
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি দেখায় কিভাবে ডিপ অ্যান্ড ক্রস নেটওয়ার্ক (DCN) ব্যবহার করে কার্যকরভাবে বৈশিষ্ট্য ক্রস শিখতে হয়।
পটভূমি
বৈশিষ্ট্য ক্রস কি এবং কেন তারা গুরুত্বপূর্ণ? কল্পনা করুন যে আমরা গ্রাহকদের কাছে একটি ব্লেন্ডার বিক্রি করার জন্য একটি সুপারিশকারী সিস্টেম তৈরি করছি। এর পরে, যেমন একটি গ্রাহক অতীত ক্রয়ের ইতিহাস purchased_bananas এবং purchased_cooking_books , অথবা ভৌগলিক বৈশিষ্ট্য, একক বৈশিষ্ট্য। এক উভয় কলা এবং রান্না করা বই কিনে থাকে, তাহলে এই গ্রাহকের সম্ভাবনা বেশি প্রস্তাবিত মিশ্রণকারী ক্লিক করবে। সমন্বয় purchased_bananas এবং purchased_cooking_books একটি বৈশিষ্ট্য ক্রস, যা পৃথক বৈশিষ্ট্য তার পরেও অতিরিক্ত মিথষ্ক্রিয়া তথ্য প্রদান করে হিসাবে উল্লেখ করা হয়।
বৈশিষ্ট্য ক্রস শেখার চ্যালেঞ্জ কি কি? ওয়েব-স্কেল অ্যাপ্লিকেশনগুলিতে, ডেটা বেশিরভাগই শ্রেণীবদ্ধ, যা বড় এবং বিক্ষিপ্ত বৈশিষ্ট্য স্থানের দিকে পরিচালিত করে। এই সেটিংয়ে কার্যকর বৈশিষ্ট্য ক্রস শনাক্ত করার জন্য প্রায়ই ম্যানুয়াল ফিচার ইঞ্জিনিয়ারিং বা সম্পূর্ণ অনুসন্ধানের প্রয়োজন হয়। ঐতিহ্যগত ফিড-ফরোয়ার্ড মাল্টিলেয়ার পারসেপ্টরন (এমএলপি) মডেলগুলি সর্বজনীন ফাংশন আনুমানিক; যাইহোক, তারা দক্ষতার সঙ্গে এমনকি 2nd অথবা 3 য়-অর্ডার বৈশিষ্ট্য ক্রস [আনুমানিক না পারেন, 1 , 2 ]।
ডিপ অ্যান্ড ক্রস নেটওয়ার্ক (ডিসিএন) কী? DCN কে সুস্পষ্ট এবং আবদ্ধ-ডিগ্রী ক্রস বৈশিষ্ট্যগুলি আরও কার্যকরভাবে শেখার জন্য ডিজাইন করা হয়েছিল। এটি একটি ইনপুট স্তর (সাধারণত একটি এম্বেডিং স্তর), একাধিক ক্রস স্তর ধারণকারী একটি ক্রস নেটওয়ার্ক দ্বারা অনুসৃত দিয়ে শুরু হয় যে মডেলের স্পষ্ট বৈশিষ্ট্য পারস্পরিক ক্রিয়ার, এবং তারপর সম্মিলন একটি গভীর নেটওয়ার্কের সঙ্গে যে মডেলের অন্তর্নিহিত বৈশিষ্ট্য কথাবার্তাও।
- ক্রস নেটওয়ার্ক। এটি DCN এর মূল। এটি স্পষ্টভাবে প্রতিটি স্তরে বৈশিষ্ট্য ক্রসিং প্রয়োগ করে এবং স্তরের গভীরতার সাথে সর্বোচ্চ বহুপদী ডিগ্রি বৃদ্ধি পায়। নিচের চিত্র শো \((i+1)\)ক্রস স্তর -th।
- গভীর নেটওয়ার্ক। এটি একটি ঐতিহ্যগত ফিডফরোয়ার্ড মাল্টিলেয়ার পারসেপ্ট্রন (এমএলপি)।
গভীর নেটওয়ার্ক এবং ক্রস নেটওয়ার্কের তারপর DCN [গঠনের একত্রিত করা হয় 1 ]। সাধারণত, আমরা ক্রস নেটওয়ার্কের উপরে একটি গভীর নেটওয়ার্ক স্ট্যাক করতে পারি (স্ট্যাক করা কাঠামো); আমরা তাদের সমান্তরাল (সমান্তরাল কাঠামো) রাখতেও পারি।
