
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
في هذا البرنامج التعليمي featurization نحن دمج ميزات متعددة في نماذجنا، ولكن تتكون نماذج من طبقة تضمينها فقط. يمكننا إضافة طبقات أكثر كثافة إلى نماذجنا لزيادة قوتها التعبيرية.
بشكل عام ، النماذج الأعمق قادرة على تعلم أنماط أكثر تعقيدًا من النماذج الضحلة. على سبيل المثال، لدينا نموذج مستخدم يتضمن هويات المستخدمين والطوابع الزمنية لتفضيلات المستخدم نموذجية عند نقطة في الوقت المناسب. قد يكون النموذج الضحل (على سبيل المثال ، طبقة تضمين واحدة) قادرًا فقط على تعلم أبسط العلاقات بين تلك الميزات والأفلام: فيلم معين هو الأكثر شعبية في وقت إطلاقه ، ويفضل مستخدم معين أفلام الرعب عمومًا على الأفلام الكوميدية. لالتقاط علاقات أكثر تعقيدًا ، مثل تطور تفضيلات المستخدم بمرور الوقت ، قد نحتاج إلى نموذج أعمق مع طبقات كثيفة متعددة مكدسة.
بالطبع ، النماذج المعقدة لها أيضًا عيوبها. الأول هو التكلفة الحسابية ، حيث تتطلب النماذج الأكبر حجمًا ذاكرة أكبر والمزيد من العمليات الحسابية لتلائم الخدمة وتخدمها. والثاني هو الحاجة إلى مزيد من البيانات: بشكل عام ، هناك حاجة إلى مزيد من بيانات التدريب للاستفادة من النماذج الأعمق. مع وجود المزيد من المعلمات ، قد تزيد النماذج العميقة أو حتى تحفظ أمثلة التدريب بدلاً من تعلم وظيفة يمكن أن تعمم. أخيرًا ، قد يكون تدريب النماذج الأعمق أكثر صعوبة ، ويجب توخي مزيد من العناية في اختيار إعدادات مثل التنظيم ومعدل التعلم.
إيجاد بنية جيدة لنظام المزكي في العالم الحقيقي هو فن معقدة، وتتطلب الحدس الجيد والدقيق hyperparameter ضبط . على سبيل المثال ، يمكن لعوامل مثل عمق النموذج وعرضه ووظيفة التنشيط ومعدل التعلم والمحسن تغيير أداء النموذج بشكل جذري. تزداد خيارات النمذجة تعقيدًا بسبب حقيقة أن مقاييس التقييم الجيدة غير المتصلة بالإنترنت قد لا تتوافق مع الأداء الجيد عبر الإنترنت ، وأن اختيار ما يجب تحسينه غالبًا ما يكون أكثر أهمية من اختيار النموذج نفسه.
ومع ذلك ، فإن الجهد المبذول في بناء النماذج الأكبر وضبطها يؤتي ثماره غالبًا. في هذا البرنامج التعليمي ، سوف نوضح كيفية بناء نماذج استرجاع عميقة باستخدام مرشحي TensorFlow. سنفعل ذلك من خلال بناء نماذج أكثر تعقيدًا بشكل تدريجي لنرى كيف يؤثر ذلك على أداء النموذج.
مقدمات
نقوم أولاً باستيراد الحزم الضرورية.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import os
import tempfile
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
plt.style.use('seaborn-whitegrid')
في هذا البرنامج التعليمي سوف نستخدم نماذج من وfeaturization البرنامج التعليمي لتوليد التضمينات. ومن ثم سنستخدم فقط معرّف المستخدم والطابع الزمني وميزات عنوان الفيلم.
ratings = tfds.load("movielens/100k-ratings", split="train")
movies = tfds.load("movielens/100k-movies", split="train")
ratings = ratings.map(lambda x: {
"movie_title": x["movie_title"],
"user_id": x["user_id"],
"timestamp": x["timestamp"],
})
movies = movies.map(lambda x: x["movie_title"])
2021-10-02 11:11:47.672650: E tensorflow/stream_executor/cuda/cuda_driver.cc:271] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
نقوم أيضًا ببعض التدبير المنزلي لإعداد المفردات المميزة.
