
Dowiedz się, jak zintegrować praktyki odpowiedzialnej sztucznej inteligencji z przepływem pracy ML za pomocą TensorFlow
TensorFlow angażuje się w pomoc w postępie w odpowiedzialnym rozwoju sztucznej inteligencji, udostępniając zbiór zasobów i narzędzi społeczności ML.

Czym jest odpowiedzialna sztuczna inteligencja?
Rozwój sztucznej inteligencji stwarza nowe możliwości rozwiązywania trudnych, rzeczywistych problemów. Rodzi to również nowe pytania dotyczące najlepszego sposobu tworzenia systemów sztucznej inteligencji, z których wszyscy skorzystają.

Zalecane najlepsze praktyki dotyczące sztucznej inteligencji
Projektowanie systemów sztucznej inteligencji powinno odbywać się zgodnie z najlepszymi praktykami w zakresie tworzenia oprogramowania, jednocześnie skupiając się na człowieku
podejście do ML

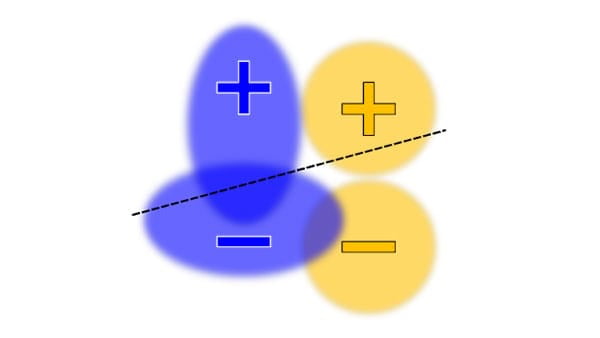
Uczciwość
Ponieważ wpływ sztucznej inteligencji wzrasta w różnych sektorach i społeczeństwach, niezwykle istotne jest działanie na rzecz systemów, które będą sprawiedliwe i włączające dla wszystkich

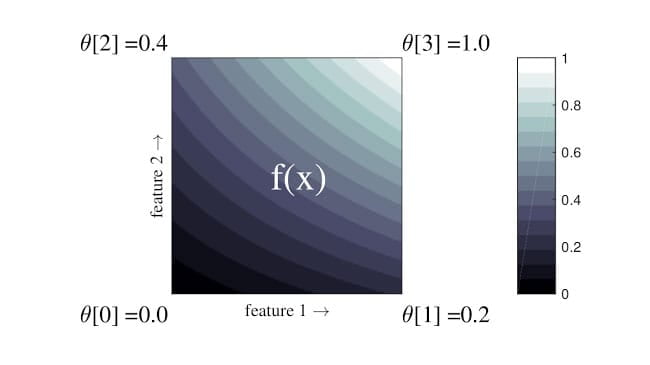
Interpretowalność
Zrozumienie systemów sztucznej inteligencji i zaufanie do nich jest ważne, aby mieć pewność, że działają zgodnie z przeznaczeniem

Prywatność
Modele szkoleniowe na podstawie wrażliwych danych wymagają zabezpieczeń chroniących prywatność

Bezpieczeństwo
Identyfikacja potencjalnych zagrożeń może pomóc w zapewnieniu bezpieczeństwa systemów AI
Odpowiedzialna sztuczna inteligencja w procesie ML
Odpowiedzialne praktyki AI można włączyć na każdym etapie przepływu pracy w zakresie uczenia maszynowego. Oto kilka kluczowych pytań, które należy rozważyć na każdym etapie.
Dla kogo jest mój system ML?
Sposób, w jaki faktyczni użytkownicy korzystają z systemu, jest niezbędny do oceny prawdziwego wpływu jego przewidywań, rekomendacji i decyzji. Upewnij się, że już na początku procesu tworzenia oprogramowania uzyskasz informacje od zróżnicowanej grupy użytkowników.
Czy używam reprezentatywnego zbioru danych?
Czy Twoje dane są próbkowane w sposób reprezentujący użytkowników (np. będą wykorzystywane w przypadku wszystkich grup wiekowych, ale masz tylko dane dotyczące szkoleń od seniorów) i ustawienia w świecie rzeczywistym (np. będą wykorzystywane przez cały rok, ale masz tylko dane dotyczące szkoleń? dane z lata)?
