
| | |  Ver fonte no GitHub Ver fonte no GitHub | |
Este tutorial demonstra como usar Deep & Cross Network (DCN) para aprender cruzamentos de recursos com eficácia.
Fundo
O que são cruzamentos de recursos e por que são importantes? Imagine que estejamos construindo um sistema de recomendação para vender um liquidificador aos clientes. Então, histórico de compras passado de um cliente, como purchased_bananas e purchased_cooking_books , ou características geográficas, são características individuais. Se alguém comprou duas bananas e livros de cozinha, em seguida, esse cliente será mais provável clique no liquidificador recomendada. A combinação de purchased_bananas e purchased_cooking_books é referida como uma característica transversal, que fornece informação adicional interacção além das características individuais.
Quais são os desafios na aprendizagem de cruzamentos de recursos? Em aplicativos de escala da Web, os dados são principalmente categóricos, levando a um espaço de recursos grande e esparso. Identificar cruzamentos de recursos eficazes nesta configuração geralmente requer engenharia de recursos manual ou pesquisa exaustiva. Os modelos tradicionais de perceptron multicamadas feed-forward (MLP) são aproximadores de função universais; no entanto, eles não podem de forma eficiente aproximar mesmo 2ª ou 3ª ordem cruzes função [ 1 , 2 ].
O que é Deep & Cross Network (DCN)? O DCN foi projetado para aprender recursos cruzados explícitos e de grau limitado de forma mais eficaz. Ela começa com uma camada de entrada (tipicamente uma camada de embutir), seguido por uma rede transversal contendo múltiplas camadas cruzadas que interacções explícitas modelos de recursos, e, em seguida, combina-se com uma rede de profundidade que modela interacções característica implícita.
- Rede cruzada. Este é o cerne da DCN. Ele aplica explicitamente o cruzamento de recursos em cada camada, e o grau polinomial mais alto aumenta com a profundidade da camada. Os seguintes figura mostra o \((i+1)\)-ésimo camada transversal.
- Deep Network. É um perceptron multilayer feedforward tradicional (MLP).
A rede de profundidade e a rede cruzada são então combinadas para formar DCN [ 1 ]. Normalmente, podemos empilhar uma rede profunda no topo da rede cruzada (estrutura empilhada); também podemos colocá-los em paralelo (estrutura paralela).
A seguir, mostraremos primeiro a vantagem do DCN com um exemplo de brinquedo e, em seguida, mostraremos algumas maneiras comuns de utilizar o DCN usando o conjunto de dados MovieLen-1M.
Vamos primeiro instalar e importar os pacotes necessários para este colab.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
Exemplo de brinquedo
Para ilustrar os benefícios do DCN, vamos trabalhar com um exemplo simples. Suponha que temos um conjunto de dados onde estamos tentando modelar a probabilidade de um cliente clicar em um anúncio do blender, com seus recursos e rótulo descritos a seguir.
| Características / etiqueta | Descrição | Tipo / intervalo de valor |
|---|---|---|
| \(x_1\) = país | o país em que o cliente mora | Int em [0, 199] |
| \(x_2\) = bananas | # bananas que o cliente comprou | Int em [0, 23] |
| \(x_3\) = livros de cozinha | # livros de culinária que o cliente comprou | Int em [0, 5] |
| \(y\) | a probabilidade de clicar em um anúncio do liquidificador | - |
Então, deixamos os dados seguirem a seguinte distribuição subjacente:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
onde a probabilidade \(y\) depende linearmente tanto em características \(x_i\)'s, mas também sobre as interacções entre o multiplicativos \(x_i\)' s. No nosso caso, diríamos que a probabilidade de comprar um liquidificador (\(y\)) depende não apenas de comprar bananas (\(x_2\)) ou livros de receitas (\(x_3\)), mas também sobre a compra de bananas e livros de receitas em conjunto (\(x_2x_3\))
Podemos gerar os dados para isso da seguinte maneira:
Geração de dados sintéticos
Em primeiro lugar, definir \(f(x_1, x_2, x_3)\) como descrito acima.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
Vamos gerar os dados que seguem a distribuição e dividir os dados em 90% para treinamento e 10% para teste.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
Construção de modelo
Vamos experimentar rede cruzada e rede profunda para ilustrar a vantagem que uma rede cruzada pode trazer para os recomendadores. Como os dados que acabamos de criar contêm apenas interações de recursos de 2ª ordem, seria suficiente ilustrar com uma rede cruzada de camada única. Se quiséssemos modelar interações de recursos de ordem superior, poderíamos empilhar várias camadas cruzadas e usar uma rede cruzada de várias camadas. Os dois modelos que iremos construir são:
- Rede cruzada com apenas uma camada cruzada;
- Rede profunda com camadas ReLU mais amplas e profundas.
