
レコメンデーション システム
料理の注文からビデオ オンデマンド、オーディオ ストリーミング、ファッションまで、 レコメンデーション システムは今日最も人気のあるアプリケーションの一部を支えています。TensorFlow エコシステムのオープンソースのライブラリとツールを使用して、 本番環境に対応したレコメンデーション システムを構築する方法をご覧ください。
レコメンデーション システムは、最も理想的なコンテンツを提供することで、アプリ内のユーザー エンゲージメントを高め、 ユーザー エクスペリエンスを改善させます。最新のレコメンダーは複雑なシステムであり、通常の場合は、 本番環境での低レイテンシを実現するために複数のステージに分割されます。取得、 ランキング、場合によってはランキング後のステージで、無関係な項目が候補の大規模なプールから 段階的に除外されていき、ユーザーがアクションを行う可能性の最も高い 選択肢のリストが最終的に提示されます。
データ準備からデプロイまでのレコメンダー システム構築の完全なワークフローを促進する、 使いやすいフレームワークである TensorFlow Recommender で構築を開始しましょう。
モデルのトレーニングが完了したら、モデルを本番環境にデプロイして、エンドユーザーにレコメンデーションを提供します。TensorFlow Serving が、高パフォーマンスの推論のためのモデルの製品化を行います。機械学習モデルのスループットの最大化を目的としており、分散型の提供を必要とする大規模なレコメンデーション モデルをサポートできます。
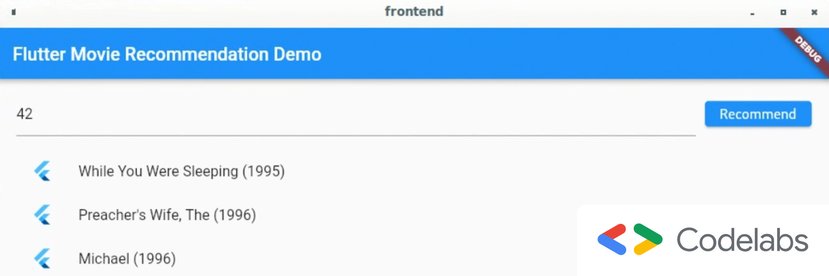
# Deploy the retrieval model with TensorFlow Serving docker run -t --rm -p 8501:8501 \ -v "RETRIEVAL/MODEL/PATH:/models/retrieval" \ -e MODEL_NAME=retrieval tensorflow/serving & # Retrieve top movies that user 42 may like curl -X POST -H "Content-Type: application/json" \ -d '{"instances":["42"]}' \ http://localhost:8501/v1/models/retrieval:predict # Output # { # "predictions":[ # { # "output_1": [2.032, 1.969, 1.813], # "output_2": ["movie1”, “movie2”, “movie3”] # } # ] # } # Deploy the ranking model with TensorFlow Serving docker run -t --rm -p 8501:8501 \ -v "RANKING/MODEL/PATH:/models/ranking" \ -e MODEL_NAME=ranking tensorflow/serving & # Get the prediction score for user 42 and movie 3 curl -X POST -H "Content-Type: application/json" \ -d '{"instances":[{"user_id":"42", "movie_title":"movie3"}]}' \ http://localhost:8501/v1/models/ranking:predict # Output: # {"predictions": [[3.66357923]]}
レコメンデーション エンジンの取得ステージとランキング ステージを改善する
大規模なレコメンデーション システムでは、効果的かつ効率的な手法で、最も関連性の高い項目を数百万単位の候補から取得およびランキング ステージを介して決定する必要があります。TensorFlow Recommender を、ScaNN ライブラリの最先端の近似最近傍探索(ANN)検索アルゴリズムと TensorFlow Ranking ライブラリの順序学習(LTR)手法で補完して、レコメンデーションを改善します。
ScaNN は、大規模なベクトル類似性検索用のライブラリです。非対称ハッシュや異方性量子化などの最新の ANN 技術を活用することで、上位候補を迅速に取得できます。
TensorFlow Ranking は、スケーラブルなニューラル LTR モデルを開発するためのライブラリです。ランキング ユーティリティを最大化するための、候補アイテムをランク付けする追加機能を提供します。
モデルのトレーニングと推論のために大規模なエンベディングを最適化する
エンベディング ルックアップ オペレーションは、大規模なレコメンデーション システムにとって重要なコンポーネントです。ハードウェア アクセラレーションと動的エンベディング テクノロジーを活用することで、大規模なエンベディング テーブルで起こりがちなパフォーマンスのボトルネックを解消できます。
TPUEmbedding Layers API を利用すれば、Tensor Processing Unit(TPU)での大規模なエンベディング テーブルのトレーニングと提供が容易になります。
TensorFlow Recommenders Addons は、コミュニティ提供のプロジェクトで、特にオンライン学習に役立つ動的エンベディング テクノロジーを活用しています。
ユーザーのプライバシーを保護する
従来型のレコメンデーション エンジンは、ユーザー インタラクション ログの収集と、未加工のユーザー アクションに基づくレコメンデーション モデルのトレーニングに依存しています。責任ある AI 開発プラクティスを組み込むことで、ユーザーデータのプライバシーを確保できます。
TensorFlow Lite は、低レイテンシで高品質なレコメンデーションを実現するとともに、すべてのユーザーデータをモバイル デバイス上に保持できる、オンデバイスのレコメンデーション ソリューションです。
TensorFlow Federated は、分散型データでのフェデレーション ラーニングやその他の計算のためのフレームワークです。Federated Reconstruction は、フェデレーション ラーニング設定に行列分解をもたらすものであり、レコメンデーションのユーザー プライバシーをより適切に保護できます。
より洗練されたレコメンダーのための高度な手法を使用する
業界では、従来型の協調フィルタリング モデルが広く使用されていますが、強化学習やグラフ ニューラル ネットワーク(GNN)などの高度な手法を採用して、レコメンデーション システムを構築する傾向が強まっています。
TensorFlow エージェント バンディットは、レコメンデーション エンジンの設定で効果的に探索、活用できるバンディット アルゴリズムの包括的ライブラリです。
TensorFlow GNN は、ネットワーク構造に基づいて項目のレコメンデーションを効率的に促進するライブラリで、取得およびランキング モデルと組み合わせて使用できます。
最先端のレコメンデーション モデルを参照する
よく知られたモデルのパフォーマンスのベンチマークを行ったり、独自のレコメンデーション モデルを構築したりするには、NCF、DLRM、DCN v2 などの一般的なモデルの公式の TensorFlow 実装をチェックして、ベスト プラクティスをご確認ください。
教育リソース
ステップバイステップのコースと動画で、レコメンデーション システムの構築の詳細を学習します。


実社会のレコメンデーション システム
あらゆる業界のアプリケーションを強化するレコメンデーション システムの例とケーススタディをご覧ください。

Spotify が TensorFlow エコシステムを活用して拡張可能なオフライン シミュレータを設計し、RL エージェントをトレーニングしてプレイリストのおすすめを生成した方法をご覧ください。