Czy moje dane zawierają błędy związane ze światem rzeczywistym/ludzkim?
Podstawowe błędy w danych mogą przyczyniać się do powstawania złożonych pętli sprzężenia zwrotnego, które wzmacniają istniejące stereotypy.
Jakich metod powinienem użyć do szkolenia mojego modelu?
Stosuj metody szkoleniowe, które budują w modelu uczciwość, interpretowalność, prywatność i bezpieczeństwo.
Jak radzi sobie mój model?
Oceń doświadczenie użytkownika w rzeczywistych scenariuszach w szerokim spektrum użytkowników, przypadków użycia i kontekstów użycia. Najpierw przetestuj i wykonaj iteracje w wersji testowej, a następnie kontynuuj testowanie po uruchomieniu.
Czy istnieją złożone pętle informacji zwrotnej?
Nawet jeśli wszystko w ogólnym projekcie systemu zostało starannie zaprojektowane, modele oparte na uczeniu maszynowym rzadko działają ze 100% perfekcją w zastosowaniu do rzeczywistych, bieżących danych. Kiedy problem pojawia się w działającym produkcie, zastanów się, czy jest on zgodny z istniejącymi wadami społecznymi i jaki wpływ na niego będą miały rozwiązania krótko- i długoterminowe.
Odpowiedzialne narzędzia AI dla TensorFlow
Ekosystem TensorFlow zawiera zestaw narzędzi i zasobów, które pomogą rozwiązać niektóre z powyższych pytań.
Zdefiniuj problem
Skorzystaj z poniższych zasobów, aby zaprojektować modele z myślą o odpowiedzialnej sztucznej inteligencji.

Dowiedz się więcej o procesie rozwoju sztucznej inteligencji i kluczowych kwestiach.
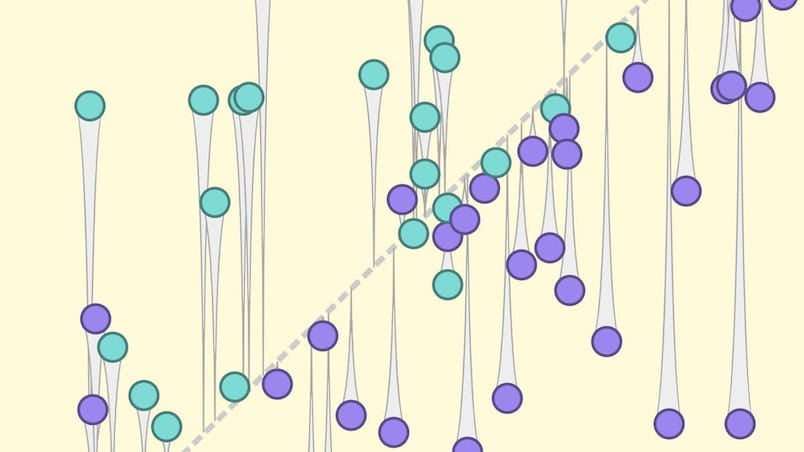
Poznaj, za pomocą interaktywnych wizualizacji, kluczowe pytania i koncepcje w dziedzinie odpowiedzialnej sztucznej inteligencji.
Konstruuj i przygotowuj dane
Skorzystaj z poniższych narzędzi, aby sprawdzić dane pod kątem potencjalnych błędów systematycznych.
