
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทช่วยสอนนี้สาธิตวิธีใช้ Deep & Cross Network (DCN) เพื่อเรียนรู้คุณลักษณะข้ามอย่างมีประสิทธิภาพ
พื้นหลัง
คุณลักษณะข้ามคืออะไรและเหตุใดจึงสำคัญ ลองนึกภาพว่าเรากำลังสร้างระบบแนะนำเพื่อขายเครื่องปั่นให้กับลูกค้า จากนั้นประวัติการซื้อของลูกค้าที่ผ่านมาเช่น purchased_bananas และ purchased_cooking_books หรือคุณลักษณะทางภูมิศาสตร์ที่มีคุณสมบัติเดียว หากหนึ่งได้ซื้อทั้งกล้วยและหนังสือการปรุงอาหารแล้วลูกค้ารายนี้มีแนวโน้มที่จะคลิกที่ปั่นแนะนำ การรวมกันของ purchased_bananas และ purchased_cooking_books จะเรียกว่าข้ามคุณลักษณะซึ่งให้ข้อมูลเพิ่มเติมนอกเหนือจากการมีปฏิสัมพันธ์คุณลักษณะของบุคคล
อะไรคือความท้าทายในการเรียนรู้คุณลักษณะข้าม? ในแอปพลิเคชันระดับเว็บ ข้อมูลส่วนใหญ่จะจัดเป็นหมวดหมู่ นำไปสู่พื้นที่คุณลักษณะขนาดใหญ่และกระจัดกระจาย การระบุจุดตัดของคุณลักษณะที่มีประสิทธิภาพในการตั้งค่านี้มักต้องใช้วิศวกรรมคุณลักษณะด้วยตนเองหรือการค้นหาอย่างละเอียดถี่ถ้วน โมเดล perceptron multilayer perceptron (MLP) แบบ feed-forward แบบดั้งเดิมเป็นตัวประมาณฟังก์ชันสากล แต่พวกเขาไม่สามารถได้อย่างมีประสิทธิภาพใกล้เคียงแม้ 2 หรือ 3 สั่งไม้กางเขนคุณลักษณะ [ 1 , 2 ]
Deep & Cross Network (DCN) คืออะไร? DCN ได้รับการออกแบบมาเพื่อเรียนรู้คุณลักษณะข้ามระดับที่ชัดเจนและมีขอบเขตอย่างมีประสิทธิภาพมากขึ้น มันเริ่มต้นด้วยการป้อนข้อมูลชั้น (ปกติชั้นฝัง) ตามด้วยเครือข่ายที่มีการข้ามชั้นข้ามหลายรุ่นอย่างชัดเจนปฏิสัมพันธ์คุณลักษณะแล้วรวมกับเครือข่ายลึกว่ารูปแบบการปฏิสัมพันธ์นัยคุณลักษณะ
- ข้ามเครือข่าย นี่คือแกนหลักของ DCN โดยจะใช้การข้ามคุณลักษณะในแต่ละเลเยอร์อย่างชัดเจน และดีกรีพหุนามสูงสุดจะเพิ่มขึ้นตามความลึกของเลเยอร์ ต่อไปนี้แสดงให้เห็นว่ารูป \((i+1)\)-th ชั้นข้าม
- เครือข่ายลึก มันเป็น feedforward multilayer perceptron (MLP) แบบดั้งเดิม
เครือข่ายลึกและเครือข่ายข้ามจะรวมกันแล้วในรูปแบบ DCN [ 1 ] โดยทั่วไป เราสามารถซ้อนเครือข่ายลึกบนเครือข่ายข้าม (โครงสร้างแบบซ้อน); เราสามารถวางพวกมันขนานกัน (โครงสร้างคู่ขนาน)
ต่อไปนี้ เราจะแสดงข้อดีของ DCN ด้วยตัวอย่างของเล่นก่อน จากนั้นเราจะแนะนำวิธีทั่วไปบางประการในการใช้ DCN โดยใช้ชุดข้อมูล MovieLen-1M
