caricare i dati come elenco di oggetti IrisBatch
/// Initialize an `IrisBatch` dataset from a CSV file.
func loadIrisDatasetFromCSV(
contentsOf: String, hasHeader: Bool, featureColumns: [Int], labelColumns: [Int]) -> [IrisBatch] {
let np = Python.import("numpy")
let featuresNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: featureColumns,
dtype: Float.numpyScalarTypes.first!)
guard let featuresTensor = Tensor<Float>(numpy: featuresNp) else {
// This should never happen, because we construct featuresNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
let labelsNp = np.loadtxt(
contentsOf,
delimiter: ",",
skiprows: hasHeader ? 1 : 0,
usecols: labelColumns,
dtype: Int32.numpyScalarTypes.first!)
guard let labelsTensor = Tensor<Int32>(numpy: labelsNp) else {
// This should never happen, because we construct labelsNp in such a
// way that it should be convertible to tensor.
fatalError("np.loadtxt result can't be converted to Tensor")
}
return zip(featuresTensor.unstacked(), labelsTensor.unstacked()).map{IrisBatch(features: $0.0, labels: $0.1)}
}
Ora possiamo utilizzare la funzione di caricamento CSV per caricare il set di dati di training e creare un oggetto TrainingEpochs
let trainingDataset: [IrisBatch] = loadIrisDatasetFromCSV(contentsOf: trainDataFilename,
hasHeader: true,
featureColumns: [0, 1, 2, 3],
labelColumns: [4])
let trainingEpochs: TrainingEpochs = TrainingEpochs(samples: trainingDataset, batchSize: batchSize)
L'oggetto TrainingEpochs è una sequenza infinita di epoche. Ogni epoca contiene IrisBatch es. Diamo un'occhiata al primo elemento della prima epoca.
let firstTrainEpoch = trainingEpochs.next()!
let firstTrainBatch = firstTrainEpoch.first!.collated
let firstTrainFeatures = firstTrainBatch.features
let firstTrainLabels = firstTrainBatch.labels
print("First batch of features: \(firstTrainFeatures)")
print("firstTrainFeatures.shape: \(firstTrainFeatures.shape)")
print("First batch of labels: \(firstTrainLabels)")
print("firstTrainLabels.shape: \(firstTrainLabels.shape)")
First batch of features: [[5.1, 2.5, 3.0, 1.1], [6.4, 3.2, 4.5, 1.5], [4.9, 3.1, 1.5, 0.1], [5.0, 2.0, 3.5, 1.0], [6.3, 2.5, 5.0, 1.9], [6.7, 3.1, 5.6, 2.4], [4.9, 3.1, 1.5, 0.1], [7.7, 2.8, 6.7, 2.0], [6.7, 3.0, 5.0, 1.7], [7.2, 3.6, 6.1, 2.5], [4.8, 3.0, 1.4, 0.1], [5.2, 3.4, 1.4, 0.2], [5.0, 3.5, 1.3, 0.3], [4.9, 3.1, 1.5, 0.1], [5.0, 3.5, 1.6, 0.6], [6.7, 3.3, 5.7, 2.1], [7.7, 3.8, 6.7, 2.2], [6.2, 3.4, 5.4, 2.3], [4.8, 3.4, 1.6, 0.2], [6.0, 2.9, 4.5, 1.5], [5.0, 3.0, 1.6, 0.2], [6.3, 3.4, 5.6, 2.4], [5.1, 3.8, 1.9, 0.4], [4.8, 3.1, 1.6, 0.2], [7.6, 3.0, 6.6, 2.1], [5.7, 3.0, 4.2, 1.2], [6.3, 3.3, 6.0, 2.5], [5.6, 2.5, 3.9, 1.1], [5.0, 3.4, 1.6, 0.4], [6.1, 3.0, 4.9, 1.8], [5.0, 3.3, 1.4, 0.2], [6.3, 3.3, 4.7, 1.6]] firstTrainFeatures.shape: [32, 4] First batch of labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1] firstTrainLabels.shape: [32]
Si noti che le funzionalità per i primi esempi batchSize sono raggruppate insieme (o raggruppate in batch ) in firstTrainFeatures e che le etichette per i primi esempi batchSize sono raggruppate in batch in firstTrainLabels .