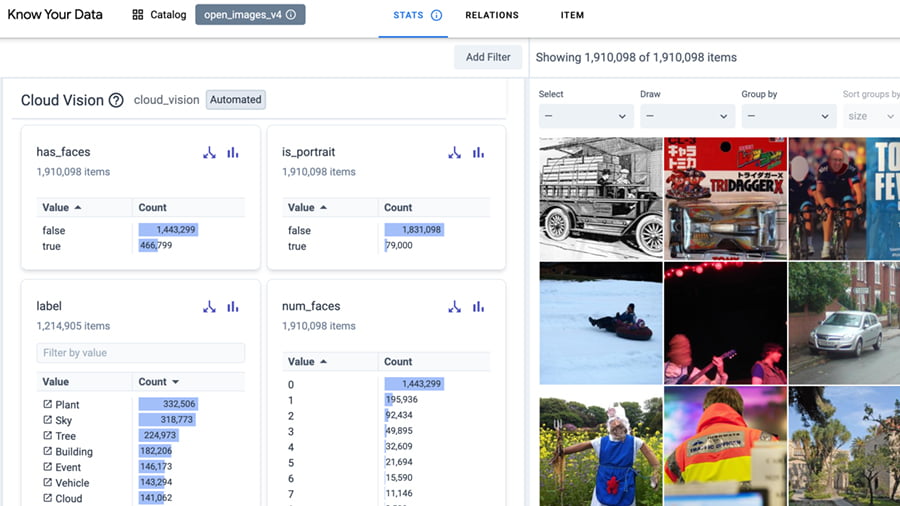
Interaktywnie badaj swój zbiór danych, aby poprawić jakość danych i złagodzić problemy związane z uczciwością i stronniczością.
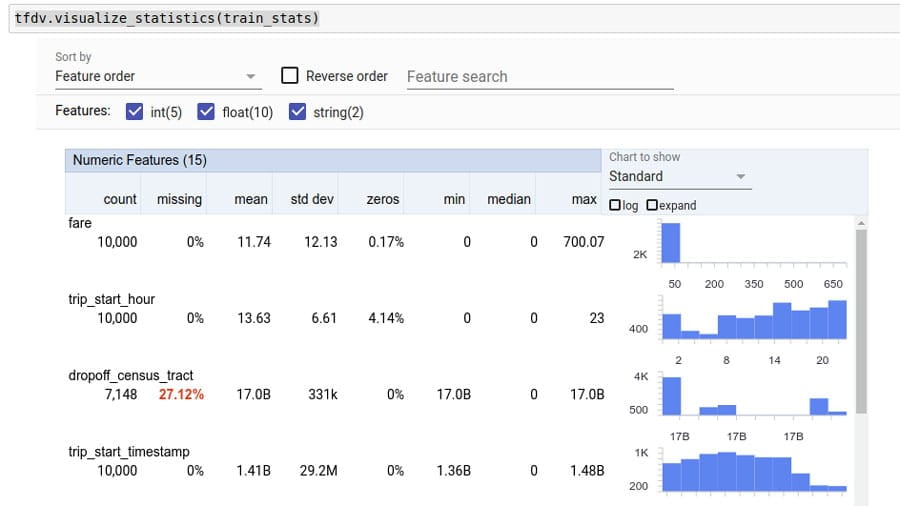
Analizuj i przekształcaj dane, aby wykrywać problemy i opracowywać bardziej efektywne zestawy funkcji.


Bardziej inkluzywna skala odcieni skóry, dostępna na otwartej licencji, dzięki której gromadzenie danych i budowanie modeli będą bardziej niezawodne i włączające.
Buduj i trenuj model
Skorzystaj z poniższych narzędzi, aby szkolić modele przy użyciu technik chroniących prywatność, możliwych do interpretacji i nie tylko.

Trenuj modele uczenia maszynowego, aby promować bardziej sprawiedliwe wyniki.
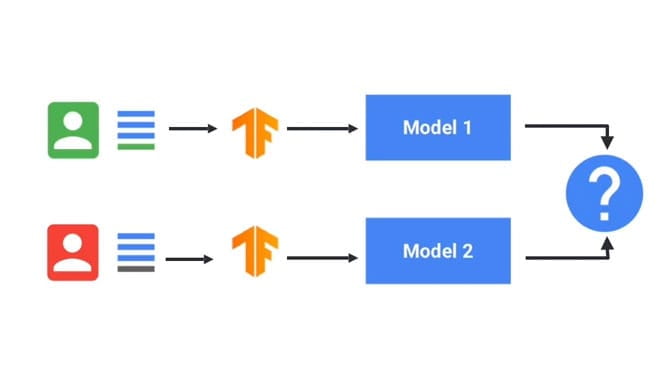
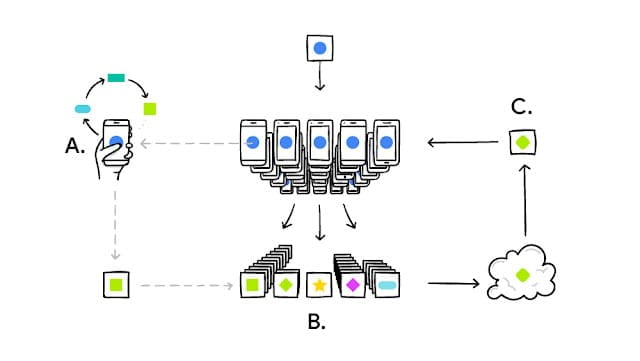
Trenuj modele uczenia maszynowego przy użyciu technik uczenia się stowarzyszonego.