নিম্নলিখিতটিতে, আমরা প্রথমে একটি খেলনা উদাহরণ সহ DCN এর সুবিধা দেখাব, এবং তারপরে আমরা আপনাকে MovieLen-1M ডেটাসেট ব্যবহার করে DCN ব্যবহার করার কিছু সাধারণ উপায়ের মাধ্যমে নিয়ে যাব।
চলুন প্রথমে এই কোল্যাবের জন্য প্রয়োজনীয় প্যাকেজ ইন্সটল এবং ইমপোর্ট করি।
pip install -q tensorflow-recommenderspip install -q --upgrade tensorflow-datasets
import pprint
%matplotlib inline
import matplotlib.pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
import tensorflow_recommenders as tfrs
খেলনার উদাহরণ
DCN এর সুবিধাগুলি বোঝাতে, আসুন একটি সাধারণ উদাহরণ দিয়ে কাজ করি। ধরুন আমাদের কাছে একটি ডেটাসেট আছে যেখানে আমরা একটি ব্লেন্ডার বিজ্ঞাপনে ক্লিক করার একটি গ্রাহকের সম্ভাবনা মডেল করার চেষ্টা করছি, এর বৈশিষ্ট্য এবং লেবেল নিম্নরূপ বর্ণনা করা হয়েছে৷
| বৈশিষ্ট্য / লেবেল | বর্ণনা | মান প্রকার / পরিসীমা |
|---|---|---|
| \(x_1\) = দেশ | এই গ্রাহক যে দেশে বাস করেন | Int [0, 199] |
| \(x_2\) = কলা | # গ্রাহক কিনেছেন কলা | int [0, 23] |
| \(x_3\) = রান্নার বই | # গ্রাহকের কেনা রান্নার বই | Int [0, 5] |
| \(y\) | একটি ব্লেন্ডার বিজ্ঞাপনে ক্লিক করার সম্ভাবনা | -- |
তারপরে, আমরা ডেটাকে নিম্নলিখিত অন্তর্নিহিত বিতরণ অনুসরণ করতে দিই:
\[y = f(x_1, x_2, x_3) = 0.1x_1 + 0.4x_2+0.7x_3 + 0.1x_1x_2+3.1x_2x_3+0.1x_3^2\]
যেখানে সম্ভাবনা \(y\) সুসংগত উভয় নির্ভর বৈশিষ্ট্যের উপর \(x_i\)এর, কিন্তু মধ্যে গুণনশীল পারস্পরিক ক্রিয়ার উপর \(x_i\)s 'এর। আমাদের ক্ষেত্রে, আমরা বলতে চাই যে একটি মিশ্রণকারী (ক্রয় সম্ভাবনা\(y\)) শুধু কলা (কেনার নয় নির্ভর\(x_2\)) অথবা রান্নার বই (\(x_3\)), কিন্তু কলা এবং রান্নার বই একসঙ্গে কেনার (চালু\(x_2x_3\))
আমরা এর জন্য নিম্নরূপ ডেটা তৈরি করতে পারি:
সিন্থেটিক ডেটা জেনারেশন
আমরা প্রথম সংজ্ঞায়িত \(f(x_1, x_2, x_3)\) উপরে বর্ণিত।
def get_mixer_data(data_size=100_000, random_seed=42):
# We need to fix the random seed
# to make colab runs repeatable.
rng = np.random.RandomState(random_seed)
country = rng.randint(200, size=[data_size, 1]) / 200.
bananas = rng.randint(24, size=[data_size, 1]) / 24.
coockbooks = rng.randint(6, size=[data_size, 1]) / 6.
