
| |  GitHubでソースを表示 GitHubでソースを表示 | |
でフィーチャーチュートリアル、我々は我々のモデルに複数の機能を組み込んだ、しかしモデルのみ埋め込む層で構成されています。モデルに密度の高いレイヤーを追加して、表現力を高めることができます。
一般に、深いモデルは、浅いモデルよりも複雑なパターンを学習できます。たとえば、私たちのユーザー・モデルは、ある時点でのモデル、ユーザの好みにユーザーIDとタイムスタンプが組み込まれています。浅いモデル(たとえば、単一の埋め込みレイヤー)は、これらの機能と映画の間の最も単純な関係しか学習できない場合があります。特定の映画はリリースの頃に最も人気があり、特定のユーザーは一般的にコメディよりもホラー映画を好みます。時間の経過とともに進化するユーザー設定など、より複雑な関係をキャプチャするには、複数の密なレイヤーを積み重ねた、より深いモデルが必要になる場合があります。
もちろん、複雑なモデルにも欠点があります。 1つ目は計算コストです。モデルが大きくなると、適合して提供するためにより多くのメモリとより多くの計算が必要になるためです。 2つ目は、より多くのデータの要件です。一般に、より深いモデルを利用するには、より多くのトレーニングデータが必要です。より多くのパラメーターを使用すると、一般化できる関数を学習する代わりに、深いモデルが過剰適合したり、トレーニング例を単に記憶したりする可能性があります。最後に、より深いモデルのトレーニングは難しい場合があり、正則化や学習率などの設定を選択する際には、より注意を払う必要があります。
実世界の推薦システムのための優れたアーキテクチャを見つけることは良い勘と慎重必要とする複雑な芸術であり、ハイパーパラメータのチューニングを。たとえば、モデルの深さと幅、活性化関数、学習率、オプティマイザーなどの要因によって、モデルのパフォーマンスが根本的に変わる可能性があります。優れたオフライン評価指標が優れたオンラインパフォーマンスに対応しない可能性があり、最適化する対象の選択がモデル自体の選択よりも重要であることが多いという事実により、モデリングの選択はさらに複雑になります。
それにもかかわらず、より大きなモデルの構築と微調整に注がれた努力は、しばしば報われます。このチュートリアルでは、TensorFlowレコメンダーを使用してディープリトリーブモデルを構築する方法を説明します。これを行うには、徐々に複雑なモデルを作成して、これがモデルのパフォーマンスにどのように影響するかを確認します。
予選
まず、必要なパッケージをインポートします。
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
このチュートリアルでは、からモデルを使用するフィーチャーチュートリアル埋め込みを生成します。したがって、ユーザーID、タイムスタンプ、および映画のタイトル機能のみを使用します。
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
また、機能の語彙を準備するためにいくつかのハウスキーピングを行います。
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
モデル定義
クエリモデル
私たちは、で定義されたユーザモデルで始まるフィーチャーチュートリアル機能の埋め込みに生の入力例を変換する使命を帯び我々のモデルの第一層として、。
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
より深いモデルを定義するには、この最初の入力の上にモードレイヤーをスタックする必要があります。活性化関数によって分離された、徐々に狭くなる層のスタックは、一般的なパターンです。
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
深い線形モデルの表現力は浅い線形モデルの表現力よりも大きくないため、最後の隠れ層を除くすべてにReLUアクティベーションを使用します。最終的な隠れ層はアクティブ化関数を使用しません。アクティブ化関数を使用すると、最終的な埋め込みの出力スペースが制限され、モデルのパフォーマンスに悪影響を与える可能性があります。たとえば、ReLUが射影レイヤーで使用されている場合、出力埋め込みのすべてのコンポーネントは非負になります。