ขั้นแรก มาติดตั้งและนำเข้าแพ็คเกจที่จำเป็นสำหรับ colab นี้
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
ตัวอย่างของเล่น
เพื่อแสดงประโยชน์ของ DCN มาดูตัวอย่างง่ายๆ สมมติว่าเรามีชุดข้อมูลที่เราพยายามจำลองแนวโน้มที่ลูกค้าจะคลิกโฆษณา Blender โดยมีคุณลักษณะและป้ายกำกับอธิบายไว้ดังนี้
| คุณสมบัติ / ฉลาก | คำอธิบาย | ประเภทค่า / ช่วง |
|---|---|---|
| \(x_1\) = ประเทศ | ประเทศที่ลูกค้ารายนี้อาศัยอยู่ | อินท์ใน [0, 1999] |
| \(x_2\) = กล้วย | #กล้วยที่ลูกค้าซื้อ | อินท์ใน [0, 23] |
| \(x_3\) = ตำรา | #หนังสือทำอาหารที่ลูกค้าซื้อ | อินท์ใน [0, 5] |
| \(y\) | โอกาสที่จะคลิกที่เครื่องปั่นAd | -- |
จากนั้น เราปล่อยให้ข้อมูลติดตามการแจกแจงพื้นฐานต่อไปนี้:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
ที่น่าจะเป็น \(y\) ขึ้นเป็นเส้นตรงทั้งในคุณลักษณะ \(x_i\)'s แต่ยังเกี่ยวกับการมีปฏิสัมพันธ์ระหว่างคูณ \(x_i\)' s ในกรณีที่เราจะบอกว่าน่าจะเป็นของการจัดซื้อเครื่องปั่น (คน\(y\)) ขึ้นไม่เพียง แต่ในการซื้อกล้วย (\(x_2\)) หรือตำรา (\(x_3\)) แต่ยังในการซื้อกล้วยและตำรากัน (\(x_2x_3\)).
เราสามารถสร้างข้อมูลสำหรับสิ่งนี้ได้ดังนี้:
การสร้างข้อมูลสังเคราะห์
ครั้งแรกที่เรากำหนด \(f(x_1, x_2, x_3)\) ตามที่อธิบายไว้ข้างต้น
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
มาสร้างข้อมูลที่ตามการแจกแจงกัน และแบ่งข้อมูลออกเป็น 90% สำหรับการฝึกอบรมและ 10% สำหรับการทดสอบ
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
การสร้างแบบจำลอง
เราจะลองใช้ทั้งเครือข่ายข้ามเครือข่ายและเครือข่ายระดับลึกเพื่อแสดงข้อได้เปรียบที่เครือข่ายข้ามสามารถนำมาสู่ผู้แนะนำได้ เนื่องจากข้อมูลที่เราเพิ่งสร้างขึ้นมีเพียงการโต้ตอบของฟีเจอร์ลำดับที่ 2 จึงเพียงพอที่จะแสดงภาพด้วยเครือข่ายข้ามชั้นเดียว หากเราต้องการสร้างแบบจำลองการโต้ตอบของฟีเจอร์ที่มีลำดับสูงกว่า เราสามารถซ้อนเลเยอร์ข้ามหลายเลเยอร์และใช้เครือข่ายข้ามแบบหลายเลเยอร์ได้ สองแบบจำลองที่เราจะสร้างคือ:
- ข้ามเครือข่ายที่มีชั้นข้ามเพียงชั้นเดียว
- Deep Network พร้อมเลเยอร์ ReLU ที่กว้างและลึกยิ่งขึ้น
ขั้นแรก เราสร้างคลาสโมเดลที่เป็นหนึ่งเดียวซึ่งการสูญเสียคือความคลาดเคลื่อนกำลังสองเฉลี่ย
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
