
TL;DR : Giảm mã soạn sẵn để xây dựng, đào tạo và phục vụ các mô hình Xếp hạng TensorFlow với Quy trình xếp hạng TensorFlow; Sử dụng các chiến lược phân phối phù hợp cho các ứng dụng xếp hạng quy mô lớn tùy theo trường hợp sử dụng và tài nguyên.
Giới thiệu
Đường dẫn xếp hạng TensorFlow bao gồm một loạt các quy trình xử lý dữ liệu, xây dựng mô hình, đào tạo và cung cấp cho phép bạn xây dựng, đào tạo và phục vụ các mô hình xếp hạng dựa trên mạng thần kinh có thể mở rộng từ nhật ký dữ liệu với những nỗ lực tối thiểu. Quy trình hoạt động hiệu quả nhất khi hệ thống mở rộng quy mô. Nói chung, nếu mô hình của bạn mất 10 phút trở lên để chạy trên một máy, hãy cân nhắc sử dụng khung quy trình này để phân phối tải và tăng tốc độ xử lý.
Quy trình xếp hạng TensorFlow đã được chạy liên tục và ổn định trong các thử nghiệm và sản xuất quy mô lớn với dữ liệu lớn (terabyte+) và các mô hình lớn (100M+ FLOP) trên các hệ thống phân tán (CPU 1K+ và hơn 100 GPU và TPU). Sau khi mô hình TensorFlow được chứng minh bằng model.fit trên một phần nhỏ dữ liệu, quy trình được đề xuất để quét siêu tham số, đào tạo liên tục và các tình huống quy mô lớn khác.
Quy trình xếp hạng
Trong TensorFlow, một quy trình điển hình để xây dựng, đào tạo và phục vụ mô hình xếp hạng bao gồm các bước điển hình sau.
- Xác định cấu trúc mô hình:
- Tạo đầu vào;
- Tạo các lớp tiền xử lý;
- Tạo kiến trúc mạng lưới thần kinh;
- Mô hình tàu hỏa:
- Tạo tập dữ liệu đào tạo và xác thực từ nhật ký dữ liệu;
- Chuẩn bị mô hình với các siêu tham số thích hợp:
- Trình tối ưu hóa;
- Xếp hạng tổn thất;
- Số liệu xếp hạng;
- Định cấu hình các chiến lược phân tán để đào tạo trên nhiều thiết bị.
- Định cấu hình cuộc gọi lại cho các sổ sách kế toán khác nhau.
- Mô hình xuất khẩu phục vụ;
- Mô hình phục vụ:
- Xác định định dạng dữ liệu khi phục vụ;
- Chọn và tải mô hình đã được đào tạo;
- Quá trình với mô hình được tải.
Một trong những mục tiêu chính của quy trình Xếp hạng TensorFlow là giảm mã soạn sẵn trong các bước, chẳng hạn như tải và xử lý trước tập dữ liệu, khả năng tương thích của dữ liệu theo danh sách và chức năng tính điểm theo điểm cũng như xuất mô hình. Mục tiêu quan trọng khác là thực thi thiết kế nhất quán của nhiều quy trình có mối tương quan vốn có, ví dụ: đầu vào của mô hình phải tương thích với cả tập dữ liệu huấn luyện và định dạng dữ liệu khi phân phát.
Hướng dẫn sử dụng
Với tất cả các thiết kế trên, việc khởi chạy mô hình xếp hạng TF rơi vào các bước sau, như trong Hình 1.
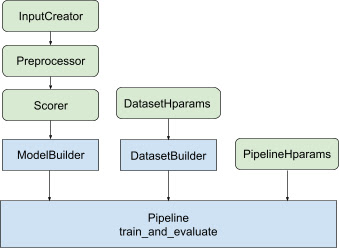
Ví dụ sử dụng mạng nơ-ron phân tán
Trong ví dụ này, bạn sẽ tận dụng tfr.keras.model.FeatureSpecInputCreator , tfr.keras.pipeline.SimpleDatasetBuilder và tfr.keras.pipeline.SimplePipeline tích hợp sẵn trong feature_spec s để xác định nhất quán các tính năng đầu vào trong đầu vào mô hình và máy chủ dữ liệu. Bạn có thể tìm thấy phiên bản sổ tay có hướng dẫn từng bước trong hướng dẫn xếp hạng phân tán .
