
Các mô hình học thần kinh để xếp hạng (LTR) có thể mở rộng, các mô hình học thần kinh để xếp hạng (LTR) có thể mở rộng
import tensorflow as tf import tensorflow_datasets as tfds import tensorflow_ranking as tfr # Prep data ds = tfds.load("mslr_web/10k_fold1", split="train") ds = ds.map(lambda feature_map: { "_mask": tf.ones_like(feature_map["label"], dtype=tf.bool), **feature_map }) ds = ds.shuffle(buffer_size=1000).padded_batch(batch_size=32) ds = ds.map(lambda feature_map: ( feature_map, tf.where(feature_map["_mask"], feature_map.pop("label"), -1.))) # Create a model inputs = { "float_features": tf.keras.Input(shape=(None, 136), dtype=tf.float32) } norm_inputs = [tf.keras.layers.BatchNormalization()(x) for x in inputs.values()] x = tf.concat(norm_inputs, axis=-1) for layer_width in [128, 64, 32]: x = tf.keras.layers.Dense(units=layer_width)(x) x = tf.keras.layers.Activation(activation=tf.nn.relu)(x) scores = tf.squeeze(tf.keras.layers.Dense(units=1)(x), axis=-1) # Compile and train model = tf.keras.Model(inputs=inputs, outputs=scores) model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=tfr.keras.losses.SoftmaxLoss(), metrics=tfr.keras.metrics.get("ndcg", topn=5, name="NDCG@5")) model.fit(ds, epochs=3)
TensorFlow Ranking là một thư viện mã nguồn mở để phát triển các mô hình học thần kinh để xếp hạng (LTR) có thể mở rộng. Các mô hình xếp hạng thường được sử dụng trong các hệ thống tìm kiếm và đề xuất, nhưng cũng đã được áp dụng thành công trong nhiều lĩnh vực khác nhau, bao gồm dịch máy , hệ thống đối thoại thương mại điện tử , trình giải SAT , quy hoạch thành phố thông minh và thậm chí cả sinh học tính toán.
Mô hình xếp hạng lấy danh sách các mục (trang web, tài liệu, sản phẩm, phim, v.v.) và tạo danh sách theo thứ tự được tối ưu hóa, chẳng hạn như các mục có liên quan nhất ở trên cùng và các mục ít liên quan nhất ở dưới cùng, thường là để đáp ứng với một truy vấn của người dùng:
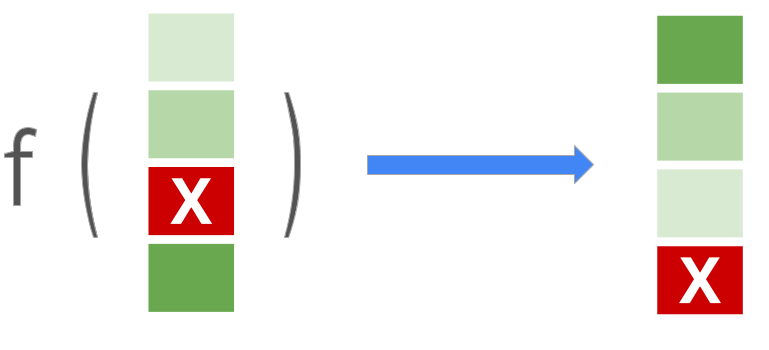
Thư viện này hỗ trợ các chức năng mất điểm tiêu chuẩn, theo từng cặp và theo danh sách cho các mô hình LTR. Nó cũng hỗ trợ một loạt các chỉ số xếp hạng, bao gồm Xếp hạng đối ứng trung bình (MRR) và Mức tăng tích lũy được chiết khấu chuẩn hóa (NDCG), vì vậy bạn có thể đánh giá và so sánh các phương pháp này cho nhiệm vụ xếp hạng của mình. Thư viện Xếp hạng cũng cung cấp các chức năng cho các phương pháp xếp hạng nâng cao do các kỹ sư máy học tại Google nghiên cứu, thử nghiệm và xây dựng.
Bắt đầu với thư viện Xếp hạng TensorFlow bằng cách xem hướng dẫn . Tìm hiểu thêm về các khả năng của thư viện bằng cách đọc Tổng quan Kiểm tra mã nguồn cho Xếp hạng TensorFlow trên GitHub .