
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 | |
에서 기능화 튜토리얼 우리는 우리의 모델에 여러 기능을 통합,하지만 모델 만 매립 층으로 구성되어 있습니다. 표현력을 높이기 위해 모델에 더 조밀한 레이어를 추가할 수 있습니다.
일반적으로 더 깊은 모델은 얕은 모델보다 더 복잡한 패턴을 학습할 수 있습니다. 예를 들어, 우리의 사용자 모델은 특정 시점에서 모델 사용자 환경 설정에 사용자 ID와 타임 스탬프를 포함합니다. 얕은 모델(예: 단일 임베딩 레이어)은 해당 기능과 영화 간의 가장 단순한 관계만 학습할 수 있습니다. 특정 영화는 개봉 당시 가장 인기가 많았고 특정 사용자는 일반적으로 코미디보다 공포 영화를 선호합니다. 시간이 지남에 따라 진화하는 사용자 기본 설정과 같은 더 복잡한 관계를 캡처하려면 여러 개의 스택된 조밀한 레이어가 있는 더 깊은 모델이 필요할 수 있습니다.
물론 복잡한 모델에도 단점이 있습니다. 첫 번째는 더 큰 모델이 적합하고 제공하는 데 더 많은 메모리와 더 많은 계산이 필요하기 때문에 계산 비용입니다. 두 번째는 더 많은 데이터에 대한 요구 사항입니다. 일반적으로 더 깊은 모델을 활용하려면 더 많은 훈련 데이터가 필요합니다. 더 많은 매개변수를 사용하면 심층 모델이 일반화할 수 있는 함수를 학습하는 대신 과적합되거나 단순히 학습 예제를 암기할 수도 있습니다. 마지막으로 더 깊은 모델을 훈련하는 것이 더 어려울 수 있으며 정규화 및 학습률과 같은 설정을 선택할 때 더 많은 주의를 기울여야 합니다.
실제 추천 시스템에 대한 좋은 아키텍처를 찾는 것은 좋은 직관과주의가 필요한 복잡한 예술이다 hyperparameter 튜닝 . 예를 들어, 모델의 깊이와 너비, 활성화 함수, 학습률, 옵티마이저와 같은 요소는 모델의 성능을 근본적으로 바꿀 수 있습니다. 좋은 오프라인 평가 메트릭이 좋은 온라인 성능과 일치하지 않을 수 있고 최적화할 대상의 선택이 종종 모델 자체의 선택보다 더 중요하다는 사실 때문에 모델링 선택이 더욱 복잡해집니다.
그럼에도 불구하고 더 큰 모델을 만들고 미세 조정하는 데 들인 노력은 종종 결실을 맺습니다. 이 튜토리얼에서는 TensorFlow Recommenders를 사용하여 심층 검색 모델을 구축하는 방법을 설명합니다. 우리는 이것이 모델 성능에 어떤 영향을 미치는지 알아보기 위해 점진적으로 더 복잡한 모델을 구축함으로써 이를 수행할 것입니다.
예선
먼저 필요한 패키지를 가져옵니다.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
이 튜토리얼에서 우리는에서 모델을 사용 기능화 튜토리얼 묻어을 생성 할 수 있습니다. 따라서 우리는 사용자 ID, 타임스탬프 및 영화 제목 기능만 사용할 것입니다.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
우리는 또한 기능 어휘를 준비하기 위해 약간의 하우스키핑을 합니다.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
모델 정의
쿼리 모델
우리가 정의 된 사용자 모델 시작 기능화 튜토리얼 우리 모델의 제 1 층으로서 기능에 묻어 원시 입력 예 변환하는 임무.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
더 깊은 모델을 정의하려면 이 첫 번째 입력 위에 모드 레이어를 쌓아야 합니다. 활성화 함수로 구분되는 점진적으로 좁아지는 레이어 스택은 일반적인 패턴입니다.
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
깊은 선형 모델의 표현력이 얕은 선형 모델의 표현력보다 크지 않기 때문에 마지막 은닉층을 제외한 모든 것에 ReLU 활성화를 사용합니다. 최종 은닉층은 활성화 함수를 사용하지 않습니다. 활성화 함수를 사용하면 최종 임베딩의 출력 공간이 제한되고 모델의 성능에 부정적인 영향을 미칠 수 있습니다. 예를 들어, ReLU가 투영 레이어에서 사용되는 경우 출력 임베딩의 모든 구성 요소는 음수가 아닙니다.
우리는 여기에서 비슷한 것을 시도할 것입니다. 다양한 깊이에 대한 실험을 쉽게 하기 위해 깊이(및 너비)가 생성자 매개변수 세트로 정의되는 모델을 정의해 보겠습니다.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
는 layer_sizes 매개 변수는 우리에게 모델의 깊이와 폭을 제공합니다. 더 얕거나 더 깊은 모델을 실험하기 위해 변경할 수 있습니다.