Puoi iniziare a vedere alcuni cluster tracciando alcune funzionalità dal batch, utilizzando matplotlib di Python:
let firstTrainFeaturesTransposed = firstTrainFeatures.transposed()
let petalLengths = firstTrainFeaturesTransposed[2].scalars
let sepalLengths = firstTrainFeaturesTransposed[0].scalars
plt.scatter(petalLengths, sepalLengths, c: firstTrainLabels.array.scalars)
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
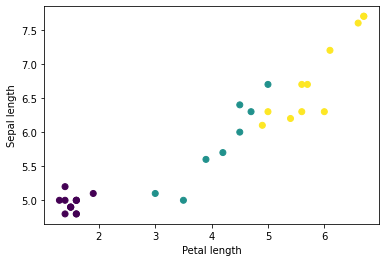
Use `print()` to show values.
Seleziona il tipo di modello
Perché modellare?
Un modello è una relazione tra le caratteristiche e l'etichetta. Per il problema della classificazione dell'iride, il modello definisce la relazione tra le misurazioni dei sepali e dei petali e le specie di iride previste. Alcuni modelli semplici possono essere descritti con poche righe di algebra, ma i modelli complessi di machine learning hanno un gran numero di parametri difficili da riassumere.
Potresti determinare la relazione tra le quattro caratteristiche e le specie di iride senza utilizzare l'apprendimento automatico? Cioè, potresti usare le tecniche di programmazione tradizionali (ad esempio, molte istruzioni condizionali) per creare un modello? Forse, se analizzassi il set di dati abbastanza a lungo da determinare le relazioni tra le misurazioni dei petali e dei sepali per una specie particolare. E questo diventa difficile, forse impossibile, su set di dati più complicati. Un buon approccio di machine learning determina il modello adatto a te . Se inserisci un numero sufficiente di esempi rappresentativi nel giusto tipo di modello di machine learning, il programma scoprirà le relazioni per te.
Seleziona il modello
Dobbiamo selezionare il tipo di modello da addestrare. Esistono molti tipi di modelli e sceglierne uno buono richiede esperienza. Questo tutorial utilizza una rete neurale per risolvere il problema della classificazione dell'iride. Le reti neurali possono trovare relazioni complesse tra le caratteristiche e l'etichetta. È un grafico altamente strutturato, organizzato in uno o più livelli nascosti . Ogni strato nascosto è costituito da uno o più neuroni . Esistono diverse categorie di reti neurali e questo programma utilizza una rete neurale densa o completamente connessa : i neuroni di uno strato ricevono connessioni di input da ogni neurone dello strato precedente. Ad esempio, la Figura 2 illustra una fitta rete neurale composta da uno strato di input, due strati nascosti e uno strato di output:
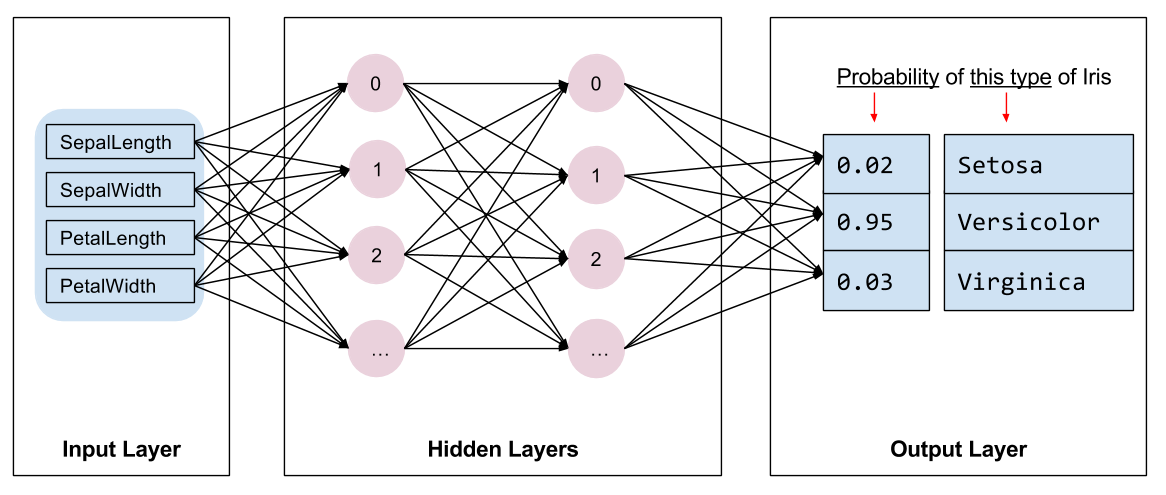 |
| Figura 2. Una rete neurale con funzionalità, livelli nascosti e previsioni. |