x = np.concatenate([country, bananas, coockbooks], axis=1)
# # Create 1st-order terms.
y = 0.1 * country + 0.4 * bananas + 0.7 * coockbooks
# Create 2nd-order cross terms.
y += 0.1 * country * bananas + 3.1 * bananas * coockbooks + (
0.1 * coockbooks * coockbooks)
return x, y
ডিস্ট্রিবিউশন অনুসরণ করে এমন ডেটা তৈরি করি এবং প্রশিক্ষণের জন্য 90% এবং পরীক্ষার জন্য 10% ডেটা ভাগ করি।
x, y = get_mixer_data()
num_train = 90000
train_x = x[:num_train]
train_y = y[:num_train]
eval_x = x[num_train:]
eval_y = y[num_train:]
মডেল নির্মাণ
একটি ক্রস নেটওয়ার্ক সুপারিশকারীদের জন্য যে সুবিধা আনতে পারে তা বোঝাতে আমরা ক্রস নেটওয়ার্ক এবং গভীর নেটওয়ার্ক উভয়ই চেষ্টা করে দেখতে যাচ্ছি। যেহেতু আমরা এইমাত্র যে ডেটা তৈরি করেছি তাতে শুধুমাত্র ২য়-ক্রম বৈশিষ্ট্য মিথস্ক্রিয়া রয়েছে, তাই এটি একটি একক-স্তরযুক্ত ক্রস নেটওয়ার্কের সাথে চিত্রিত করা যথেষ্ট হবে। আমরা যদি উচ্চ-অর্ডার বৈশিষ্ট্য ইন্টারঅ্যাকশন মডেল করতে চাই, আমরা একাধিক ক্রস স্তর স্ট্যাক করতে পারি এবং একটি বহু-স্তরযুক্ত ক্রস নেটওয়ার্ক ব্যবহার করতে পারি। আমরা যে দুটি মডেল তৈরি করব তা হল:
- শুধুমাত্র একটি ক্রস স্তর সহ ক্রস নেটওয়ার্ক;
- বিস্তৃত এবং গভীর ReLU স্তর সহ গভীর নেটওয়ার্ক।
আমরা প্রথমে একটি ইউনিফাইড মডেল ক্লাস তৈরি করি যার ক্ষতি হল গড় বর্গ ত্রুটি।
class Model(tfrs.Model):
def __init__(self, model):
super().__init__()
self._model = model
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[
tf.keras.metrics.RootMeanSquaredError("RMSE")
]
)
def call(self, x):
x = self._model(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
x, labels = features
scores = self(x)
return self.task(
labels=labels,
predictions=scores,
)
তারপরে, আমরা ক্রস নেটওয়ার্ক (আকার 3 এর 1 ক্রস স্তর সহ) এবং ReLU-ভিত্তিক DNN (স্তরের আকার সহ [512, 256, 128] নির্দিষ্ট করি):
crossnet = Model(tfrs.layers.dcn.Cross())
deepnet = Model(
tf.keras.Sequential([
tf.keras.layers.Dense(512, activation="relu"),
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(128, activation="relu")
])
)
মডেল প্রশিক্ষণ
এখন যেহেতু আমাদের কাছে ডেটা এবং মডেল প্রস্তুত আছে, আমরা মডেলগুলিকে প্রশিক্ষণ দিতে যাচ্ছি। মডেল প্রশিক্ষণের জন্য প্রস্তুত করার জন্য আমরা প্রথমে ডেটা শাফেল এবং ব্যাচ করি।
train_data = tf.data.Dataset.from_tensor_slices((train_x, train_y)).batch(1000)
eval_data = tf.data.Dataset.from_tensor_slices((eval_x, eval_y)).batch(1000)
তারপরে, আমরা যুগের সংখ্যার পাশাপাশি শেখার হার সংজ্ঞায়িত করি।
epochs = 100
learning_rate = 0.4
ঠিক আছে, এখন সবকিছু প্রস্তুত এবং মডেলগুলিকে কম্পাইল করে প্রশিক্ষণ দেওয়া যাক। আপনি সেট পারে verbose=True যদি আপনি কিভাবে দেখতে মডেল অগ্রগতি চাই।
crossnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
crossnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d82ef390>
deepnet.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate))
deepnet.fit(train_data, epochs=epochs, verbose=False)
<keras.callbacks.History at 0x7f27d07a3dd0>
মডেল মূল্যায়ন
আমরা মূল্যায়ন ডেটাসেটে মডেলের কার্যকারিতা যাচাই করি এবং রুট মিন স্কয়ারড ত্রুটির রিপোর্ট করি (RMSE, যত কম তত ভালো)।
crossnet_result = crossnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"CrossNet(1 layer) RMSE is {crossnet_result['RMSE']:.4f} "
f"using {crossnet.count_params()} parameters.")
deepnet_result = deepnet.evaluate(eval_data, return_dict=True, verbose=False)
print(f"DeepNet(large) RMSE is {deepnet_result['RMSE']:.4f} "
f"using {deepnet.count_params()} parameters.")
