
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ইন featurization টিউটোরিয়াল আমরা আমাদের মডেল একাধিক বৈশিষ্ট্য অন্তর্ভূক্ত কিন্তু মডেলের শুধুমাত্র একটি এম্বেডিং স্তর দ্বারা গঠিত। আমরা তাদের অভিব্যক্তি ক্ষমতা বাড়াতে আমাদের মডেলগুলিতে আরও ঘন স্তর যুক্ত করতে পারি।
সাধারণভাবে, গভীর মডেলগুলি অগভীর মডেলের তুলনায় আরও জটিল নিদর্শন শিখতে সক্ষম। উদাহরণস্বরূপ, আমাদের ব্যবহারকারী মডেল সময় একটি বিন্দুতে মডেল ব্যবহারকারীর পছন্দ ব্যবহারকারীর আইডি এবং টাইমস্ট্যাম্প অন্তর্ভুক্ত। একটি অগভীর মডেল (বলুন, একটি একক এম্বেডিং স্তর) কেবলমাত্র সেই বৈশিষ্ট্যগুলি এবং চলচ্চিত্রগুলির মধ্যে সহজতম সম্পর্কগুলি শিখতে সক্ষম হতে পারে: একটি প্রদত্ত চলচ্চিত্র এটির মুক্তির সময় সবচেয়ে জনপ্রিয় হয় এবং একটি প্রদত্ত ব্যবহারকারী সাধারণত কমেডি থেকে হরর চলচ্চিত্র পছন্দ করে। আরও জটিল সম্পর্ক ক্যাপচার করতে, যেমন সময়ের সাথে সাথে ব্যবহারকারীর পছন্দগুলি বিকশিত হচ্ছে, আমাদের একাধিক স্ট্যাক করা ঘন স্তর সহ একটি গভীর মডেলের প্রয়োজন হতে পারে।
অবশ্যই, জটিল মডেলগুলিরও তাদের অসুবিধা রয়েছে। প্রথমটি হল কম্পিউটেশনাল খরচ, কারণ বৃহত্তর মডেলগুলিতে ফিট এবং পরিবেশন করার জন্য আরও মেমরি এবং আরও গণনা উভয়ই প্রয়োজন। দ্বিতীয়টি হ'ল আরও ডেটার প্রয়োজনীয়তা: সাধারণভাবে, গভীর মডেলগুলির সুবিধা নেওয়ার জন্য আরও প্রশিক্ষণ ডেটা প্রয়োজন৷ আরও পরামিতি সহ, গভীর মডেলগুলি সাধারণীকরণ করতে পারে এমন একটি ফাংশন শেখার পরিবর্তে প্রশিক্ষণের উদাহরণগুলিকে ওভারফিট করতে পারে বা এমনকি সহজভাবে মুখস্থ করতে পারে। অবশেষে, গভীর মডেলের প্রশিক্ষণ কঠিন হতে পারে এবং নিয়মিতকরণ এবং শেখার হারের মতো সেটিংস বেছে নেওয়ার ক্ষেত্রে আরও যত্ন নেওয়া দরকার।
কে বাস্তব পৃথিবীতে recommender সিস্টেমের জন্য একটি ভাল স্থাপত্য খোঁজা একটি জটিল শিল্প, ভাল স্বজ্ঞা এবং সতর্কতা অবলম্বন প্রয়োজন হয় hyperparameter সুরকরণ । উদাহরণস্বরূপ, মডেলের গভীরতা এবং প্রস্থ, অ্যাক্টিভেশন ফাংশন, শেখার হার এবং অপ্টিমাইজারের মতো বিষয়গুলি মডেলের কার্যকারিতাকে আমূল পরিবর্তন করতে পারে। মডেলিং পছন্দগুলি আরও জটিল হয় যে ভাল অফলাইন মূল্যায়ন মেট্রিক্স ভাল অনলাইন পারফরম্যান্সের সাথে সঙ্গতিপূর্ণ নাও হতে পারে এবং কোনটির জন্য অপ্টিমাইজ করতে হবে তার পছন্দটি প্রায়শই মডেলের পছন্দের চেয়ে বেশি গুরুত্বপূর্ণ।
তবুও, বড় মডেল তৈরি এবং সূক্ষ্ম-টিউনিং করার প্রচেষ্টা প্রায়শই বন্ধ করে দেয়। এই টিউটোরিয়ালে, আমরা ব্যাখ্যা করব কিভাবে TensorFlow Recommenders ব্যবহার করে গভীর পুনরুদ্ধার মডেল তৈরি করা যায়। এটি কীভাবে মডেলের কার্যকারিতাকে প্রভাবিত করে তা দেখতে আমরা ধীরে ধীরে আরও জটিল মডেল তৈরি করে এটি করব।
প্রাথমিক
আমরা প্রথমে প্রয়োজনীয় প্যাকেজ আমদানি করি।
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
এই টিউটোরিয়ালে আমরা থেকে মডেল ব্যবহার করবে featurization টিউটোরিয়াল embeddings তৈরি করতে। তাই আমরা শুধুমাত্র ইউজার আইডি, টাইমস্ট্যাম্প এবং মুভি টাইটেল ফিচার ব্যবহার করব।
