
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش نحوه استفاده از Deep & Cross Network (DCN) را برای یادگیری موثر تلاقی ویژگی ها نشان می دهد.
زمینه
ضربدرهای ویژگی چیست و چرا مهم هستند؟ تصور کنید که ما در حال ساختن یک سیستم توصیه کننده برای فروش یک مخلوط کن به مشتریان هستیم. سپس، تاریخ خرید گذشته مشتری مانند purchased_bananas و purchased_cooking_books ، یا ویژگی های جغرافیایی، ویژگی های تک هستند. اگر یکی هر دو موز و کتاب آشپزی خریداری کرده است، پس از این مشتری به احتمال زیاد بیشتر در مخلوط کن توصیه می شود کلیک کنید. ترکیبی از purchased_bananas و purchased_cooking_books است که به عنوان یک صلیب ویژگی، فراهم می کند که اطلاعات تعاملی اضافی فراتر از ویژگی های فردی اشاره شده است.
چالش های یادگیری صلیب های ویژگی چیست؟ در برنامههای کاربردی در مقیاس وب، دادهها عمدتاً طبقهبندی شدهاند که منجر به فضای بزرگ و پراکنده ویژگیها میشود. شناسایی تلاقی ویژگی های موثر در این تنظیم اغلب به مهندسی ویژگی های دستی یا جستجوی جامع نیاز دارد. مدلهای پرسپترون چندلایه پیشخور سنتی (MLP) تقریبکنندههای تابع جهانی هستند. با این حال، آنها نمی توانند موثر تقریبی حتی 2 یا 3-سفارش شمشیر برای نابودی وسایل از ویژگی های [ 1 ، 2 ].
شبکه عمیق و متقابل (DCN) چیست؟ DCN برای یادگیری مؤثرتر ویژگیهای متقاطع صریح و با درجه محدود طراحی شده است. آن را با یک لایه ورودی (معمولا یک لایه تعبیه)، به دنبال یک شبکه متقاطع حاوی لایه های متقابل چند شروع می شود که فعل و انفعالات مدل صریح ویژگی، و پس از آن ترکیب با یک شبکه عمیق است که مدل تعاملات ویژگی ضمنی.
- شبکه متقابل. این هسته DCN است. این به صراحت تلاقی ویژگی را در هر لایه اعمال می کند و بالاترین درجه چند جمله ای با عمق لایه افزایش می یابد. شکل زیر نشان می دهد \((i+1)\)هفتم متقابل لایه.
- شبکه عمیق این یک پرسپترون چند لایه پیشخور سنتی (MLP) است.
شبکه عمیق و شبکه متقابل سپس ترکیب به شکل DCN [ 1 ]. معمولاً میتوانیم یک شبکه عمیق را در بالای شبکه متقابل (ساختار پشتهای) قرار دهیم. ما همچنین می توانیم آنها را در موازی (ساختار موازی) قرار دهیم.
در ادامه، ابتدا مزیت DCN را با یک مثال اسباب بازی نشان میدهیم و سپس شما را با چند روش رایج برای استفاده از DCN با استفاده از مجموعه داده MovieLen-1M آشنا میکنیم.
ابتدا پکیج های لازم برای این کولب را نصب و وارد کنیم.
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
نمونه اسباب بازی
برای نشان دادن مزایای DCN، اجازه دهید با یک مثال ساده کار کنیم. فرض کنید مجموعه دادهای داریم که در آن سعی میکنیم احتمال کلیک مشتری روی یک تبلیغ مخلوطکن را با ویژگیها و برچسب آن به شرح زیر مدلسازی کنیم.
| ویژگی ها / برچسب | شرح | نوع ارزش / محدوده |
|---|---|---|
| \(x_1\) = کشور | کشوری که این مشتری در آن زندگی می کند | Int در [0, 199] |
| \(x_2\) = موز | # موز مشتری خریداری کرده است | Int در [0، 23] |
| \(x_3\) = آشپزی | # کتاب آشپزی که مشتری خریداری کرده است | Int در [0، 5] |
| \(y\) | احتمال کلیک بر روی یک تبلیغ مخلوط کن | -- |
سپس، اجازه می دهیم داده ها از توزیع زیربنایی پیروی کنند:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
که در آن احتمال \(y\) بستگی خطی هر دو در ویژگی های \(x_i\)است، بلکه در تعامل ضربی بین \(x_i\)است. در مورد ما، ما می گویند که احتمال خرید یک مخلوط کن (\(y\)) بستگی دارد فقط در خرید موز (نه\(x_2\)) یا آشپزی (\(x_3\))، بلکه در خرید موز و آشپزی با هم (\(x_2x_3\)).