timestamps = np.concatenate(list(ratings.map(lambda x: x["timestamp"]).batch(100)))
max_timestamp = timestamps.max()
min_timestamp = timestamps.min()
timestamp_buckets = np.linspace(
min_timestamp, max_timestamp, num=1000,
)
unique_movie_titles = np.unique(np.concatenate(list(movies.batch(1000))))
unique_user_ids = np.unique(np.concatenate(list(ratings.batch(1_000).map(
lambda x: x["user_id"]))))
تعريف النموذج
نموذج الاستعلام
نبدأ مع نموذج محدد من قبل المستخدم في البرنامج التعليمي featurization والطبقة الأولى من نموذجنا، المكلفة تحويل أمثلة المدخلات الخام إلى التضمينات الميزة.
class UserModel(tf.keras.Model):
def __init__(self):
super().__init__()
self.user_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32),
])
self.timestamp_embedding = tf.keras.Sequential([
tf.keras.layers.Discretization(timestamp_buckets.tolist()),
tf.keras.layers.Embedding(len(timestamp_buckets) + 1, 32),
])
self.normalized_timestamp = tf.keras.layers.Normalization(
axis=None
)
self.normalized_timestamp.adapt(timestamps)
def call(self, inputs):
# Take the input dictionary, pass it through each input layer,
# and concatenate the result.
return tf.concat([
self.user_embedding(inputs["user_id"]),
self.timestamp_embedding(inputs["timestamp"]),
tf.reshape(self.normalized_timestamp(inputs["timestamp"]), (-1, 1)),
], axis=1)
سيتطلب تحديد نماذج أعمق منا تكديس طبقات الوضع أعلى هذا الإدخال الأول. مجموعة طبقات أضيق تدريجيًا ، مفصولة بوظيفة التنشيط ، هي نمط شائع:
+----------------------+
| 128 x 64 |
+----------------------+
| relu
+--------------------------+
| 256 x 128 |
+--------------------------+
| relu
+------------------------------+
| ... x 256 |
+------------------------------+
نظرًا لأن القوة التعبيرية للنماذج الخطية العميقة ليست أكبر من تلك الخاصة بالنماذج الخطية الضحلة ، فإننا نستخدم عمليات تنشيط ReLU للجميع باستثناء الطبقة المخفية الأخيرة. لا تستخدم الطبقة المخفية النهائية أي وظيفة تنشيط: استخدام وظيفة التنشيط سيحد من مساحة الإخراج للتضمينات النهائية وقد يؤثر سلبًا على أداء النموذج. على سبيل المثال ، إذا تم استخدام ReLUs في طبقة الإسقاط ، فإن جميع المكونات في تضمين الإخراج ستكون غير سالبة.
سنقوم بتجربة شيء مشابه هنا. لجعل التجريب باستخدام أعماق مختلفة أمرًا سهلاً ، دعنا نحدد نموذجًا يتم تحديد عمقه (وعرضه) من خلال مجموعة من معلمات المُنشئ.
class QueryModel(tf.keras.Model):
"""Model for encoding user queries."""
def __init__(self, layer_sizes):
"""Model for encoding user queries.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
# We first use the user model for generating embeddings.
self.embedding_model = UserModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
و layer_sizes المعلمة يعطينا عمق وعرض للنموذج. يمكننا تنويعها لتجربة نماذج أعمق أو ضحلة.