Quando il modello della Figura 2 viene addestrato e alimentato con un esempio senza etichetta, produce tre previsioni: la probabilità che questo fiore sia della specie di iris specificata. Questa previsione è chiamata inferenza . Per questo esempio, la somma delle previsioni di output è 1,0. Nella Figura 2, questa previsione è suddivisa in: 0.02 per Iris setosa , 0.95 per Iris versicolor e 0.03 per Iris virginica . Ciò significa che il modello prevede, con una probabilità del 95%, che un fiore di esempio senza etichetta sia un Iris versicolor .
Crea un modello utilizzando la libreria di deep learning di Swift per TensorFlow
La libreria di deep learning di Swift per TensorFlow definisce livelli primitivi e convenzioni per collegarli insieme, semplificando la creazione di modelli e la sperimentazione.
Un modello è una struct conforme a Layer , il che significa che definisce un metodo callAsFunction(_:) che associa Tensor di input ai Tensor di output. Il metodo callAsFunction(_:) spesso sequenzia semplicemente l'input attraverso i sottolivelli. Definiamo un IrisModel che sequenzia l'input attraverso tre sottolivelli Dense .
import TensorFlow
let hiddenSize: Int = 10
struct IrisModel: Layer {
var layer1 = Dense<Float>(inputSize: 4, outputSize: hiddenSize, activation: relu)
var layer2 = Dense<Float>(inputSize: hiddenSize, outputSize: hiddenSize, activation: relu)
var layer3 = Dense<Float>(inputSize: hiddenSize, outputSize: 3)
@differentiable
func callAsFunction(_ input: Tensor<Float>) -> Tensor<Float> {
return input.sequenced(through: layer1, layer2, layer3)
}
}
var model = IrisModel()
La funzione di attivazione determina la forma di output di ciascun nodo nel livello. Queste non linearità sono importanti: senza di esse il modello equivarrebbe a un singolo strato. Sono disponibili molte attivazioni, ma ReLU è comune per i livelli nascosti.
Il numero ideale di strati e neuroni nascosti dipende dal problema e dal set di dati. Come molti aspetti dell’apprendimento automatico, scegliere la forma migliore della rete neurale richiede un mix di conoscenza e sperimentazione. Come regola generale, l’aumento del numero di strati e neuroni nascosti crea in genere un modello più potente, che richiede più dati per un addestramento efficace.
Utilizzando il modello
Diamo una rapida occhiata a ciò che questo modello fa a una serie di funzionalità:
// Apply the model to a batch of features.
let firstTrainPredictions = model(firstTrainFeatures)
print(firstTrainPredictions[0..<5])
[[ 1.1514063, -0.7520321, -0.6730235], [ 1.4915676, -0.9158071, -0.9957161], [ 1.0549936, -0.7799266, -0.410466], [ 1.1725322, -0.69009197, -0.8345413], [ 1.4870572, -0.8644099, -1.0958937]]
Qui, ogni esempio restituisce un logit per ogni classe.