Đầu tiên hãy xác định feature_spec s cho cả tính năng ngữ cảnh và ví dụ.
context_feature_spec = {}
example_feature_spec = {
'custom_features_{}'.format(i + 1):
tf.io.FixedLenFeature(shape=(1,), dtype=tf.float32, default_value=0.0)
for i in range(10)
}
label_spec = ('utility', tf.io.FixedLenFeature(
shape=(1,), dtype=tf.float32, default_value=-1))
Thực hiện theo các bước được minh họa trong Hình 1:
Xác định input_creator từ feature_spec s.
input_creator = tfr.keras.model.FeatureSpecInputCreator(
context_feature_spec, example_feature_spec)
Sau đó, xác định các phép biến đổi tính năng tiền xử lý cho cùng một bộ tính năng đầu vào.
def log1p(tensor):
return tf.math.log1p(tensor * tf.sign(tensor)) * tf.sign(tensor)
preprocessor = {
'custom_features_{}'.format(i + 1): log1p
for i in range(10)
}
Xác định trình ghi điểm bằng mô hình DNN chuyển tiếp tích hợp sẵn.
dnn_scorer = tfr.keras.model.DNNScorer(
hidden_layer_dims=[1024, 512, 256],
output_units=1,
activation=tf.nn.relu,
use_batch_norm=True,
batch_norm_moment=0.99,
dropout=0.4)
Tạo model_builder với input_creator , preprocessor và scorer .
model_builder = tfr.keras.model.ModelBuilder(
input_creator=input_creator,
preprocessor=preprocessor,
scorer=dnn_scorer,
mask_feature_name='__list_mask__',
name='web30k_dnn_model')
Bây giờ hãy đặt siêu tham số cho dataset_builder .
dataset_hparams = tfr.keras.pipeline.DatasetHparams(
train_input_pattern='/path/to/MSLR-WEB30K-ELWC/train-*',
valid_input_pattern='/path/to/MSLR-WEB30K-ELWC/vali-*',
train_batch_size=128,
valid_batch_size=128,
list_size=200,
dataset_reader=tf.data.RecordIODataset,
convert_labels_to_binary=False)
Tạo dataset_builder .
tfr.keras.pipeline.SimpleDatasetBuilder(
context_feature_spec=context_feature_spec,
example_feature_spec=example_feature_spec,
mask_feature_name='__list_mask__',
label_spec=label_spec,
hparams=dataset_hparams)
Đồng thời đặt siêu tham số cho đường ống.
pipeline_hparams = tfr.keras.pipeline.PipelineHparams(
model_dir='/tmp/web30k_dnn_model',
num_epochs=100,
num_train_steps=100000,
num_valid_steps=100,
loss='softmax_loss',
loss_reduction=tf.losses.Reduction.AUTO,
optimizer='adam',
learning_rate=0.0001,
steps_per_execution=100,
export_best_model=True,
strategy='MirroredStrategy',
tpu=None)
Tạo ranking_pipeline và đào tạo.
ranking_pipeline = tfr.keras.pipeline.SimplePipeline(
model_builder=model_builder,
dataset_builder=dataset_builder,
hparams=pipeline_hparams,
)
ranking_pipeline.train_and_validate()
Thiết kế đường dẫn xếp hạng TensorFlow
Đường dẫn xếp hạng TensorFlow giúp tiết kiệm thời gian kỹ thuật với mã soạn sẵn, đồng thời cho phép tùy chỉnh linh hoạt thông qua ghi đè và phân lớp. Để đạt được điều này, quy trình giới thiệu các lớp có thể tùy chỉnh tfr.keras.model.AbstractModelBuilder , tfr.keras.pipeline.AbstractDatasetBuilder và tfr.keras.pipeline.AbstractPipeline để thiết lập quy trình Xếp hạng TensorFlow.

Người xây dựng mô hình
Mã soạn sẵn liên quan đến việc xây dựng mô hình Keras được tích hợp trong Tóm AbstractModelBuilder , được chuyển đến AbstractPipeline và được gọi bên trong quy trình để xây dựng mô hình theo phạm vi chiến lược. Điều này được thể hiện trong Hình 1. Các phương thức lớp được định nghĩa trong lớp cơ sở trừu tượng.
class AbstractModelBuilder:
def __init__(self, mask_feature_name, name):
@abstractmethod
def create_inputs(self):
// To create tf.keras.Input. Abstract method, to be overridden.
...
@abstractmethod
def preprocess(self, context_inputs, example_inputs, mask):
// To preprocess input features. Abstract method, to be overridden.
