
확장 가능한 신경 학습 순위 지정(LTR) 모델,확장 가능한 신경 학습 순위 지정(LTR) 모델
import tensorflow as tf import tensorflow_datasets as tfds import tensorflow_ranking as tfr # Prep data ds = tfds.load("mslr_web/10k_fold1", split="train") ds = ds.map(lambda feature_map: { "_mask": tf.ones_like(feature_map["label"], dtype=tf.bool), **feature_map }) ds = ds.shuffle(buffer_size=1000).padded_batch(batch_size=32) ds = ds.map(lambda feature_map: ( feature_map, tf.where(feature_map["_mask"], feature_map.pop("label"), -1.))) # Create a model inputs = { "float_features": tf.keras.Input(shape=(None, 136), dtype=tf.float32) } norm_inputs = [tf.keras.layers.BatchNormalization()(x) for x in inputs.values()] x = tf.concat(norm_inputs, axis=-1) for layer_width in [128, 64, 32]: x = tf.keras.layers.Dense(units=layer_width)(x) x = tf.keras.layers.Activation(activation=tf.nn.relu)(x) scores = tf.squeeze(tf.keras.layers.Dense(units=1)(x), axis=-1) # Compile and train model = tf.keras.Model(inputs=inputs, outputs=scores) model.compile( optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), loss=tfr.keras.losses.SoftmaxLoss(), metrics=tfr.keras.metrics.get("ndcg", topn=5, name="NDCG@5")) model.fit(ds, epochs=3)
TensorFlow Ranking은 확장 가능한 신경망 순위 학습 (LTR) 모델을 개발하기 위한 오픈 소스 라이브러리입니다. 순위 모델은 일반적으로 검색 및 추천 시스템에 사용되지만 기계 번역 , 대화 시스템 전자 상거래 , SAT 솔버 , 스마트 도시 계획 및 컴퓨터 생물학을 포함한 다양한 분야에서도 성공적으로 적용되었습니다.
순위 모델은 항목(웹 페이지, 문서, 제품, 영화 등)의 목록을 가져와서 가장 관련성이 높은 항목을 맨 위에, 가장 관련성이 낮은 항목을 맨 아래에 배치하는 등 최적화된 순서로 목록을 생성합니다. 사용자 쿼리:
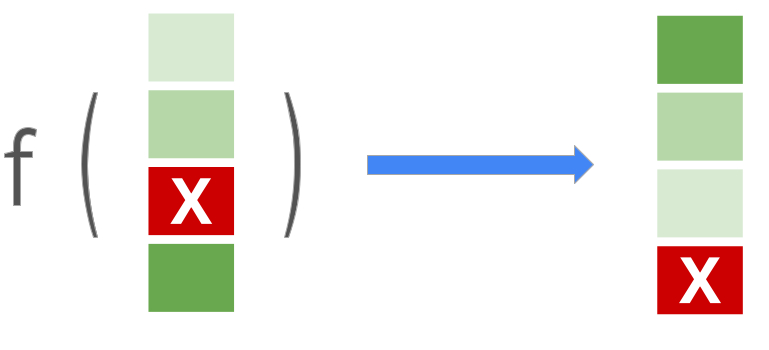
이 라이브러리는 LTR 모델에 대한 표준 포인트별, 쌍별 및 목록별 손실 함수를 지원합니다. 또한 MRR( Mean Reciprocal Rank ) 및 NDCG( Normalized Discounted Cumulative Gain )를 비롯한 다양한 순위 측정항목을 지원하므로 순위 작업에 대해 이러한 접근 방식을 평가하고 비교할 수 있습니다. 순위 라이브러리는 또한 Google의 기계 학습 엔지니어가 연구, 테스트 및 구축한 향상된 순위 접근 방식을 위한 기능을 제공합니다.
튜토리얼 을 확인하여 TensorFlow Ranking 라이브러리를 시작하세요. GitHub 에서 TensorFlow Ranking에 대한 소스 코드 개요 를 확인하여 라이브러리의 기능에 대해 자세히 알아보세요.