Per convertire questi logit in una probabilità per ciascuna classe, utilizzare la funzione softmax :
print(softmax(firstTrainPredictions[0..<5]))
[[ 0.7631462, 0.11375094, 0.123102814], [ 0.8523791, 0.076757915, 0.07086295], [ 0.7191151, 0.11478964, 0.16609532], [ 0.77540654, 0.12039323, 0.10420021], [ 0.8541314, 0.08133837, 0.064530246]]
Prendendo l' argmax tra le classi otteniamo l'indice della classe previsto. Ma il modello non è stato ancora addestrato, quindi queste non sono buone previsioni.
print("Prediction: \(firstTrainPredictions.argmax(squeezingAxis: 1))")
print(" Labels: \(firstTrainLabels)")
Prediction: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Labels: [1, 1, 0, 1, 2, 2, 0, 2, 1, 2, 0, 0, 0, 0, 0, 2, 2, 2, 0, 1, 0, 2, 0, 0, 2, 1, 2, 1, 0, 2, 0, 1]
Addestra il modello
L'addestramento è la fase dell'apprendimento automatico in cui il modello viene gradualmente ottimizzato o il modello apprende il set di dati. L'obiettivo è apprendere abbastanza sulla struttura del set di dati di addestramento per fare previsioni sui dati invisibili. Se impari troppo sul set di dati di addestramento, le previsioni funzioneranno solo per i dati visualizzati e non saranno generalizzabili. Questo problema si chiama overfitting : è come memorizzare le risposte invece di capire come risolvere un problema.
Il problema della classificazione dell'iride è un esempio di apprendimento automatico supervisionato : il modello viene addestrato da esempi che contengono etichette. Nell'apprendimento automatico non supervisionato , gli esempi non contengono etichette. Invece, il modello in genere trova modelli tra le funzionalità.
Scegli una funzione di perdita
Sia le fasi di formazione che quelle di valutazione devono calcolare la perdita del modello. Questo misura quanto le previsioni di un modello si discostano dall'etichetta desiderata, in altre parole, quanto sono scarse le prestazioni del modello. Vogliamo ridurre al minimo o ottimizzare questo valore.
Il nostro modello calcolerà la sua perdita utilizzando la funzione softmaxCrossEntropy(logits:labels:) che prende le previsioni di probabilità della classe del modello e l'etichetta desiderata e restituisce la perdita media negli esempi.
Calcoliamo la perdita per l'attuale modello non addestrato:
let untrainedLogits = model(firstTrainFeatures)
let untrainedLoss = softmaxCrossEntropy(logits: untrainedLogits, labels: firstTrainLabels)
print("Loss test: \(untrainedLoss)")
Loss test: 1.7598655
Crea un ottimizzatore
Un ottimizzatore applica i gradienti calcolati alle variabili del modello per ridurre al minimo la funzione loss . Puoi pensare alla funzione di perdita come a una superficie curva (vedi Figura 3) e noi vogliamo trovare il suo punto più basso camminandovi intorno. Le pendenze puntano nella direzione della salita più ripida, quindi viaggeremo nella direzione opposta e scenderemo dalla collina. Calcolando iterativamente la perdita e il gradiente per ciascun lotto, regoleremo il modello durante l'addestramento. A poco a poco, il modello troverà la migliore combinazione di pesi e distorsioni per ridurre al minimo le perdite. E minore è la perdita, migliori saranno le previsioni del modello.