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
আমরা বৈশিষ্ট্য শব্দভান্ডার প্রস্তুত করার জন্য কিছু হাউসকিপিং করি।
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
মডেল সংজ্ঞা
কোয়েরি মডেল
আমরা ব্যবহারকারী মডেল সংজ্ঞায়িত দিয়ে শুরু featurization টিউটোরিয়াল আমাদের মডেল প্রথম স্তর হিসেবে, বৈশিষ্ট্য embeddings মধ্যে কাঁচা ইনপুট উদাহরণ রূপান্তর সঙ্গে tasked।
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
গভীর মডেল সংজ্ঞায়িত করার জন্য আমাদের এই প্রথম ইনপুটের উপরে মোড স্তরগুলিকে স্ট্যাক করতে হবে। একটি সক্রিয়করণ ফাংশন দ্বারা পৃথক করা স্তরগুলির একটি ক্রমান্বয়ে সংকীর্ণ স্ট্যাক একটি সাধারণ প্যাটার্ন:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
যেহেতু গভীর রৈখিক মডেলের অভিব্যক্তিগত শক্তি অগভীর রৈখিক মডেলের চেয়ে বেশি নয়, তাই আমরা শেষ লুকানো স্তর ছাড়া সকলের জন্য ReLU অ্যাক্টিভেশন ব্যবহার করি। চূড়ান্ত লুকানো স্তর কোনো অ্যাক্টিভেশন ফাংশন ব্যবহার করে না: একটি অ্যাক্টিভেশন ফাংশন ব্যবহার করা চূড়ান্ত এম্বেডিংয়ের আউটপুট স্পেসকে সীমিত করবে এবং মডেলের কর্মক্ষমতাকে নেতিবাচকভাবে প্রভাবিত করতে পারে। উদাহরণস্বরূপ, যদি প্রজেকশন লেয়ারে ReLUs ব্যবহার করা হয়, আউটপুট এম্বেডিংয়ের সমস্ত উপাদান অ-নেতিবাচক হবে।
আমরা এখানে অনুরূপ কিছু চেষ্টা করতে যাচ্ছি. বিভিন্ন গভীরতা নিয়ে পরীক্ষা-নিরীক্ষা সহজ করতে, আসুন এমন একটি মডেল সংজ্ঞায়িত করি যার গভীরতা (এবং প্রস্থ) কনস্ট্রাক্টর প্যারামিটারের একটি সেট দ্বারা সংজ্ঞায়িত করা হয়।
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
layer_sizes প্যারামিটার আমাদের গভীরতা এবং মডেল প্রস্থ দেয়। আমরা অগভীর বা গভীর মডেলের সাথে পরীক্ষা করার জন্য এটির পরিবর্তন করতে পারি।
প্রার্থী মডেল
আমরা সিনেমা মডেলের জন্য একই পদ্ধতি অবলম্বন করতে পারি। আবার, আমরা দিয়ে শুরু MovieModel থেকে featurization টিউটোরিয়াল:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
এবং লুকানো স্তরগুলির সাথে এটি প্রসারিত করুন:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
সম্মিলিত মডেল
উভয় সঙ্গে QueryModel এবং CandidateModel সংজ্ঞায়িত, আমরা একটি সম্মিলিত মডেল একত্র করা এবং আমাদের কমে যাওয়া এবং বৈশিষ্ট্যের মান যুক্তিবিজ্ঞান বাস্তবায়ন করতে পারে। জিনিসগুলিকে সহজ করার জন্য, আমরা বলব যে মডেলের গঠনটি কোয়েরি এবং প্রার্থী মডেল জুড়ে একই।
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
মডেল প্রশিক্ষণ
ডেটা প্রস্তুত করুন
আমরা প্রথমে একটি প্রশিক্ষণ সেট এবং একটি পরীক্ষার সেটে ডেটা বিভক্ত করি।
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
অগভীর মডেল
আমরা আমাদের প্রথম, অগভীর, মডেল চেষ্টা করার জন্য প্রস্তুত!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
এটি আমাদের প্রায় 0.27 এর শীর্ষ-100 নির্ভুলতা দেয়। গভীর মডেলের মূল্যায়ন করার জন্য আমরা এটি একটি রেফারেন্স পয়েন্ট হিসাবে ব্যবহার করতে পারি।
গভীর মডেল
দুই স্তর সঙ্গে একটি গভীর মডেল সম্পর্কে কি?