...
@abstractmethod
def score(self, context_features, example_features, mask):
// To score based on preprocessed features. Abstract method, to be overridden.
...
def build(self):
context_inputs, example_inputs, mask = self.create_inputs()
context_features, example_features = self.preprocess(
context_inputs, example_inputs, mask)
logits = self.score(context_features, example_features, mask)
return tf.keras.Model(inputs=..., outputs=logits, name=self._name)
Bạn có thể trực tiếp phân lớp AbstractModelBuilder và ghi đè bằng các phương thức cụ thể để tùy chỉnh, như
class MyModelBuilder(AbstractModelBuilder):
def create_inputs(self, ...):
...
Đồng thời, bạn nên sử dụng ModelBuilder với các tính năng đầu vào, các phép biến đổi tiền xử lý và các hàm tính điểm được chỉ định làm hàm đầu vào input_creator , preprocessor và scorer trong lớp init thay vì phân lớp con.
class ModelBuilder(AbstractModelBuilder):
def __init__(self, input_creator, preprocessor, scorer, mask_feature_name, name):
...
Để giảm bớt các bản mẫu tạo các đầu vào này, các lớp hàm tfr.keras.model.InputCreator cho input_creator , tfr.keras.model.Preprocessor cho preprocessor và tfr.keras.model.Scorer cho scorer được cung cấp cùng với các lớp con cụ thể tfr.keras.model.FeatureSpecInputCreator , tfr.keras.model.TypeSpecInputCreator , tfr.keras.model.PreprocessorWithSpec , tfr.keras.model.UnivariateScorer , tfr.keras.model.DNNScorer và tfr.keras.model.GAMScorer . Chúng sẽ bao gồm hầu hết các trường hợp sử dụng phổ biến.
Lưu ý rằng các lớp hàm này là các lớp Keras nên không cần phải tuần tự hóa. Phân lớp là cách được đề xuất để tùy chỉnh chúng.
Trình tạo dữ liệu
Lớp DatasetBuilder thu thập bản tóm tắt liên quan đến tập dữ liệu. Dữ liệu được chuyển đến Pipeline và được gọi để phục vụ các tập dữ liệu đào tạo và xác thực cũng như để xác định chữ ký cung cấp cho các mô hình đã lưu. Như được hiển thị trong Hình 1, các phương thức DatasetBuilder được định nghĩa trong lớp cơ sở tfr.keras.pipeline.AbstractDatasetBuilder ,
class AbstractDatasetBuilder:
@abstractmethod
def build_train_dataset(self, *arg, **kwargs):
// To return the training dataset.
...
@abstractmethod
def build_valid_dataset(self, *arg, **kwargs):
// To return the validation dataset.
...
@abstractmethod
def build_signatures(self, *arg, **kwargs):
// To build the signatures to export saved model.
...
Trong lớp DatasetBuilder cụ thể, bạn phải triển khai build_train_datasets , build_valid_datasets và build_signatures .
Một lớp cụ thể tạo các tập dữ liệu từ feature_spec s cũng được cung cấp:
class BaseDatasetBuilder(AbstractDatasetBuilder):
def __init__(self, context_feature_spec, example_feature_spec,
training_only_example_spec,
mask_feature_name, hparams,
training_only_context_spec=None):
// Specify label and weight specs in training_only_example_spec.
...
def _features_and_labels(self, features):
// To split the labels and weights from input features.
...
def _build_dataset(self, ...):
return tfr.data.build_ranking_dataset(
context_feature_spec+training_only_context_spec,
example_feature_spec+training_only_example_spec, mask_feature_name, ...)
def build_train_dataset(self):
return self._build_dataset(...)
def build_valid_dataset(self):
return self._build_dataset(...)
def build_signatures(self, model):
return saved_model.Signatures(model, context_feature_spec,
example_feature_spec, mask_feature_name)()
hparams được sử dụng trong DatasetBuilder được chỉ định trong lớp dữ liệu tfr.keras.pipeline.DatasetHparams .
Đường ống
Đường ống xếp hạng dựa trên lớp tfr.keras.pipeline.AbstractPipeline :
class AbstractPipeline:
@abstractmethod
def build_loss(self):
// Returns a tf.keras.losses.Loss or a dict of Loss. To be overridden.
...
@abstractmethod
def build_metrics(self):
// Returns a list of evaluation metrics. To be overridden.
...
@abstractmethod
def build_weighted_metrics(self):
// Returns a list of weighted metrics. To be overridden.