 |
| Figura 3. Algoritmi di ottimizzazione visualizzati nel tempo nello spazio 3D. (Fonte: Stanford classe CS231n , licenza MIT, credito immagine: Alec Radford ) |
Swift per TensorFlow dispone di numerosi algoritmi di ottimizzazione disponibili per l'addestramento. Questo modello utilizza l'ottimizzatore SGD che implementa l'algoritmo SGD ( stochastic gradient descend ). Il learningRate imposta la dimensione del passo da compiere per ogni iterazione in discesa. Si tratta di un iperparametro che verrà comunemente modificato per ottenere risultati migliori.
let optimizer = SGD(for: model, learningRate: 0.01)
Usiamo optimizer per eseguire un singolo passaggio di discesa del gradiente. Per prima cosa calcoliamo il gradiente della perdita rispetto al modello:
let (loss, grads) = valueWithGradient(at: model) { model -> Tensor<Float> in
let logits = model(firstTrainFeatures)
return softmaxCrossEntropy(logits: logits, labels: firstTrainLabels)
}
print("Current loss: \(loss)")
Current loss: 1.7598655
Successivamente, passiamo il gradiente che abbiamo appena calcolato all'ottimizzatore, che aggiorna di conseguenza le variabili differenziabili del modello:
optimizer.update(&model, along: grads)
Se calcoliamo nuovamente la perdita, dovrebbe essere inferiore, perché i passaggi di discesa del gradiente (di solito) diminuiscono la perdita:
let logitsAfterOneStep = model(firstTrainFeatures)
let lossAfterOneStep = softmaxCrossEntropy(logits: logitsAfterOneStep, labels: firstTrainLabels)
print("Next loss: \(lossAfterOneStep)")
Next loss: 1.5318773
Ciclo di allenamento
Con tutti i pezzi a posto, il modello è pronto per l'allenamento! Un ciclo di addestramento inserisce gli esempi di set di dati nel modello per aiutarlo a fare previsioni migliori. Il seguente blocco di codice imposta questi passaggi di training:
- Iterare su ogni epoca . Un'epoca è un passaggio attraverso il set di dati.
- All'interno di un'epoca, ripetere ogni batch nell'epoca di addestramento
- Raccogli il batch e prendi le sue caratteristiche (
x) ed etichetta (y). - Utilizzando le funzionalità del batch fascicolato, fai una previsione e confrontala con l'etichetta. Misura l'imprecisione della previsione e utilizzala per calcolare la perdita e i gradienti del modello.
- Utilizza la discesa del gradiente per aggiornare le variabili del modello.
- Tieni traccia di alcune statistiche per la visualizzazione.
- Ripetere per ogni epoca.
La variabile epochCount è il numero di volte in cui ripetere la raccolta del set di dati. Controintuitivamente, l'addestramento di un modello più a lungo non garantisce un modello migliore. epochCount è un iperparametro che puoi ottimizzare. Scegliere il numero giusto di solito richiede sia esperienza che sperimentazione.