CrossNet(1 layer) RMSE is 0.0011 using 16 parameters. DeepNet(large) RMSE is 0.1258 using 166401 parameters.
আমরা যে ক্রস নেটওয়ার্কের অর্জন মাত্রার একটি ReLU ভিত্তিক DNN চেয়ে RMSE কম মাত্রার কম পরামিতি সঙ্গে, দেখুন। এটি ফিচার ক্রস শেখার ক্ষেত্রে একটি ক্রস নেটওয়ার্কের দক্ষতার পরামর্শ দিয়েছে।
মডেল বোঝার
আমরা ইতিমধ্যেই জানি যে আমাদের ডেটাতে কোন বৈশিষ্ট্য ক্রসগুলি গুরুত্বপূর্ণ, আমাদের মডেল সত্যিই গুরুত্বপূর্ণ বৈশিষ্ট্য ক্রস শিখেছে কিনা তা পরীক্ষা করা মজাদার হবে৷ এটি DCN-এ শেখা ওজন ম্যাট্রিক্স কল্পনা করে করা যেতে পারে। ওজন \(W_{ij}\) বৈশিষ্ট্য মধ্যে মিথস্ক্রিয়া শিখেছি গুরুত্ব প্রতিনিধিত্ব করে \(x_i\) এবং \(x_j\)।
mat = crossnet._model._dense.kernel
features = ["country", "purchased_bananas", "purchased_cookbooks"]
plt.figure(figsize=(9,9))
im = plt.matshow(np.abs(mat.numpy()), cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([''] + features, rotation=45, fontsize=10)
_ = ax.set_yticklabels([''] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:11: UserWarning: FixedFormatter should only be used together with FixedLocator # This is added back by InteractiveShellApp.init_path() /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:12: UserWarning: FixedFormatter should only be used together with FixedLocator if sys.path[0] == '': <Figure size 648x648 with 0 Axes>
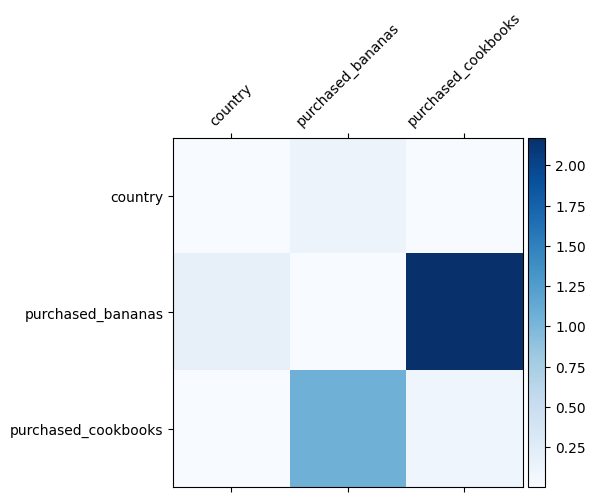
গাঢ় রং শক্তিশালী শেখা মিথস্ক্রিয়া প্রতিনিধিত্ব করে - এই ক্ষেত্রে, এটা স্পষ্ট যে মডেল শিখেছে যে বাবানা এবং রান্নার বই একসাথে কেনা গুরুত্বপূর্ণ।
আপনি আরো জটিল কৃত্রিম তথ্য চেষ্টা আগ্রহী, খুঁজে বার করো বিনা দ্বিধায় এই কাগজ ।
মুভিলেনস 1M উদাহরণ
আমরা এখন একটি বাস্তব বিশ্বের ডেটা সেটটি উপর DCN কার্যকারিতা পরীক্ষা: Movielens 1 মিঃ [ 3 ]। Movielens 1M সুপারিশ গবেষণার জন্য একটি জনপ্রিয় ডেটাসেট। এটি ব্যবহারকারী-সম্পর্কিত বৈশিষ্ট্য এবং চলচ্চিত্র-সম্পর্কিত বৈশিষ্ট্য প্রদত্ত ব্যবহারকারীদের চলচ্চিত্রের রেটিং পূর্বাভাস দেয়। আমরা DCN ব্যবহার করার কিছু সাধারণ উপায় প্রদর্শন করতে এই ডেটাসেটটি ব্যবহার করি।
তথ্য প্রক্রিয়াজাতকরণ
ডাটা প্রসেসিং পদ্ধতি যেমন একটি অনুরূপ পদ্ধতি অনুসরণ করে মৌলিক র্যাংকিং টিউটোরিয়াল ।
ratings = tfds.load("movie_lens/100k-ratings", split="train")
ratings = ratings.map(lambda x: {
"movie_id": x["movie_id"],
"user_id": x["user_id"],
"user_rating": x["user_rating"],
"user_gender": int(x["user_gender"]),
"user_zip_code": x["user_zip_code"],
"user_occupation_text": x["user_occupation_text"],
"bucketized_user_age": int(x["bucketized_user_age"]),
})
WARNING:absl:The handle "movie_lens" for the MovieLens dataset is deprecated. Prefer using "movielens" instead.
