
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
در featurization آموزش ما ویژگی های متعدد به مدل های ما به ثبت رسیده، اما مدل تنها یک لایه تعبیه شده است. ما می توانیم لایه های متراکم بیشتری را به مدل های خود اضافه کنیم تا قدرت بیان آنها را افزایش دهیم.
به طور کلی، مدلهای عمیقتر نسبت به مدلهای کم عمقتر قادر به یادگیری الگوهای پیچیدهتر هستند. به عنوان مثال، ما مدل کاربر شامل شناسه کاربری و timestamp به تنظیمات کاربر مدل در یک نقطه در زمان. یک مدل کم عمق (مثلاً یک لایه جاسازی شده) فقط می تواند ساده ترین روابط بین آن ویژگی ها و فیلم ها را بیاموزد: یک فیلم معین در زمان اکرانش بیشترین محبوبیت را دارد و یک کاربر معین عموماً فیلم های ترسناک را به کمدی ترجیح می دهد. برای ثبت روابط پیچیدهتر، مانند ترجیحات کاربر که در طول زمان تغییر میکنند، ممکن است به یک مدل عمیقتر با چندین لایه متراکم روی هم نیاز داشته باشیم.
البته مدل های پیچیده هم معایبی دارند. اولین مورد هزینه محاسباتی است، زیرا مدل های بزرگتر برای جا دادن و ارائه به حافظه بیشتر و محاسبات بیشتری نیاز دارند. مورد دوم، نیاز به داده های بیشتر است: به طور کلی، داده های آموزشی بیشتری برای استفاده از مدل های عمیق تر مورد نیاز است. با پارامترهای بیشتر، مدلهای عمیق ممکن است به جای یادگیری تابعی که میتواند تعمیم دهد، نمونههای آموزشی را بیش از حد برازش میکنند یا حتی به سادگی آنها را حفظ میکنند. در نهایت، آموزش مدلهای عمیقتر ممکن است سختتر باشد و باید در انتخاب تنظیماتی مانند منظمسازی و میزان یادگیری دقت بیشتری کرد.
پیدا کردن یک معماری خوب برای یک سیستم پیشنهاد در دنیای واقعی یک هنر پیچیده، نیاز به شهود خوب و دقیق است تنظیم hyperparameter . به عنوان مثال، عواملی مانند عمق و عرض مدل، عملکرد فعال سازی، نرخ یادگیری و بهینه ساز می توانند عملکرد مدل را به شدت تغییر دهند. انتخابهای مدلسازی با این واقعیت پیچیدهتر میشوند که معیارهای ارزیابی آفلاین خوب ممکن است با عملکرد آنلاین خوب مطابقت نداشته باشند، و اینکه انتخاب آنچه برای بهینهسازی باید انجام شود، اغلب مهمتر از انتخاب خود مدل است.
با این وجود، تلاش برای ساخت و تنظیم دقیق مدلهای بزرگتر اغلب نتیجه میدهد. در این آموزش، نحوه ساخت مدل های بازیابی عمیق با استفاده از توصیه کننده های TensorFlow را نشان خواهیم داد. ما این کار را با ساختن مدلهای پیچیدهتر به تدریج انجام میدهیم تا ببینیم این کار چگونه بر عملکرد مدل تأثیر میگذارد.
مقدماتی
ابتدا بسته های لازم را وارد می کنیم.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
در این آموزش ما را به مدل های از استفاده آموزش featurization برای تولید درونه گیریها. از این رو ما فقط از ویژگی های شناسه کاربر، مهر زمانی و عنوان فیلم استفاده خواهیم کرد.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
ما همچنین خانه داری را برای تهیه واژگان ویژگی انجام می دهیم.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
تعریف مدل
مدل پرس و جو
ما با استفاده از مدل تعریف شده توسط کاربر در شروع آموزش featurization به عنوان اولین لایه از مدل ما، وظیفه با تبدیل نمونه ورودی های خام را به درونه گیریها ویژگی.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
برای تعریف مدلهای عمیقتر، ما باید لایههای حالت را در بالای این ورودی اول قرار دهیم. یک پشته به تدریج باریکتر از لایه ها، که توسط یک تابع فعال سازی از هم جدا می شوند، یک الگوی رایج است:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
از آنجایی که قدرت بیان مدل های خطی عمیق بیشتر از مدل های خطی کم عمق نیست، ما از فعال سازی ReLU برای همه به جز آخرین لایه پنهان استفاده می کنیم. لایه پنهان نهایی از هیچ تابع فعال سازی استفاده نمی کند: استفاده از یک تابع فعال سازی فضای خروجی جاسازی های نهایی را محدود می کند و ممکن است بر عملکرد مدل تأثیر منفی بگذارد. به عنوان مثال، اگر ReLU ها در لایه پروجکشن استفاده شود، همه اجزای موجود در تعبیه خروجی غیر منفی خواهند بود.