میتوانیم دادهها را به صورت زیر تولید کنیم:
تولید داده های مصنوعی
ما برای اولین بار تعریف \(f(x_1, x_2, x_3)\) همانطور که در بالا توضیح داده شد.
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
بیایید دادههایی را که به دنبال توزیع است تولید کنیم و دادهها را به 90% برای آموزش و 10% برای آزمایش تقسیم کنیم.
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
ساخت مدل
ما قصد داریم هم شبکه متقاطع و هم شبکه عمیق را امتحان کنیم تا مزیتی را که یک شبکه متقاطع می تواند برای توصیه کنندگان به ارمغان بیاورد را نشان دهیم. از آنجایی که دادههایی که ما به تازگی ایجاد کردیم فقط شامل تعاملات ویژگی مرتبه دوم است، برای نشان دادن یک شبکه متقابل تک لایه کافی است. اگر بخواهیم تعاملات ویژگی های مرتبه بالاتر را مدل کنیم، می توانیم چندین لایه متقابل را روی هم قرار دهیم و از یک شبکه متقابل چند لایه استفاده کنیم. دو مدلی که ما خواهیم ساخت عبارتند از:
- شبکه متقابل تنها با یک لایه متقابل.
- شبکه عمیق با لایه های گسترده تر و عمیق تر ReLU.
ابتدا یک کلاس مدل یکپارچه می سازیم که ضرر آن میانگین مربعات خطا است.
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
سپس، شبکه متقاطع (با 1 لایه متقاطع با اندازه 3) و DNN مبتنی بر ReLU (با اندازه لایه [512، 256، 128]) را مشخص می کنیم:
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
آموزش مدل
اکنون که داده ها و مدل ها را آماده کرده ایم، به آموزش مدل ها می پردازیم. ابتدا داده ها را به هم می زنیم و دسته بندی می کنیم تا برای آموزش مدل آماده شویم.
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
سپس تعداد دوره ها و همچنین میزان یادگیری را تعریف می کنیم.
epochs = 100
learning_rate = 0.4
خوب، همه چیز آماده است و بیایید مدل ها را جمع آوری و آموزش دهیم. شما می توانید مجموعه ای verbose=True اگر شما می خواهید برای دیدن چگونگی پیشرفت مدل.
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
ارزیابی مدل
ما عملکرد مدل را در مجموعه داده ارزیابی تأیید میکنیم و خطای میانگین مربعات ریشه (RMSE، هرچه کمتر، بهتر) گزارش میکنیم.
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
ما می بینیم که شبکه متقابل مقادیر به دست آمده را کاهش RMSE از یک DNN بر اساس ReLU، با پارامترهای اندازه کمتر. این امر کارایی یک شبکه متقاطع را در یادگیری تلاقی های ویژگی پیشنهاد کرده است.
درک مدل
ما قبلاً می دانیم که چه ویژگی های متقاطع در داده های ما مهم هستند، جالب است که بررسی کنیم آیا مدل ما واقعاً متقاطع ویژگی های مهم را یاد گرفته است یا خیر. این را می توان با تجسم ماتریس وزن آموخته شده در DCN انجام داد. وزن \(W_{ij}\) نشان دهنده اهمیت و دست از تعامل بین ویژگی \(x_i\) و \(x_j\).