Wdrażaj elastyczne, kontrolowane i interpretowalne modele oparte na kratach.
Oceń model
Debuguj, oceniaj i wizualizuj wydajność modelu za pomocą następujących narzędzi.
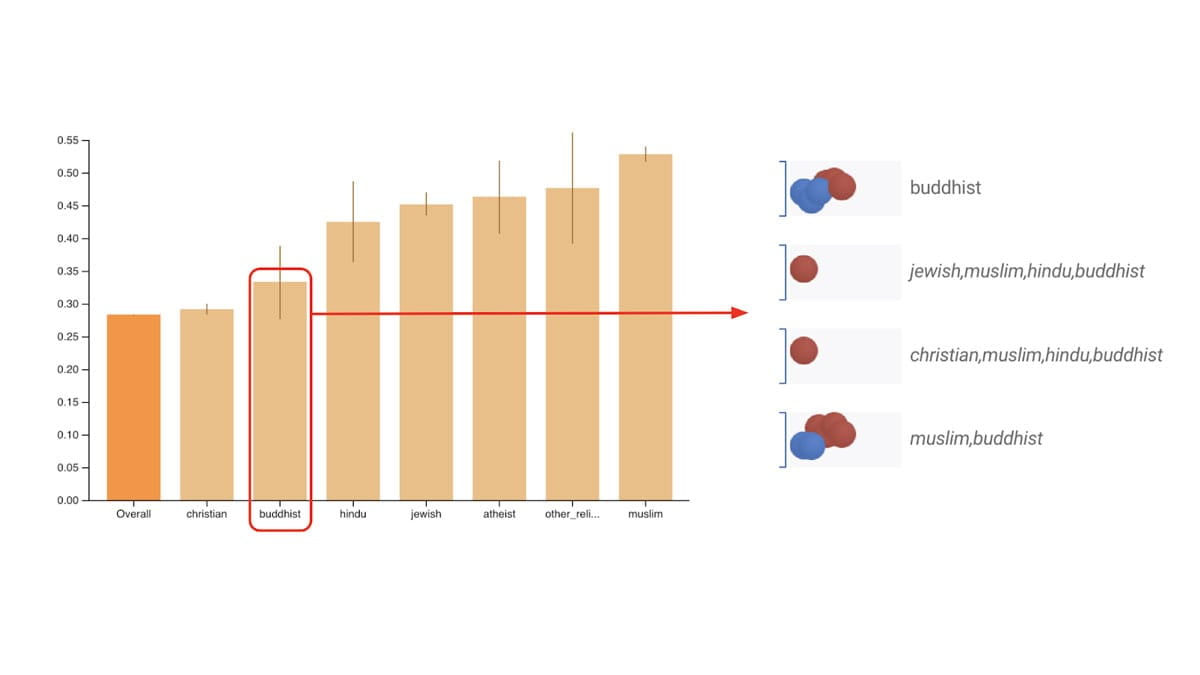
Oceń powszechnie identyfikowane metryki uczciwości dla klasyfikatorów binarnych i wieloklasowych.
Oceniaj modele w sposób rozproszony i przeprowadzaj obliczenia na różnych wycinkach danych.