ما قصد داریم چیزی مشابه را در اینجا امتحان کنیم. برای آسان کردن آزمایش با اعماق مختلف، بیایید مدلی را تعریف کنیم که عمق (و عرض) آن توسط مجموعهای از پارامترهای سازنده تعریف میشود.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizes پارامتر به ما می دهد عمق و عرض مدل. ما می توانیم آن را برای آزمایش با مدل های کم عمق تر یا عمیق تر تغییر دهیم.
مدل کاندید
ما می توانیم همین رویکرد را برای مدل فیلم اتخاذ کنیم. باز هم، ما با شروع MovieModel از featurization آموزش:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
و آن را با لایه های مخفی گسترش دهید:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
مدل ترکیبی
با هر دو QueryModel و CandidateModel تعریف شده است، ما می توانیم با هم یک مدل ترکیبی قرار داده و پیاده سازی از دست دادن و معیارهای منطق ما. برای سادهتر کردن کارها، ما اجبار میکنیم که ساختار مدل در بین مدلهای پرس و جو و کاندید یکسان باشد.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
آموزش مدل
داده ها را آماده کنید
ابتدا داده ها را به یک مجموعه آموزشی و یک مجموعه آزمایشی تقسیم می کنیم.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
مدل کم عمق
ما آماده ایم که اولین مدل کم عمق خود را امتحان کنیم!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
این به ما یک دقت بالای 100 در حدود 0.27 می دهد. ما می توانیم از این به عنوان یک نقطه مرجع برای ارزیابی مدل های عمیق تر استفاده کنیم.
مدل عمیق تر
مدل عمیق تر با دو لایه چطور؟
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
دقت در اینجا 0.29 است، که بسیار بهتر از مدل کم عمق است.
ما می توانیم منحنی های دقت اعتبار سنجی را برای نشان دادن این رسم کنیم:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>

حتی در اوایل آموزش، مدل بزرگتر برتری واضح و پایداری نسبت به مدل کم عمق دارد، که نشان میدهد افزودن عمق به مدل کمک میکند تا روابط ظریفتری را در دادهها ثبت کند.
با این حال، حتی مدل های عمیق تر لزوما بهتر نیستند. مدل زیر عمق را به سه لایه گسترش می دهد:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
در واقع، ما شاهد بهبودی نسبت به مدل کم عمق نیستیم:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
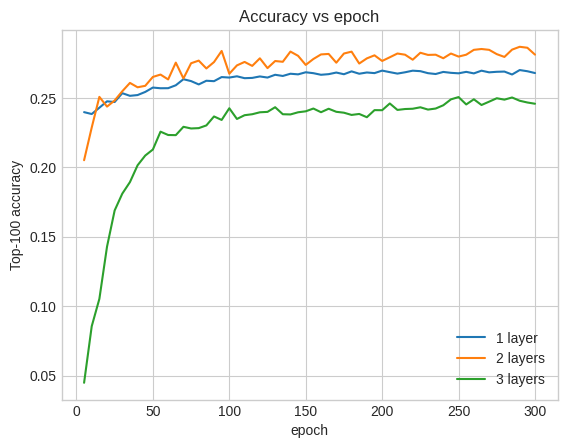
این یک تصویر خوب از این واقعیت است که مدلهای عمیقتر و بزرگتر، در حالی که قادر به عملکرد عالی هستند، اغلب نیاز به تنظیم بسیار دقیق دارند. به عنوان مثال، در طول این آموزش ما از یک نرخ یادگیری ثابت و واحد استفاده کردیم. انتخاب های جایگزین ممکن است نتایج بسیار متفاوتی به همراه داشته باشند و ارزش بررسی را دارند.
با تنظیم مناسب و دادههای کافی، تلاش برای ساخت مدلهای بزرگتر و عمیقتر در بسیاری از موارد ارزشش را دارد: مدلهای بزرگتر میتوانند به پیشرفتهای اساسی در دقت پیشبینی منجر شوند.
مراحل بعدی
در این آموزش مدل بازیابی خود را با لایه های متراکم و توابع فعال سازی گسترش دادیم. تا ببینید که چگونه برای ایجاد یک مدل است که می تواند نه تنها وظایف بازیابی و اما وظایف کلاس انجام دهد، نگاهی به آموزش Multitask تمام .