ここで似たようなことを試してみます。さまざまな深さでの実験を容易にするために、深さ(および幅)がコンストラクターパラメーターのセットによって定義されるモデルを定義しましょう。
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizesパラメータは、私たちに、モデルの深さと幅を提供します。浅いモデルまたは深いモデルで実験するために、それを変えることができます。
候補モデル
映画モデルにも同じアプローチを採用できます。ここでも、我々はで始まるMovieModelからフィーチャーチュートリアル:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
そしてそれを隠しレイヤーで展開します:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
複合モデル
両方でQueryModelとCandidateModel定義され、私たちは一緒に組み合わせたモデルを入れて、私たちの損失とメトリックロジックを実装することができます。簡単にするために、モデル構造がクエリモデルと候補モデルで同じであることを強制します。
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
モデルのトレーニング
データを準備する
まず、データをトレーニングセットとテストセットに分割します。
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
浅いモデル
最初の浅いモデルを試す準備ができました!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
これにより、トップ100の精度は約0.27になります。これは、より深いモデルを評価するための参照ポイントとして使用できます。
より深いモデル
2層のより深いモデルはどうですか?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
ここでの精度は0.29で、浅いモデルよりもかなり優れています。
これを説明するために、検証精度曲線をプロットできます。
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
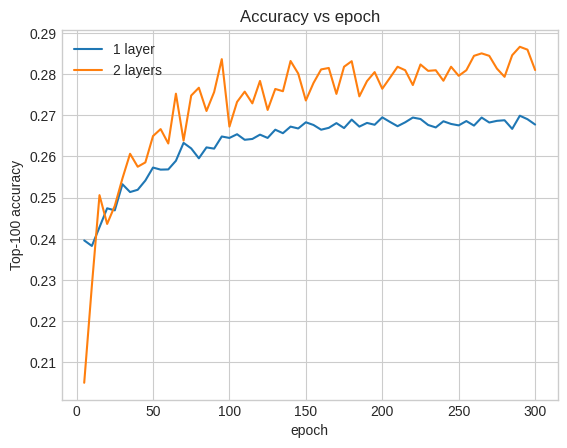
トレーニングの早い段階でさえ、大きなモデルは浅いモデルよりも明確で安定したリードを持っており、深さを追加すると、モデルがデータ内のより微妙な関係をキャプチャするのに役立つことを示唆しています。
ただし、より深いモデルでも必ずしも優れているとは限りません。次のモデルは、深さを3つのレイヤーに拡張します。
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
実際、浅いモデルに比べて改善は見られません。
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
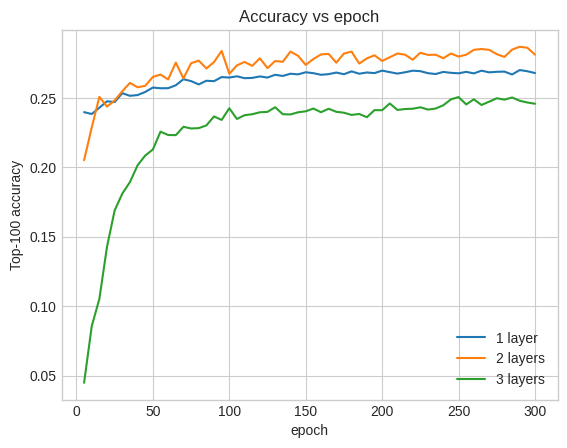
これは、より深く、より大きなモデルは優れたパフォーマンスを発揮しますが、多くの場合、非常に注意深い調整が必要であるという事実の良い例です。たとえば、このチュートリアル全体を通して、単一の固定学習率を使用しました。別の選択肢は非常に異なる結果をもたらす可能性があり、調査する価値があります。
適切な調整と十分なデータがあれば、より大きくより深いモデルを構築するための努力は、多くの場合、それだけの価値があります。より大きなモデルは、予測精度の大幅な向上につながる可能性があります。
次のステップ
このチュートリアルでは、高密度レイヤーと活性化関数を使用して検索モデルを拡張しました。検索タスクもレーティングタスクだけでなく、実行できるモデルを作成する方法を参照するには、見とるマルチタスクのチュートリアルを。