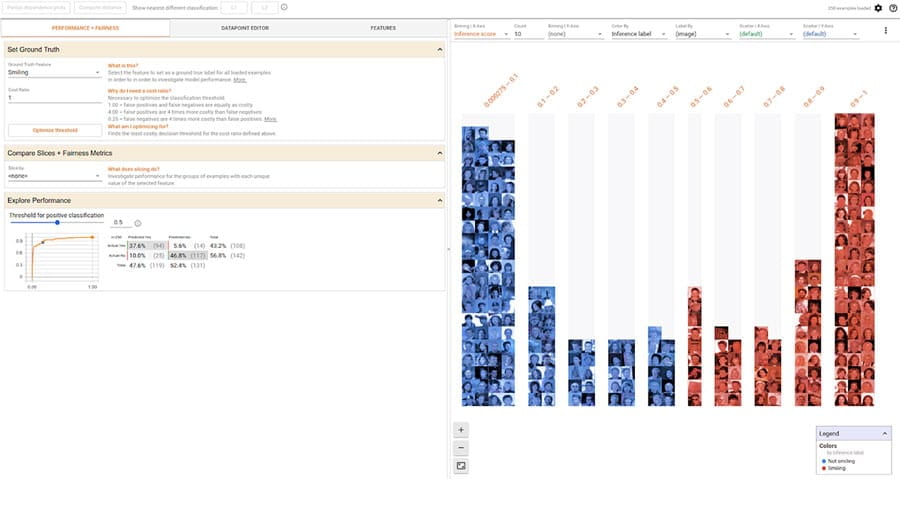
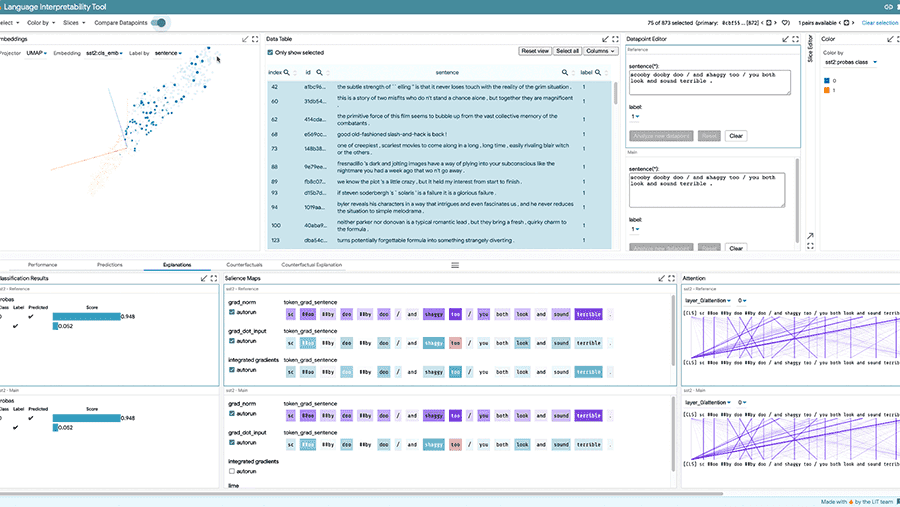
Opracuj możliwe do zinterpretowania i włączające modele uczenia maszynowego.