...
@abstractmethod
def train_and_validate(self, *arg, **kwargs):
// Main function to run the training pipeline. To be overridden.
...
Một lớp đường dẫn cụ thể huấn luyện mô hình với tf.distribute.strategy khác nhau tương thích với model.fit cũng được cung cấp:
class ModelFitPipeline(AbstractPipeline):
def __init__(self, model_builder, dataset_builder, hparams):
...
def build_callbacks(self):
// Builds callbacks used in model.fit. Override for customized usage.
...
def export_saved_model(self, model, export_to, checkpoint=None):
if checkpoint:
model.load_weights(checkpoint)
model.save(export_to, signatures=dataset_builder.build_signatures(model))
def train_and_validate(self, verbose=0):
with self._strategy.scope():
model = model_builder.build()
model.compile(
optimizer,
loss=self.build_loss(),
metrics=self.build_metrics(),
loss_weights=self.hparams.loss_weights,
weighted_metrics=self.build_weighted_metrics())
train_dataset, valid_dataset = (
dataset_builder.build_train_dataset(),
dataset_builder.build_valid_dataset())
model.fit(
x=train_dataset,
validation_data=valid_dataset,
callbacks=self.build_callbacks(),
verbose=verbose)
self.export_saved_model(model, export_to=model_output_dir)
hparams được sử dụng trong tfr.keras.pipeline.ModelFitPipeline được chỉ định trong lớp dữ liệu tfr.keras.pipeline.PipelineHparams . Lớp ModelFitPipeline này đủ cho hầu hết các trường hợp sử dụng Xếp hạng TF. Khách hàng có thể dễ dàng phân lớp nó cho các mục đích cụ thể.
Hỗ trợ chiến lược phân phối
Vui lòng tham khảo phần đào tạo phân tán để biết giới thiệu chi tiết về các chiến lược phân tán được TensorFlow hỗ trợ. Hiện tại, quy trình Xếp hạng TensorFlow hỗ trợ tf.distribute.MirroredStrategy (mặc định), tf.distribute.TPUStrategy , tf.distribute.MultiWorkerMirroredStrategy và tf.distribute.ParameterServerStrategy . Chiến lược nhân đôi tương thích với hầu hết các hệ thống máy đơn lẻ. Vui lòng đặt strategy thành None nếu không có chiến lược phân phối.
Nhìn chung, MirroredStrategy hoạt động với các kiểu máy tương đối nhỏ trên hầu hết các thiết bị có tùy chọn CPU và GPU. MultiWorkerMirroredStrategy hoạt động cho các mô hình lớn không phù hợp với một công nhân. ParameterServerStrategy thực hiện đào tạo không đồng bộ và yêu cầu có sẵn nhiều công nhân. TPUStrategy lý tưởng cho các mô hình lớn và dữ liệu lớn khi có sẵn TPU, tuy nhiên, nó kém linh hoạt hơn về hình dạng tensor mà nó có thể xử lý.
Câu hỏi thường gặp
Tập hợp các thành phần tối thiểu để sử dụng
RankingPipeline
Xem mã ví dụ ở trên.Nếu tôi có
modelKeras của riêng mình thì sao
Để được huấn luyện với các chiến lượctf.distribute,modelcần được xây dựng với tất cả các biến có thể huấn luyện được xác định trong Strategy.scope(). Vì vậy, hãy bọc mô hình của bạn trongModelBuilderdưới dạng,
class MyModelBuilder(AbstractModelBuilder):
def __init__(self, model, context_feature_names, example_feature_names,
mask_feature_name, name):
super().__init__(mask_feature_name, name)
self._model = model
self._context_feature_names = context_feature_names
self._example_feature_names = example_feature_names
def create_inputs(self):
inputs = self._model.input
context_inputs = {inputs[name] for name in self._context_feature_names}
example_inputs = {inputs[name] for name in self._example_feature_names}
mask = inputs[self._mask_feature_name]
return context_inputs, example_inputs, mask
def preprocess(self, context_inputs, example_inputs, mask):
return context_inputs, example_inputs, mask
def score(self, context_features, example_features, mask):
inputs = dict(
list(context_features.items()) + list(example_features.items()) +
[(self._mask_feature_name, mask)])
return self._model(inputs)
model_builder = MyModelBuilder(model, context_feature_names, example_feature_names,
mask_feature_name, "my_model")
Sau đó đưa model_builder này vào quy trình để đào tạo thêm.