
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu eğitici, özellik çaprazlarını etkili bir şekilde öğrenmek için Derin ve Çapraz Ağın (DCN) nasıl kullanılacağını gösterir.
Arka plan
Özellik çaprazları nedir ve neden önemlidir? Müşterilere bir blender satmak için bir tavsiye sistemi oluşturduğumuzu hayal edin. Daha sonra, örneğin bir müşterinin geçmişteki satın alma geçmişi purchased_bananas ve purchased_cooking_books veya coğrafi özellikler, tek özellikleridir. Bir muz ve pişirme kitapları hem satın aldıysa, o zaman bu müşteri daha muhtemel önerilen blender tıklar. Kombinasyonu purchased_bananas ve purchased_cooking_books bireysel özelliklerin ötesinde ek bir etkileşim bilgi sağlayan bir özelliği çapraz olarak adlandırılır.
Özellik çaprazlarını öğrenmedeki zorluklar nelerdir? Web ölçeğindeki uygulamalarda, veriler çoğunlukla kategoriktir, bu da geniş ve seyrek özellik alanına yol açar. Bu ayarda etkin özellik kesişimlerini belirlemek, genellikle manuel özellik mühendisliği veya kapsamlı arama gerektirir. Geleneksel ileri beslemeli çok katmanlı algılayıcı (MLP) modelleri evrensel fonksiyon tahmin edicileridir; ancak, verimli bile 2. veya 3. dereceden özelliği haç [yakın olamamasıdır 1 , 2 ].
Derin ve Çapraz Ağ (DCN) nedir? DCN, açık ve sınırlı dereceli çapraz özellikleri daha etkili bir şekilde öğrenmek için tasarlanmıştır. Bu, birden fazla çapraz katman içeren bir enine ağ, ardından bir giriş tabakası (tipik olarak bir gömme tabakası) ile başlar, derin ağı ile daha sonra modelleri açık özellik etkileşimleri ve biçerdöverler modelleri örtülü özelliği etkileşimleri o.
- Çapraz Ağ. Bu, DCN'nin özüdür. Açıkça her katmanda özellik geçişi uygular ve en yüksek polinom derecesi katman derinliği ile artar. Aşağıdaki şekil göstermektedir \((i+1)\)çapraz tabaka inci.
- Derin Ağ. Geleneksel bir ileri beslemeli çok katmanlı algılayıcıdır (MLP).
Derin ağı ve çapraz ağ daha sonra DCN [oluşturmak üzere birleştirilir 1 ]. Genelde, derin bir ağı çapraz ağın (yığılmış yapı) üzerine yığabiliriz; onları paralel olarak da yerleştirebiliriz (paralel yapı).
Aşağıda, önce bir oyuncak örneğiyle DCN'nin avantajını göstereceğiz ve ardından MovieLen-1M veri kümesini kullanarak DCN'yi kullanmanın bazı yaygın yollarında size yol göstereceğiz.
Öncelikle bu colab için gerekli paketleri kurup import edelim.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
Oyuncak Örneği
DCN'nin faydalarını göstermek için basit bir örnek üzerinde çalışalım. Bir müşterinin bir blender Reklamına tıklama olasılığını modellemeye çalıştığımız bir veri kümemiz olduğunu varsayalım, özellikleri ve etiketi aşağıda açıklanan şekilde olsun.
| Özellikler / Etiket | Açıklama | Değer Türü / Aralığı |
|---|---|---|
| \(x_1\) = ülke | bu müşterinin yaşadığı ülke | Int [0, 199] |
| \(x_2\) = muz | # müşterinin satın aldığı muz | Int [0, 23] |
| \(x_3\) yemek kitapları = | # müşterinin satın aldığı yemek kitapları | Int [0, 5] |
| \(y\) | bir blender Reklamına tıklama olasılığı | -- |
Ardından, verilerin aşağıdaki temel dağılımı izlemesine izin veriyoruz:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
olabilirlik burada \(y\) özellikleri doğrusal de bağlıdır \(x_i\)'in değil, aynı zamanda arasında çarpımsal etkileşimlere \(x_i\)s'. Bizim durumumuzda, biz bir blender (satın alma olasılığı olduğunu söyleyebilirim\(y\)) sadece muz (satın alma değil bağlıdır\(x_2\)) ya da yemek kitapları (\(x_3\)) değil, aynı zamanda birlikte muz ve yemek kitapları satın (üzerinde\(x_2x_3\)).
Bunun için verileri şu şekilde üretebiliriz:
Sentetik veri üretimi
İlk tanımlayan \(f(x_1, x_2, x_3)\) yukarıda tarif edildiği gibi.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
Dağılımı takip eden verileri oluşturalım ve verileri eğitim için %90 ve test için %10 olarak ayıralım.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
Model yapımı
Bir çapraz ağın tavsiye sahiplerine getirebileceği avantajı göstermek için hem çapraz ağı hem de derin ağı deneyeceğiz. Az önce oluşturduğumuz veriler sadece 2. dereceden özellik etkileşimlerini içerdiğinden, tek katmanlı bir çapraz ağ ile göstermek yeterli olacaktır. Daha yüksek dereceli özellik etkileşimlerini modellemek istersek, birden çok çapraz katmanı istifleyebilir ve çok katmanlı bir çapraz ağ kullanabiliriz. İnşa edeceğimiz iki model:
- Yalnızca bir çapraz katmanla Çapraz Ağ;
- Daha geniş ve daha derin ReLU katmanlarına sahip Derin Ağ.
