
Масштабируемые модели нейронного обучения для ранжирования (LTR), Масштабируемые модели нейронного обучения для ранжирования (LTR)
import tensorflow as tf import tensorflow_datasets as tfds import tensorflow_ranking as tfr # Prep data ds = tfds.load("mslr_web/10k_fold1", split="train") ds = ds.map(lambda feature_map: { "_mask": tf.ones_like(feature_map["label"], dtype=tf.bool), **feature_map }) ds = ds.shuffle(buffer_size=1000).padded_batch(batch_size=32) ds = ds.map(lambda feature_map: ( feature_map, tf.where(feature_map["_mask"], feature_map.pop("label"), -1.))) # Create a model inputs = { "float_features": tf.keras.Input(shape=(None, 136), dtype=tf.float32) } norm_inputs = [tf.keras.layers.BatchNormalization()(x) for x in inputs.values()] x = tf.concat(norm_inputs, axis=-1) for layer_width in [128, 64, 32]: x = tf.keras.layers.Dense(units=layer_width)(x) x = tf.keras.layers.Activation(activation=tf.nn.relu)(x) scores = tf.squeeze(tf.keras.layers.Dense(units=1)(x), axis=-1) # Compile and train model = tf.keras.Model(inputs=inputs, outputs=scores) model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=tfr.keras.losses.SoftmaxLoss(), metrics=tfr.keras.metrics.get("ndcg", topn=5, name="NDCG@5")) model.fit(ds, epochs=3)
TensorFlow Ranking — это библиотека с открытым исходным кодом для разработки масштабируемых моделей нейронного обучения для ранжирования (LTR). Модели ранжирования обычно используются в поисковых и рекомендательных системах, но также успешно применяются в самых разных областях, включая машинный перевод , диалоговые системы электронной коммерции , SAT-решатели , интеллектуальное городское планирование и даже вычислительную биологию.
Модель ранжирования берет список элементов (веб-страницы, документы, продукты, фильмы и т. д.) и создает список в оптимизированном порядке, например, наиболее релевантные элементы находятся вверху, а наименее релевантные - внизу, обычно в ответ на запрос пользователя:
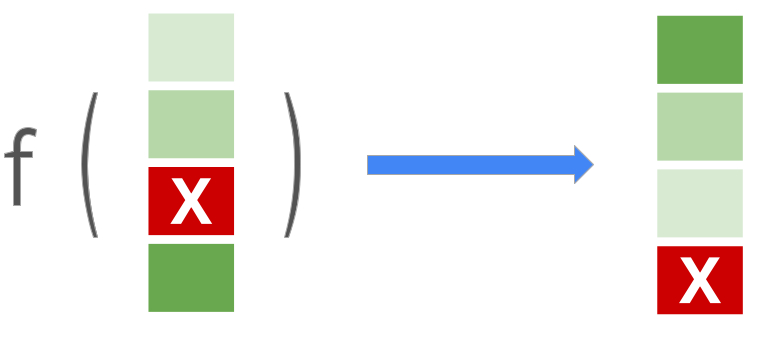
Эта библиотека поддерживает стандартные точечные, парные и списочные функции потерь для моделей LTR. Он также поддерживает широкий спектр показателей ранжирования, включая средний взаимный ранг (MRR) и нормализованный дисконтированный кумулятивный выигрыш (NDCG), поэтому вы можете оценить и сравнить эти подходы для своей задачи ранжирования. Библиотека рейтинга также предоставляет функции для расширенных подходов к ранжированию, которые исследуются, тестируются и создаются инженерами по машинному обучению в Google.
Начните работу с библиотекой ранжирования TensorFlow, ознакомившись с учебным пособием . Узнайте больше о возможностях библиотеки, прочитав обзор . Ознакомьтесь с исходным кодом TensorFlow Ranking на GitHub .