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
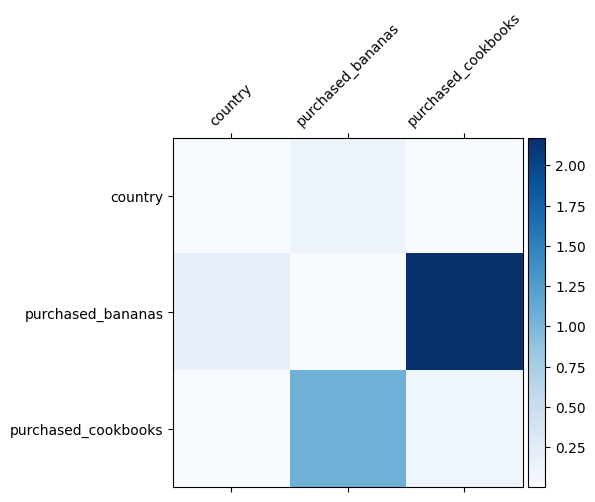
رنگهای تیره نشاندهنده تعاملات آموختهشده قویتر هستند - در این مورد، واضح است که مدل آموخته است که خرید بابانا و کتابهای آشپزی با هم مهم است.
اگر شما در تلاش داده های مصنوعی پیچیده بیشتر علاقه مند، احساس رایگان برای چک کردن این مقاله .
مثال Movielens 1M
ما در حال حاضر اثربخشی DCN در یک مجموعه داده های دنیای واقعی بررسی: Movielens 1M [ 3 ]. Movielens 1M یک مجموعه داده محبوب برای تحقیقات توصیه است. با توجه به ویژگیهای مربوط به کاربر و ویژگیهای مرتبط با فیلم، رتبهبندی فیلمهای کاربران را پیشبینی میکند. ما از این مجموعه داده برای نشان دادن برخی از روش های رایج برای استفاده از DCN استفاده می کنیم.
پردازش داده ها
روش پردازش داده یک روش مشابه به عنوان زیر آموزش های اساسی رتبه بندی .
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
در مرحله بعد، داده ها را به طور تصادفی به 80 درصد برای آموزش و 20 درصد برای آزمایش تقسیم می کنیم.
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
سپس، برای هر ویژگی واژگان ایجاد می کنیم.
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
ساخت مدل
معماری مدلی که ما خواهیم ساخت با یک لایه تعبیه شده شروع می شود که به یک شبکه متقاطع و سپس یک شبکه عمیق وارد می شود. بعد تعبیه برای همه ویژگی ها روی 32 تنظیم شده است. همچنین می توانید از اندازه های مختلف تعبیه برای ویژگی های مختلف استفاده کنید.
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
آموزش مدل
ما دادههای آموزشی و آزمایشی را به هم میزنیم، دستهبندی میکنیم و ذخیره میکنیم.
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
بیایید تابعی را تعریف کنیم که یک مدل را چندین بار اجرا می کند و میانگین RMSE و انحراف استاندارد مدل را از چندین اجرا برمی گرداند.
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
ما برخی از پارامترهای فوق را برای مدل ها تنظیم می کنیم. توجه داشته باشید که این هایپرپارامترها به صورت سراسری برای همه مدلها به منظور نمایش تنظیم شدهاند. اگر میخواهید بهترین عملکرد را برای هر مدل به دست آورید، یا مقایسهای منصفانه بین مدلها انجام دهید، به شما پیشنهاد میکنیم که پارامترهای فوق را به خوبی تنظیم کنید. به یاد داشته باشید که معماری مدل و طرح های بهینه سازی در هم تنیده شده اند.
epochs = 8
learning_rate = 0.01
DCN (انباشته). ما ابتدا یک مدل DCN را با ساختار پشتهای آموزش میدهیم، یعنی ورودیها به یک شبکه متقاطع و سپس یک شبکه عمیق تغذیه میشوند.
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
DCN رتبه پایین. برای کاهش هزینه آموزش و سرویس، از تکنیکهای رتبه پایین برای تقریب ماتریسهای وزن DCN استفاده میکنیم. این ردهبندی به در از طریق آرگومان projection_dim ؛ کوچکتر projection_dim منجر به هزینه پایین تر است. توجه داشته باشید که projection_dim نیازهای به کوچکتر از (اندازه ورودی) / 2 به منظور کاهش هزینه. در عمل، مشاهده کردهایم که استفاده از DCN با رتبه پایین با رتبه (اندازه ورودی)/4 به طور مداوم دقت یک DCN با رتبه کامل را حفظ میکند.