এরপরে, আমরা প্রশিক্ষণের জন্য 80% এবং পরীক্ষার জন্য 20% এ এলোমেলোভাবে ডেটা বিভক্ত করি।
tf.random.set_seed(42)
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
তারপর, আমরা প্রতিটি বৈশিষ্ট্যের জন্য শব্দভান্ডার তৈরি করি।
feature_names = ["movie_id", "user_id", "user_gender", "user_zip_code",
"user_occupation_text", "bucketized_user_age"]
vocabularies = {}
for feature_name in feature_names:
vocab = ratings.batch(1_000_000).map(lambda x: x[feature_name])
vocabularies[feature_name] = np.unique(np.concatenate(list(vocab)))
মডেল নির্মাণ
আমরা যে মডেল আর্কিটেকচারটি তৈরি করব তা একটি এমবেডিং স্তর দিয়ে শুরু হয়, যা একটি ক্রস নেটওয়ার্কে খাওয়ানো হয় এবং একটি গভীর নেটওয়ার্ক দ্বারা অনুসরণ করা হয়। সমস্ত বৈশিষ্ট্যের জন্য এমবেডিং মাত্রা 32 এ সেট করা হয়েছে। আপনি বিভিন্ন বৈশিষ্ট্যের জন্য বিভিন্ন এমবেডিং আকারও ব্যবহার করতে পারেন।
class DCN(tfrs.Model):
def __init__(self, use_cross_layer, deep_layer_sizes, projection_dim=None):
super().__init__()
self.embedding_dimension = 32
str_features = ["movie_id", "user_id", "user_zip_code",
"user_occupation_text"]
int_features = ["user_gender", "bucketized_user_age"]
self._all_features = str_features + int_features
self._embeddings = {}
# Compute embeddings for string features.
for feature_name in str_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.StringLookup(
vocabulary=vocabulary, mask_token=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