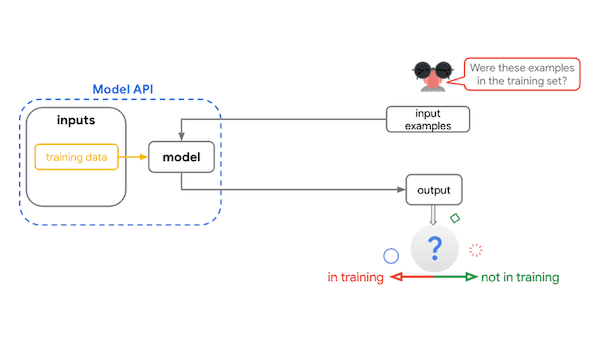
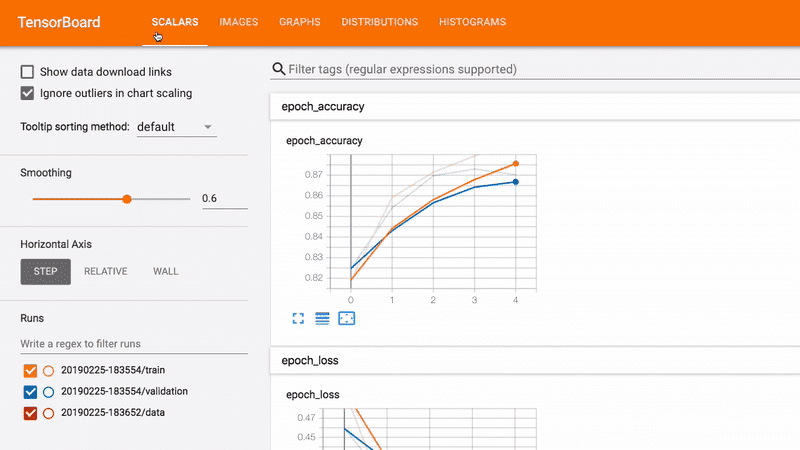
Wdrażaj i monitoruj
Użyj poniższych narzędzi do śledzenia kontekstu i szczegółów modelu oraz komunikowania się na ten temat.
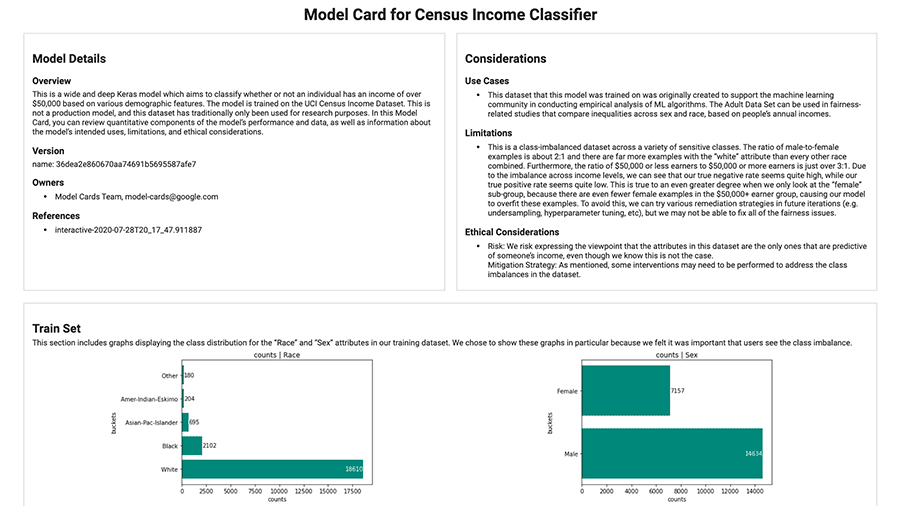
Z łatwością generuj karty modeli, korzystając z zestawu narzędzi Model Card.
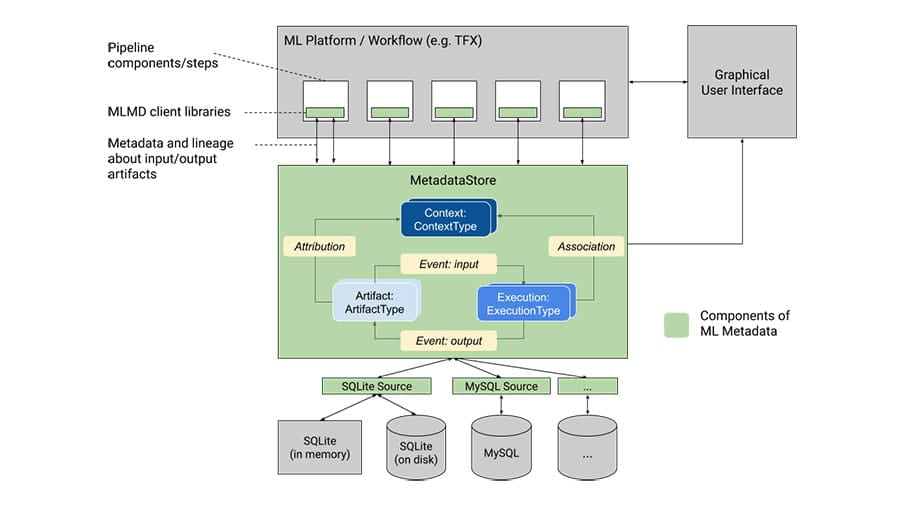
Rejestruj i pobieraj metadane powiązane z przepływami pracy programistów ML i analityków danych.