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
DNN. ما یک مدل DNN هم اندازه را به عنوان مرجع آموزش می دهیم.
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
ما مدل را بر روی داده های آزمون ارزیابی می کنیم و میانگین و انحراف استاندارد را از 5 اجرا گزارش می کنیم.
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
می بینیم که DCN نسبت به یک DNN هم اندازه با لایه های ReLU به عملکرد بهتری دست یافته است. علاوه بر این، DCN با رتبه پایین قادر به کاهش پارامترها در عین حفظ دقت بود.
بیشتر در DCN. علاوه بر این what've بالا نشان داده شده است، راه های هنوز عملا مفید خلاق تر به استفاده از DCN [وجود دارد 1 ].
DCN با ساختار موازی. ورودی ها به موازات یک شبکه متقاطع و یک شبکه عمیق تغذیه می شوند.
الحاق لایه های متقابل. ورودی ها به موازات چندین لایه متقابل تغذیه می شوند تا تلاقی ویژگی های مکمل را بگیرند.
درک مدل
ماتریس وزن \(W\) در DCN نشان می دهد آنچه ویژگی عبور از مدل به دست است که مهم است. به یاد بیاورید که در مثال اسباب بازی قبلی، اهمیت تعاملات بین \(i\)هفتم و \(j\)هفتم ویژگی های است که توسط (اسیر\(i, j\)) عنصر توریم از \(W\).
چه مختلف کمی اینجا این است که درونه گیریها قابلیت اندازه 32 به جای اندازه 1. از این رو، اهمیت خواهد بود که توسط مشخص \((i, j)\)بلوک هفتم\(W_{i,j}\) است که از ابعاد 32 توسط 32. در زیر، ما تجسم هنجار Frobenius به [ 4 ] \(||W_{i,j}||_F\) هر بلوک، و یک هنجار بزرگتر اهمیت بالاتر نشان (با فرض درونه گیریها از ویژگی های از ابعاد مشابه هستند).
علاوه بر هنجار بلوک، ما همچنین میتوانیم کل ماتریس یا مقدار میانگین/متوسط/حداکثر هر بلوک را تجسم کنیم.
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
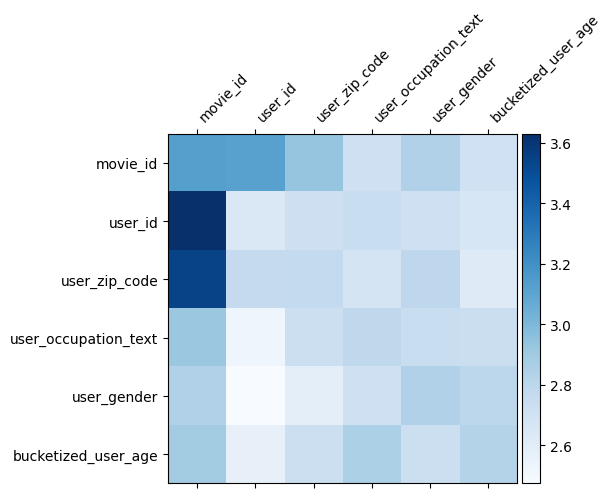
این همه برای این colab است! امیدواریم از یادگیری برخی از اصول DCN و روش های رایج استفاده از آن لذت برده باشید. اگر شما به یادگیری بیشتر در علاقه مند، شما می توانید بررسی کنید دو مقاله مرتبط: DCN-V1 کاغذ ، DCN-V2 کاغذ .
منابع
DCN V2: بهبود عمیق و صلیب شبکه و درس های عملی برای یادگیری در مقیاس وب به رتبه سیستم .
روکسی وانگ، راکش شیوانا، درک ژیوان چنگ، ساگار جین، دونگ لین، لیچان هونگ، اد چی. (2020)
عمیق و صلیب شبکه برای پیش بینی کلیک کنید آگهی .
روکسی وانگ، بین فو، گانگ فو، مینگلیانگ وانگ. (AdKDD 2017)