# Compute embeddings for int features.
for feature_name in int_features:
vocabulary = vocabularies[feature_name]
self._embeddings[feature_name] = tf.keras.Sequential(
[tf.keras.layers.IntegerLookup(
vocabulary=vocabulary, mask_value=None),
tf.keras.layers.Embedding(len(vocabulary) + 1,
self.embedding_dimension)
])
if use_cross_layer:
self._cross_layer = tfrs.layers.dcn.Cross(
projection_dim=projection_dim,
kernel_initializer="glorot_uniform")
else:
self._cross_layer = None
self._deep_layers = [tf.keras.layers.Dense(layer_size, activation="relu")
for layer_size in deep_layer_sizes]
self._logit_layer = tf.keras.layers.Dense(1)
self.task = tfrs.tasks.Ranking(
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError("RMSE")]
)
def call(self, features):
# Concatenate embeddings
embeddings = []
for feature_name in self._all_features:
embedding_fn = self._embeddings[feature_name]
embeddings.append(embedding_fn(features[feature_name]))
x = tf.concat(embeddings, axis=1)
# Build Cross Network
if self._cross_layer is not None:
x = self._cross_layer(x)
# Build Deep Network
for deep_layer in self._deep_layers:
x = deep_layer(x)
return self._logit_layer(x)
def compute_loss(self, features, training=False):
labels = features.pop("user_rating")
scores = self(features)
return self.task(
labels=labels,
predictions=scores,
)
মডেল প্রশিক্ষণ
আমরা প্রশিক্ষণ এবং পরীক্ষার ডেটা শাফেল, ব্যাচ এবং ক্যাশে করি।
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
আসুন এমন একটি ফাংশন সংজ্ঞায়িত করি যা একটি মডেলকে একাধিকবার চালায় এবং একাধিক রানের মধ্যে মডেলের RMSE গড় এবং আদর্শ বিচ্যুতি প্রদান করে।
def run_models(use_cross_layer, deep_layer_sizes, projection_dim=None, num_runs=5):
models = []
rmses = []
for i in range(num_runs):
model = DCN(use_cross_layer=use_cross_layer,
deep_layer_sizes=deep_layer_sizes,
projection_dim=projection_dim)
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate))
models.append(model)
model.fit(cached_train, epochs=epochs, verbose=False)
metrics = model.evaluate(cached_test, return_dict=True)
rmses.append(metrics["RMSE"])
mean, stdv = np.average(rmses), np.std(rmses)
return {"model": models, "mean": mean, "stdv": stdv}
আমরা মডেলের জন্য কিছু হাইপার-প্যারামিটার সেট করেছি। নোট করুন যে এই হাইপার-প্যারামিটারগুলি প্রদর্শনের উদ্দেশ্যে সমস্ত মডেলের জন্য বিশ্বব্যাপী সেট করা হয়েছে। আপনি যদি প্রতিটি মডেলের জন্য সেরা পারফরম্যান্স পেতে চান, বা মডেলগুলির মধ্যে একটি ন্যায্য তুলনা পরিচালনা করতে চান, তাহলে আমরা আপনাকে হাইপার-প্যারামিটারগুলি সূক্ষ্ম-টিউন করার পরামর্শ দেব। মনে রাখবেন যে মডেল আর্কিটেকচার এবং অপ্টিমাইজেশান স্কিমগুলি একে অপরের সাথে জড়িত।
epochs = 8
learning_rate = 0.01
DCN (স্ট্যাকড)। আমরা প্রথমে একটি স্তুপীকৃত কাঠামো সহ একটি DCN মডেলকে প্রশিক্ষণ দিই, অর্থাৎ, ইনপুটগুলি একটি ক্রস নেটওয়ার্কে খাওয়ানো হয় এবং একটি গভীর নেটওয়ার্ক অনুসরণ করে।
dcn_result = run_models(use_cross_layer=True,
deep_layer_sizes=[192, 192])
WARNING:tensorflow:mask_value is deprecated, use mask_token instead. WARNING:tensorflow:mask_value is deprecated, use mask_token instead. 5/5 [==============================] - 3s 24ms/step - RMSE: 0.9312 - loss: 0.8674 - regularization_loss: 0.0000e+00 - total_loss: 0.8674 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8726 - regularization_loss: 0.0000e+00 - total_loss: 0.8726 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9326 - loss: 0.8703 - regularization_loss: 0.0000e+00 - total_loss: 0.8703 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9351 - loss: 0.8752 - regularization_loss: 0.0000e+00 - total_loss: 0.8752 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9339 - loss: 0.8729 - regularization_loss: 0.0000e+00 - total_loss: 0.8729