نموذج المرشح
يمكننا اعتماد نفس النهج لنموذج الفيلم. مرة أخرى، ونحن نبدأ مع MovieModel من featurization البرنامج التعليمي:
class MovieModel(tf.keras.Model):
def __init__(self):
super().__init__()
max_tokens = 10_000
self.title_embedding = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_movie_titles,mask_token=None),
tf.keras.layers.Embedding(len(unique_movie_titles) + 1, 32)
])
self.title_vectorizer = tf.keras.layers.TextVectorization(
max_tokens=max_tokens)
self.title_text_embedding = tf.keras.Sequential([
self.title_vectorizer,
tf.keras.layers.Embedding(max_tokens, 32, mask_zero=True),
tf.keras.layers.GlobalAveragePooling1D(),
])
self.title_vectorizer.adapt(movies)
def call(self, titles):
return tf.concat([
self.title_embedding(titles),
self.title_text_embedding(titles),
], axis=1)
وقم بتوسيعها بطبقات مخفية:
class CandidateModel(tf.keras.Model):
"""Model for encoding movies."""
def __init__(self, layer_sizes):
"""Model for encoding movies.
Args:
layer_sizes:
A list of integers where the i-th entry represents the number of units
the i-th layer contains.
"""
super().__init__()
self.embedding_model = MovieModel()
# Then construct the layers.
self.dense_layers = tf.keras.Sequential()
# Use the ReLU activation for all but the last layer.
for layer_size in layer_sizes[:-1]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size, activation="relu"))
# No activation for the last layer.
for layer_size in layer_sizes[-1:]:
self.dense_layers.add(tf.keras.layers.Dense(layer_size))
def call(self, inputs):
feature_embedding = self.embedding_model(inputs)
return self.dense_layers(feature_embedding)
نموذج مدمج
مع كل QueryModel و CandidateModel محددة، يمكن أن نضع معا نموذجا المشترك وتنفيذ لدينا الخسارة ومقاييس المنطق. لتبسيط الأمور ، سنفرض أن بنية النموذج هي نفسها عبر نماذج الاستعلام والنماذج المرشحة.
class MovielensModel(tfrs.models.Model):
def __init__(self, layer_sizes):
super().__init__()
self.query_model = QueryModel(layer_sizes)
self.candidate_model = CandidateModel(layer_sizes)
self.task = tfrs.tasks.Retrieval(
metrics=tfrs.metrics.FactorizedTopK(
candidates=movies.batch(128).map(self.candidate_model),
),
)
def compute_loss(self, features, training=False):
# We only pass the user id and timestamp features into the query model. This
# is to ensure that the training inputs would have the same keys as the
# query inputs. Otherwise the discrepancy in input structure would cause an
# error when loading the query model after saving it.
query_embeddings = self.query_model({
"user_id": features["user_id"],
"timestamp": features["timestamp"],
})
movie_embeddings = self.candidate_model(features["movie_title"])
return self.task(
query_embeddings, movie_embeddings, compute_metrics=not training)
تدريب النموذج
تحضير البيانات
قمنا أولاً بتقسيم البيانات إلى مجموعة تدريب ومجموعة اختبار.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
cached_train = train.shuffle(100_000).batch(2048)
cached_test = test.batch(4096).cache()
نموذج ضحل
نحن على استعداد لتجربة نموذجنا الأول الضحل!
num_epochs = 300
model = MovielensModel([32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
one_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.27.
هذا يعطينا دقة أعلى 100 تبلغ حوالي 0.27. يمكننا استخدام هذا كنقطة مرجعية لتقييم النماذج الأعمق.
نموذج أعمق
ماذا عن نموذج أعمق ذو طبقتين؟
model = MovielensModel([64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
two_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.29.
الدقة هنا هي 0.29 ، وهي أفضل قليلاً من النموذج الضحل.