Primeiro construímos uma classe de modelo unificado cuja perda é o erro quadrático médio.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
Em seguida, especificamos a rede cruzada (com 1 camada cruzada de tamanho 3) e o DNN baseado em ReLU (com tamanhos de camada [512, 256, 128]):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
Treinamento de modelo
Agora que temos os dados e os modelos prontos, vamos treinar os modelos. Primeiro embaralhamos e agrupamos os dados para nos preparar para o treinamento do modelo.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
Em seguida, definimos o número de épocas, bem como a taxa de aprendizagem.
epochs = 100
learning_rate = 0.4
Tudo bem, tudo está pronto agora e vamos compilar e treinar os modelos. Você pode definir verbose=True se você quiser ver como os avanços modelo.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
Avaliação de modelo
Verificamos o desempenho do modelo no conjunto de dados de avaliação e relatamos o erro quadrático médio (RMSE, quanto menor, melhor).
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
Vemos que a rede cruz magnitudes alcançados diminuir RMSE do que um DNN baseado em Relu, com magnitudes menos parâmetros. Isso sugeriu a eficiência de uma rede cruzada no aprendizado de cruzamentos de recursos.
Compreensão do modelo
Já sabemos quais cruzamentos de recursos são importantes em nossos dados, seria divertido verificar se nosso modelo realmente aprendeu o cruzamento de recursos importantes. Isso pode ser feito visualizando a matriz de peso aprendida no DCN. O peso \(W_{ij}\) representa a importância aprendido de interacção entre característica \(x_i\) e \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
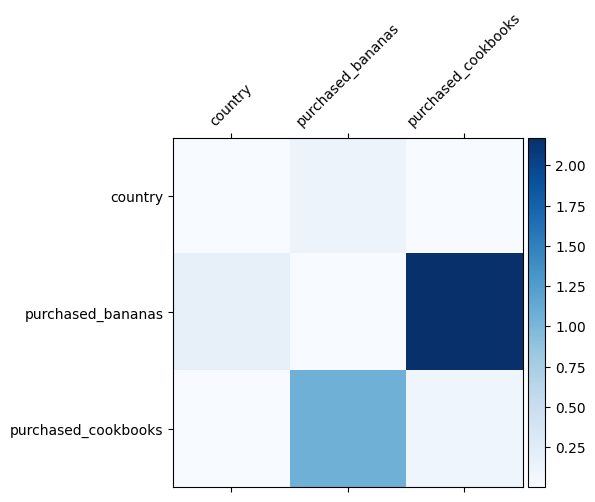
Cores mais escuras representam interações aprendidas mais fortes - neste caso, está claro que o modelo aprendeu que comprar babanas e livros de receitas juntos é importante.
Se você estiver interessado em experimentar dados sintéticos mais complicado, sinta livre para verificar este papel .
Exemplo de Movielens 1M
Vamos agora examinar a eficácia das DCN em um conjunto de dados do mundo real: Movielens 1M [ 3 ]. Movielens 1M é um conjunto de dados popular para pesquisa de recomendação. Ele prevê as classificações de filmes dos usuários de acordo com recursos relacionados ao usuário e recursos relacionados ao filme. Usamos este conjunto de dados para demonstrar algumas maneiras comuns de utilizar DCN.
Processamento de dados
O procedimento de processamento de dados segue um procedimento semelhante ao do tutorial classificação de base .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
Em seguida, dividimos aleatoriamente os dados em 80% para treinamento e 20% para teste.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
Em seguida, criamos vocabulário para cada recurso.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
Construção de modelo
A arquitetura do modelo que iremos construir começa com uma camada de incorporação, que é alimentada em uma rede cruzada seguida por uma rede profunda. A dimensão de incorporação é definida como 32 para todos os recursos. Você também pode usar tamanhos de incorporação diferentes para recursos diferentes.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
Treinamento de modelo
Misturamos, agrupamos e armazenamos em cache os dados de treinamento e teste.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
Vamos definir uma função que executa um modelo várias vezes e retorna a média RMSE do modelo e o desvio padrão de várias execuções.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
Definimos alguns hiperparâmetros para os modelos. Observe que esses hiperparâmetros são definidos globalmente para todos os modelos para fins de demonstração. Se você deseja obter o melhor desempenho para cada modelo ou realizar uma comparação justa entre os modelos, sugerimos que você ajuste os hiperparâmetros. Lembre-se de que a arquitetura do modelo e os esquemas de otimização estão interligados.