নিম্ন-র্যাঙ্কের DCN। প্রশিক্ষণ এবং পরিবেশন খরচ কমাতে, আমরা DCN ওজন ম্যাট্রিক্স আনুমানিক করার জন্য নিম্ন-র্যাঙ্কের কৌশলগুলি ব্যবহার করি। র্যাঙ্ক যুক্তি মাধ্যমে পাস করা হয়েছে projection_dim ; একটি ছোট projection_dim একটি নিম্ন খরচের ফলাফল নেই। লক্ষ্য করুন projection_dim চাহিদা খরচ কমানোর জন্য (ইনপুট আকারের) / 2 চেয়ে ছোট হতে হবে। অনুশীলনে, আমরা র্যাঙ্ক (ইনপুট আকার)/4 সহ নিম্ন-র্যাঙ্কের DCN ব্যবহার করে দেখেছি ধারাবাহিকভাবে একটি পূর্ণ-র্যাঙ্ক DCN-এর নির্ভুলতা সংরক্ষণ করা হয়েছে।
dcn_lr_result = run_models(use_cross_layer=True,
projection_dim=20,
deep_layer_sizes=[192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9307 - loss: 0.8669 - regularization_loss: 0.0000e+00 - total_loss: 0.8669 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9312 - loss: 0.8668 - regularization_loss: 0.0000e+00 - total_loss: 0.8668 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9303 - loss: 0.8666 - regularization_loss: 0.0000e+00 - total_loss: 0.8666 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9337 - loss: 0.8723 - regularization_loss: 0.0000e+00 - total_loss: 0.8723 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9300 - loss: 0.8657 - regularization_loss: 0.0000e+00 - total_loss: 0.8657
ডিএনএন। আমরা একটি রেফারেন্স হিসাবে একই আকারের DNN মডেলকে প্রশিক্ষণ দিই।
dnn_result = run_models(use_cross_layer=False,
deep_layer_sizes=[192, 192, 192])
5/5 [==============================] - 0s 3ms/step - RMSE: 0.9462 - loss: 0.8989 - regularization_loss: 0.0000e+00 - total_loss: 0.8989 5/5 [==============================] - 0s 4ms/step - RMSE: 0.9352 - loss: 0.8765 - regularization_loss: 0.0000e+00 - total_loss: 0.8765 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9393 - loss: 0.8840 - regularization_loss: 0.0000e+00 - total_loss: 0.8840 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9362 - loss: 0.8772 - regularization_loss: 0.0000e+00 - total_loss: 0.8772 5/5 [==============================] - 0s 3ms/step - RMSE: 0.9377 - loss: 0.8798 - regularization_loss: 0.0000e+00 - total_loss: 0.8798
আমরা পরীক্ষার ডেটাতে মডেলটিকে মূল্যায়ন করি এবং 5 রানের মধ্যে গড় এবং মানক বিচ্যুতি রিপোর্ট করি।
print("DCN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_result["mean"], dcn_result["stdv"]))
print("DCN (low-rank) RMSE mean: {:.4f}, stdv: {:.4f}".format(
dcn_lr_result["mean"], dcn_lr_result["stdv"]))
print("DNN RMSE mean: {:.4f}, stdv: {:.4f}".format(
dnn_result["mean"], dnn_result["stdv"]))
DCN RMSE mean: 0.9333, stdv: 0.0013 DCN (low-rank) RMSE mean: 0.9312, stdv: 0.0013 DNN RMSE mean: 0.9389, stdv: 0.0039
আমরা দেখতে পাই যে DCN একই আকারের DNN এর থেকে ReLU স্তরগুলির সাথে ভাল কার্যক্ষমতা অর্জন করেছে৷ অধিকন্তু, নিম্ন-র্যাঙ্কের DCN নির্ভুলতা বজায় রেখে পরামিতিগুলি হ্রাস করতে সক্ষম হয়েছিল।
DCN-এ আরও What've উপরে প্রদর্শিত হয়েছে ছাড়া DCN [ব্যবহার করতে আরো সৃষ্টিশীল এখনো কার্যত দরকারী উপায় আছে 1 ]।
একটি সমান্তরাল গঠন DCN। ইনপুটগুলি একটি ক্রস নেটওয়ার্ক এবং একটি গভীর নেটওয়ার্কের সমান্তরালে খাওয়ানো হয়।
ক্রস স্তর সংযুক্ত করা. পরিপূরক বৈশিষ্ট্য ক্রস ক্যাপচার করার জন্য ইনপুটগুলি একাধিক ক্রস স্তরের সমান্তরালে খাওয়ানো হয়।
মডেল বোঝার
ওজন ম্যাট্রিক্স \(W\) DCN কি বৈশিষ্ট্য অতিক্রম করে মডেল গুরুত্বপূর্ণ হতে শেখা হয়েছে প্রকাশ করে। রিকল যে আগের খেলনা উদাহরণে মধ্যে পারস্পরিক ক্রিয়ার গুরুত্ব \(i\)-th এবং \(j\)-th Features (ক্যাপচার হয়\(i, j\)) এর -th উপাদান \(W\)।
কি একটু ভিন্ন এখানে যা ফিচার embeddings 32 আকার পরিবর্তে অত: পর আকার 1 হয়, গুরুত্ব দ্বারা চিহ্নিত করা হবে \((i, j)\)-th ব্লক\(W_{i,j}\) 32 দ্বারা মাত্রা 32 যা নিম্নলিখিত, আমরা Frobenius আদর্শ [ঠাহর 4 ] \(||W_{i,j}||_F\) প্রতিটি ব্লক, এবং একটি বড় আদর্শ উচ্চ গুরুত্ব সুপারিশ করবে (অভিমানী বৈশিষ্ট্য 'embeddings অনুরূপ দাঁড়িপাল্লা হয়)।
ব্লক আদর্শ ছাড়াও, আমরা সম্পূর্ণ ম্যাট্রিক্স, অথবা প্রতিটি ব্লকের গড়/মধ্য/সর্বোচ্চ মান কল্পনা করতে পারি।
model = dcn_result["model"][0]
mat = model._cross_layer._dense.kernel
features = model._all_features
block_norm = np.ones([len(features), len(features)])