후보 모델
우리는 영화 모델에 대해 동일한 접근 방식을 채택할 수 있습니다. 다시 말하지만, 우리는 시작 MovieModel 로부터 기능화 튜토리얼 :
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
그리고 숨겨진 레이어로 확장합니다.
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
결합 모델
모두 QueryModel 및 CandidateModel 정의 된, 우리는 결합 된 모델을 함께 넣어 우리의 손실을 측정 로직을 구현할 수 있습니다. 일을 단순화하기 위해 모델 구조가 쿼리 및 후보 모델에서 동일하도록 적용합니다.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
모델 훈련
데이터 준비
먼저 데이터를 훈련 세트와 테스트 세트로 나눕니다.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
얕은 모델
우리는 첫 번째 얕은 모델을 시험해 볼 준비가 되었습니다!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
이것은 약 0.27의 상위 100개 정확도를 제공합니다. 우리는 이것을 더 깊은 모델을 평가하기 위한 기준점으로 사용할 수 있습니다.
더 깊은 모델
두 개의 레이어가 있는 더 깊은 모델은 어떻습니까?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
정확도는 0.29로 얕은 모델보다 훨씬 좋습니다.
이를 설명하기 위해 검증 정확도 곡선을 그릴 수 있습니다.
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
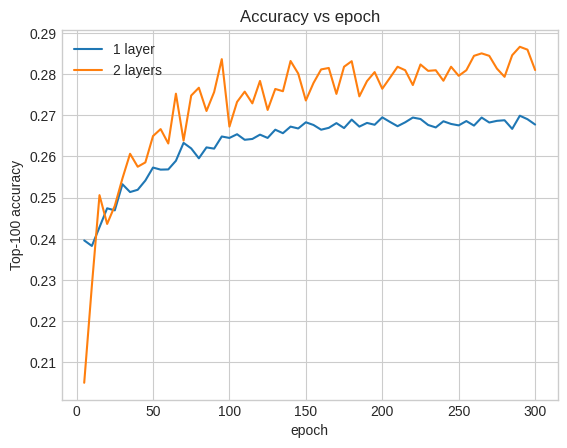
훈련 초기에도 더 큰 모델은 얕은 모델보다 명확하고 안정적으로 앞서 있으며, 깊이를 추가하면 모델이 데이터에서 더 미묘한 관계를 포착하는 데 도움이 됩니다.
그러나 더 깊은 모델이 반드시 더 좋은 것은 아닙니다. 다음 모델은 깊이를 세 개의 레이어로 확장합니다.
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
사실, 우리는 얕은 모델에 비해 개선을 보지 못했습니다.
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
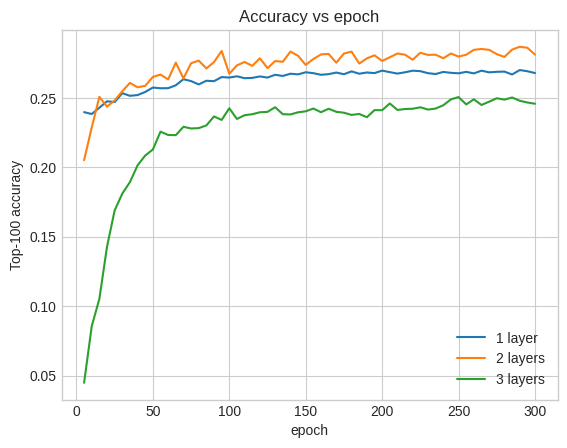
이것은 더 깊고 더 큰 모델이 우수한 성능을 발휘할 수 있지만 종종 매우 신중한 조정이 필요하다는 사실을 잘 보여줍니다. 예를 들어, 이 튜토리얼 전체에서 우리는 고정된 단일 학습률을 사용했습니다. 대안 선택은 매우 다른 결과를 제공할 수 있으며 탐색할 가치가 있습니다.
적절한 조정과 충분한 데이터가 있으면 더 크고 심층적인 모델을 구축하는 데 드는 노력이 많은 경우에 그만한 가치가 있습니다. 더 큰 모델은 예측 정확도의 상당한 개선으로 이어질 수 있습니다.
다음 단계
이 튜토리얼에서 우리는 고밀도 레이어와 활성화 함수로 검색 모델을 확장했습니다. 검색 작업뿐만 아니라 평가 작업뿐만 아니라 수행 할 수있는 모델을 만드는 방법을 확인하려면, 한 번 봐 걸릴 멀티 태스크 자습서를 .