epochs = 8
learning_rate = 0.01
DCN (empilhado). Primeiramente, treinamos um modelo DCN com uma estrutura empilhada, ou seja, as entradas são enviadas para uma rede cruzada seguida por uma rede profunda.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN de baixo escalão. Para reduzir o custo de treinamento e serviço, usamos técnicas de classificação inferior para aproximar as matrizes de peso DCN. A classificação é passado através de argumento projection_dim ; um menor projection_dim resulta num custo mais baixo. Note-se que projection_dim necessidades para ser menor do que (tamanho de entrada) / 2 para reduzir o custo. Na prática, observamos o uso de DCN de classificação inferior com classificação (tamanho de entrada) / 4 preservou de forma consistente a precisão de um DCN de classificação completa.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. Treinamos um modelo DNN do mesmo tamanho como referência.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
Avaliamos o modelo nos dados de teste e relatamos a média e o desvio padrão de 5 execuções.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
Vemos que o DCN obteve melhor desempenho do que um DNN do mesmo tamanho com camadas ReLU. Além disso, o DCN de classificação inferior foi capaz de reduzir os parâmetros, mantendo a precisão.
Mais sobre DCN. Além what've sido demonstrado acima, existem maneiras mais criativas ainda praticamente útil para utilizar DCN [ 1 ].
DCN com uma estrutura paralela. As entradas são alimentadas em paralelo a uma rede cruzada e uma rede profunda.
Camadas cruzadas de concatenação. As entradas são alimentadas em paralelo a várias camadas cruzadas para capturar cruzamentos de recursos complementares.
Compreensão do modelo
A matriz de peso \(W\) no DCN revela o recurso atravessa o modelo aprendeu a ser importante. Recorde-se que no exemplo anterior do brinquedo, a importância das interacções entre o \(i\)-ésimo e \(j\)-ésimo apresenta é capturado pelo (\(i, j\)) -ésimo elemento de \(W\).
O que é um pouco diferente aqui é que os embeddings recurso são de tamanho 32, em vez de tamanho 1. Daí a importância será caracterizada pela \((i, j)\)bloco -ésimo\(W_{i,j}\) que é de dimensão de 32 por 32. Em seguida, nós visualizar a norma Frobenius [ 4 ] \(||W_{i,j}||_F\) de cada bloco, e uma norma maior sugeriria maior importância (assumindo incorporações dos recursos são de escalas semelhantes).
Além da norma do bloco, também pudemos visualizar toda a matriz, ou o valor médio / mediano / máximo de cada bloco.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
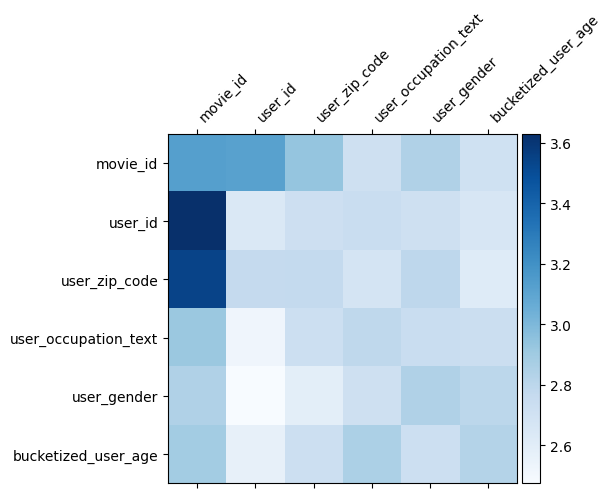
Isso é tudo por este colab! Esperamos que você tenha gostado de aprender alguns princípios básicos da DCN e maneiras comuns de utilizá-la. Se você estiver interessado em aprender mais, você poderia verificar dois artigos relevantes: DCN-v1 de papel , DCN-v2-papel .
Referências
DCN V2: Melhoria Deep & Cruz Rede e lições práticas para a Aprendizagem Web escala para classificar Sistemas .
Ruoxi Wang, Rakesh Shivanna, Derek Zhiyuan Cheng, Sagar Jain, Dong Lin, Lichan Hong, Ed Chi. (2020)
Deep & Cruz Rede de clique em anúncios previsões .
Ruoxi Wang, Bin Fu, Gang Fu, Mingliang Wang. (AdKDD 2017)