dim = model.embedding_dimension
# Compute the norms of the blocks.
for i in range(len(features)):
for j in range(len(features)):
block = mat[i * dim:(i + 1) * dim,
j * dim:(j + 1) * dim]
block_norm[i,j] = np.linalg.norm(block, ord="fro")
plt.figure(figsize=(9,9))
im = plt.matshow(block_norm, cmap=plt.cm.Blues)
ax = plt.gca()
divider = make_axes_locatable(plt.gca())
cax = divider.append_axes("right", size="5%", pad=0.05)
plt.colorbar(im, cax=cax)
cax.tick_params(labelsize=10)
_ = ax.set_xticklabels([""] + features, rotation=45, ha="left", fontsize=10)
_ = ax.set_yticklabels([""] + features, fontsize=10)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:23: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:24: UserWarning: FixedFormatter should only be used together with FixedLocator <Figure size 648x648 with 0 Axes>
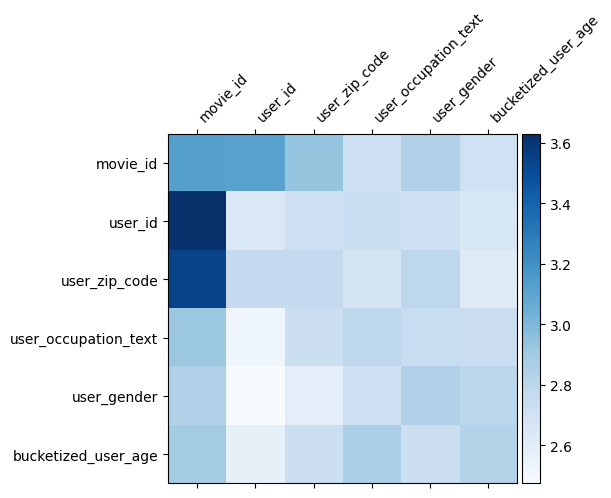
এই কোলাব জন্য যে সব! আমরা আশা করি আপনি DCN এর কিছু মৌলিক বিষয় এবং এটি ব্যবহার করার সাধারণ উপায়গুলি শিখতে উপভোগ করেছেন। : আপনি আরো জানতে আগ্রহী হয়, আপনি দুই প্রাসঙ্গিক কাগজপত্র খুঁজে বার করো পারে DCN-v1 এ-কাগজ , DCN-V2 কাগজ ।
তথ্যসূত্র
DCN থেকে V2: র্যাঙ্ক সিস্টেম এ করা ওয়েব মাপের শিক্ষণ জন্য উন্নত ডীপ & ক্রস নেটওয়ার্ক এবং প্রাকটিক্যাল পাঠ ।
রুক্সি ওয়াং, রাকেশ শিভান্না, ডেরেক ঝিউয়ান চেং, সাগর জৈন, ডং লিন, লিচান হং, এড চি। (2020)
এ্যাড ক্লিক করুন ভবিষ্যতবাণী জন্য গভীর & ক্রস নেটওয়ার্ক ।
রুক্সি ওয়াং, বিন ফু, গ্যাং ফু, মিংলিয়াং ওয়াং। (AdKDD 2017)