Önce kaybı ortalama kare hatası olan birleştirilmiş bir model sınıfı oluşturuyoruz.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
Ardından, çapraz ağı (1 çapraz katman boyutu 3 ile) ve ReLU tabanlı DNN'yi (katman boyutları [512, 256, 128] ile) belirleriz:
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
Model eğitimi
Artık veriler ve modeller hazır olduğuna göre, modelleri eğiteceğiz. Model eğitimine hazırlanmak için önce verileri karıştırıp topluyoruz.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
Ardından, öğrenme hızının yanı sıra dönem sayısını da tanımlarız.
epochs = 100
learning_rate = 0.4
Pekala, şimdi her şey hazır ve modelleri derleyip eğitelim. Sen ayarlayabilirsiniz verbose=True nasıl modeli ilerledikçe görmek istiyorsanız.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
Model değerlendirmesi
Model performansını değerlendirme veri setinde doğrularız ve Kök Ortalama Kare Hatasını rapor ederiz (RMSE, ne kadar düşükse o kadar iyidir).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
Biz çapraz ağ elde büyüklükleri büyüklükleri az parametrelerle bir relu merkezli DNN daha RMSE düşürmek görüyoruz. Bu, özellik çaprazlarını öğrenmede bir çapraz ağın etkinliğini önerdi.
Model anlayışı
Verilerimizde hangi özellik çaprazlarının önemli olduğunu zaten biliyoruz, modelimizin önemli özellik çaprazını gerçekten öğrenip öğrenmediğini kontrol etmek eğlenceli olurdu. Bu, öğrenilen ağırlık matrisini DCN'de görselleştirerek yapılabilir. Ağırlık \(W_{ij}\) özelliği arasındaki etkileşimin öğrenilen teşkil etmektedir \(x_i\) ve \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
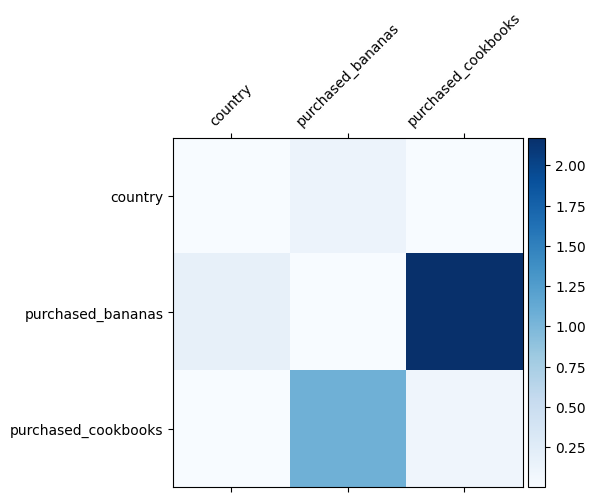
Daha koyu renkler daha güçlü öğrenilmiş etkileşimleri temsil eder - bu durumda modelin babanas ve yemek kitaplarını birlikte satın almanın önemli olduğunu öğrendiği açıktır.
Daha karmaşık sentetik veri denediğiniz ilgilenen varsa, kontrol etmek çekinmeyin bu kağıdı .
Movielens 1M örneği
Şimdi gerçek dünyadaki bir veri kümesi üzerinde DCN etkinliğini incelemek: Movielens 1M [ 3 ]. Movielens 1M, öneri araştırması için popüler bir veri kümesidir. Kullanıcıyla ilgili özellikler ve filmle ilgili özellikler göz önüne alındığında, kullanıcıların film derecelendirmelerini tahmin eder. DCN'yi kullanmanın bazı yaygın yollarını göstermek için bu veri kümesini kullanıyoruz.
Veri işleme
Veri işleme prosedürü benzer bir prosedür takip temel sıralama öğretici .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
Ardından, verileri rastgele olarak eğitim için %80 ve test için %20 olarak ayırdık.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
Ardından, her özellik için kelime dağarcığı oluşturuyoruz.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
Model yapımı
İnşa edeceğimiz model mimarisi, derin bir ağ tarafından takip edilen bir çapraz ağa beslenen bir gömme katmanı ile başlar. Gömme boyutu, tüm özellikler için 32'ye ayarlanmıştır. Farklı özellikler için farklı gömme boyutları da kullanabilirsiniz.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
Model eğitimi
Eğitim ve test verilerini karıştırır, gruplandırır ve önbelleğe alırız.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
Bir modeli birden çok kez çalıştıran ve birden çok çalıştırmadan modelin RMSE ortalamasını ve standart sapmasını döndüren bir işlev tanımlayalım.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
Modeller için bazı hiper parametreler belirledik. Bu hiper parametrelerin, gösterim amacıyla tüm modeller için global olarak ayarlandığını unutmayın. Her model için en iyi performansı elde etmek veya modeller arasında adil bir karşılaştırma yapmak istiyorsanız, hiper parametrelerde ince ayar yapmanızı öneririz. Model mimarisi ve optimizasyon şemalarının iç içe olduğunu unutmayın.