Uporządkuj podstawowe fakty dotyczące uczenia maszynowego w ustrukturyzowany sposób.
Zasoby społeczności
Dowiedz się, co robi społeczność i poznaj sposoby zaangażowania się.

Pomóż usługom Google stać się bardziej włączającymi i reprezentatywnymi dla Twojego języka, regionu i kultury.

Poprosiliśmy uczestników, aby wykorzystali TensorFlow 2.2 do zbudowania modelu lub aplikacji z uwzględnieniem zasad odpowiedzialnej sztucznej inteligencji. Zajrzyj do galerii, aby zobaczyć zwycięzców i inne niesamowite projekty.

Przedstawiamy ramy myślenia o ML, uczciwości i prywatności.
Dowiedz się, jak zintegrować praktyki odpowiedzialnej sztucznej inteligencji z przepływem pracy ML za pomocą TensorFlow
TensorFlow angażuje się w pomoc w postępie w odpowiedzialnym rozwoju sztucznej inteligencji, udostępniając zbiór zasobów i narzędzi społeczności ML.
Czym jest odpowiedzialna sztuczna inteligencja?
Rozwój sztucznej inteligencji stwarza nowe możliwości rozwiązywania trudnych, rzeczywistych problemów. Rodzi to również nowe pytania dotyczące najlepszego sposobu tworzenia systemów sztucznej inteligencji, z których wszyscy skorzystają.
Zalecane najlepsze praktyki dotyczące sztucznej inteligencji
Projektowanie systemów sztucznej inteligencji powinno odbywać się zgodnie z najlepszymi praktykami w zakresie tworzenia oprogramowania, jednocześnie skupiając się na człowieku
podejście do ML
Uczciwość
Ponieważ wpływ sztucznej inteligencji wzrasta w różnych sektorach i społeczeństwach, niezwykle istotne jest działanie na rzecz systemów, które będą sprawiedliwe i włączające dla wszystkich
Interpretowalność
Zrozumienie systemów sztucznej inteligencji i zaufanie do nich jest ważne, aby mieć pewność, że działają zgodnie z przeznaczeniem
Prywatność
Modele szkoleniowe na podstawie wrażliwych danych wymagają zabezpieczeń chroniących prywatność
Bezpieczeństwo
Identyfikacja potencjalnych zagrożeń może pomóc w zapewnieniu bezpieczeństwa systemów AI
Odpowiedzialna sztuczna inteligencja w procesie ML
Odpowiedzialne praktyki AI można włączyć na każdym etapie przepływu pracy w zakresie uczenia maszynowego. Oto kilka kluczowych pytań, które należy rozważyć na każdym etapie.
Dla kogo jest mój system ML?
Sposób, w jaki faktyczni użytkownicy korzystają z systemu, jest niezbędny do oceny prawdziwego wpływu jego przewidywań, rekomendacji i decyzji. Upewnij się, że na początku procesu tworzenia oprogramowania uzyskasz informacje od zróżnicowanej grupy użytkowników.
Czy używam reprezentatywnego zbioru danych?
Czy Twoje dane są próbkowane w sposób reprezentujący użytkowników (np. będą wykorzystywane w przypadku wszystkich grup wiekowych, ale masz tylko dane dotyczące szkoleń od seniorów) i ustawienia w świecie rzeczywistym (np. będą wykorzystywane przez cały rok, ale masz tylko dane dotyczące szkoleń? dane z lata)?
Czy moje dane zawierają błędy związane ze światem rzeczywistym/ludzkim?
Podstawowe błędy w danych mogą przyczyniać się do powstawania złożonych pętli sprzężenia zwrotnego, które wzmacniają istniejące stereotypy.
Jakich metod powinienem użyć do szkolenia mojego modelu?