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
এখানে নির্ভুলতা 0.29, অগভীর মডেলের তুলনায় বেশ কিছুটা ভালো।
আমরা এটি ব্যাখ্যা করার জন্য বৈধতা নির্ভুলতা বক্ররেখা প্লট করতে পারি:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
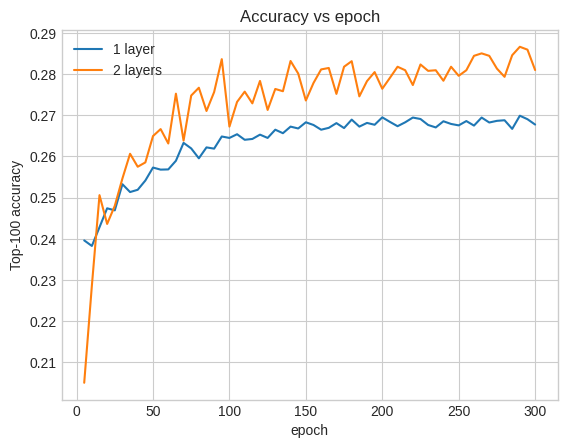
এমনকি প্রশিক্ষণের প্রথম দিকে, বড় মডেলের অগভীর মডেলের উপরে একটি স্পষ্ট এবং স্থিতিশীল নেতৃত্ব রয়েছে, পরামর্শ দেয় যে গভীরতা যোগ করা মডেলটিকে ডেটাতে আরও সূক্ষ্ম সম্পর্ক ক্যাপচার করতে সহায়তা করে।
যাইহোক, এমনকি গভীর মডেল অগত্যা ভাল হয় না. নিম্নলিখিত মডেলটি গভীরতাকে তিনটি স্তরে প্রসারিত করে:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
আসলে, আমরা অগভীর মডেলের উপর উন্নতি দেখতে পাচ্ছি না:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
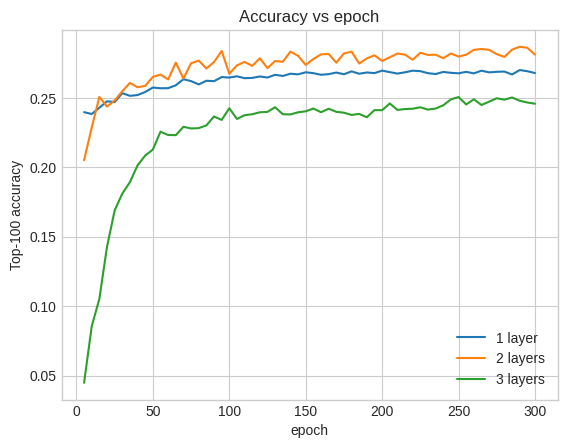
এটি এই সত্যটির একটি ভাল দৃষ্টান্ত যে গভীর এবং বৃহত্তর মডেলগুলি, যদিও উচ্চতর কার্যক্ষমতার জন্য সক্ষম, প্রায়শই খুব যত্নশীল টিউনিংয়ের প্রয়োজন হয়। উদাহরণস্বরূপ, এই টিউটোরিয়াল জুড়ে আমরা একটি একক, নির্দিষ্ট শেখার হার ব্যবহার করেছি। বিকল্প পছন্দগুলি খুব ভিন্ন ফলাফল দিতে পারে এবং এটি অন্বেষণের যোগ্য।
উপযুক্ত টিউনিং এবং পর্যাপ্ত ডেটা সহ, বৃহত্তর এবং গভীর মডেলগুলি তৈরি করার জন্য যে প্রচেষ্টা করা হয়েছে তা অনেক ক্ষেত্রেই উপযুক্ত: বৃহত্তর মডেলগুলি ভবিষ্যদ্বাণীর নির্ভুলতার ক্ষেত্রে যথেষ্ট উন্নতি ঘটাতে পারে৷
পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালে আমরা ঘন স্তর এবং সক্রিয়করণ ফাংশন সহ আমাদের পুনরুদ্ধার মডেল প্রসারিত করেছি। একটি মডেল যে না শুধুমাত্র আহরণ কর্ম বরং রেটিং কর্ম সম্পাদন করতে পারবেন তৈরি করার পদ্ধতি দেখার জন্য, কটাক্ষপাত করা একাধিক কার্য টিউটোরিয়াল ।