let epochCount = 500
var trainAccuracyResults: [Float] = []
var trainLossResults: [Float] = []
func accuracy(predictions: Tensor<Int32>, truths: Tensor<Int32>) -> Float {
return Tensor<Float>(predictions .== truths).mean().scalarized()
}
for (epochIndex, epoch) in trainingEpochs.prefix(epochCount).enumerated() {
var epochLoss: Float = 0
var epochAccuracy: Float = 0
var batchCount: Int = 0
for batchSamples in epoch {
let batch = batchSamples.collated
let (loss, grad) = valueWithGradient(at: model) { (model: IrisModel) -> Tensor<Float> in
let logits = model(batch.features)
return softmaxCrossEntropy(logits: logits, labels: batch.labels)
}
optimizer.update(&model, along: grad)
let logits = model(batch.features)
epochAccuracy += accuracy(predictions: logits.argmax(squeezingAxis: 1), truths: batch.labels)
epochLoss += loss.scalarized()
batchCount += 1
}
epochAccuracy /= Float(batchCount)
epochLoss /= Float(batchCount)
trainAccuracyResults.append(epochAccuracy)
trainLossResults.append(epochLoss)
if epochIndex % 50 == 0 {
print("Epoch \(epochIndex): Loss: \(epochLoss), Accuracy: \(epochAccuracy)")
}
}
Epoch 0: Loss: 1.475254, Accuracy: 0.34375 Epoch 50: Loss: 0.91668004, Accuracy: 0.6458333 Epoch 100: Loss: 0.68662673, Accuracy: 0.6979167 Epoch 150: Loss: 0.540665, Accuracy: 0.6979167 Epoch 200: Loss: 0.46283028, Accuracy: 0.6979167 Epoch 250: Loss: 0.4134724, Accuracy: 0.8229167 Epoch 300: Loss: 0.35054502, Accuracy: 0.8958333 Epoch 350: Loss: 0.2731444, Accuracy: 0.9375 Epoch 400: Loss: 0.23622067, Accuracy: 0.96875 Epoch 450: Loss: 0.18956228, Accuracy: 0.96875
Visualizza la funzione di perdita nel tempo
Anche se è utile stampare i progressi dell'addestramento del modello, spesso è più utile visualizzarli. Possiamo creare grafici di base utilizzando il modulo matplotlib di Python.
Interpretare questi grafici richiede una certa esperienza, ma vorrai davvero vedere la perdita diminuire e la precisione aumentare.
plt.figure(figsize: [12, 8])
let accuracyAxes = plt.subplot(2, 1, 1)
accuracyAxes.set_ylabel("Accuracy")
accuracyAxes.plot(trainAccuracyResults)
let lossAxes = plt.subplot(2, 1, 2)
lossAxes.set_ylabel("Loss")
lossAxes.set_xlabel("Epoch")
lossAxes.plot(trainLossResults)
plt.show()
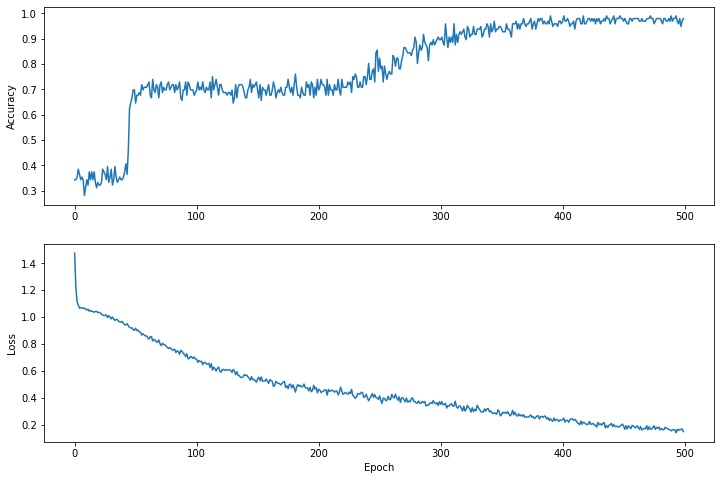
Use `print()` to show values.
Si noti che gli assi y dei grafici non sono a base zero.
Valutare l'efficacia del modello
Ora che il modello è addestrato, possiamo ottenere alcune statistiche sulle sue prestazioni.
Valutare significa determinare l’efficacia con cui il modello fa previsioni. Per determinare l'efficacia del modello nella classificazione dell'iride, passare alcune misurazioni dei sepali e dei petali al modello e chiedere al modello di prevedere quali specie di iride rappresentano. Quindi confrontare la previsione del modello con l'etichetta effettiva. Ad esempio, un modello che ha scelto la specie corretta sulla metà degli esempi di input ha una precisione di 0.5 . La Figura 4 mostra un modello leggermente più efficace, che ottiene 4 previsioni su 5 corrette con una precisione dell'80%:
| Funzionalità di esempio | Etichetta | Previsione del modello | |||
|---|---|---|---|---|---|
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0,5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
| Figura 4. Un classificatore dell'iride accurato all'80%. | |||||
Configura il set di dati di prova
La valutazione del modello è simile all'addestramento del modello. La differenza più grande è che gli esempi provengono da un set di test separato anziché dal set di training. Per valutare equamente l'efficacia di un modello, gli esempi utilizzati per valutare un modello devono essere diversi dagli esempi utilizzati per addestrare il modello.