จากนั้น เราระบุ cross network (ด้วย 1 cross layer ขนาด 3) และ ReLU-based DNN (ด้วยขนาดเลเยอร์ [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
การฝึกโมเดล
ตอนนี้เรามีข้อมูลและแบบจำลองพร้อมแล้ว เรากำลังจะไปฝึกแบบจำลอง ก่อนอื่น เราสุ่มและแบทช์ข้อมูลเพื่อเตรียมสำหรับการฝึกโมเดล
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
จากนั้น เรากำหนดจำนวนยุคตลอดจนอัตราการเรียนรู้
epochs = 100
learning_rate = 0.4
เอาล่ะ ทุกอย่างพร้อมแล้ว มาคอมไพล์และฝึกโมเดลกัน คุณสามารถตั้ง verbose=True ถ้าคุณต้องการที่จะเห็นว่ารูปแบบการดำเนิน
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
การประเมินแบบจำลอง
เราตรวจสอบประสิทธิภาพของแบบจำลองในชุดข้อมูลการประเมินและรายงานข้อผิดพลาด Root Mean Squared (RMSE ยิ่งต่ำยิ่งดี)
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
เราจะเห็นว่าเครือข่ายข้ามประสบความสำเร็จขนาดลด RMSE กว่า Relu ตาม DNN มีพารามิเตอร์เคาะน้อยลง สิ่งนี้ชี้ให้เห็นถึงประสิทธิภาพของเครือข่ายแบบไขว้ในการเรียนรู้การข้ามคุณสมบัติ
ความเข้าใจแบบจำลอง
เราทราบแล้วว่าการข้ามคุณลักษณะใดมีความสำคัญในข้อมูลของเรา การตรวจสอบว่าแบบจำลองของเราได้เรียนรู้คุณลักษณะข้ามที่สำคัญแล้วจริงหรือไม่ ซึ่งสามารถทำได้โดยการแสดงภาพเมทริกซ์น้ำหนักที่เรียนรู้ใน DCN น้ำหนัก \(W_{ij}\) แสดงให้เห็นถึงความสำคัญของการเรียนรู้ของการปฏิสัมพันธ์ระหว่างคุณลักษณะ \(x_i\) และ \(x_j\)
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
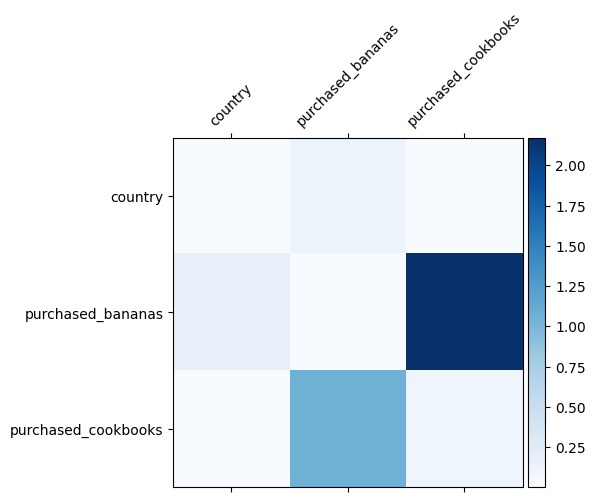
สีเข้มแสดงถึงปฏิสัมพันธ์ที่เรียนรู้ได้ดีขึ้น ในกรณีนี้ เห็นได้ชัดว่านางแบบได้เรียนรู้ว่าการซื้อบาบาน่าและตำราอาหารร่วมกันเป็นสิ่งสำคัญ
หากคุณมีความสนใจในการพยายามออกข้อมูลสังเคราะห์ที่มีความซับซ้อนมากขึ้นรู้สึกอิสระที่จะตรวจสอบ บทความนี้
ตัวอย่างเลนส์มูฟวี่ 1M
ตอนนี้เราตรวจสอบประสิทธิภาพของ DCN ในชุดข้อมูลที่แท้จริงของโลก: Movielens 1M [ 3 ] Movielens 1M เป็นชุดข้อมูลยอดนิยมสำหรับการวิจัยคำแนะนำ มันคาดการณ์การจัดอันดับภาพยนตร์ของผู้ใช้ตามคุณสมบัติที่เกี่ยวข้องกับผู้ใช้และคุณสมบัติที่เกี่ยวข้องกับภาพยนตร์ เราใช้ชุดข้อมูลนี้เพื่อสาธิตวิธีทั่วไปบางประการในการใช้ DCN
การประมวลผลข้อมูล