يمكننا رسم منحنيات دقة التحقق لتوضيح ذلك:
num_validation_runs = len(one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"])
epochs = [(x + 1)* 5 for x in range(num_validation_runs)]
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c7513d0>
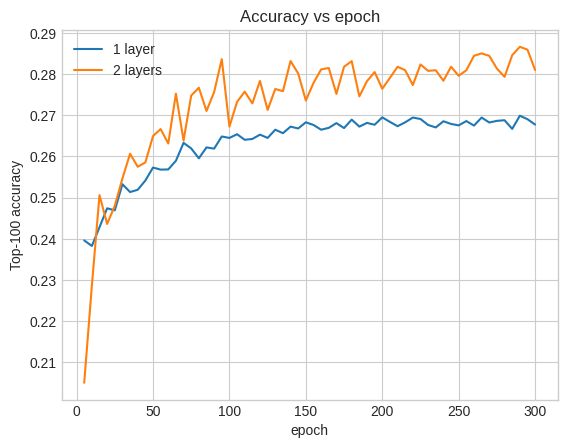
حتى في وقت مبكر من التدريب ، يتمتع النموذج الأكبر بتقدم واضح ومستقر على النموذج الضحل ، مما يشير إلى أن إضافة العمق تساعد النموذج على التقاط علاقات أكثر دقة في البيانات.
ومع ذلك ، فحتى النماذج الأعمق ليست بالضرورة أفضل. النموذج التالي يمتد العمق إلى ثلاث طبقات:
model = MovielensModel([128, 64, 32])
model.compile(optimizer=tf.keras.optimizers.Adagrad(0.1))
three_layer_history = model.fit(
cached_train,
validation_data=cached_test,
validation_freq=5,
epochs=num_epochs,
verbose=0)
accuracy = three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"][-1]
print(f"Top-100 accuracy: {accuracy:.2f}.")
Top-100 accuracy: 0.26.
في الواقع ، لا نرى تحسنًا على النموذج الضحل:
plt.plot(epochs, one_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="1 layer")
plt.plot(epochs, two_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="2 layers")
plt.plot(epochs, three_layer_history.history["val_factorized_top_k/top_100_categorical_accuracy"], label="3 layers")
plt.title("Accuracy vs epoch")
plt.xlabel("epoch")
plt.ylabel("Top-100 accuracy");
plt.legend()
<matplotlib.legend.Legend at 0x7f841c6d8590>
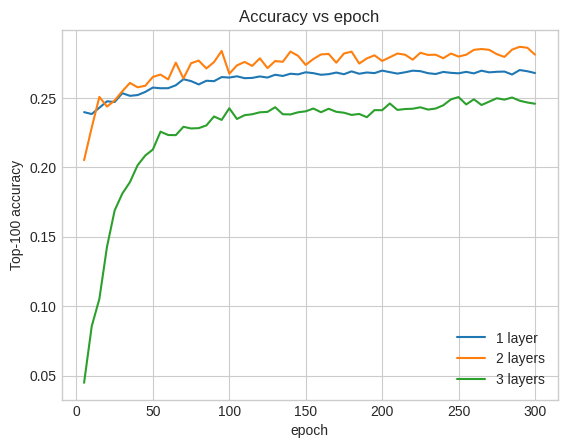
هذا توضيح جيد لحقيقة أن النماذج الأعمق والأكبر ، رغم قدرتها على الأداء المتفوق ، غالبًا ما تتطلب ضبطًا دقيقًا للغاية. على سبيل المثال ، خلال هذا البرنامج التعليمي ، استخدمنا معدل تعلم واحدًا وثابتًا. قد تعطي الخيارات البديلة نتائج مختلفة جدًا وتستحق الاستكشاف.
مع الضبط المناسب والبيانات الكافية ، فإن الجهد المبذول في بناء نماذج أكبر وأعمق يستحق في كثير من الحالات: النماذج الأكبر يمكن أن تؤدي إلى تحسينات جوهرية في دقة التنبؤ.
الخطوات التالية
في هذا البرنامج التعليمي ، قمنا بتوسيع نموذج الاسترجاع الخاص بنا بطبقات كثيفة ووظائف التنشيط. لمعرفة كيفية إنشاء نموذج التي يمكن أن تؤدي ليس فقط المهام استرجاع ولكن أيضا مهام تقييم، نلقي نظرة على لتعدد المهام البرنامج التعليمي .