La configurazione del set di dati di test è simile alla configurazione del set di dati di training. Scarica il set di test da http://download.tensorflow.org/data/iris_test.csv :
let testDataFilename = "iris_test.csv"
download(from: "http://download.tensorflow.org/data/iris_test.csv", to: testDataFilename)
Ora caricalo in un array di IrisBatch es:
let testDataset = loadIrisDatasetFromCSV(
contentsOf: testDataFilename, hasHeader: true,
featureColumns: [0, 1, 2, 3], labelColumns: [4]).inBatches(of: batchSize)
Valutare il modello sul set di dati di test
A differenza della fase di training, il modello valuta solo una singola epoca dei dati di test. Nella cella di codice seguente, iteriamo su ogni esempio nel set di test e confrontiamo la previsione del modello con l'etichetta effettiva. Viene utilizzato per misurare l'accuratezza del modello nell'intero set di test.
// NOTE: Only a single batch will run in the loop since the batchSize we're using is larger than the test set size
for batchSamples in testDataset {
let batch = batchSamples.collated
let logits = model(batch.features)
let predictions = logits.argmax(squeezingAxis: 1)
print("Test batch accuracy: \(accuracy(predictions: predictions, truths: batch.labels))")
}
Test batch accuracy: 0.96666664
Possiamo vedere nel primo lotto, ad esempio, che il modello è solitamente corretto:
let firstTestBatch = testDataset.first!.collated
let firstTestBatchLogits = model(firstTestBatch.features)
let firstTestBatchPredictions = firstTestBatchLogits.argmax(squeezingAxis: 1)
print(firstTestBatchPredictions)
print(firstTestBatch.labels)
[1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 2, 1, 1, 0, 1, 2, 1] [1, 2, 0, 1, 1, 1, 0, 2, 1, 2, 2, 0, 2, 1, 1, 0, 1, 0, 0, 2, 0, 1, 2, 1, 1, 1, 0, 1, 2, 1]
Utilizzare il modello addestrato per fare previsioni
Abbiamo addestrato un modello e dimostrato che è efficace, ma non perfetto, nel classificare le specie di iris. Usiamo ora il modello addestrato per fare alcune previsioni su esempi senza etichetta ; cioè su esempi che contengono funzionalità ma non un'etichetta.
Nella vita reale, gli esempi senza etichetta potrebbero provenire da molte fonti diverse, tra cui app, file CSV e feed di dati. Per ora forniremo manualmente tre esempi senza etichetta per prevederne le etichette. Ricordiamo che i numeri delle etichette sono mappati su una rappresentazione denominata come:
-
0: Iris setosa -
1: Iris versicolor -
2: Iris virginica
let unlabeledDataset: Tensor<Float> =
[[5.1, 3.3, 1.7, 0.5],
[5.9, 3.0, 4.2, 1.5],
[6.9, 3.1, 5.4, 2.1]]
let unlabeledDatasetPredictions = model(unlabeledDataset)
for i in 0..<unlabeledDatasetPredictions.shape[0] {
let logits = unlabeledDatasetPredictions[i]
let classIdx = logits.argmax().scalar!
print("Example \(i) prediction: \(classNames[Int(classIdx)]) (\(softmax(logits)))")
}
Example 0 prediction: Iris setosa ([ 0.98731947, 0.012679046, 1.4035809e-06]) Example 1 prediction: Iris versicolor ([0.005065103, 0.85957265, 0.13536224]) Example 2 prediction: Iris virginica ([2.9613977e-05, 0.2637373, 0.73623306])