ขั้นตอนการประมวลผลข้อมูลต่อไปนี้เป็นขั้นตอนที่คล้ายกันเป็น กวดวิชาพื้นฐานการจัดอันดับ
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
ต่อไป เราสุ่มแบ่งข้อมูลออกเป็น 80% สำหรับการฝึกอบรมและ 20% สำหรับการทดสอบ
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
จากนั้นเราสร้างคำศัพท์สำหรับแต่ละคุณสมบัติ
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
การสร้างแบบจำลอง
สถาปัตยกรรมแบบจำลองที่เราจะสร้างเริ่มต้นด้วยเลเยอร์การฝัง ซึ่งป้อนเข้าในเครือข่ายข้ามตามด้วยเครือข่ายลึก มิติข้อมูลการฝังถูกตั้งค่าเป็น 32 สำหรับคุณลักษณะทั้งหมด คุณยังสามารถใช้ขนาดการฝังที่แตกต่างกันสำหรับคุณลักษณะต่างๆ ได้
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
การฝึกโมเดล
เราสับเปลี่ยน แบทช์ และแคชข้อมูลการฝึกอบรมและทดสอบ
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
มากำหนดฟังก์ชันที่เรียกใช้แบบจำลองหลายครั้งและส่งคืนค่าเฉลี่ย RMSE และค่าเบี่ยงเบนมาตรฐานของแบบจำลองจากการรันหลายครั้ง
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
เราตั้งค่าไฮเปอร์พารามิเตอร์สำหรับโมเดล โปรดทราบว่าไฮเปอร์พารามิเตอร์เหล่านี้ได้รับการตั้งค่าทั่วโลกสำหรับโมเดลทั้งหมดเพื่อการสาธิต หากคุณต้องการได้รับประสิทธิภาพที่ดีที่สุดสำหรับแต่ละรุ่น หรือทำการเปรียบเทียบอย่างยุติธรรมระหว่างรุ่นต่างๆ เราขอแนะนำให้คุณปรับแต่งไฮเปอร์พารามิเตอร์ โปรดจำไว้ว่าสถาปัตยกรรมแบบจำลองและโครงร่างการปรับให้เหมาะสมนั้นเชื่อมโยงกัน
epochs = 8
learning_rate = 0.01
DCN (ซ้อนกัน) ขั้นแรก เราฝึกโมเดล DCN ที่มีโครงสร้างแบบซ้อน นั่นคือ อินพุตจะถูกป้อนไปยังเครือข่ายข้ามตามด้วยเครือข่ายลึก
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN ระดับต่ำ เพื่อลดต้นทุนการฝึกอบรมและการให้บริการ เราใช้ประโยชน์จากเทคนิคระดับต่ำเพื่อประมาณเมทริกซ์น้ำหนัก DCN อันดับจะถูกส่งผ่านอาร์กิวเมนต์ projection_dim ; ที่มีขนาดเล็ก projection_dim ผลในการลดค่าใช้จ่าย โปรดทราบว่า projection_dim ความต้องการที่จะมีขนาดเล็กกว่า (ขนาดอินพุต) / 2 เพื่อลดค่าใช้จ่าย ในทางปฏิบัติ เราได้สังเกตการใช้ DCN ระดับต่ำที่มีอันดับ (ขนาดอินพุต)/4 รักษาความถูกต้องของ DCN ระดับเต็มอย่างสม่ำเสมอ
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