epochs = 8
learning_rate = 0.01
DCN (yığılmış). Önce yığılmış bir yapıya sahip bir DCN modelini eğitiyoruz, yani girdiler bir çapraz ağa ve ardından derin bir ağa besleniyor.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
Düşük dereceli DCN. Eğitim ve hizmet maliyetini azaltmak için DCN ağırlık matrislerine yaklaşmak için düşük dereceli tekniklerden yararlanıyoruz. Rütbe argüman yoluyla geçirilen projection_dim ; Daha küçük projection_dim daha düşük bir maliyetle sonuçlanır. Bu Not projection_dim ihtiyaçları maliyetini azaltmak için (giriş boyutu) / 2 den daha küçük olması. Uygulamada, derece (giriş boyutu)/4 ile düşük dereceli DCN kullanmanın tam dereceli bir DCN'nin doğruluğunu tutarlı bir şekilde koruduğunu gözlemledik.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. Aynı boyutta bir DNN modelini referans olarak eğitiyoruz.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
Modeli test verileri üzerinde değerlendirir ve 5 çalıştırmanın ortalamasını ve standart sapmasını rapor ederiz.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
DCN'nin ReLU katmanlarına sahip aynı boyutlu bir DNN'den daha iyi performans elde ettiğini görüyoruz. Ayrıca, düşük dereceli DCN, doğruluğu korurken parametreleri azaltabildi.
DCN'de daha fazlası. Yukarıda gösterilmiş, neyin yanında DCN [yararlanmak için daha yaratıcı henüz pratik açıdan yararlı yolu vardır 1 ].
Paralel bir yapıya sahip DCN. Girişler, bir çapraz ağa ve bir derin ağa paralel olarak beslenir.
Birleştirilmiş çapraz katmanlar. Girişler, tamamlayıcı özellik çaprazlarını yakalamak için çoklu çapraz katmanlara paralel olarak beslenir.
Model anlayışı
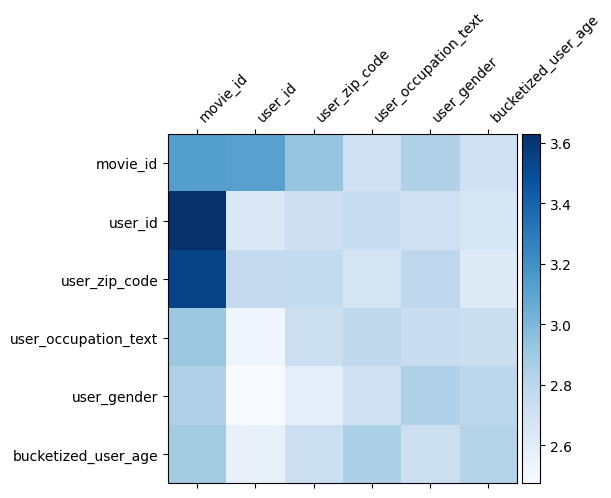
Ağırlık matrisi \(W\) DCN özellik modeli önemli olduğu öğrendi haçlar neyi ortaya koymaktadır. Önceki oyuncak örnekte, arasındaki etkileşimlerin önemi, geri çağırma \(i\)inci ve \(j\)özellikleri inci (tarafından yakalanır\(i, j\)) arasında inci elemanı \(W\).
Ne biraz daha farklı burada özellik kalıplamaların boyutu 32 yerine Dolayısıyla büyüklüğü 1. olan önemi ile karakterize olmasıdır \((i, j)\)inci blok\(W_{i,j}\) Aşağıda 32'ye göre boyut 32 olduğu için, Frobemino norm [görselleştirmek 4 ] \(||W_{i,j}||_F\) her bloğun ve daha yüksek önemine işaret edecek bir daha büyük bir norm (özellikleri kalıplamaların benzer ölçeklerin varsayılarak).
Blok normunun yanı sıra, tüm matrisi veya her bloğun ortalama/medyan/maks değerini de görselleştirebiliriz.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
Hepsi bu iş birliği için! DCN'nin bazı temellerini ve onu kullanmanın yaygın yollarını öğrenmekten keyif aldığınızı umuyoruz. : Daha fazla bilgi edinmek ilgilenen varsa, iki ilgili kağıtlarını kontrol edebilir DCN-v1 kağıdı , DCN-v2-kağıt .
Referanslar
DCN V2: Sıra Sistemleri Web ölçekli Öğrenme Derin & Çapraz Ağ ve Pratik Dersler Geliştirilmiş .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
Reklam tıklayın Tahminler için Derin & Ağlar Arası .
Ruoxi Wang, Bin Fu, Gang Fu, Mingliang Wang. (AdKDD 2017)