Stosuj metody szkoleniowe, które budują w modelu uczciwość, interpretowalność, prywatność i bezpieczeństwo.
Jak radzi sobie mój model?
Oceń doświadczenie użytkownika w rzeczywistych scenariuszach w szerokim spektrum użytkowników, przypadków użycia i kontekstów użycia. Najpierw przetestuj i wykonaj iteracje w wersji testowej, a następnie kontynuuj testowanie po uruchomieniu.
Czy istnieją złożone pętle informacji zwrotnej?
Nawet jeśli wszystko w ogólnym projekcie systemu zostało starannie zaprojektowane, modele oparte na uczeniu maszynowym rzadko działają ze 100% perfekcją w zastosowaniu do rzeczywistych, bieżących danych. Kiedy problem pojawia się w działającym produkcie, zastanów się, czy jest on zgodny z istniejącymi wadami społecznymi i jaki wpływ na niego będą miały rozwiązania krótko- i długoterminowe.
Odpowiedzialne narzędzia AI dla TensorFlow
Ekosystem TensorFlow zawiera zestaw narzędzi i zasobów, które pomogą rozwiązać niektóre z powyższych pytań.
Zdefiniuj problem
Skorzystaj z poniższych zasobów, aby zaprojektować modele z myślą o odpowiedzialnej sztucznej inteligencji.
Dowiedz się więcej o procesie rozwoju sztucznej inteligencji i kluczowych kwestiach.
Poznaj, za pomocą interaktywnych wizualizacji, kluczowe pytania i koncepcje w dziedzinie odpowiedzialnej sztucznej inteligencji.
Konstruuj i przygotowuj dane
Skorzystaj z poniższych narzędzi, aby sprawdzić dane pod kątem potencjalnych błędów systematycznych.
Interaktywnie badaj swój zbiór danych, aby poprawić jakość danych i złagodzić problemy związane z uczciwością i stronniczością.
Analizuj i przekształcaj dane, aby wykrywać problemy i opracowywać bardziej efektywne zestawy funkcji.
Bardziej inkluzywna skala odcieni skóry, dostępna na otwartej licencji, dzięki której gromadzenie danych i budowanie modeli będą bardziej niezawodne i włączające.
Buduj i trenuj model
Skorzystaj z poniższych narzędzi, aby szkolić modele przy użyciu technik chroniących prywatność, możliwych do interpretacji i nie tylko.
Trenuj modele uczenia maszynowego, aby promować bardziej sprawiedliwe wyniki.
Trenuj modele uczenia maszynowego przy użyciu technik uczenia się stowarzyszonego.
Wdrażaj elastyczne, kontrolowane i interpretowalne modele oparte na kratach.
Oceń model
Debuguj, oceniaj i wizualizuj wydajność modelu za pomocą następujących narzędzi.
Oceń powszechnie identyfikowane metryki uczciwości dla klasyfikatorów binarnych i wieloklasowych.
Oceniaj modele w sposób rozproszony i przeprowadzaj obliczenia na różnych wycinkach danych.
Opracuj możliwe do zinterpretowania i włączające modele uczenia maszynowego.
Wdrażaj i monitoruj
Użyj poniższych narzędzi do śledzenia kontekstu i szczegółów modelu oraz komunikowania się na ten temat.
Z łatwością generuj karty modeli, korzystając z zestawu narzędzi Model Card.
Rejestruj i pobieraj metadane powiązane z przepływami pracy programistów ML i analityków danych.
Uporządkuj podstawowe fakty dotyczące uczenia maszynowego w ustrukturyzowany sposób.
Zasoby społeczności
Dowiedz się, co robi społeczność i poznaj sposoby zaangażowania się.
Pomóż usługom Google stać się bardziej włączającymi i reprezentatywnymi dla Twojego języka, regionu i kultury.
Poprosiliśmy uczestników, aby wykorzystali TensorFlow 2.2 do zbudowania modelu lub aplikacji z uwzględnieniem zasad odpowiedzialnej sztucznej inteligencji. Zajrzyj do galerii, aby zobaczyć zwycięzców i inne niesamowite projekty.
Przedstawiamy ramy myślenia o ML, uczciwości i prywatności.