ดีเอ็นเอ็น. เราฝึกโมเดล DNN ขนาดเดียวกันเพื่อเป็นข้อมูลอ้างอิง
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
เราประเมินแบบจำลองจากข้อมูลการทดสอบและรายงานค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐานจากการวิ่ง 5 รอบ
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
เราเห็นว่า DCN มีประสิทธิภาพที่ดีกว่า DNN ขนาดเดียวกันที่มีเลเยอร์ ReLU นอกจากนี้ DCN ระดับต่ำยังสามารถลดพารามิเตอร์ในขณะที่ยังคงความถูกต้องไว้
เพิ่มเติมเกี่ยวกับ DCN นอกจาก what've ได้แสดงให้เห็นข้างต้นมีวิธีการยังมีประโยชน์ในทางปฏิบัติที่สร้างสรรค์มากขึ้นที่จะใช้ DCN [ 1 ]
DCN มีโครงสร้างแบบคู่ขนาน อินพุตถูกป้อนขนานกับเครือข่ายข้ามและเครือข่ายลึก
การต่อชั้นข้าม อินพุตถูกป้อนขนานกับเลเยอร์ไขว้หลายชั้นเพื่อจับการข้ามคุณสมบัติเสริม
ความเข้าใจแบบจำลอง
น้ำหนักเมทริกซ์ \(W\) ใน DCN เผยให้เห็นสิ่งคุณลักษณะข้ามรุ่นได้เรียนรู้ที่จะมีความสำคัญ จำได้ว่าในตัวอย่างของเล่นที่ก่อนหน้านี้ความสำคัญของการปฏิสัมพันธ์ระหว่าง \(i\)-th และ \(j\)-th มีถูกจับโดย (\(i, j\)) องค์ประกอบของ -th \(W\)
มีอะไรที่แตกต่างกันเล็กน้อยที่นี่เป็นที่ embeddings คุณลักษณะมีขนาด 32 แทนขนาด 1 ดังนั้นความสำคัญจะโดดเด่นด้วย \((i, j)\)บล็อก -th\(W_{i,j}\) ซึ่งเป็นมิติ 32 จาก 32 ในต่อไปนี้เรา เห็นภาพ Frobenius บรรทัดฐาน [ 4 ] \(||W_{i,j}||_F\) ของแต่ละบล็อกและบรรทัดฐานที่มีขนาดใหญ่จะแนะนำให้ความสำคัญสูง (สมมติว่าคุณสมบัติ embeddings มีเกล็ดคล้ายกัน)
นอกจากบรรทัดฐานของบล็อกแล้ว เรายังสามารถเห็นภาพเมทริกซ์ทั้งหมด หรือค่ากลาง/ค่ามัธยฐาน/สูงสุดของแต่ละบล็อก
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
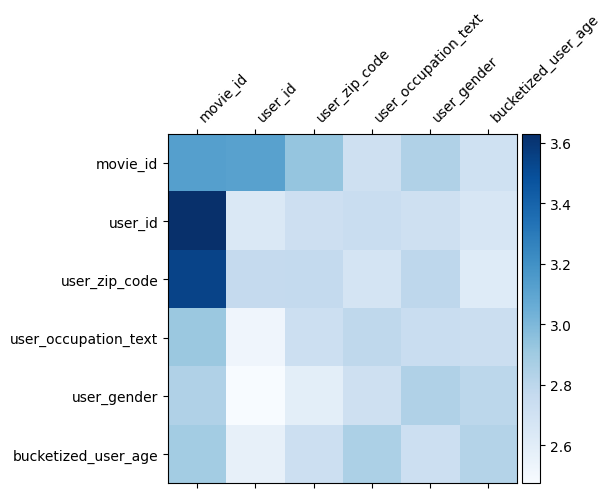
นั่นคือทั้งหมดสำหรับ colab นี้! เราหวังว่าคุณจะสนุกกับการเรียนรู้พื้นฐานของ DCN และวิธีทั่วไปในการใช้งาน หากคุณมีความสนใจในการเรียนรู้มากขึ้นคุณสามารถตรวจสอบสองเอกสารที่เกี่ยวข้อง: DCN-v1 กระดาษ , DCN-v2 กระดาษ
อ้างอิง
DCN V2: ปรับปรุงลึกและข้ามเครือข่ายและบทเรียนการปฏิบัติสำหรับการเรียนรู้บนเว็บขนาดไปที่ Systems อันดับ
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, เอ็ดจี้ (2020)
ลึกและข้ามเครือข่ายโฆษณาคลิกที่คาดการณ์
รัวซี หวาง, ปินฟู่, กังฟู, หมิงเหลียงหวาง. (AdKDD 2017)